本文参考网上可查询到的资料简要总结AI加速器的概念和应用等信息 1。
未完待续
更新: 2023 / 3 / 22
行业观察 | 来了解一下AI加速器
AI、机器学习、深度学习 最早可追溯到几十年前,但是在过去的十几年才开始流行。在接下来的文章内容中,前 苹果、飞利浦、Mellanox(现属英伟达)工程师、普林斯顿大学博士 Adi Funchs 尝试从 AI加速器 的角度为我们寻找这些问题的答案。
过去,科技公司通过观察用户行为、研究市场趋势,在通常需要数月甚至数年时间的周期中优化产品线来改进产品。
如今,人工智能已经为无须人工干预就能驱动人机反馈的自我改进( self-improving ) 算法铺平了道路。这一切都是在数百万(甚至数十亿)用户的规模下完成的,并极大地缩短了产品优化周期。
人工智能的成功归功于三个重要的趋势:
在这里我们重点关注第3个趋势,具体来说,会对AI应用中的加速器做一个高层次的概述——AI加速器是什么?它们是如何变得如此流行的?
加速器源自一个更广泛的概念,而不仅仅是一种特定类型的系统或实现。而且,它们也不是纯硬件驱动的。事实上,AI加速器行业的大部分焦点都集中在构建稳健而复杂的软件库和编译器工具链上。
人工智能不仅仅是软件和算法
AI,机器学习、深度学习 的概念可以追溯到50多年以前,然而在过去的十几年才开始真正流行起来。
深度学习的开始源于 2012 年多伦多大学的 Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton 等人提出了一个名为 AlexNet 的深度神经网络并凭借该网络赢得了 2012 年大规模视觉识别挑战赛的冠军。在这场比赛中,参赛者需要完成一个名叫 object region 的任务,即给定一张包含某目标的图像和一串目标类别(如飞机、瓶子、猫),每个团队的实现都需要识别出图像中的目标属于哪个类。
AlexNet 的表现颇具颠覆性。这是获胜团队首次使用一种名为 卷积神经网络( CNN )的深度学习架构。由于表现过于惊艳,之后几年的 ImageNet 挑战赛冠军都沿用了 CNN。这是计算机视觉史上的一个关键时刻,也激发了人们将深度学习应用于其他领域(如 NLP、机器人、推荐系统)的兴趣。

ImageNet 挑战赛冠军团队的分类错误率逐年变化情况(越低越好)。
「为了加速训练,我们用到了非饱和神经元和一个非常高效的 GPU 卷积操作实现。」
事实证明,AlexNet 作者花了相当多的时间将耗时的卷积操作映射到 GPU 上。与标准处理器相比,GPU 能够更快地执行特定任务,如计算机图形和基于线性代数的计算( CNN 包含大量的此类计算)。高效的 GPU 实现可以帮他们缩短训练时间。他们还详细说明了如何将他们的网络映射到多个 GPU,从而能够部署更深、更宽的网络,并以更快的速度进行训练。
拿 AlexNet 作为一个研究案例,我们可以找到一个回答开篇问题的线索:尽管算法方面的进展很重要,但使用专门的 GPU 硬件使我们能够在合理的时间内学习更复杂的关系(网络更深、更大 = 用于预测的变量更多),从而提高了整个网络的准确率。如果没有能在合理的时间框架内处理所有数据的计算能力,我们就不会看到深度学习应用的广泛采用。
如果我是一名 AI 从业者,我需要关心处理器吗?
作为一名 AI 从业者,如果你探索新的模型和想法,你或多或少需要熟悉一些底层硬件和如何调试性能,以减少你的推理和训练时间。
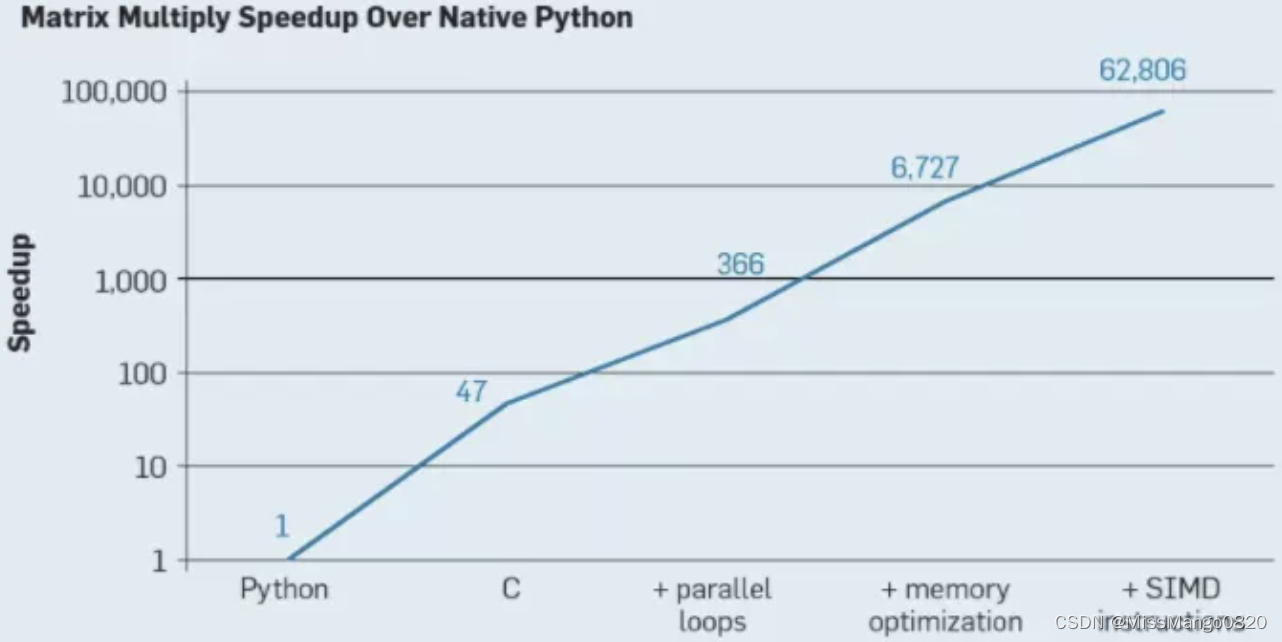
各种并行化技术对于矩阵乘法的加速效果
如果不懂硬件,你所花的时间可能会多 2 - 3 倍,有时甚至多一个数量级。简单地改变做矩阵乘法的方式可能帮你收获巨大的性能提升(或损失)。
那么,为什么不能保证得到最佳性能呢?因为我们还没有有效地达到合理的 user-to-hardware expressiveness。我们有一些有效利用硬件的用例,但还没泛化到「开箱即用」的程度。这里的「开箱即用」指的是在你写出一个全新的 AI 模型之后,你无需手动调整编译器或软件堆栈就能充分利用你的硬件。

AI User-to-Hardware Expressiveness
上图说明了 user-to-hardware expressiveness 的主要挑战。我们需要准确地描述用户需求,并将其转换成硬件层(处理器、GPU、内存、网络等)能够理解的语言。这里的主要问题是,虽然左箭头( programming frameworks )主要是面向用户的,但将编程代码转换为机器码的右箭头却不是。因此,我们需要依靠智能的编译器、库和解释器来无缝地将你的高级代码转换为机器表示。
这种语义鸿沟难以弥合的原因有两个:
GPU 处理核心)、你的程序需要的内存数量、你的程序所展示的内存访问模式和数据重用类型,以及计算图中不同部分之间的关系。以上任何一种都可能以意想不到的方式对系统的不同部分造成压力。为了克服这个问题,我们需要了解硬件 / 软件堆栈的所有不同层是如何交互的。虽然你可以在许多常见的场景中获得良好的性能,但现实中还有无尽的长尾场景,你的模型在这些场景中可能表现极差。因此,你(用户)仍然需要探索正确的方法来识别计算耗时瓶颈。为此,你需要了解处理器,特别是当前的 AI 加速器,以及它们如何与你的 AI 程序交互。
回顾一下处理器的发展历史。
处理器是计算机系统中负责实际数字计算的部分。它接收用户输入数据(用数值表示),并根据用户的请求生成新的数据,即执行一组用户希望的算术运算。
随着计算密集型应用的日益普及和大量新用户数据的出现,当代计算系统必须满足对处理能力不断增长的需求,因此我们总是需要更好的处理器,更好意味着更快,即花同样的时间、使用更少的能源。
计算机系统的进化关键在于半导体行业,以及它如何改进处理器的速度、功率和成本。

英特尔 4004:第一款商用微处理器,发布于 1971 年
处理器是由被称为 晶体管 的电子元件组成的。晶体管是逻辑开关,用作从原始逻辑函数(如 与、或、非 )到复杂算术( 浮点加法、正弦函数 )、存储器(如 ROM、DRAM )等所有东西的构建模块。这些年来,晶体管一直在不断缩小。
处理器发展第一阶段:频率时代(1970-2000 年代)

微处理器频率速率的演变
早期,微处理器行业主要集中在 CPU 上,因为 CPU 是当时计算机系统的主力。微处理器厂商充分利用了缩放定律。具体来说,他们的目标是提高 CPU 的频率,因为更快的晶体管使处理器能够以更高的速率执行相同的计算(更高的频率 = 每秒更多的计算)。这是一种有些简单的看待事物的方式;处理器有很多架构创新,但最终,在早期,频率对性能有很大贡献,从英特尔 4004 的 0.5MHz、486 的 50MHz、奔腾的 500MHz 到奔腾 4 系列的 3–4GHz。

