论文题目:《YOLO5Face: Why Reinventing a Face Detector》
论文地址:https://arxiv.org/pdf/2105.12931.pdf
代码地址:https://github.com/deepcam-cn/yolov5-face
近年来,CNN在人脸检测方面已经得到广泛的应用。但是许多人脸检测器都是需要使用特别设计的人脸检测器来进行人脸的检测,而YOLOv5的作者则是把人脸检测作为一个一般的目标检测任务来看待的。YOLOv5Face在YOLOv5的基础上添加了一个 5-Point Landmark Regression Head(关键点回归),并对Landmark Regression Head使用了Wing loss进行约束。YOLOv5Face设计了不同模型尺寸的检测器,从大模型到超小模型,以实现在嵌入式或移动设备上的实时检测。
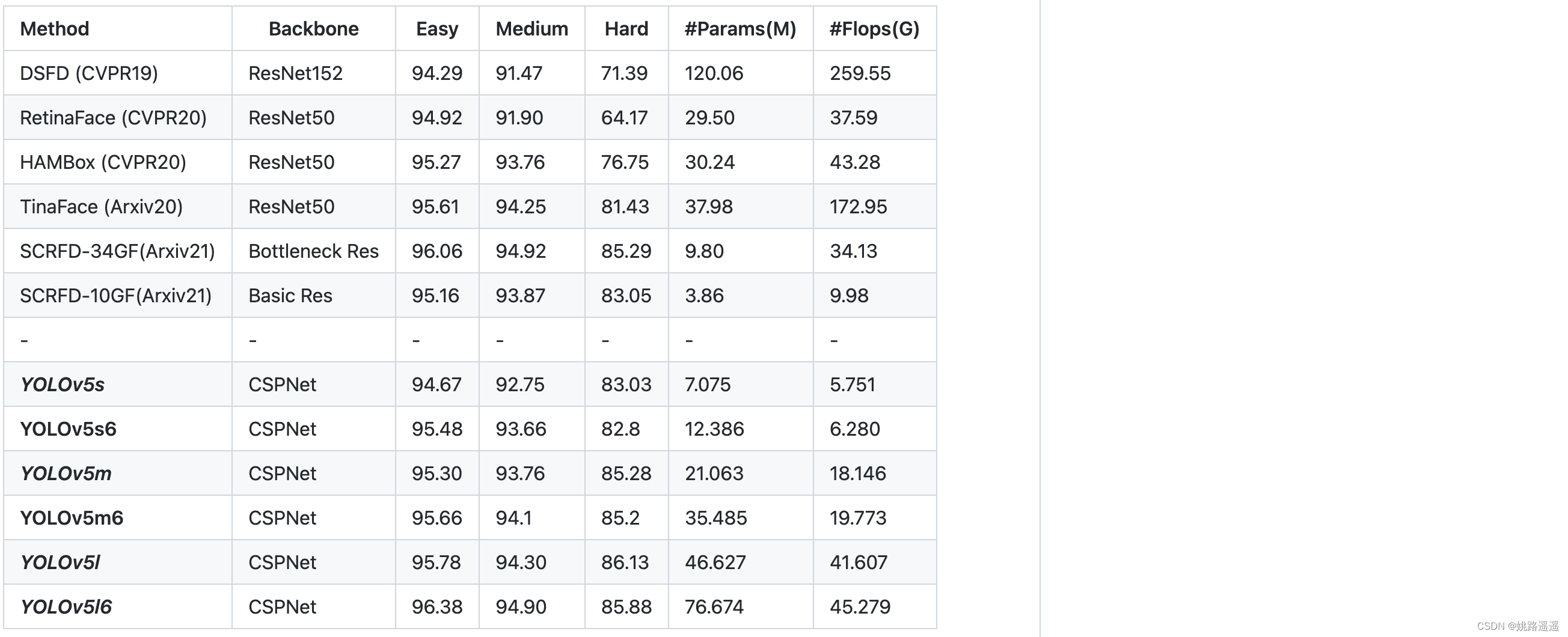
在WiderFace数据集上的实验结果表明,YOLOv5Face在几乎所有的Easy、Medium和Hard子集上都能达到最先进的性能,超过了特定设计的人脸检测器。
为什么人脸检测=一般检测:
在YOLOv5Face的方法中是把人脸检测作为一个一般的目标检测任务。与TinaFace想法类似把人脸作为一个目标。正如在TinaFace中所讨论的:
・从数据的角度来看,人脸所具有的诸如姿态、尺度、遮挡、光照以及模糊等也会出现在其他的一般检测任务之中;
・从面部的独特属来看性,如表情和化妆,也可以对应一般检测问题中的形状变化和颜色变化。
Landmark相对来说是一个特殊的存在,但他们也并不是唯一的。它们只是一个物体的关键点。例如,在车牌检测中,也使用了Landmark。在目标预测模型的Head中添加Landmark回归相对来说是一键简单的事情。那么从人脸检测所面临的挑战来看,多尺度、小人脸、密集场景等在一般的目标检测中都存在。因此,人脸检测完全可以看作一个一般目标检测子任务。
设计目标
YOLOv5Face针对人脸检测的对YOLOv5进行了再设计和修改,考虑到大人脸、小人脸、Landmark监督等不同的复杂性和应用。YOLOv5Face的目标是为不同的应用程序提供一个模型组合,从非常复杂的应用程序到非常简单的应用程序,以在嵌入式或移动设备上获得性能和速度的最佳权衡。
主要贡献
