redis服务器端口默认是6379
在编译完成后的bin目录下启动服务端:redis-server
客户端连接操作:redis-cli -h localhost -p 6379,如果是一台机器可以省略后面的:redis-cli
(备注:可以复制redis解压目录下的redis-conf文件到另一个文件夹,然后可以修改端口号 port 7000 这时你再次启动服务还是6379的端口号,读取的还是源码目录里的redis-conf文件,要想在启动的时候读取我们修改后的配置文件,需要修改启动命令的格式:redis-server 复制过来修改后的配置文件路径,比如:redis-server ./redis.conf 客户端启动的时候默认是与6379的端口号的redis服务连接,所有当我们指定端口号启动的时候,客户端也需要改变,格式为:redis-cli -h 服务器的ip地址 -p 端口号 ,比如:redis-cli -h localhost -p 7000)
redis 数据库默认有16个库,名字从0开始到15编号。一开始默认进入的是0号库。我们可以在客户端通过select dbid(库的编号)来切换库,比如:select 1 切换到1号库。同时需要注意的是库与库之间的数据是不共享的,是相对隔离的。
del 指令
语法 : DEL key [key ...]
作用 : 删除给定的一个或多个key 。不存在的key 会被忽略。多个key之间使用空格隔开
可用版本: >= 1.0.0
返回值: 被删除key 的数量。
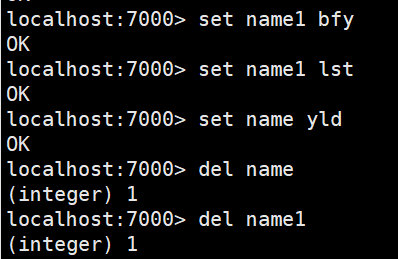
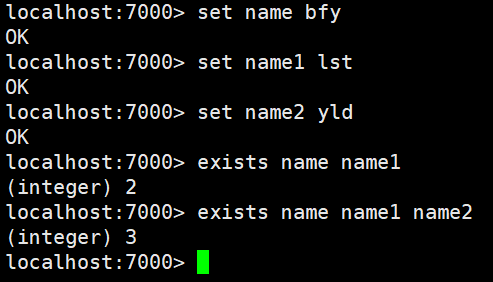
exists指令
语法: EXISTS key
作用: 检查给定key 是否存在。多个key之间使用空格隔开,只要有一个key存在,返回值就是1 新版本中会提示几个键存在
可用版本: >= 1.0.0
返回值: 若key 存在,返回1 ,否则返回0。
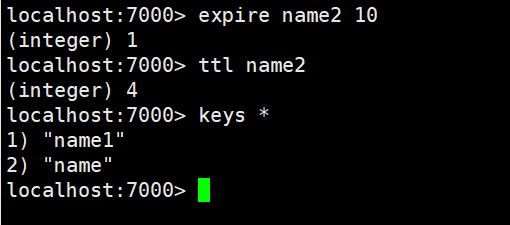
expire指令
语法: EXPIRE key seconds
作用: 为给定key 设置生存时间,以秒为单位,当key 过期时(生存时间为0 ),它会被自动删除。
可用版本: >= 1.0.0
时间复杂度: O(1)
返回值:设置成功返回1 。
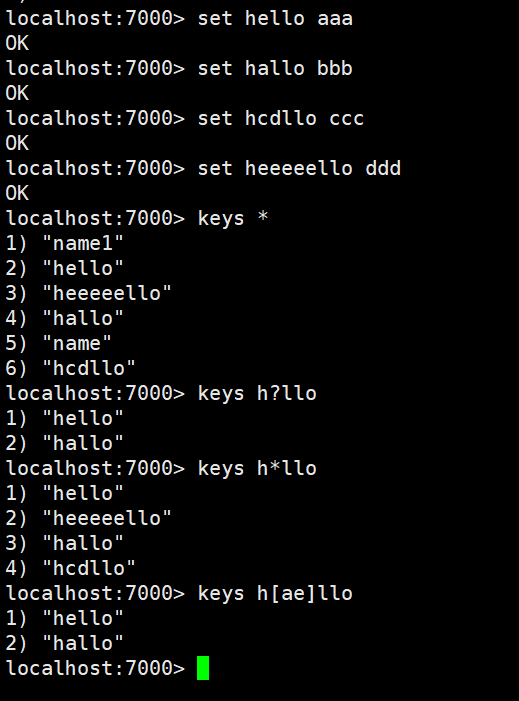