功率密度的演变
大约在 2000 年,登纳德缩放比例定律开始崩溃。具体来说,随着频率的提升,电压停止以相同的速率下降,功率密度速率也是如此。如果这种趋势持续下去,芯片发热问题将不容忽视。然而,强大的散热方案还不成熟。因此,供应商无法继续依靠提高 CPU 频率来获得更高的性能,需要想想其他出路。
处理器发展第二阶段:多核时代(2000 年代 - 2010 年代中期)
停滞不前的 CPU 频率意味着提高单个应用的速度变得非常困难,因为单个应用是以连续指令流的形式编写的。但是,正如摩尔定律所说的那样,每过 18 个月,我们芯片中的晶体管就会变为原来的两倍。因此,这次的解决方案不是加快单个处理器的速度,而是将芯片分成多个相同的处理内核,每个内核执行其指令流。

CPU 和 GPU 核数的演化
对于 CPU 来说,拥有多个内核是很自然的,因为它已经在并发执行多个独立的任务,比如你的互联网浏览器、文字处理器和声音播放器(更准确地说,操作系统在创建这种并发执行的抽象方面做得很好)。因此,一个应用可以在一个内核上运行,而另一个应用可以在另一个内核上运行。通过这种实践,多核芯片可以在给定的时间内执行更多的任务。然而,为了加快单个程序的速度,程序员需要将其并行化,这意味着将原始程序的指令流分解成多个指令 子流 或 线程。简单地说,一组线程可以以任何顺序在多个内核上并发运行,没有任何一个线程会干扰另一个线程的执行。这种实践被称为 多线程编程,是单个程序从多核执行中获得性能提升的最普遍方式。
多核执行的一种常见形式是在 GPU 中。虽然 CPU 由少量快速和复杂的内核组成,但 GPU 依赖大量更简单的内核。通常来讲,GPU 侧重于图形应用,因为图形图像(例如视频中的图像)由数千个像素组成,可以通过一系列简单且预先确定的计算来独立处理。从概念上来说,每个像素可以被分配一个线程,并执行一个简单的「迷你程序」来计算其行为(如颜色和亮度级别)。高度的像素级并行使得开发数千个处理内核变得很自然。因此,在下一轮处理器进化中,CPU 和 GPU 供应商没有加快单个任务的速度,而是利用摩尔定律来增加内核数量,因为他们仍然能够在单个芯片上获得和使用更多的晶体管。

不幸的是,到了 2010 年前后,事情变得更加复杂:登纳德缩放比例定律走到了尽头,因为晶体管的电压接近物理极限,无法继续缩小。虽然以前可以在保持相同功率预算的情况下增加晶体管数量,但晶体管数量翻倍意味着功耗也翻倍。登纳德缩放比例定律的消亡意味着当代芯片将遭遇「利用墙( utilization wall )」。此时,我们的芯片上有多少晶体管并不重要——只要有功耗限制(受芯片冷却能力的限制),我们就不能利用芯片中超过给定部分的晶体管。芯片的其余部分必须断电,这种现象也被称为「暗硅」。
处理器发展第三阶段:加速器时代(2010 年代至今)
暗硅本质上是「摩尔定律终结」的大预演——对处理器制造商来说,时代变得具有挑战性。一方面,计算需求飞速增长:智能手机变得无处不在,而且拥有强大的计算能力,云服务器需要处理越来越多的服务,「最糟糕的是」——人工智能重新登上历史舞台,并以惊人的速度吞噬计算资源。另一方面,在这个不幸的时代,暗硅成为晶体管芯片发展的障碍。因此,当我们比以往任何时候都更需要提高处理能力时,这件事却变得以往任何时候都更加困难。
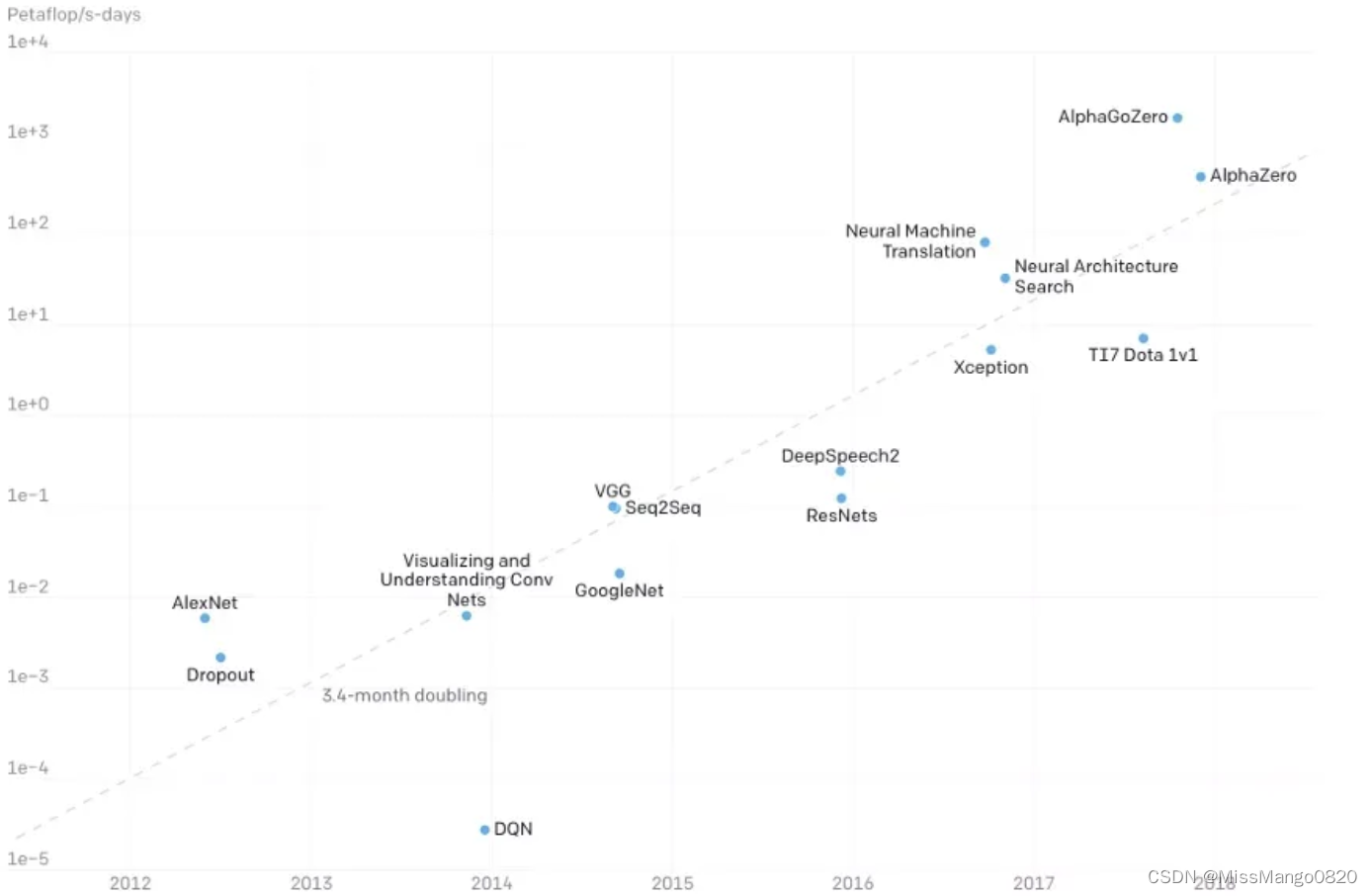
训练 SOTA AI 模型所需的计算量
自从新一代芯片被暗硅束缚以来,计算机行业就开始把精力放到了硬件加速器上。他们的想法是:如果不能再增加晶体管,那就好好利用现有的晶体管吧。具体怎么做呢?答案是:专门化。
传统的 CPU 被设计成通用的。它们使用相同的硬件结构来运行我们所有应用(操作系统、文字处理器、计算器、互联网浏览器、电子邮件客户端、媒体播放器等)的代码。这些硬件结构需要支持大量的逻辑操作,并捕获许多可能的模式和程序诱发的行为。这相当于硬件可用性很好,但效率相当低。如果我们只专注于某些应用,我们就可以缩小问题领域,进而从芯片中去除大量的结构冗余。