1.重新设计了YOLOV5来作为一个人脸检测器,并称之为YOLOv5Face。对网络进行了关键的修改,以提高平均平均精度(mAP)和速度方面的性能;
2.设计了一系列不同规模的模型,从大型模型到中型模型,再到超小模型,以满足不同应用中的需要。除了在YOLOv5中使用的Backbone外,还实现了一个基于ShuffleNetV2的Backbone,它为移动设备提供了最先进的性能和快速的速度;
3.在WiderFace数据集上评估了YOLOv5Face模型。在VGA分辨率的图像上,几乎所有的模型都达到了SOTA性能和速度。这也证明了前面的结论,不需要重新设计一个人脸检测器,因为YOLO5就可以完成它。
YOLOv5Face是以YOLOv5作为Baseline来进行改进和再设计以适应人脸检测。这里主要是检测小脸和大脸的修改。整体结构如下:
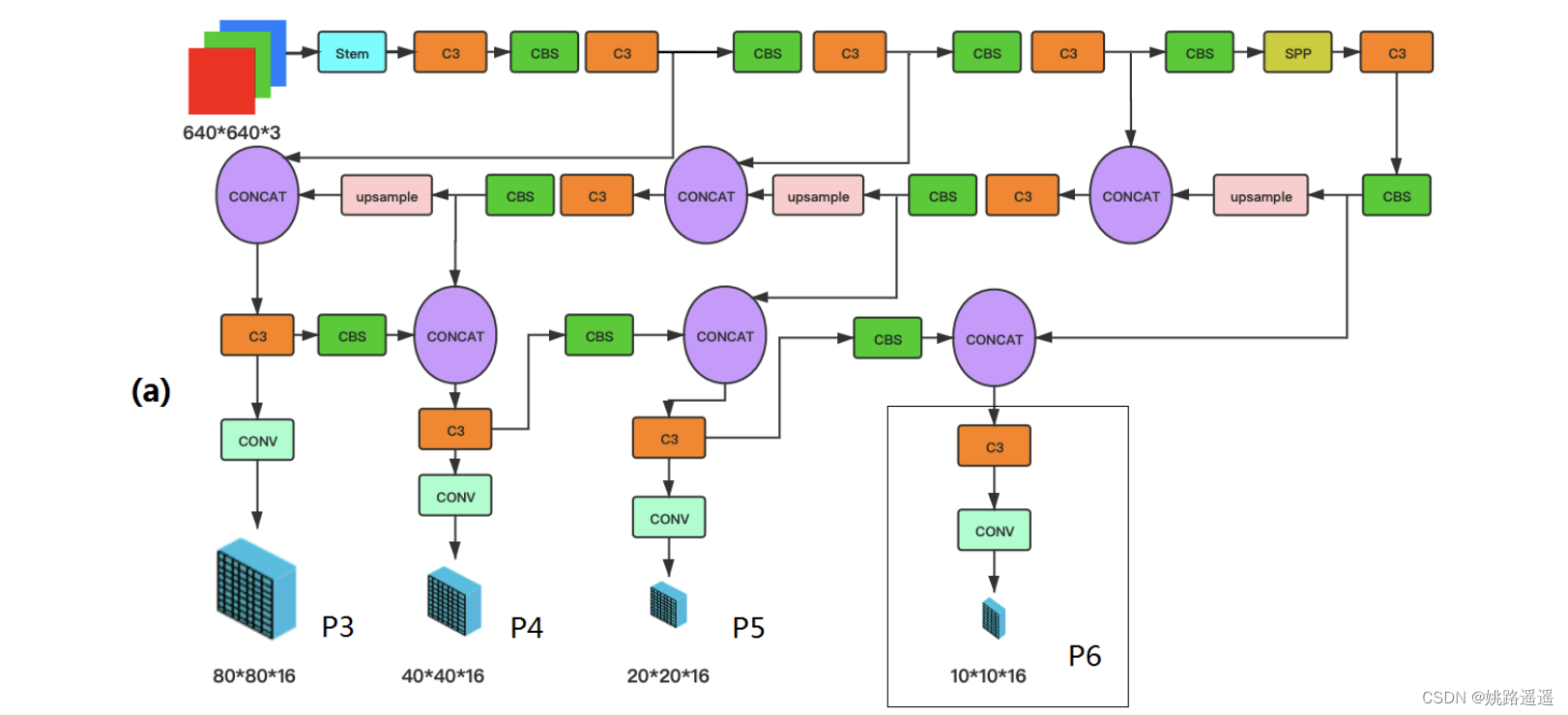
YOLO5人脸检测器的网络架构如上图所示。它由Backbone、Neck和Head组成,描述了整体的网络体系结构。在YOLOv5中,使用了CSPNet Backbone。在Neck中使用了SPP和PAN来融合这些特征。在Head中也都使用了回归和分类。

上图定义了一个CBS Block,它由Conv、BN和SiLU激活函数组成。CBS Block也被用于许多其他Block之中。
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
# 卷积层
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
# BN层
self.bn = nn.BatchNorm2d(c2)
# SiLU激活层
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))

在上图中,显示了Head的输出标签,其中包括边界框(bbox)、置信度(conf)、分类(cls)和5-Point Landmarks。这些Landmarks是对YOLOv5的改进点,使其成为一个具有Landmarks输出的人脸检测器。如果没有Landmarks,最后一个向量的长度应该是6而不是16。
请注意,P3中的输出尺寸80×80×16,P4中的40×40×16,P5中的20×20×16,可选P6中的10×10×16为每个Anchor。实际的尺寸应该乘以Anchor的数量。