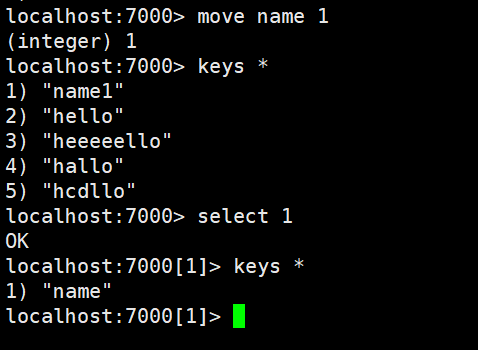
keys指令
语法 : KEYS pattern
作用 : 查找所有符合给定模式pattern 的key 。
语法:
KEYS * 匹配数据库中所有key 。
KEYS h?llo 匹配hello ,hallo 和hxllo 等。
KEYS h*llo 匹配hllo 和heeeeello 等。
KEYS h[ae]llo 匹配hello 和hallo ,但不匹配hillo 。特殊符号用 "" 隔开
可用版本: >= 1.0.0
返回值: 符合给定模式的key 列表。
move指令
语法 : MOVE key db (move name 1----将name键移动到1号库)
作用 : 将当前数据库的key 移动到给定的数据库db 当中。
可用版本: >= 1.0.0
返回值: 移动成功返回1 ,失败则返回0 。
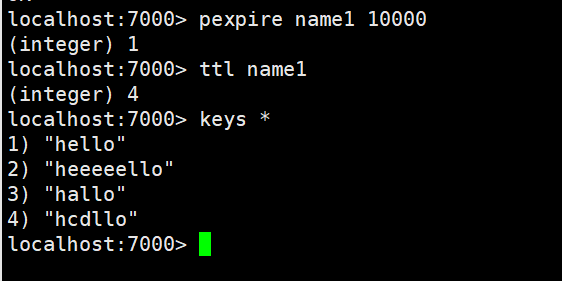
pexpire指令
语法 : PEXPIRE key milliseconds
作用 : 这个命令和EXPIRE 命令的作用类似,但是它以毫秒为单位设置key 的生存时间,而不像EXPIRE 命令那样,以秒为单位。
可用版本: >= 2.6.0
时间复杂度: O(1)
返回值:设置成功,返回1 key 不存在或设置失败,返回0
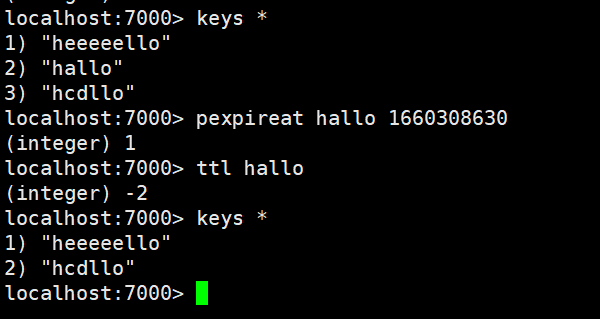
pexpireat指令
语法 : PEXPIREAT key milliseconds-timestamp
作用 : 这个命令和EXPIREAT 命令类似,但它以毫秒为单位设置key 的过期unix 时间戳,而不是像EXPIREAT那样,以秒为单位。
可用版本: >= 2.6.0
返回值:如果生存时间设置成功,返回1 。当key 不存在或没办法设置生存时间时,返回0 。(查看EXPIRE 命令获取更多信息)
ttl指令
语法 : TTL key
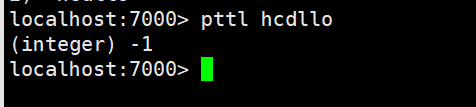
pttl指令
语法 : PTTL key
作用 : 这个命令类似于TTL 命令,但它以毫秒为单位返回key 的剩余生存时间,而不是像TTL 命令那样,以秒为单位。
可用版本: >= 2.6.0
返回值: 当key 不存在时,返回-2 。当key 存在但没有设置剩余生存时间时,返回-1 。