通用 CPU vs. 面向特定应用的加速器
加速器是专门面向特定应用或领域的芯片,也就是说,它们不会运行所有应用(例如不运行操作系统),而是在硬件设计层面就考虑一个很窄的范围,因为:
1)它们的硬件结构仅满足特定任务的操作;
2)硬件和软件之间的接口更简单。具体来说,由于加速器在给定的域内运行,加速器程序的代码应该更紧凑,因为它编码的数据更少。
举个例子,假如你要开一家餐厅,但面积、用电预算是有限的。现在你要决定这个餐厅具体做哪些菜,
是比萨、素食、汉堡、寿司全做(a)
还是只做披萨(b)?
如果选 a,你的餐厅确实能满足很多口味不同的顾客,但你的厨师就要做很多菜,而且不见得每种都擅长。此外,你可能还需要买多个冰箱来存储不同的食材,并密切关注哪些食材用完了,哪些变质了,不同的食材还有可能混在一起,管理成本大大提高。
但如果选 b,你就可以雇佣一位顶级的披萨专家,准备少量的配料,再买一台定制的烤箱来做披萨。你的厨房会非常整洁、高效:一张桌子做面团,一张桌子放酱汁和奶酪,一张桌子放配料。但同时,这种做法也有风险:如果明天没有人想吃披萨怎么办?如果大家想吃的披萨用你定制的烤箱做不出来怎么办?你已经花了很多钱打造这个专门化的厨房,现在是进退两难:不改造厨房就可能面临关店,改造又要花一大笔钱,而且改完之后,客户的口味可能又变了。
回到处理器世界:类比上面的例子,CPU 就相当于选项 a,面向特定领域的加速器就是选项 b,店面大小限制就相当于硅预算。你将如何设计你的芯片?显然,现实并没有那么两极分化,而是有一个类似光谱的过渡区域。在这个光谱中,人们或多或少地用通用性来换取效率。早期的硬件加速器是为一些特定领域设计的,如 数字信号处理、网络处理,或者作为主 CPU 的辅助协处理器。
从 CPU 到主要加速应用领域的第一个转变是 GPU。一个 CPU 有几个复杂的处理核心,每个核心都采用各种技巧,比如分支预测器和乱序执行引擎,以尽可能加快单线程作业的速度。GPU 的结构则有所不同。GPU 由许多简单的内核组成,这些内核具有简单的控制流并运行简单的程序。最初,GPU 用于图形应用,如计算机游戏,因为这些应用包含由数千或数百万像素组成的图像,每个像素都可以并行独立计算。一个 GPU 程序通常由一些核函数组成,称为「内核( kernel )」。每个内核都包含一系列简单的计算,并在不同的数据部分(如一个像素或包含几个像素的 patch )执行数千次。这些属性使得图形应用成为硬件加速的目标。它们行为简单,因此不需要分支预测器形式的复杂指令控制流;它们只需要少量操作,因此不需要复杂的算术单元(比如计算正弦函数或进行 64 位浮点除法的单元)。人们后来发现,这些属性不仅适用于图形应用,GPU 的适用性还可以扩展到其他领域,如线性代数或科学应用。如今,加速计算已经不仅仅局限于 GPU。从完全可编程但低效的 CPU 到高效但可编程性有限的 ASIC,加速计算的概念无处不在。

如今,随着越来越多表现出「良好」特性的应用程序成为加速的目标,加速器越来越受关注:视频编解码器、数据库处理器、加密货币矿机、分子动力学,当然还有 人工智能。
是什么让 AI 成为加速目标?
商业可行性
设计芯片是一个费力、耗资的事情——你需要聘请行业专家、使用昂贵的工具进行芯片设计和验证、开发原型以及制造芯片。如果你想使用尖端的制程(例如现在的 5nm CMOS ),耗资将达到数千万美元,不论成功或失败。幸运的是,对于人工智能来说,花钱不是问题。AI 的潜在收益是巨大的,AI 平台有望在不久的将来产生数万亿美元的收入。如果你的想法足够好,你应该能够很容易地为这项工作找到资金。
人工智能无处不在,大型数据中心、智能手机、传感器,机器人 和 自动驾驶汽车 中都有它的身影。每个系统都有不同的现实限制:人们肯定不愿意自动驾驶汽车因为算力太小而无法检测障碍物,也不能接受因为效率低而在训练超大规模预训练模型时每天多花数千美元,AI 的硬件不存在一个芯片适用所有场景的说法,计算需求巨大,每一点效率都意味着花费大量的时间、精力和成本。如果没有适当的加速硬件来满足你的 AI 需求,对 AI 进行实验和发现的能力将受到限制。
可行性
AI 程序具有使其适用于硬件加速的所有属性:
大规模并行 ,大部分计算都花在张量运算上,如卷积或自注意力算子。如果可能,还可以增加 batch size,以便硬件一次处理多个样本,提高硬件利用率并进一步推动并行性。硬件处理器驱动其快速运行能力的主要因素是并行计算。
仅限于少数运算种类:主要是线性代数核的乘法和加法、一些非线性算子,例如模拟突触激活的 ReLU,以及基于 softmax 的分类的指数运算。狭窄的问题空间使我们能够简化计算硬件,专注于某些运算符。
可以在编译时知道 控制流,就像具有已知迭代次数的 for 循环一样,通信和数据重用模式也相当受限,因此可以表征我们需要哪些网络拓扑在不同计算单元和软件定义的暂存存储器之间通信数据,以控制数据的存储和编排方式。
硬件友好
不久之前,如果你想在计算架构领域进行创新,你可能会说:「我有一个新的架构改进的想法,它可以显著地提高一些东西,但是——我需要做的就是稍微改变编程界面并让程序员使用这个功能。」在那个时候这种想法会行不通。程序员的 API 是不可触及的,而且用破坏程序「干净」语义流的低级细节来加重程序员的负担是很难的。
此外,将底层架构细节与面向程序员的代码混合在一起并不是一个好习惯。首先它是不可移植的,因为某些架构特征在芯片代际之间发生变化。其次它可能会被错误地编程,因为大多数程序员对底层硬件没有深入的了解。
虽然你可以说 GPU 和多核 CPU 已经因为多线程(有时甚至是——内存墙)偏离了传统的编程模型,但由于单线程性能早已不是指数级增长,我们只能将希望诉诸于多线程编程,因为这是我们唯一的选择。多线程编程仍然很难掌握,需要大量的教育。幸运的是,当人们编写 AI 程序时,他们会使用神经层和其他定义明确的块来构建计算图。
高级程序代码(例如 TensorFlow 或 PyTorch 中的代码)已经在以一种可以标记并行块并构建数据流图的方式编写。因此理论上,你可以构建丰富的软件库和足够精细的编译器工具链来理解程序的语义并将其有效地降为硬件表示,而无需开发应用程序的程序员做任何参与,让数据科学家做他们的事情,他们可以不在乎任务在哪些硬件上运行。在实践中,编译器完全成熟还需要时间。
这里会介绍 AI加速器 的架构基础,包括指令集 ISA( Instruction Set Architecture )、特定领域的指令集 ISA、超长指令字( VLIW )架构、脉动阵列、可重构处理器、数据流操作、内存处理。
ISA 描述了指令和操作如何由编译器编码,然后由处理器解码和执行,它是处理架构中面向程序员的部分。
常见的例子是 Intel 的 x86,ARM,IBM Power,MIPS 和 RISC-V。
我们可以将 ISA 视为处理器支持所有操作的词汇表。通常,它由算数指令(如加、乘)、内存操作(加载、存储)和控制操作(例如,在 if 语句中使用的分支)组成。

目前看来,CPU ISA 已被分类为精简指令集计算( RISC,Reduced Instruction Set Architecture )和复杂指令集( CISC,Complex Instruction Set Architecture ):
RISC ISA 由简单的指令组成,它们支持少量简单操作(加、乘等)。所有指令的位长相同(例如 32 位),因此,RISC 指令的硬件解码器被认为是最简单的;CISC ISA 中,不同的指令可以有不同的长度,单个指令就可以描述操作和条件的复杂组合。通常,CISC 程序比其等效的 RISC 程序代码占用空间更小,即存储程序指令所需的内存量。这是因为单个 CISC 指令可以跨越多个 RISC 指令,并且可变长度的 CISC 指令被编码为使得最少的位数代表最常见的指令。然而,为了体现复杂指令带来的优势,编译器需要做的足够复杂才能实现。
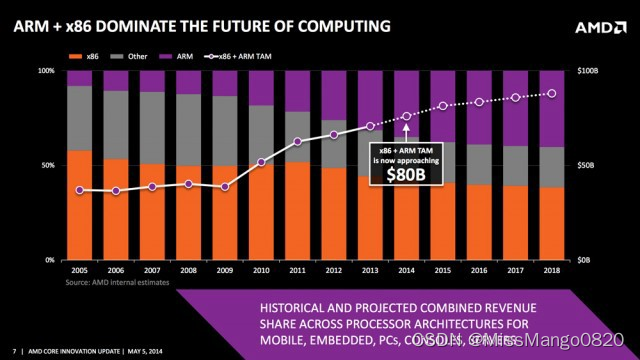
x86(橙色)相对于 ARM(紫色)的计算市场递减率预测。图源:AMD/ExtremeTech
早在 1980 年、1990 年和 2000 年代初期,就有「 RISC 与 CISC 之战 」,基于 x86 的 Intel 和 AMD 主要专注于 CISC ,而 ARM 专注于 RISC。其实每种方法都有利弊,但最终,由于基于 ARM 的智能手机的蓬勃发展,RISC 在移动设备中占据了上风。现在,随着亚马逊基于 ARM 的 AWS Graviton 处理器等的发布,RISC 在云中也开始占据主导地位。
RISC 和 CISC 是用于构建通用处理器的通用指令集架构。但在加速器的背景下,CISC 和 RISC 相比,RISC 具有简单性和简洁性,更受欢迎(至少对于智能手机而言)。

45nm CMOS 处理器中执行 ADD 指令能耗。图源:M.Horowitz ISSCC 2014
很多 AI 加速器公司采用特定领域的 ISA。鉴于现有的精简指令集架构(以及潜在的处理核心),可以通过仅支持目标应用领域所需的指令子集来进一步减少它。特定领域的 ISA 进一步简化了处理内核和硬件 / 软件接口,以实现高效的加速器设计。在通常由线性代数和非线性激活组成的 AI 应用中,不需要许多「奇异」类型的运算。因此,ISA 可以设计为支持相对较窄的操作范围。
使用现有 RISC ISA 的简化版本的好处是,一些 RISC 公司(如 ARM )出售现有 IP,即支持完整 ISA 的现有处理内核,可用作定制处理的基线,用于加速器芯片的核心。这样,加速器供应商就可以依赖已经过验证并可能部署在其他系统中的基线设计;这是从头开始设计新架构更可靠的替代方案,对于工程资源有限、希望获得现有处理生态系统支持或希望缩短启动时间的初创公司尤其有吸引力。
VLIW( Very Long Instruction Word )架构是由 Josh Fisher 在 20 世纪 80 年代早期提出,当时集成电路制造技术和高级语言编译器技术出现了巨大的进步。其主要思想是:
CPU 中有对应数量的 ALU 完成相应的指令操作;就像特定领域的 ISA 可以被认为是 RISC 思想(更简单的指令,支持的操作较少)的扩展,同样地,我们可以将 CISC 进行多个操作组合成单个复杂指令扩展,这些架构被称为超长指令字 ( VLIW )。
VLIW 架构由 算术 和 存储单元 的异构数据路径阵列组成。异构性源于每个单元的时序和支持功能的差异:例如,计算简单逻辑操作数的结果可能需要 1 - 2 个周期,而内存操作数可能需要数百个周期。