上图为stem结构,它用于取代YOLOv5中原来的Focus层。在YOLOv5中引入Stem块用于人脸检测是YOLOv5Face的创新之一。用Stem模块替代网络中原有的Focus模块,提高了网络的泛化能力,降低了计算复杂度,同时性能也没有下降。Stem模块的图示中虽然都是用的CBS,但是看代码可以看出来第2个和第4个CBS是1×1卷积,第1个和第3个CBS是3×3,stride=2的卷积。配合yaml文件可以看到stem以后图像大小由640×640变成了160×160。
class StemBlock(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=None, g=1, act=True):
super(StemBlock, self).__init__()
# 3×3卷积
self.stem_1 = Conv(c1, c2, k, s, p, g, act)
# 1×1卷积
self.stem_2a = Conv(c2, c2 // 2, 1, 1, 0)
# 3×3卷积
self.stem_2b = Conv(c2 // 2, c2, 3, 2, 1)
# 最大池化层
self.stem_2p = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
# 1×1卷积
self.stem_3 = Conv(c2 * 2, c2, 1, 1, 0)
def forward(self, x):
stem_1_out = self.stem_1(x)
stem_2a_out = self.stem_2a(stem_1_out)
stem_2b_out = self.stem_2b(stem_2a_out)
stem_2p_out = self.stem_2p(stem_1_out)
out = self.stem_3(torch.cat((stem_2b_out, stem_2p_out), 1))
return out

上图显示了一个CSP Block(C3)。CSP Block的设计灵感来自于DenseNet。但是,不是在一些CNN层之后添加完整的输入和输出,输入被分成 2 部分。其中一半通过一个CBS Block,即一些Bottleneck Blocks,另一半是经过Conv层进行计算。
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))