否则,以毫秒为单位,返回key 的剩余生存时间。
randomkey指令
语法 : RANDOMKEY
作用 : 从当前数据库中随机返回(不删除) 一个key 。
可用版本: >= 1.0.0
返回值:当数据库不为空时,返回一个key 。当数据库为空时,返回nil 。
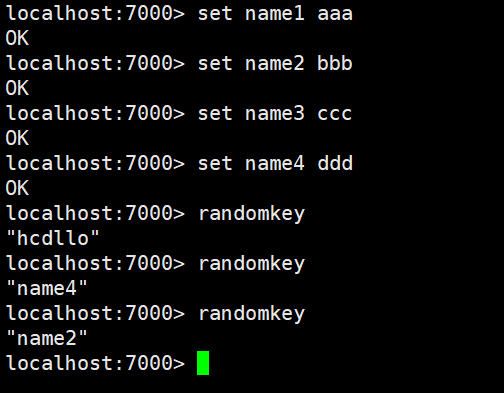
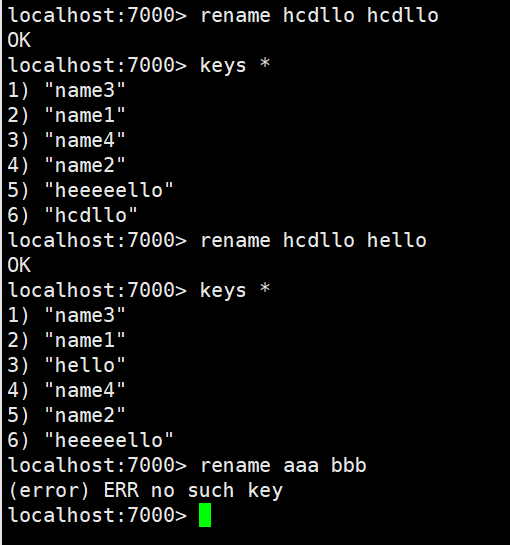
rename指令
语法 : RENAME key newkey
作用 : 将key 改名为newkey 。key 不存在时,返回一个错误。当newkey 已经存在时,RENAME 命令将覆盖旧值。
可用版本: >= 1.0.0
返回值: 改名成功时提示OK ,失败时候返回一个错误。
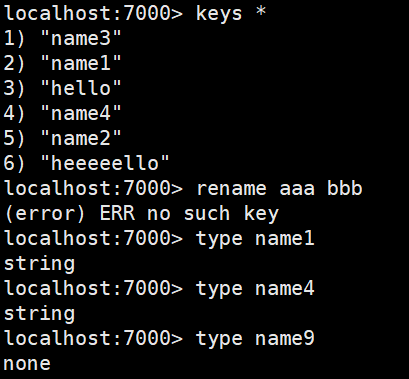
type指令
语法 : TYPE key
作用 : 返回key 所储存的值的类型。
可用版本: >= 1.0.0
返回值:
none (key 不存在)
string (字符串)
list (列表)
set (集合)
zset (有序集)
hash (哈希表)
| 命令 | 说明 |
|---|---|
| set | 设置一个key/value |
| get | 根据key获得对应的value |
| mset | 一次设置多个key value |
| mget | 一次获得多个key的value |
| getset | 获得原始key的值,同时设置新值 |
| strlen | 获得对应key存储value的长度 |
| append | 为对应key的value追加内容 |
| getrange 索引0开始 | 截取value的内容 到末尾-1 |
| setex | 设置一个key存活的有效期(秒) |
| psetex | 设置一个key存活的有效期(毫秒) |
| setnx | 存在不做任何操作,不存在添加 |
| msetnx原子操作(只要有一个存在不做任何操作) | 可以同时设置多个key,只有有一个存在都不保存 |
| decr | 进行数值类型的-1操作 |
| decrby | 根据提供的数据进行减法操作 |
| Incr | 进行数值类型的+1操作 |
| incrby | 根据提供的数据进行加法操作 |
| Incrbyfloat | 根据提供的数据加入浮点数(不是四舍五入) |