一个简单的VLIW数据路径框图
VLIW 架构依赖于一个编译器,该编译器将多个操作组合成一个单一且复杂的指令,该指令将数据分派到数据路径阵列中的单元。
例如,在 AI 加速器中,这种指令可以将 张量 指向矩阵乘法单元,并且 并行 地将数据部分发送到 向量单元 和 转置单元 等等。
VLIW 架构的优势在于,通过指令编排处理器数据路径的成本可能显着降低;缺点是我们需要保证数据路径中各个单元之间的工作负载得到平衡,以避免资源未得到充分利用。因此,要实现高性能执行,编译器需要能够进行复杂的静态调度。更具体地说,编译器需要分析程序,将数据分配给单元,知道如何对不同的数据路径资源计时,并以在给定时间利用最多单元的方式将代码分解为单个指令。归根结底,编译器需要了解不同的数据路径结构及其时序,并解决计算复杂的问题,以提取高指令级并行 ( ILP ) 并实现高性能执行。
脉动阵列 由 H. T. Kung 和 C. E. Leiserson 于 1978 年引入。2017 年,Google 研发的 TPU 采用脉动阵列作为计算核心结构,使其又一次火了起来。
脉动阵列 本身的核心概念就是让数据在运算单元的阵列中进行流动,减少访存次数,并且使得结构更加规整,布线更加统一,提高频率。整个阵列以「节拍」方式运行,每个 PE ( processing elements )在每个计算周期处理一部分数据,并将其传达给下一个互连的 PE。

矩阵通过 4x4 脉动网。图源:NJIT
脉动结构 是执行矩阵乘法的有效方式( DNN 工作负载具有丰富的矩阵乘法)。谷歌的 TPU 是第一个使用 AI 的脉动阵列。因此,在这之后,其他公司也加入了脉动阵列行列,在自家加速硬件中集成了脉动执行单元,例如 NVIDIA 的 Tensor Core。
我们所熟悉的处理器包括 CPU、GPU 和一些加速器,它们的流程依赖于预先确定数量的算术单元和运行时行为,这些行为是在运行时根据执行的程序指令确定的。但是,还有其他类别的处理器称为「 可重构处理器 」。

基础 FPGA 架构。图源:Xilinx
可重构处理器由包含互连计算单元、内存单元和控制平面的复制阵列组成。为了运行程序,专用编译器会构建一个配置文件,这个文件包含设置数组中每个元素行为的控制位。最常见的可重构处理器类别是现场可编程门阵列 ( FPGA )。
FPGA 通过启用位级可配置性来支持广泛的计算范围:可以配置算术单元来实现对任意宽度数量进行操作的功能,并且可以融合片上存储块以构建不同大小的存储空间。
可重构处理器 FPGA 的一个优点是它们可以对用硬件描述语言 ( HDL ) 编写的芯片设计进行建模;这使公司能够在几个小时内测试他们的设计,而不是流片芯片,这个过程可能需要几个月甚至几年的时间。
FPGA 的缺点是细粒度的位级可配置性效率低下,典型的编译时间可能需要数小时,并且所需的额外线路数量占用大量空间,而且在能量上也是浪费。因此,FPGA 通常用于在流片之前对设计进行原型设计,因为由此产生的芯片将比其 FPGA 同类产品性能更高、效率更高。

处理器架构的性能、功耗和灵活性的比较。图源:ACM Computing Surveys
虽然 FPGA 在性能和功耗方面存在问题,但可重构性仍然是 AI 加速器一个非常理想的特性。一般来说,一个芯片的设计周期大约是 2 - 3 年,每天会有数不清的实验依赖芯片运行。但是,一个近期制造完成并花费数百万美元的芯片,往往是基于两年多前存在的 AI 模型的假设设计的,可能与当前的模型无关。
为了将高效、性能和可重构性结合起来,一些初创公司设计了可重构处理器,它们被称为 CGRA( Coarse-Grained Reconfigurable Arrays )。
CGRA 在 1996 年被提出,与 FPGA 相比,CGRA 不支持位级可配置性,并且通常具有更严格的结构和互连网络。
CGRA 具有高度的可重构性,但粒度比 FPGA 更粗。
数据流( Dataflow )已经有一段时间了,起源可以追溯到 1970 年代。不同于传统的冯诺依曼模型,它们是计算的另一种形式。
在传统的冯诺依曼模型中,程序被表示为一系列指令和临时变量。但在数据流模型中,程序被表示为数据流图( DFG,dataflow graph ),其中输入数据的一部分是使用预定的操作数( predetermined operands )计算的,计算机中的数据根据所表示的图一直「流动」到输出,这一过程由类似图形的硬件计算而来。值得注意的是,硬件本质上是并行的。
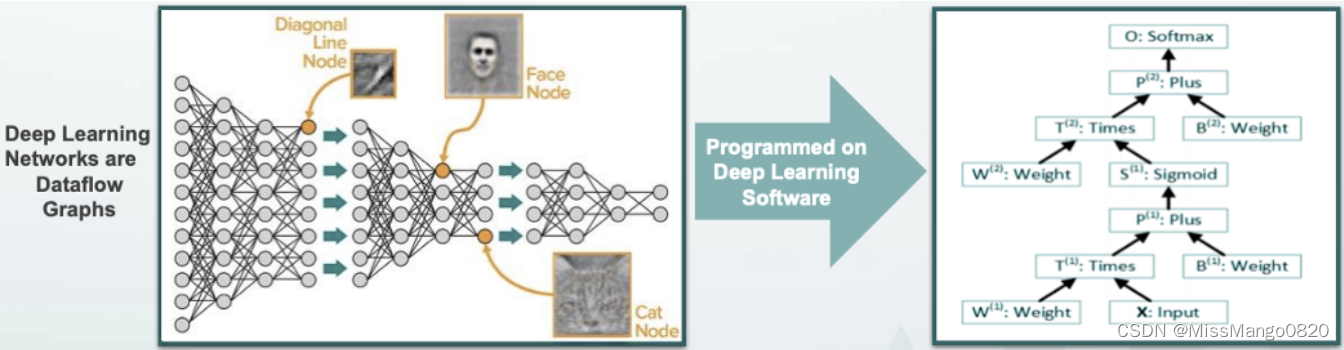
深度学习软件到数据流图映射的例子
在 AI 加速器的背景下,执行数据流有以下两个优势:
architecturally-agnostic )表示。它抽象出所有源于架构本身的不必要的约束(例如,指令集支持的寄存器或操作数等),并且程序的并行性仅受计算问题本身的固有并行维度的限制,而不是受计算问题本身的并行维度限制。研究人员在提高加速器的计算吞吐量 ( FLOP ) 上花费了大量精力,即芯片(或系统)每秒提供的最大计算数量。然而,片上计算吞吐量并不是全部,还有内存宽带,因其片上计算速度超过片外内存传输数据的速度,造成性能瓶颈。
此外,从能量角度来看, AI 模型中存在着很高的内存访问成本,将数据移入和移出主存储器比进行实际计算的成本高几个数量级。