class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
#第1个CBS模块
self.cv1 = Conv(c1, c_, 1, 1)
#第2个CBS模块
self.cv2 = Conv(c_, c2, 3, 1, g=g)
#元素add操作
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
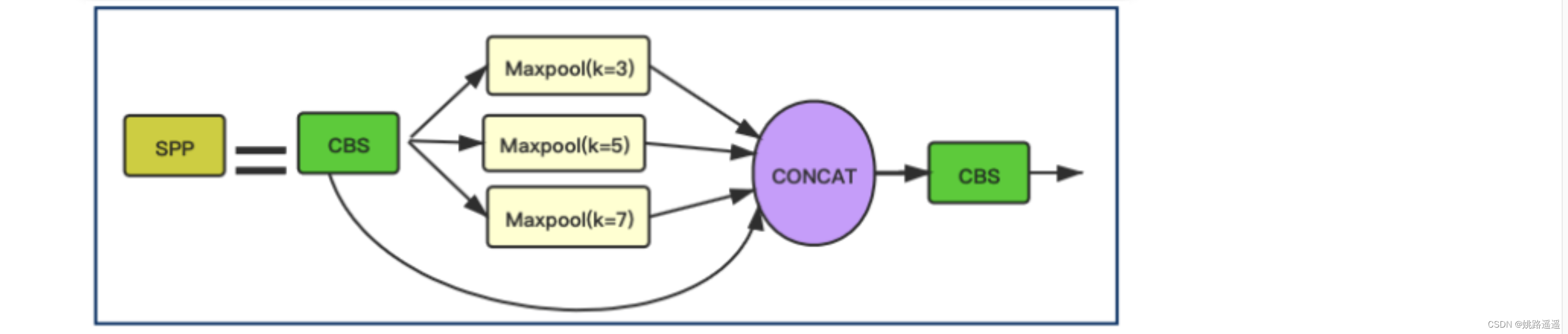
上图是SPP Block。YOLOv5Face在这个Block中把YOLOv5中的13×13,9×9,5×5的kernel size修改为7×7,5×5,3×3,这个改进更适用于人脸检测并提高了人脸检测的精度。
class SPP(nn.Module):
# 这里主要是讲YOLOv5中的kernel=(5,7,13)修改为(3, 5, 7)
def __init__(self, c1, c2, k=(3, 5, 7)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
# 对应第1个CBS Block
self.conv1 = Conv(c1, c_, 1, 1)
# 对应第2个 cat后的 CBS Block
self.conv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
# ModuleList=[3×3 MaxPool2d,5×5 MaxPool2d,7×7 MaxPool2d]
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.conv1(x)
return self.conv2(torch.cat([x] + [m(x) for m in self.m], 1))
同时,YOLOv5Face添加一个stride=64的P6输出块,P6可以提高对大人脸的检测性能。(之前的人脸检测模型大多关注提高小人脸的检测性能,这里作者关注了大人脸的检测效果,提高大人脸的检测性能来提升模型整体的检测性能)。P6的特征图大小为10x10。