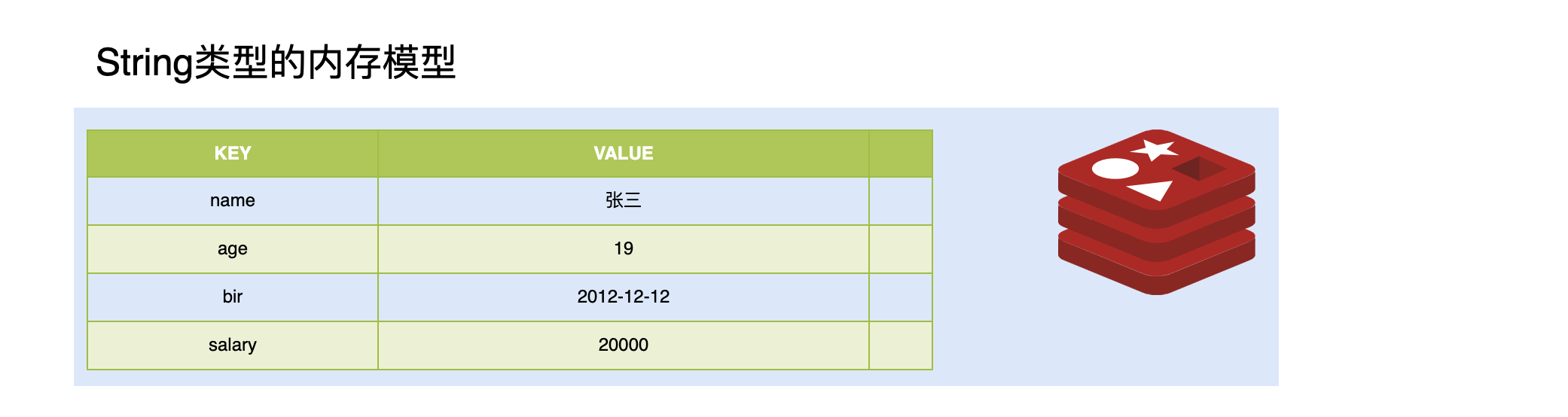
set:设置一个key/value
get:根据key获得对应的value
mset:一次设置多个key/value
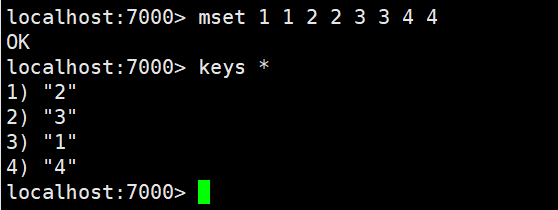
mget:一次获得多个key的value
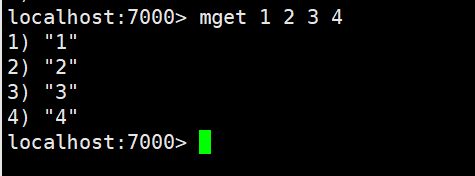
getset:获得原始的key值,同时设置新值
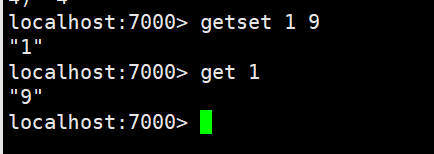
strlen:获得对应key存储value的长度
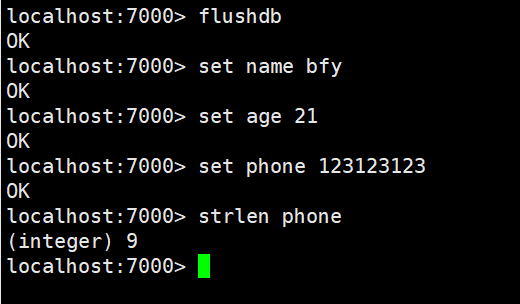
append:为对应的key的value追加内容
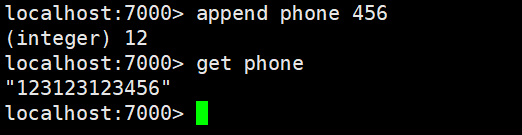
getrange:截取value的内容,字符串的索引从0开始。比如12345从前往后数索引为01234,从后往前数索引为-1-2-3-4-5。所以截取到末尾可以用0 -1 表示。
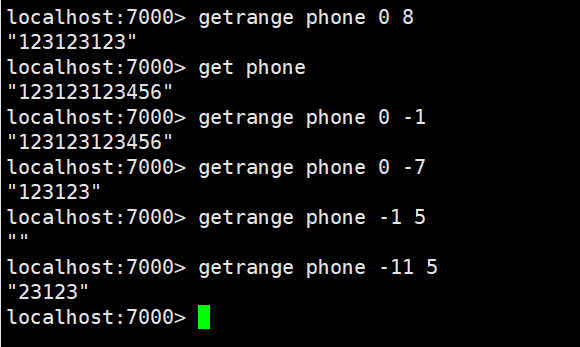
setnx:key/value如果存在,不做任何操作,不存在添加
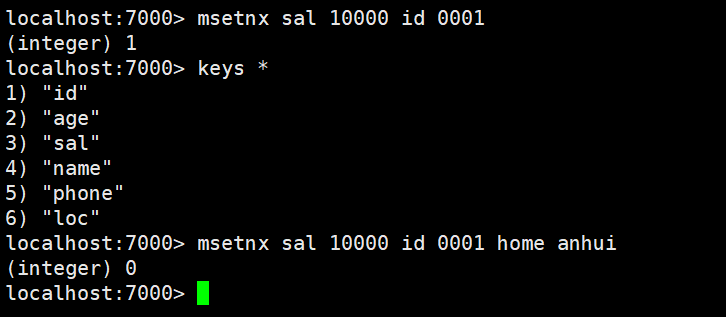
msetnx:原子操作(只要有一个存在不做任何操作)可以同时设置多个key,只有有一个存在都不保存
setex:设置一个key存活的有效期(秒),跟expire指令意思相同,但是这个指令还需要输入key对应的value
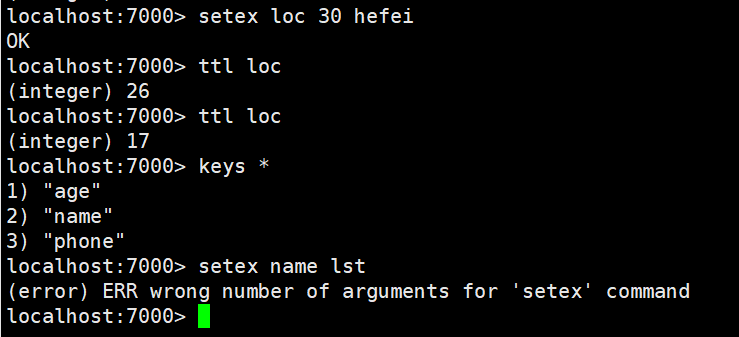
psetex:设置一个key存活的有效期(毫秒),跟pexpire指令意思相同,但是这个指令还需要输入key对应的value
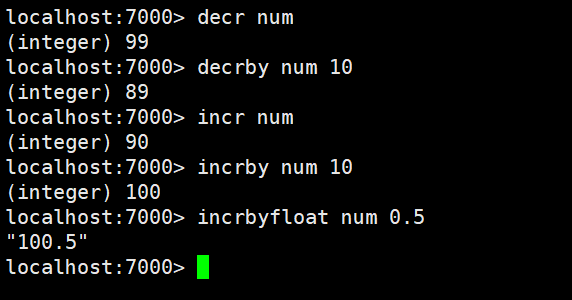
decr:进行数值类型的-1操作
decrby:根据提供的数据进行减法操作
incr:进行数值类型的+1操作
incrby:根据提供的数据进行加法操作
incrbyfloat:根据提供的数据加入浮点数,不是四舍五入
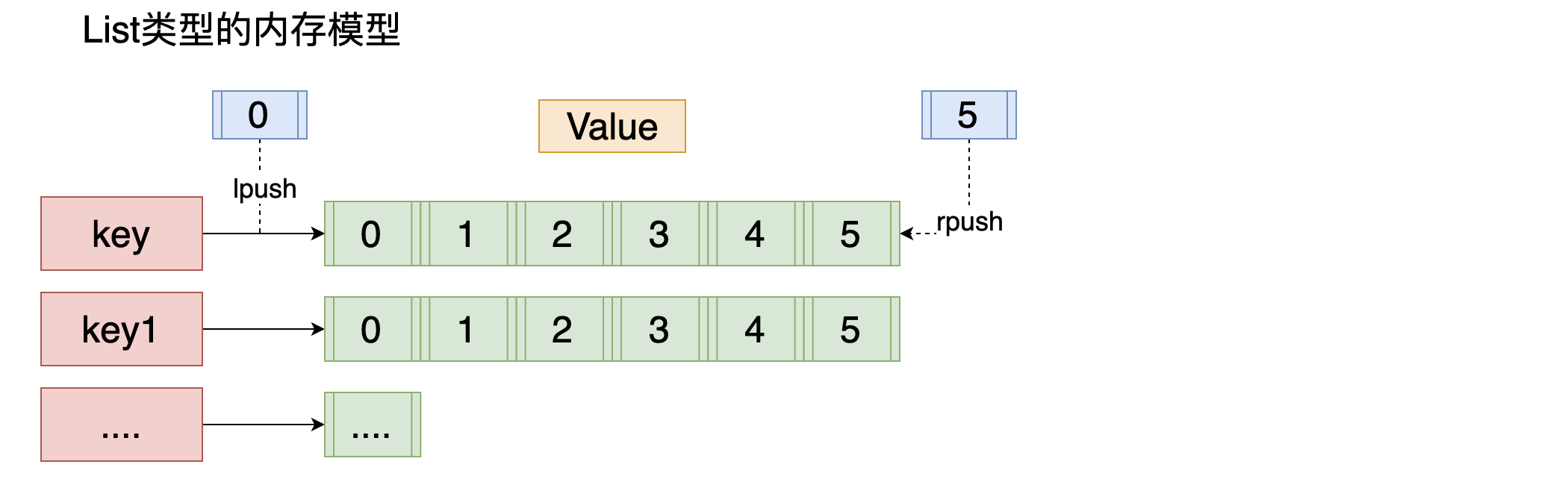
ist 列表 相当于java中list 集合 特点 元素有序 且 可以重复,key还是一个字符串,值是一个list
| 命令 | 说明 |