45nm CMOS 技术的典型内存和计算成本。图源:ISSCC 2014 / M.Horowitz
AI 加速器公司为降低内存成本常采用「近数据处理,near-data processing 」方法。这些公司设计了小型且高效的软件控制存储器(也称为便笺存储器,Scratchpad Memory ),它们将处理过的部分数据存储在核心芯片上,用于高速和低功耗并行处理。通过减少对片外存储器(大而远存储器)的访问次数,这种方法在减少访问数据时间和能源成本方面迈出了第一步。
近数据处理的极端是 PIM( Processing-in-Memory ),这种技术可以追溯到 1970 年代。在 PIM 系统中,主内存模块是用 数字逻辑元件(如 加法器 或 乘法器 )制造的,计算处理位于内存内部。因此,不需要将存储的数据传送到中间线缓冲器。商业化的 PIM 解决方案仍然不是很常见,因为制造技术和方法仍然稳定,而且设计通常被认为是僵化的。
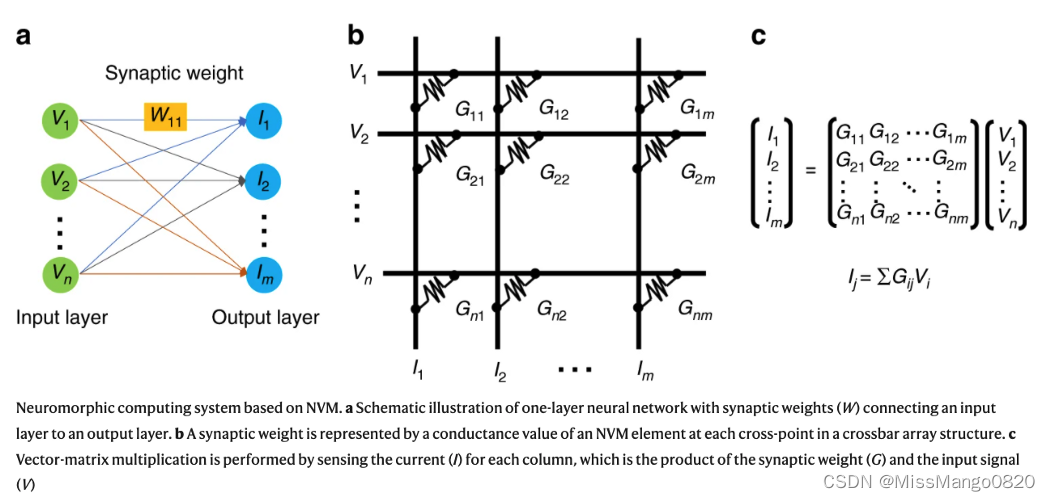
基于点积模拟处理的神经形态计算。图源:Nature Communications
许多 PIM 依赖于模拟计算( analog computations )。具体来说,在 AI 应用中,加权点积在模拟域中的计算方式类似于大脑处理信号的方式,这就是为什么这种做法通常也被称为「神经形态计算」的原因。由于计算是在模拟域中完成的,但输入和输出数据是数字的,神经形态解决方案需要特殊的模数和数模转换器,但这些在面积和功率上的成本都很高。
这一部分主要介绍 AI加速器 相关公司。
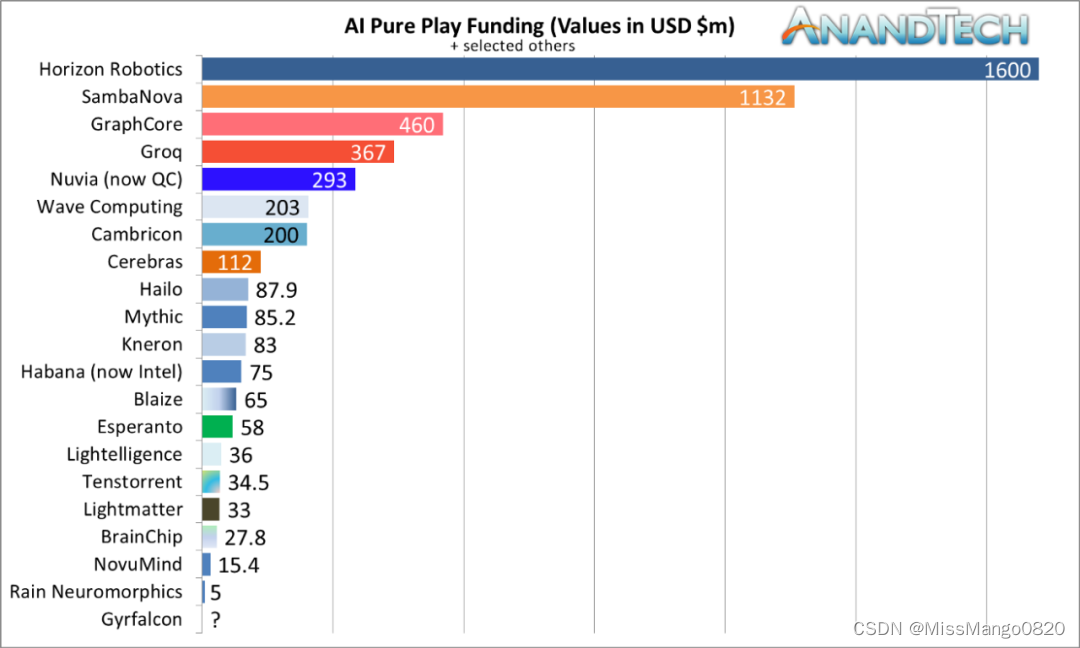
AI 硬件初创公司 - 截至 2021 年 4 月的总融资。图源:AnandTech
此外,还有一些有趣的收购故事。2016 年,英特尔以 3.5 亿美元收购了 Nervana,2019 年底又收购了另一家名为 Habana 的人工智能初创公司,该公司取代了 Nervana 提供的解决方案。非常有意思的是,英特尔为收购 Habana 支付了 20 亿美元的巨款,比收购 Nervana 多好几倍。
AI 芯片领域,或者更准确地说,AI 加速器领域(到目前为止,它已经不仅仅是芯片)包含了无数的解决方案和方法,所以让我们回顾这些方法的主要原则。
英伟达成立于 1993 年,是最早研究加速计算的大公司之一。英伟达一直是 GPU 行业的先驱,后来为游戏机、工作站和笔记本电脑等提供各种 GPU 产品线,已然成为世界领导者。正如在之前的文章中所讨论的,GPU 使用数千个简单的内核。相比来说,CPU 使用较少的内核。
最初 GPU 主要用于图形,但在 2000 年代中后期左右,它们被广泛用于分子动力学、天气预报和物理模拟等科学应用。新的应用程序以及 CUDA 和 OpenCL 等软件框架的引入,为将新领域移植到 GPU 铺平了道路,因此 GPU 逐渐成为通用 GPU ( General-Purpose GPU ),简称 GPGPU。
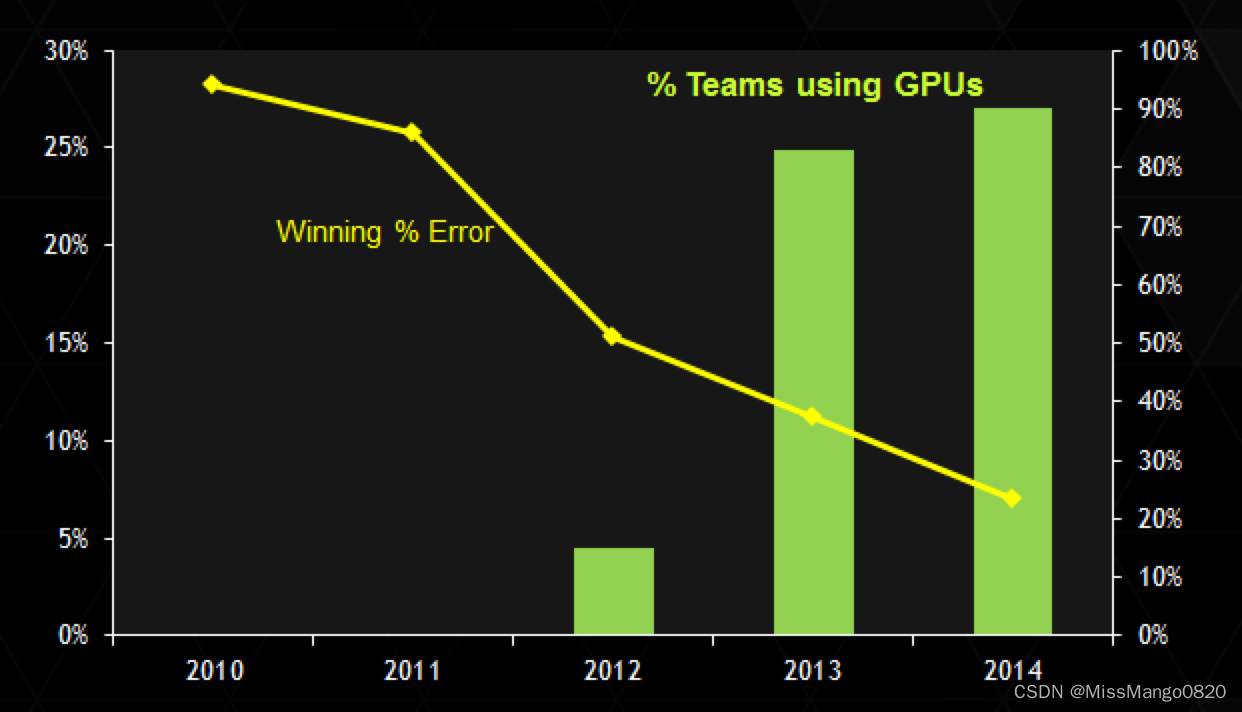
ImageNet 挑战赛:使用 GPU 的获胜误差和百分比。图源:英伟达
从历史上看,人们可能会说英伟达是幸运的,因为当 CUDA 流行和成熟时,现代 AI 就开始了。或者有人可能会争辩说,正是 GPU 和 CUDA 的成熟和普及使研究人员能够方便高效地开发 AI 应用程序。无论哪种方式,历史都是由赢家书写的 —— 事实上,最有影响力的 AI 研究,如 AlexNet、ResNet 和 Transformer 都是在 GPU 上实现和评估的,而当 AI 寒武纪爆发时,英伟达处于领先地位。