注意,这里只考虑VGA分辨率的输入图像。为了更精确地说,输入图像的较长的边缘被缩放到640,并且较短的边缘被相应地缩放。较短的边缘也被调整为SPP块最大步幅的倍数。例如,当不使用P6时,较短的边需要是32的倍数;当使用P6时,较短的边需要是64的倍数。
YOLOv5Face作者发现一些目标检测的数据增广方法并不适合用在人脸检测中,包括上下翻转和Mosaic数据增广。删除上下翻转可以提高模型性能。对小人脸进行Mosaic数据增广反而会降低模型性能,但是对中尺度和大尺度人脸进行Mosaic可以提高性能。随机裁剪有助于提高性能。
这里主要还是COCO数据集和WiderFace数据集尺度有差异,WiderFace数据集小尺度数据相对较多。
Landmark是人脸的重要特征。它们可以用于人脸比对、人脸识别、面部表情分析、年龄分析等任务。传统Landmark由68个点组成。它们被简化为5点时,这5点Landmark就被广泛应用于面部识别。人脸标识的质量直接影响人脸对齐和人脸识别的质量。
一般的物体检测器不包括Landmark。可以直接将其添加为回归Head。因此,作者将它添加到YOLO5Face中。Landmark输出将用于对齐人脸图像,然后将其发送到人脸识别网络。
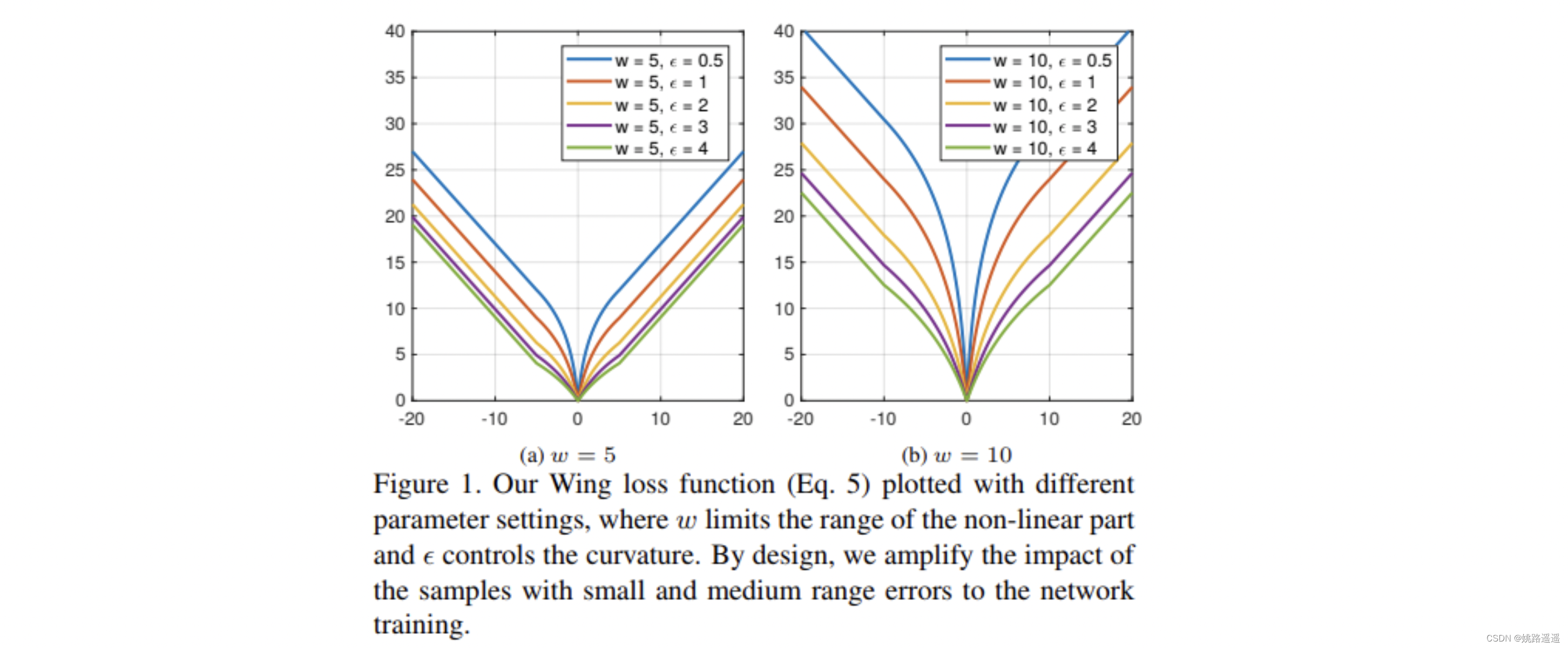
用于Landmark回归的一般损失函数为L2、L1或smooth-L1。MTCNN使用的就是L2损失函数。然而,作者发现这些损失函数对小的误差并不敏感。为了克服这个问题,提出了Wing loss:
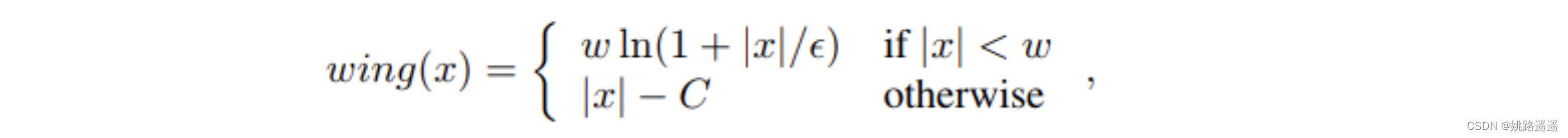

landmark的获取:
#landmarks
lks = t[:,6:14]
lks_mask = torch.where(lks < 0, torch.full_like(lks, 0.), torch.full_like(lks, 1.0))
#应该是关键点的坐标除以anch的宽高才对,便于模型学习。使用gwh会导致不同关键点的编码不同,没有统一的参考标准
lks[:, [0, 1]] = (lks[:, [0, 1]] - gij)
lks[:, [2, 3]] = (lks[:, [2, 3]] - gij)
lks[:, [4, 5]] = (lks[:, [4, 5]] - gij)
lks[:, [6, 7]] = (lks[:, [6, 7]] - gij)
Wing Loss的计算如下:
#landmarks
lks = t[:,6:14]