|---|---|
| lpush | 将某个值加入到一个key列表头部 lpush list xiaohu xiaohei xiaoming 当列表不存在的时候会进行创建 |
| lpushx | 同lpush,但是必须要保证这个key存在 必须在列表进行存在的情况下从左插入 |
| rpush | 将某个值加入到一个key列表末尾 |
| rpushx | 同rpush,但是必须要保证这个key存在 |
| lpop | 返回和移除列表左边的第一个元素 |
| rpop | 返回和移除列表右边的第一个元素 |
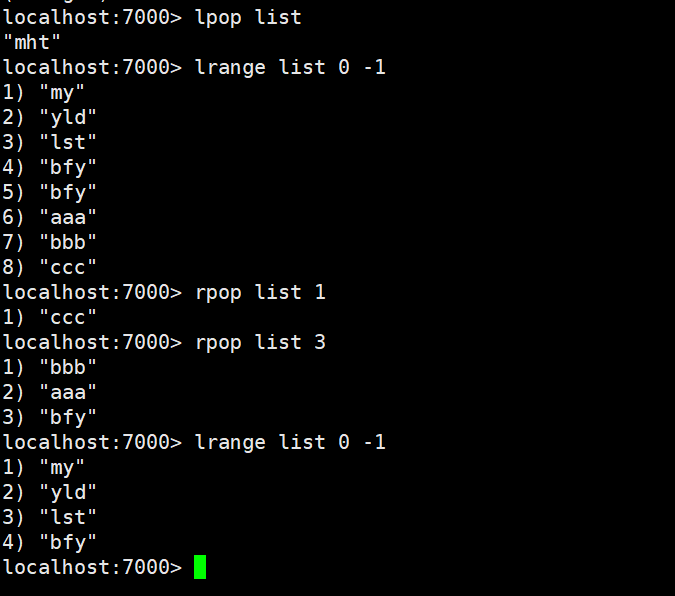
| lrange | 获取某一个下标区间内的元素 lrange list 0 -1 |
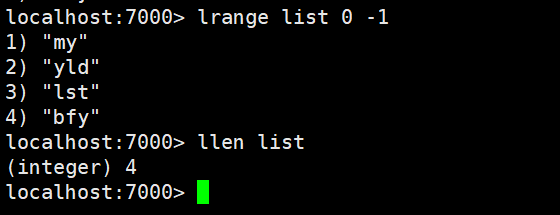
| llen | 获取列表元素个数 |
| lset | 设置某一个指定索引的值(索引必须存在) |
| lindex | 获取某一个指定索引位置的元素 |
| lrem | 删除重复元素 |
| ltrim | 保留列表中特定区间内的元素 |
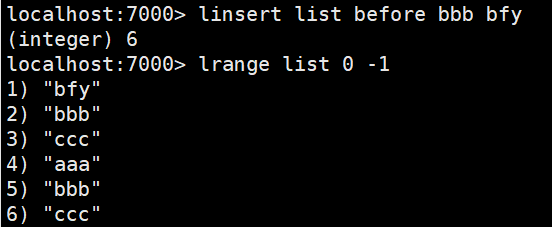
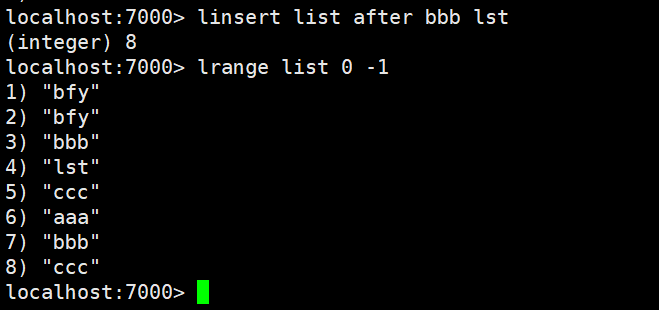
| linsert | 在某一个元素之前,之后插入新元素 |
lpush:(小写的L)将某个值加入到一个key列表头部 lpush list xiaohu xiaohei xiaoming 当列表不存在的时候会进行创建
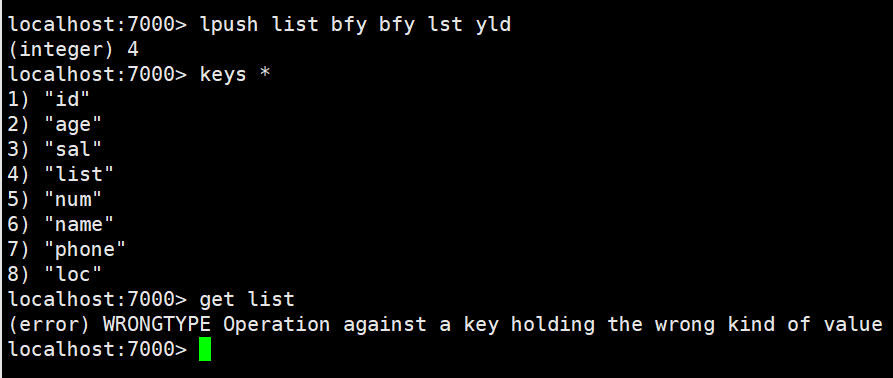
lpushx:同lpush,但是必须要保证这个key存在 必须在列表进行存在的情况下从左插入
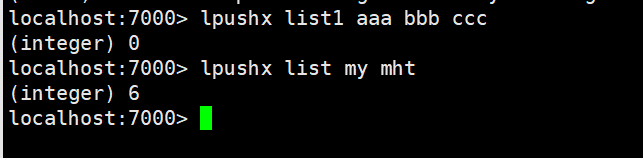
rpush:将某个值加入到一个key列表末尾
rpushx:同rpush,但是必须要保证这个key存在
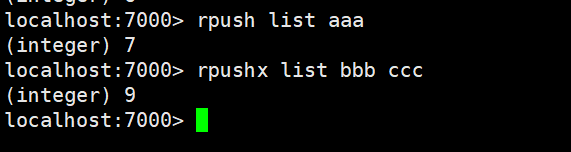
lpop:返回和移除左列表左边的第一个元素,加上数字可以移除左边前几个元素
rpop: 返回和移除列表右边的第一个元素,加上数字可以移除右边后几个元素
lrange:获取某一个下标区间内的元素 lrange list 0 -1,和string类型的getrange命令意思一样
llen:获取列表元素个数