SIMT 执行模型。图源:英伟达
GPU 遵循单指令多线程 ( SIMT ) 的编程模型,其中相同的指令在不同的内核 / 线程上并发执行,每条指令都按照其分配的线程 ID 来执行数据部分。所有内核都以帧同步( lock-step )方式运行线程,这极大地简化了控制流。
另一方面,SIMT 在概念上仍然是一个多线程类 c 的编程模型,它被重新用于 AI,但它并不是专门为 AI 设计的。由于神经网络应用程序和硬件处理都可以被描述为计算图,因此拥有一个捕获图语义的编程框架会更自然、更有效。
虽然从 CPU 转向 GPU 架构是朝着正确方向迈出的一大步,但这还不够。GPU 仍然是传统架构,采用与 CPU 相同的计算模型。
CPU 受其架构限制,在科学应用等领域逐渐被 GPU 取代。
因此,通过联合设计专门针对 AI 的计算模型和硬件,才有希望在 AI 应用市场占有一席之地。
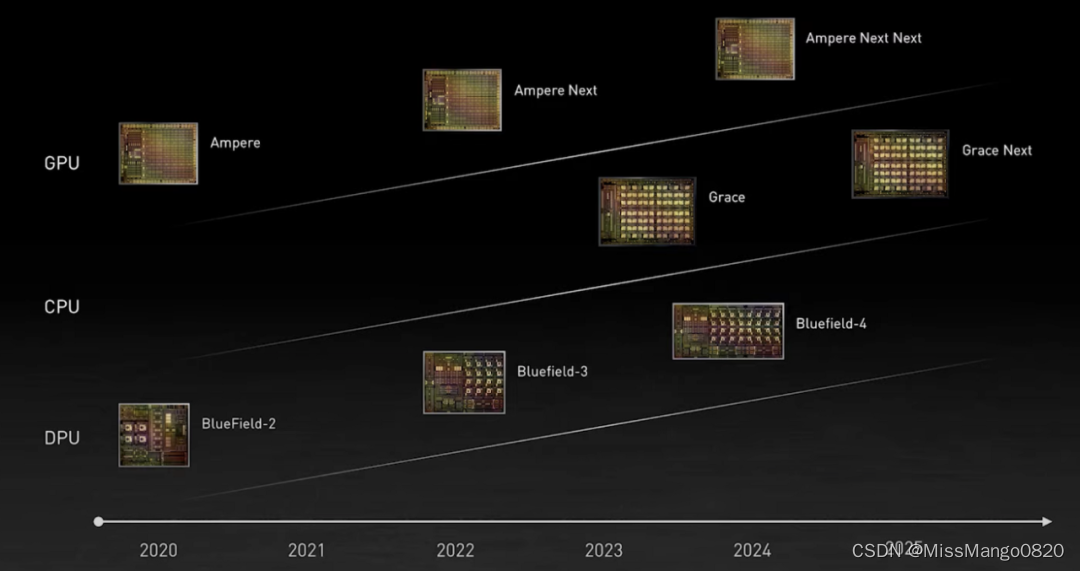
英伟达的GPU、CPU和DPU路线图。图源:英伟达
英伟达主要从两个角度发展 AI:
1)引入 Tensor Core;
2)通过收购公司。比如以数十亿美元收购 Mellanox ,以及即将对 ARM 的收购。
ARM-NVIDIA 首次合作了一款名为「 Grace 」的数据中心 CPU,以美国海军少将、计算机编程先驱 Grace Hopper 的名字命名。作为一款高度专用型处理器,Grace 主要面向大型数据密集型 HPC 和 AI 应用。新一代自然语言处理模型的训练会有超过一万亿的参数。基于 Grace 的系统与 NVIDIA GPU 紧密结合,性能比目前最先进的 NVIDIA DGX 系统(在 x86 CPU 上运行)高出 10 倍。
Grace 获得 NVIDIA HPC 软件开发套件以及全套 CUDA 和 CUDA-X 库的支持,可以对 2000 多个 GPU 应用程序加速。
Cerebras 成立于 2016 年。随着 AI 模型变得越来越复杂,训练时需要使用更多的内存、通信和计算能力。因此,Cerebras 设计了一个晶圆级引擎 ( WSE ),它是一个比萨盒大小的芯片。

Andrew Feldman。图源:IEEE spectrum
典型的处理芯片是在一块称为晶圆的硅片上制造的。作为制造过程的一部分,晶圆被分解成称为芯片的小块,这就是我们所说的处理器芯片。一个典型的晶圆可容纳数百甚至数千个这样的芯片,每个芯片的尺寸通常在 10 平方毫米到 830 平方毫米左右。NVIDIA 的 A100 GPU 被认为是最大的芯片,尺寸 826 平方毫米,可以封装 542 亿个晶体管,为大约 7000 个处理核心提供动力。

Cerebras WSE-2 与 NVIDIA A100 规格比较。图注:BusinessWire
Cerebras 不仅在单个大芯片上提供超级计算机功能,而且通过与学术机构和美国国家实验室的合作,他们还提供了软件堆栈和编译器工具链。其软件框架基于 LAIR( Linear-Algebra Intermediate Representation )和 c++ 扩展库,初级程序员可以使用它来编写内核(类似于 NVIDIA 的 CUDA ),还可用于无缝降低来自 PyTorch 或 TensorFlow 等框架的高级 Python 代码。
总而言之,Cerebras 的非传统方法吸引了许多业内人士。但是更大的芯片意味着内核和处理器因缺陷而导致失败的可能性更高,那么如何控制制造缺陷、如何冷却近百万个核心、如何同步它们、如何对它们进行编程等等都需要逐个解决,但有一点是肯定的,Cerebras 引起了很多人的注意。
GraphCore 是首批推出商业 AI 加速器的初创公司之一,这种加速器被称为 IPU( Intelligent Processing Unit )。他们已经与微软、戴尔以及其他商业和学术机构展开多项合作。
目前,GraphCore 已经开发了第二代 IPU,其解决方案基于一个名为 Poplar 的内部软件堆栈。Poplar 可以将基于 Pytorch、Tensorflow 或 ONNX 的模型转换为命令式、可以兼容 C++ 的代码,支持公司提倡的顶点编程( vertex programming )。与 NVIDIA 的 CUDA 一样,Poplar 还支持低级 C++ 编程以实现更好的潜在性能。

第二代IPU芯片图。图源GraphCore
IPU 由 tiled 多核设计组成,tiled 架构由 MIT 于 2000 年代初研发,该设计描述了复制结构的 2D 网格,每个网格都结合了网络交换机、小型本地内存和处理核心。第一代 IPU 有 1216 个 tile,目前第二代 IPU 有 1472 个 tile。每个 IPU 内核最多可以执行 6 个线程,这些线程是包含其专有指令集架构 ( ISA ) 的代码流。
IPU 采用的是大规模并行同构众核架构。其最基本的硬件处理单元是 IPU-Core,它是一个 SMT 多线程处理器,可以同时跑 6 个线程,更接近多线程 CPU,而非 GPU 的 SIMD/SIMT 架构。IPU-Tiles 由 IPU-Core 和本地的存储器( 256KB SRAM )组成,共有 1216 个。因此,一颗 IPU 芯片大约有 300MB 的片上存储器,且无外部 DRAM 接口。连接 IPU-Tiles 的互联机制称作 IPU-Exchange,可以实现无阻塞的 all-to-all 通信,共有大约 8TB 的带宽。最后,IPU-Links 实现多芯片互联,PCIe 实现和 Host CPU 的连接。
IPU 采用的是大规模并行同构众核架构。其最基本的硬件处理单元是 IPU-Core,它是一个 SMT 多线程处理器,可以同时跑 6 个线程,更接近多线程 CPU,而非 GPU 的 SIMD/SIMT 架构。IPU-Tiles 由 IPU-Core 和本地的存储器( 256KB SRAM )组成,共有 1216 个。因此,一颗 IPU 芯片大约有 300MB 的片上存储器,且无外部 DRAM 接口。连接 IPU-Tiles 的互联机制称作 IPU-Exchange,可以实现无阻塞的 all-to-all 通信,共有大约 8TB 的带宽。最后,IPU-Links 实现多芯片互联,PCIe 实现和 Host CPU 的连接。
Wave Computing、SambaNova 和 SimpleMachines 是三家推出加速器芯片的初创公司。其中 Wave Computing 成立于 2008 年,其使命是「通过可扩展的实时 AI 解决方案,从边缘到数据中心革新深度学习」,该公司由 Dado Banatao 和 Pete Foley 创立。一段时间以来,它一直处于隐身模式,从各种来源获得资金。
Wave Computing 的核心产品是数据流处理器单元( DPU ),采用非冯诺依曼架构的软件可动态重构处理器 CGRA( Coarse grain reconfigurable array / accelerator )技术,适用于大规模异步并行计算问题。2019 年前后,Wave Computing 针对边缘计算市场的算力需求,将 MIPS 技术与 Wave 旗下 WaveFlow 和 WaveTensor 技术相结合,推出 TritonAI 64 IP 平台。但不幸的是,它在 2020 年申请了破产保护。

基于时间的DPU核映射。图源:Wave Computing
SambaNova 成立于 2017 年底,自那以来,该公司获得了由 Google Ventures,Intel Capital 和 Blackrock 领导的三轮融资以及在美国能源部的 Laurence Livermore 和 Los Alamos 的部署。他们现在已经可以为一些客户提供新产品。