lks_mask = torch.where(lks < 0, torch.full_like(lks, 0.), torch.full_like(lks, 1.0))
#应该是关键点的坐标除以anch的宽高才对,便于模型学习。使用gwh会导致不同关键点的编码不同,没有统一的参考标准
lks[:, [0, 1]] = (lks[:, [0, 1]] - gij)
lks[:, [2, 3]] = (lks[:, [2, 3]] - gij)
lks[:, [4, 5]] = (lks[:, [4, 5]] - gij)
lks[:, [6, 7]] = (lks[:, [6, 7]] - gij)
Wing Loss的计算如下:
class WingLoss(nn.Module):
def __init__(self, w=10, e=2):
super(WingLoss, self).__init__()
# https://arxiv.org/pdf/1711.06753v4.pdf Figure 5
self.w = w
self.e = e
self.C = self.w - self.w * np.log(1 + self.w / self.e)
def forward(self, x, t, sigma=1): #这里的x,t分别对应之后的pret,truel
weight = torch.ones_like(t) #返回一个大小为1的张量,大小与t相同
weight[torch.where(t==-1)] = 0
diff = weight * (x - t)
abs_diff = diff.abs()
flag = (abs_diff.data < self.w).float()
y = flag * self.w * torch.log(1 + abs_diff / self.e) + (1 - flag) * (abs_diff - self.C) #全是0,1
return y.sum()
class LandmarksLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=1.0):
super(LandmarksLoss, self).__init__()
self.loss_fcn = WingLoss()#nn.SmoothL1Loss(reduction='sum')
self.alpha = alpha