lset:设置某一个指定索引的值(索引必须存在)
lindex:获取某一个指定索引位置的元素
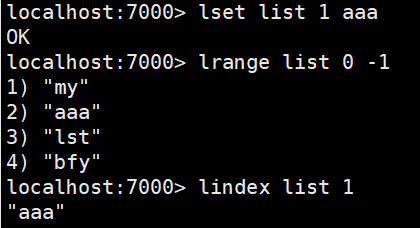
lrem:删除重复元素 。
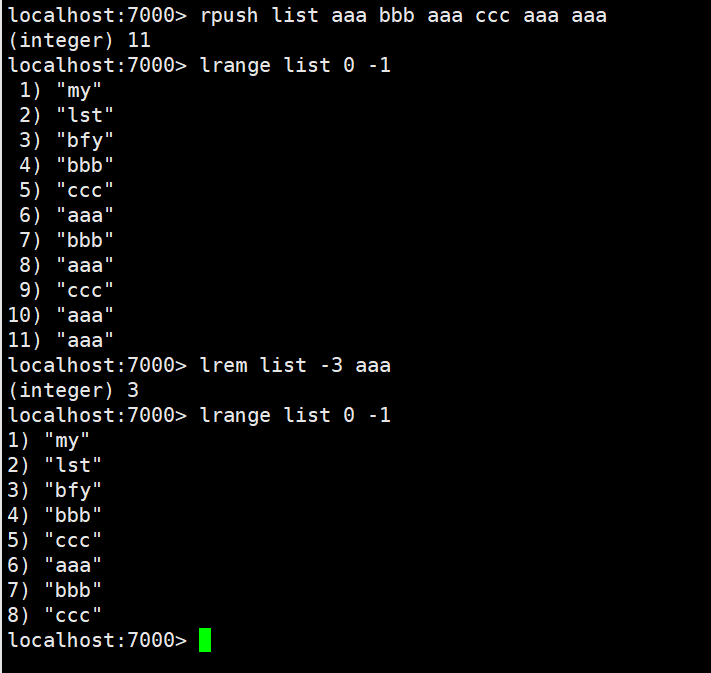
ltrim:保留列表中特定区间内的元素
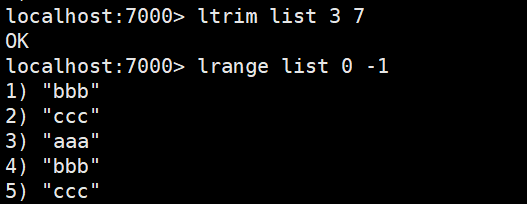
linsert:在某一个元素之前,之后插入新元素
特点: Set类型 Set集合 元素无序 不可以重复
| 命令 | 说明 |
|---|---|
| sadd | 为集合添加元素 |
| smembers | 显示集合中所有元素 无序 |
| scard | 返回集合中元素的个数 |
| spop | 随机返回一个元素 并将元素在集合中删除 |
| smove | 从一个集合中向另一个集合移动元素 必须是同一种类型 |
| srem | 从集合中删除一个元素 |
| sismember | 判断一个集合中是否含有这个元素 |
| srandmember | 随机返回元素 后面可以加数字 表示每次返回的个数 |
| sdiff | 去掉第一个集合中其它集合含有的相同元素 |
| sinter | 求交集 |
| sunion | 求和集 |
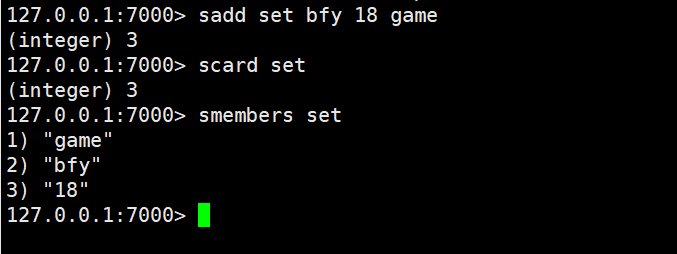
sadd:为集合添加元素
smembers:显示集合中所有元素,无序
scard:返回集合中的个数
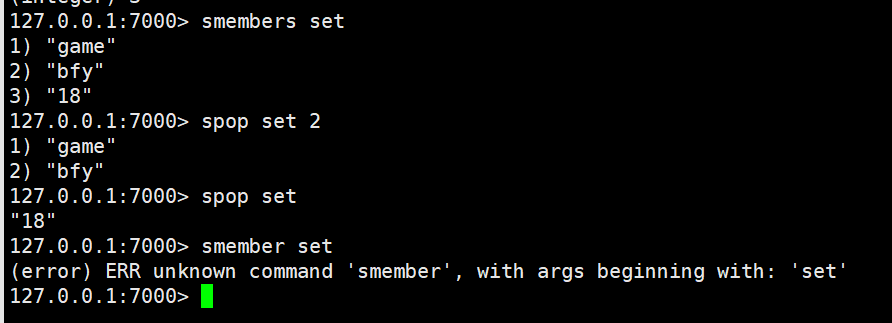
spop:返回集合中的count个元素,并在集合中删除
smove:从一个集合向另一个集合移动元素,必须是同一种集合类型,移动元素要带引号不然集合中的值虽然移动了,但是原来的值的位置还在
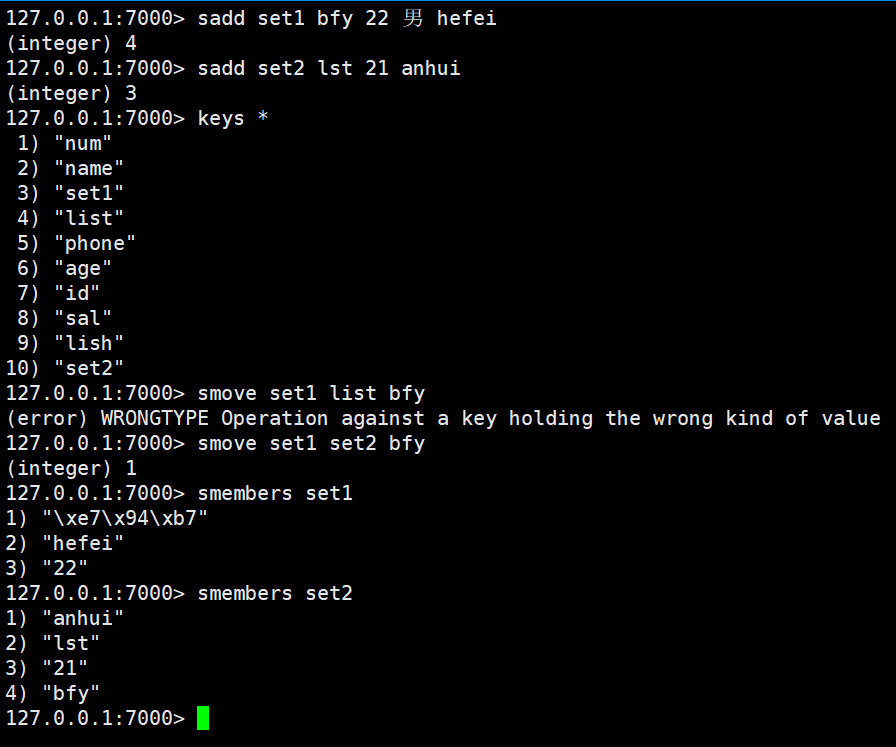
srem:从集合中删除一个或多个元素
sismember:判断一个集合中是否含有这个元素
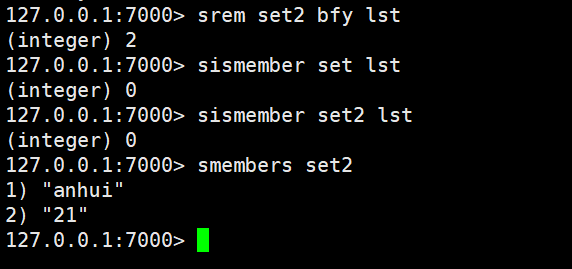
srandmember:随机返回数据,后面可以加数字表示返回的个数
sdiff:去掉一个集合中其他集合含有的相同元素(求差集)
sinter:求交集
sunion:求合集
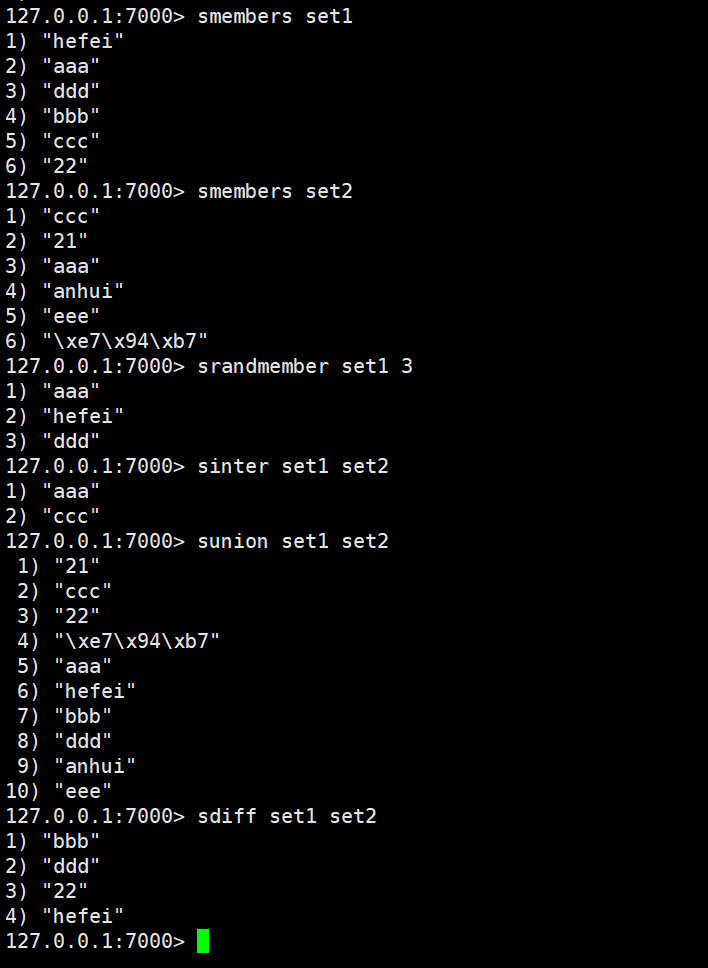