SambaNova的RDU框图
SambaNova 正在为数据中心构建芯片和软件栈,目标是用 AI 进行推理和训练。其架构的核心是可重构数据流单元( RDU,reconfigurable dataflow unit )。RDU 芯片包含一组计算单元(称为 PCU )和暂存器存储单元(称为 PMU ),它们以 2D 网格结构组织起来,并与 NoC 交换机连接。RDU 通过一组称为 AGU 和 CU 的单元结构访问芯片外存储器。
SambaNova 的软件堆栈(称为 Sambaflow )采用高级 Python 应用程序(例如 PyTorch、TensorFlow )并将它们降低为可以在编译时对芯片 PCU、PMU、AGU 和 CU 进行编程的表示。SambaNova 展示了 RDU 架构可以运行复杂的 NLP 模型、推荐模型和高分辨率视觉模型。
SimpleMachines 由威斯康星大学的一群学术研究人员于 2017 年创立。该研究小组一直在探索依赖于结合冯诺依曼(逐条指令)和非冯诺依曼(即数据流)执行的异构数据路径的可重构架构。
该公司提供的数据均参考了在顶级学术会议和期刊发表的原创研究论文。指导架构原则有点类似于 SambaNova 正在做的事情,即开发一个可重新配置的架构,以支持非常规编程模型,实现能够应对高度变化的 AI 应用程序空间的灵活执行。
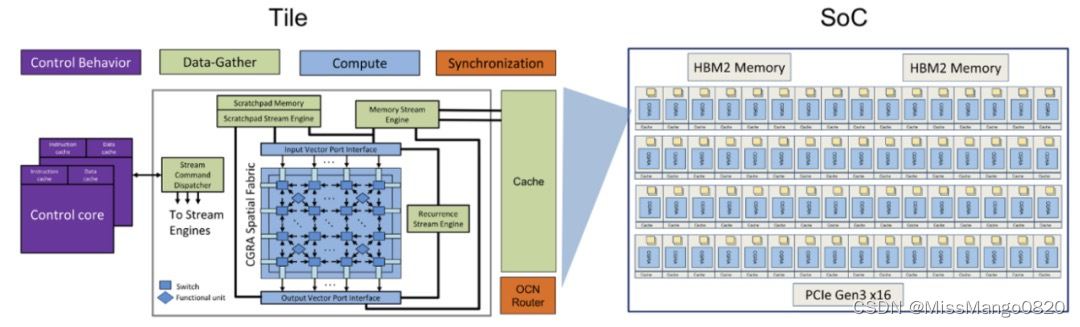
SimpleMachines的Mozart芯片。图源:SimpleMachine
该公司的首个 AI 芯片是 Mozart,该芯片针对推理进行了优化,在设计中使用了 16 纳米工艺,HBM2 高带宽内存和 PCIe Gen3x16 尺寸。2020 年,SimpleMachine 发布了第一代加速器,该加速器基于 Mozart 芯片,其由一个可配置的 tile 数组组成,它们依赖于控制、计算、数据收集等的专业化。
世界上首个专门为 AI 量身定制的处理器之一是张量处理单元( TPU ),也称张量处理器,是 Google 开发的专用集成电路( ASIC ),专门用于加速机器学习。自 2015 年起,谷歌就已经开始在内部使用 TPU,并于 2018 年将 TPU 提供给第三方使用,既将部分 TPU 作为其云基础架构的一部分,也将部分小型版本的 TPU 用于销售。

第一代 TPU 体系架构。图源:arXiv
第一代 TPU 是一个 8 位矩阵乘法的引擎,使用复杂指令集,并由主机通过 PCIe 3.0 总线驱动,它采用 28 nm 工艺制造。TPU 的指令向主机进行数据的收发,执行矩阵乘法和卷积运算,并应用激活函数。
第二代 TPU 于 2017 年 5 月发布,值得注意的是,第一代 TPU 只能进行整数运算,但第二代 TPU 还可以进行浮点运算。这使得第二代 TPU 对于机器学习模型的训练和推理都非常有用。谷歌表示,这些第二代 TPU 将可在 Google 计算引擎上使用,以用于 TensorFlow 应用程序中。
第三代 TPU 于 2018 年 5 月 8 日发布,谷歌宣布第三代 TPU 的性能是第二代的两倍,并将部署在芯片数量是上一代的四倍的 Pod 中。
第四代 TPU 于 2021 年 5 月 19 日发布。谷歌宣布第四代 TPU 的性能是第三代的 2.7 倍,并将部署在芯片数量是上一代的两倍的 Pod 中。与部署的第三代 TPU 相比,这使每个 Pod 的性能提高了 5.4 倍(每个 Pod 中最多装有 4,096 个芯片)。
Groq
谷歌在云产品中提供了 TPU,他们的目标是满足谷歌的 AI 需求并服务于自己的内部工作负载。因此,谷歌针对特定需求量身定制了 TPU。
2016 年,一个由 TPU 架构师组成的团队离开谷歌,他们设计了一种与 TPU 具有相似基线特征的新处理器,并在一家名为 Groq 的新创业公司中将其商业化。

Groq TSP 执行框图。图源:Groq
Groq 的核心是张量流处理器( TSP )。TSP 架构与 TPU 有很多共同之处:两种架构都严重依赖脉动阵列来完成繁重的工作。与第一代 TPU 相比,TSP 增加了向量单元和转置置换单元(在第二代和第三代 TPU 上也可以找到)。

Groq VLIW指令集和描述。图源:Groq
Habana
Habana 成立于 2016 年初,是一家专注于数据中心训练和推理的 AI 加速器公司。Habana 已推出云端 AI 训练芯片 Gaudi 和云端 AI 推理芯片 Goya。
Goya 处理器已实现商用,在极具竞争力的包络功率中具有超大吞吐量和超低的实时延迟,展现出卓越的推理性能。Gaudi 处理器旨在让系统实现高效灵活的横向、纵向扩展。目前 Habana 正在为特定超大规模客户提供样品。
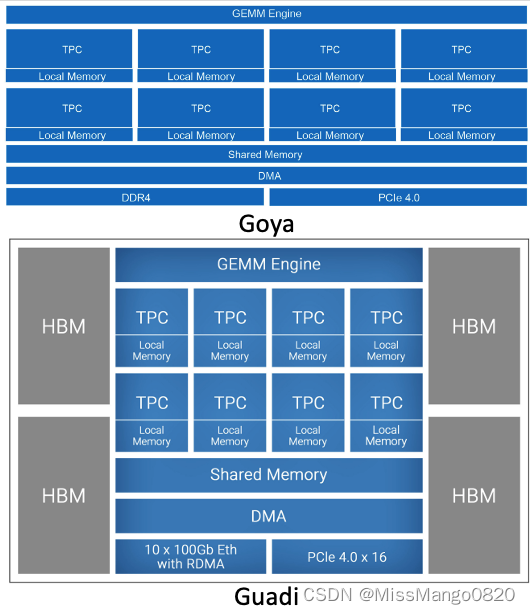
Goya、 Gaudi 架构图。图注:Habana
Goya 和 Gaudi 芯片具有相似架构,它们都依赖于 GEMM 引擎,该引擎是一个脉动矩阵乘法单元,与一组 tile 并排工作。每个 tile 包含一个本地软件控制的暂存器内存和一个张量处理核心( TPC ),具有不同精度的矢量计算单元,即它们可以计算 8 位、16 位或 32 位的矢量化操作。TPC 和 GEMM 引擎通过 DMA 和共享内存空间进行通信,并通过 PCIe 与主机处理器进行通信。
Esperanto
Esperanto 成立于 2014 年,并在相当长一段时间内一直处于隐身模式,直到 2020 年底才宣布他们的第一款产品 ET-SoC-1 芯片,其基于台积电 7nm 工艺构建的 SoC 上集成了 1000 多个 RISC-V 内核、160M BYTE 的 SRAM 和超过 240 亿个晶体管,是该公司 AI 加速器系列的第一款产品。ET-SoC-1 是一款推理加速器,预计在今年投产。
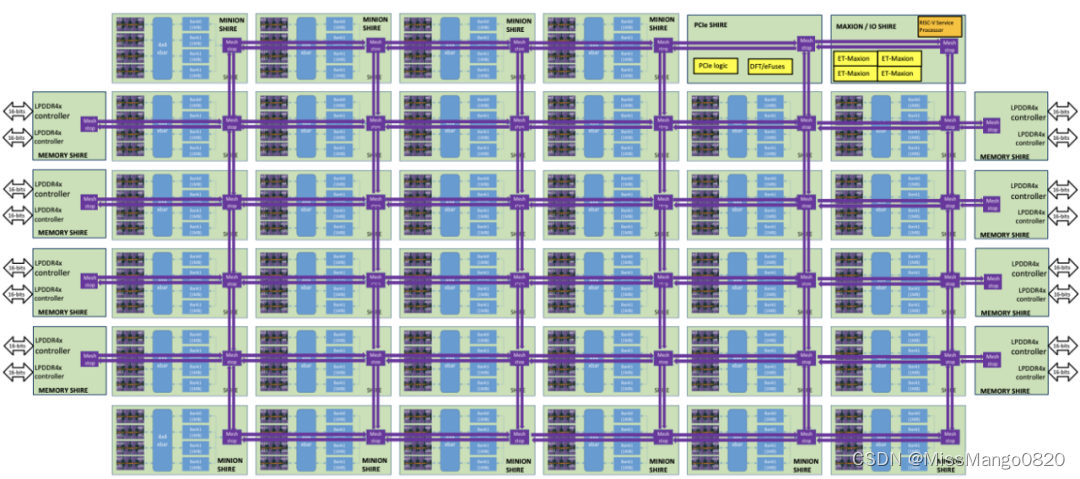
Esperanto 的 ET-SoC-1 的架构图。图源:Esperanto/HotChips
TensTorrent
TensTorrent 成立于 2016 年,总部位于加拿大多伦多,目前估值 10 亿美元,这是一家计算公司,开发旨在帮助更快和适应未来算法的处理器。
TensTorrent 提供的芯片系列不仅针对数据中心,也针对小型平台,此外,他们还提供 DevCloud。
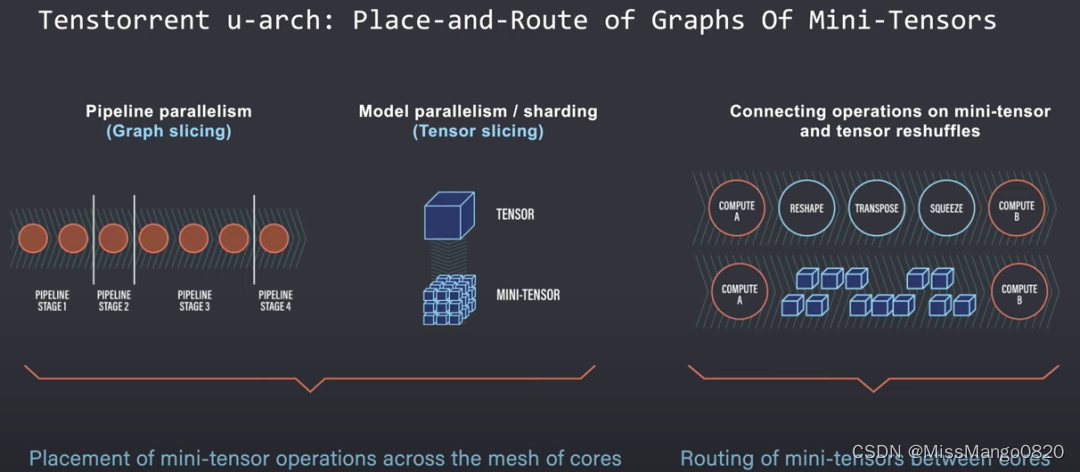
TensTorrent:图的并行性与张量切片。图源:YouTube/TensTorrent