def forward(self, pred, truel, mask): #预测的,真实的 600(原来为62*10)(推测是去掉了那些没有标注的值)
loss = self.loss_fcn(pred*mask, truel*mask) #一个值(tensor)
return loss / (torch.sum(mask) + 10e-14)
其实本质上没有改变,这里仅仅给出对比的代码。
yolov5的NMS代码如下:
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()):
"""Performs Non-Maximum Suppression (NMS) on inference results
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
nc = prediction.shape[2] -5 # number of classes
yolov5face的NMS代码如下:
def non_max_suppression_face(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, labels=()):
"""Performs Non-Maximum Suppression (NMS) on inference results
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
# 不同之处
nc = prediction.shape[2] - 15 # number of classes
综上,对比yolov5,yolov5face主要改进点简单总结如下:
1.增加了人脸landmark回归head,并提出和采用了更适用于landmark回归的wing loss。
2.替换Focus层为Stem层。增加了网络的通用性,同时减少了计算量,且模型表现没有下降。
3.将SPP的kernel尺寸改小。YOLOv5Face在这个Block中把YOLOv5中的13×13,9×9,5×5的kernel size修改为7×7,5×5,3×3,这个改进更适用于人脸检测并提高了人脸检测的精度。
4.增加了stride=64的P6特征图输出块。P6可以提高对大人脸的检测性能。(之前的人脸检测模型大多关注提高小人脸的检测性能,这里作者关注了大人脸的检测效果,提高大人脸的检测性能来提升模型整体的检测性能)。P6的特征图大小为10x10。