特点: 可排序的set集合 排序 不可重复
ZSET 官方 可排序SET sortSet
| 命令 | 说明 |
|---|---|
| zadd | 添加一个有序集合元素 zadd zset 2 xiaohu 3 xiaohu2 |
| zcard | 返回集合的元素个数 |
| zrange 升序 zrevrange 降序 | 返回一个范围内的元素 如果想看看分数 withscores |
| zrangebyscore(6.2.0版本后已弃用) | 按照分数查找一个范围内的元素 zrangebyscore zset 0 20 withscores limit 0 2 |
| zrank | 返回排名 |
| zrevrank | 倒序排名 |
| zscore | 显示某一个元素的分数 |
| zrem | 移除某一个元素 |
| zincrby | 给某个特定元素加分 |
zadd:添加一个有序集合元素
zcard: 返回集合的元素个数
zrange 升序 zrevrange 降序:返回一个范围内的元素 如果想看看分数 withscores
范围是集合的索引,左闭右闭
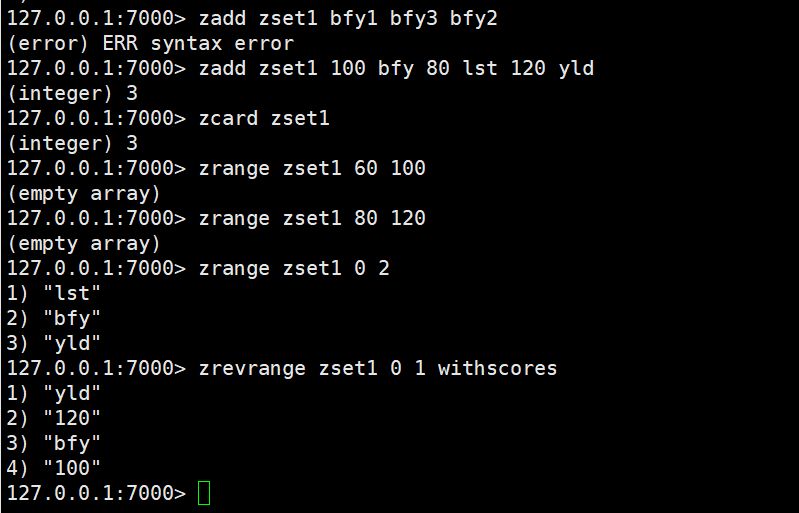
zrangebyscore:按照分数查找一个范围内的元素


按照分数查询,同时设置按索引范围查询


zrank:返回排名
zrevrank:倒序排名
zscore:显示某一个元素的分数
zrem:移除某一个元素
zincrby:给某个特定元素加分
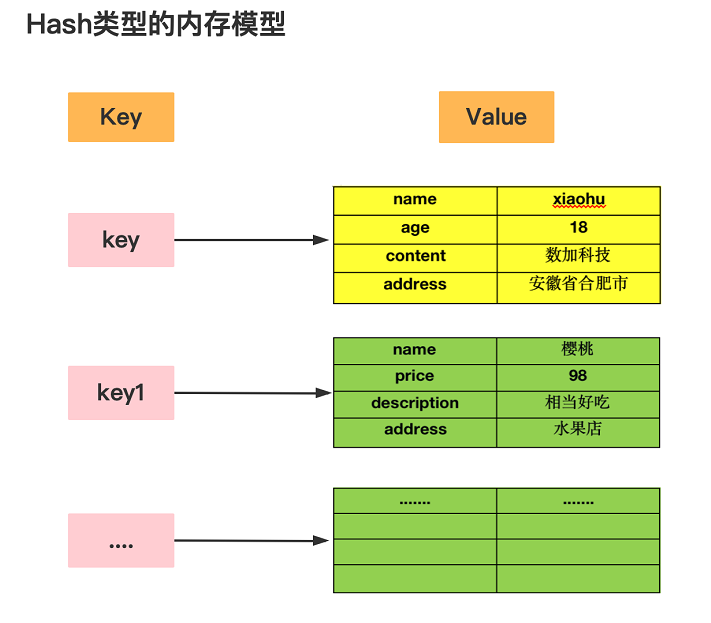
特点: value 是一个map结构 存在key value key 无序的
redis key(String) value(map)
Map<String,Map<String,value>> map
举例:map name zhangsan
| 命令 | 说明 |
|---|---|
| hset | 设置一个、多个key/value对 |
| hget | 获得一个key对应的value |
| hgetall | 获得所有的key/value对 |
| hdel | 删除某一个key/value对 |
| hexists | 判断一个key是否存在 |
| hkeys | 获得所有的key |
| hvals | 获得所有的value |
| hmset(已弃用) | 设置多个key/value |
| hmget | 获得多个key的value |