TensTorrent 核心。图源:YouTube/TensTorrent
Mythic 是 AI 硬件领域最早的初创公司之一,它成立于 2012 年。迈克・亨利(Mike Henry)和戴夫・菲克(Dave Fick)为公司的核心创始人,他们分别担任 Mythic 公司的董事长和 CTO。该公司非常重视具备能源效率和成本更低的模拟技术,Mythic 提出了如何在模拟电路中使用较小的非数字电路电流来降低能量的消耗。

矩阵乘法运算中的权重和输入 / 输出数据差分。图源:Mythic
2020 年底,Mythic 推出了其第一代 AI 芯片 M1108 AMP。与很多 AI 芯片不同,M1108 基于更加成熟的模拟计算技术,而非数字计算。这提高了 M1108 的能效,也使网络边缘设备访问更加容易。
Mythic 还推出了一个模拟计算引擎 ( ACE,Analog Compute Engine ),它使用闪存而不是 DRAM 来存储权重。本质上,它们不是从内存中获取输入和权重数据,而是将输入数据传输到权重闪存,并将其转换为模拟域,在模拟域中执行 MAC (multiply-and-accumulate)计算,并将其转换回以获取输出数据,从而避免从内存中读取和传输权重成本。
LightMatter 是一家诞生于 MIT 的初创公司,该公司押注于一种用光子而非电子执行运算的计算机芯片。这种芯片从根本上与传统的计算机芯片相区分,有望成为能够满足 AI「饥饿」的有力竞争者。
LightMatter 首席执行官尼克・哈里斯(Nick Harris)曾说:「要么我们发明的新计算机继续下去,要么人工智能放慢速度。」

光子学与电子学计算属性。图源:HotChips/LightMatter
LightMatter 设计了一种基于 脉动阵列 的方法,通过使用编码为光信号波中不同相位的相移来操纵光子输入信号,以执行乘法和累加操作。由于光子学数据以光速流动,LightMatter 芯片以非常高的速度执行矩阵和矢量化运算,并且功率可降低几个数量级。
LightMatter 在 2021 年开始发售其首款基于光子的 AI 芯片 —— Envise,并为常规数据中心提供包含 16 个这种芯片的刀锋服务器。该公司目前已从 GV(前 Google Ventures )、Spark Capital 和 Matrix Partners 筹集到了 2200 万美元。
LightMatter 声称,他们推出的 Envise 芯片的运行速度比最先进的 Nvidia A100 AI 芯片快 1.5 至 10 倍,具体根据任务的不同有所差异。以运行 BERT 自然语言模型为例,Envise 的速度是英伟达芯片的 5 倍,并且仅消耗了其六分之一的功率。

Envise。图源:LightMatter
NeuReality 是一家于 2019 年在以色列成立的初创公司,由 Tanach 、 Tzvika Shmueli 和 Yossi Kasus 共同创立。
2021 年 2 月,NeuReality 推出了 NR1-P,这是一个以 AI 为中心的推理平台。2021 年 11 月,NeuReality 宣布与 IBM 建立合作伙伴关系,其中包括许可 IBM 的低精度 AI 内核来构建 NR1,这是一种非原型生产级服务器,与 FPGA 原型相比, AI 应用程序效率更高。

我正在学习Ruby,遇到了inject。我正处于理解它的风口浪尖,但当我是那种需要真实世界的例子来学习一些东西的人时。我遇到的最常见的例子是人们使用inject来添加一个(1..10)范围的总和,我不太关心这个。这是一个任意的例子。在实际程序中我会用它做什么?我正在学习,所以我可以继续使用Rails,但我不必有一个以Web为中心的示例。我只需要一些我可以全神贯注的目标。谢谢大家。 最佳答案 inject有时可以通过它的“其他”名称reduce更好地理解。它是一个对Enumerable进行操作(迭代一次)并返回单个值的函数。它有许多有
我有33个规范以大约5秒的速度运行,以这种速度运行会导致测试套件变慢。我追踪到请求规范(4秒以上),因为模型规范只用了一小部分时间。我已经检查过,我的请求规范没有任何过于复杂或不必要的东西,所以我不知道该去哪里让它们更快,而不是只在推送代码之前运行它们以确保一切正常.加快请求规范的最佳方法是什么? 最佳答案 我使用Spork来加速我的测试。它保持整个环境加载以赢得时间。看看这个博客:http://ykyuen.wordpress.com/2010/12/14/rails-running-rspec-with-spork-test-s
有没有办法制作一个简单的守卫watch?我想在特定目录中的文件更改时运行rake任务,并且完成所有这些步骤对于这个一次性任务来说太多了。https://github.com/guard/guard/wiki/Create-a-guard我尝试将它添加到Guardfile中,但它不起作用。guard:docdowatch(%r{^documentation}){"rakedoc:build"}endwatch("/documentation"){"rakedoc:build"}那么当文件更新为guard时,您是否知道一种运行rake任务的简单方法?? 最佳答案
2022年10月21日星期五【数据指标】加密货币总市值:$0.95万亿BTC市值占比:38.51%恐慌贪婪指数:23极度恐慌 【今日快讯】1、【政讯】1.1.1、美联储布拉德:市场预期美联储11月会加息75个基点1.1.2、美联储哈克:将维持加息一段时间1.2、美国10年期国债收益率触及4.197%,为2008年6月以来最高1.3、法国数字转型部长:政府将专注于DeFi和Web31.4、巴西ATM机将于11月3日起支持USDT1.5、美众议院副议长将于11月初加入a16zCrypto担任政府事务主管1.6、香港数字资产托管机构FirstDigitalTrust首席执行官:香港仍是安全
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
我有一个适用于事件/监听器模型的应用程序。发布了几种不同类型的数据(事件),然后许多不同的事情可能需要也可能不需要对该数据(监听器)采取行动。监听器的发生没有特定的顺序,每个监听器将决定是否需要对事件采取行动。Rails应用程序有哪些工具可以完成此任务?我希望自己不必这样做(尽管我可以。这没什么大不了的。)编辑:观察者模式可能是更好的选择 最佳答案 查看EventMachine.它是一个非常流行的Ruby事件处理库。它看起来相当不错,而且很多其他库似乎都在利用它(Cramp)。这是一个很好的介绍:http://rubylearnin
我现在正在努力学习Ruby和RubyonRails。我正在学习LearningRails,第1版,但我很难理解其中的一些代码。我通常使用C、C++或Java工作,因此Ruby对我来说是一个很大的改变。我目前对数据库迁移器的以下代码块感到困惑:defself.upcreate_table:entriesdo|t|t.string:namet.timestampsendendt变量来自哪里?它实际上代表什么?它有点像for(i=0;i另外,:entries是在什么地方定义的?(entries是我的Controller的名称,但是这个函数怎么知道的?) 最佳答案
一、什么是web项目ui自动化测试?通过测试工具模拟人为操控浏览器,使软件按照测试人员的预定计划自动执行测试的一种方式,可以完成许多手工测试无法完成或者不易实现的繁琐工作。正确使用自动化测试,可以更全面的对软件进行测试,从而提高软件质量进而缩短迭代周期。二、构建测试用例的“九部曲”(一)创建流程包划分功能模块日常测试活动中,都会根据功能模块进行拆分,所以在设计器中我们可以通过创建流程包的方式来拆分需要测试的功能模块,如下图中操作创建一个电脑流程包并且取名为对应的功能模块名称,如果有多个功能模块就创建多个对应的流程包,实在RPA设计器有易用的图形可视化界面,方便管理较多的功能模块。(二)在流程包
对于一个项目,我需要解析一些非常大的CSV文件。一些条目的内容存储在MySQL数据库中。我正在尝试使用多线程来加快速度,但到目前为止,这只会减慢速度。我解析了一个CSV文件(最大10GB),其中一些记录(20M+记录CSV中的大约5M)需要插入到MySQL数据库中。为了确定需要插入的记录,我们使用Redis服务器和包含正确ID/引用的集合。由于我们在任何给定时间处理大约30个这样的文件,并且存在一些依赖关系,我们将每个文件存储在一个Resque队列中,并让多个服务器处理这些(优先级)队列。简而言之:classWorkerdefself.perform(file)CsvParser.ea