| hsetnx | 设置一个不存在的key的值 |
| hincrby | 为value进行加法运算(只能针对数值做运行) |
| hincrbyfloat | 为value加入浮点值 |
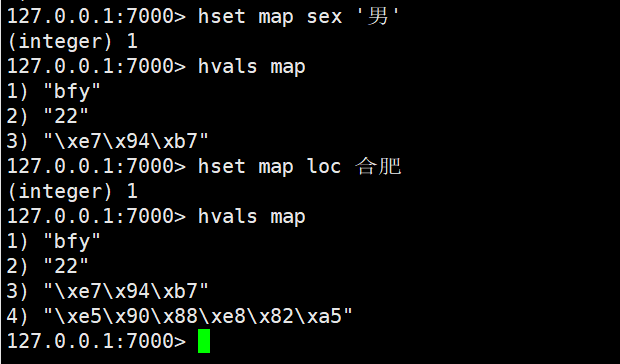
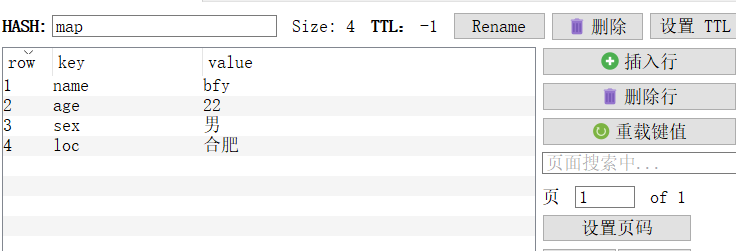
hset:设置一个key/value对,可设置多个,设置中文显示不出来,可通过可视化工具查看

hget、hmget:获得一个key的value、获得多个key的value
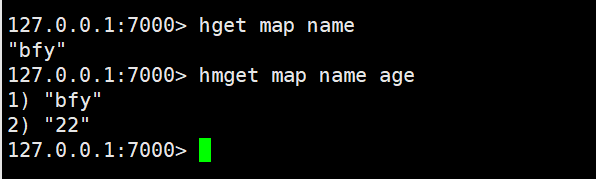
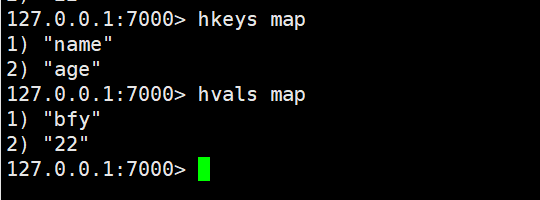
hkeys、hvals:获得所有的key、获得所有的value
 **
**
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我不知道为什么,但是当我设置这个设置时它无法编译设置:static_cache_control,[:public,:max_age=>300]这是我得到的syntaxerror,unexpectedtASSOC,expecting']'(SyntaxError)set:static_cache_control,[:public,:max_age=>300]^我只想将“过期”header设置为css、javaascript和图像文件。谢谢。 最佳答案 我猜您使用的是Ruby1.8.7。Sinatra文档中显示的语法似乎是在Ruby1.
在Ruby1.9.3(可能还有更早的版本,不确定)中,我试图弄清楚为什么Ruby的String#split方法会给我某些结果。我得到的结果似乎与我的预期相反。这是一个例子:"abcabc".split("b")#=>["a","ca","c"]"abcabc".split("a")#=>["","bc","bc"]"abcabc".split("c")#=>["ab","ab"]在这里,第一个示例返回的正是我所期望的。但在第二个示例中,我很困惑为什么#split返回零长度字符串作为返回数组的第一个值。这是什么原因呢?这是我所期望的:"abcabc".split("a")#=>["bc"
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复