##################################################################################
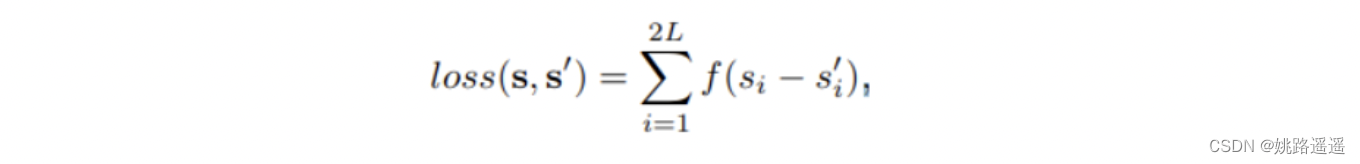
其中s是人脸关键点的ground-truth,函数f(x)就等价于:
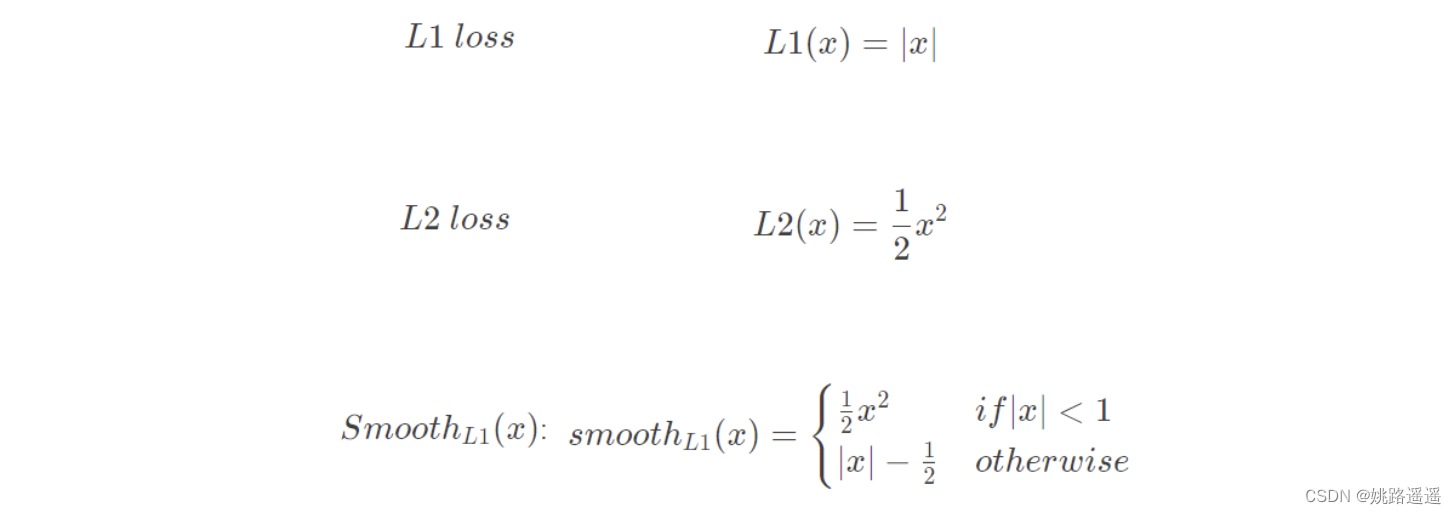
损失函数对x的导数分别为:
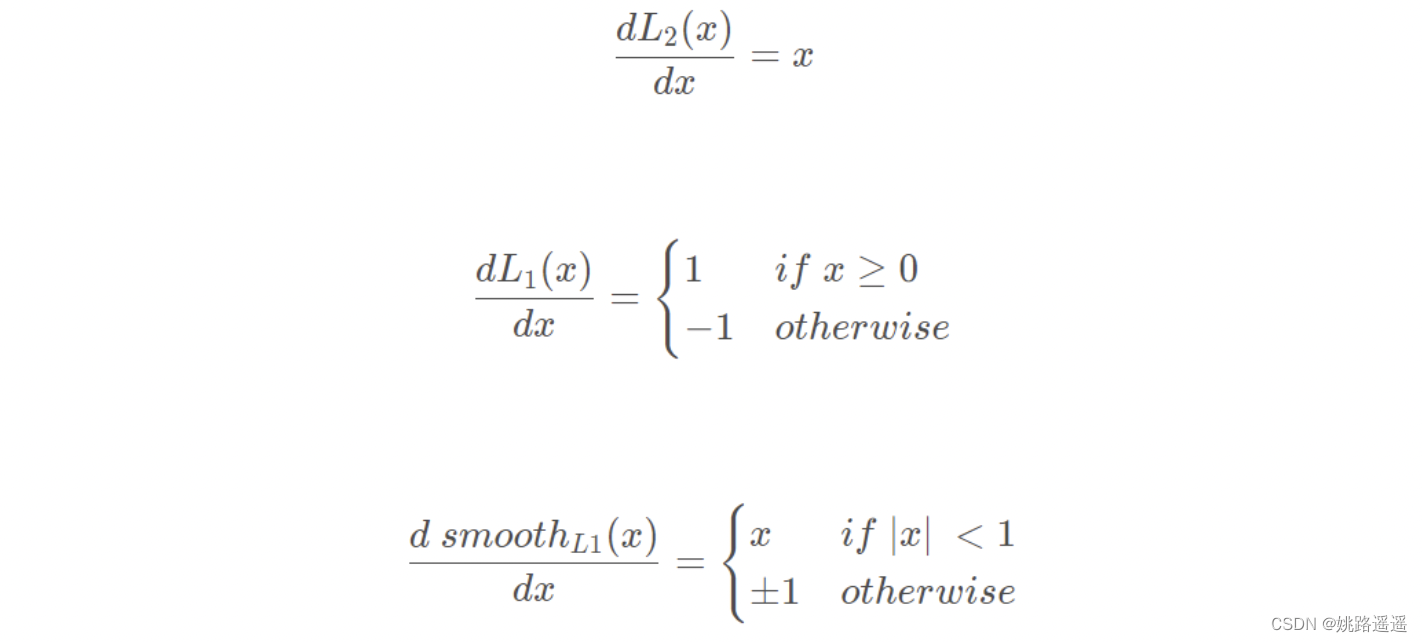
L2损失函数。当x增大时L2 loss对x的导数也增大,这就导致训练初期,预测值与ground-truth差异过大时,损失函数对预测值的梯度十分大,导致训练不稳定。
L1损失函数。L1 loss的导数为常数,在训练后期,预测值与ground-truth差异很小时, 损失对预测值的导数的绝对值仍然为1,此时学习率(learning rate)如果不变,损失函数将在稳定值附近波动,难以继续收敛达到更高精度。
Smooth L1损失函数。在x较小时,对x的梯度也会变小,而在x很大时,对x的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。smooth L1完美地避开了L1和L2损失的缺陷。
此外,根据fast rcnn的说法,“… L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet.” 也就是smooth L1让loss对于离群点更加鲁棒,即相比于L2损失函数,其对离群点、异常值(outlier)不敏感,梯度变化相对更小,训练时不容易跑飞。
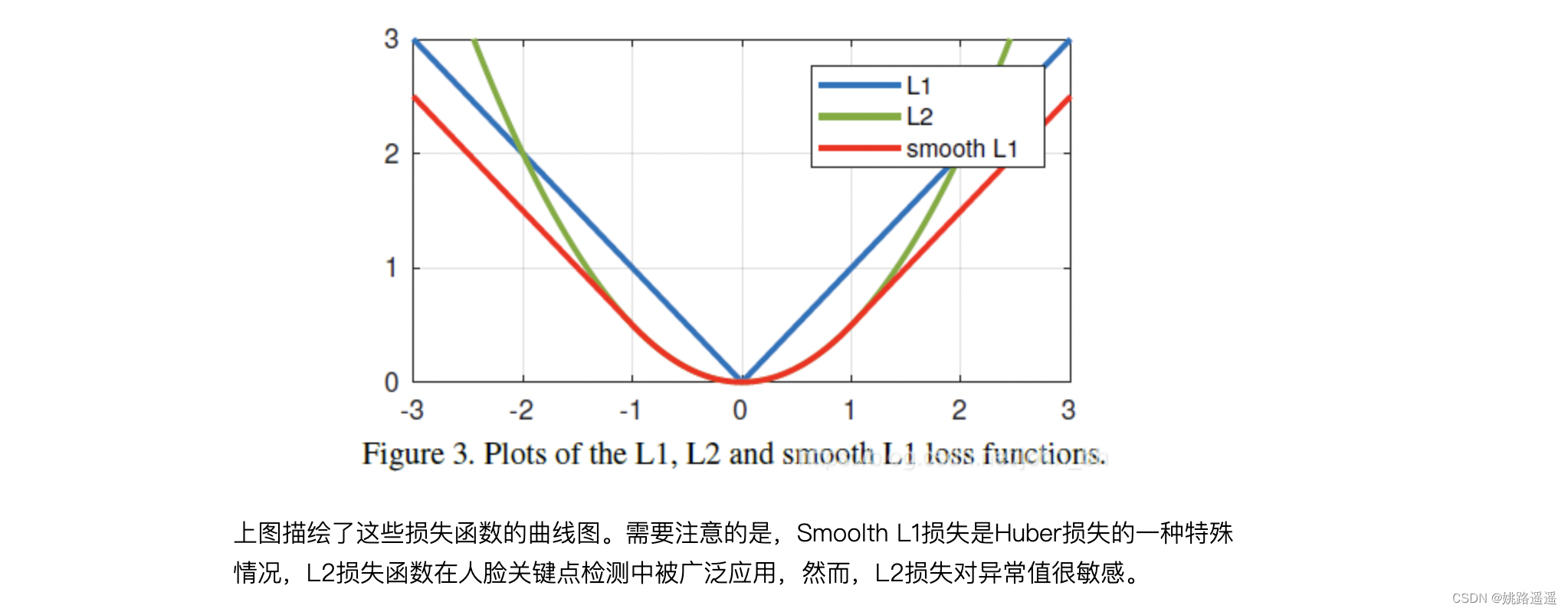
上一部分中分析的所有损失函数在出现较大误差时表现良好。这说明神经网络的训练应更多地关注具有小或中误差的样本。为了实现此目标,提出了一种新的损失函数,即基于CNN的面部Landmark定位的Wing Loss。
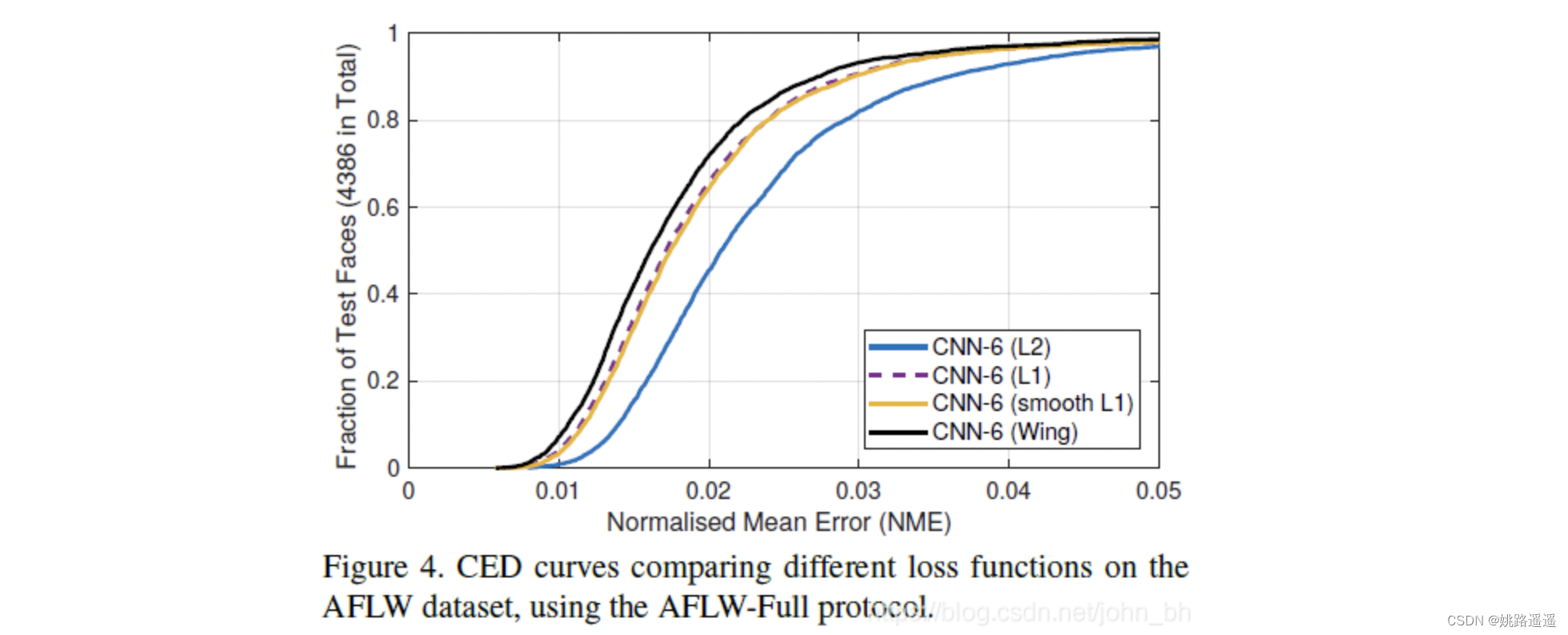
当NME在0.04的时候,测试数据比例已经接近1了,所以在0.04到0.05这一段,也就是所谓的large errros段,并没有分布更多的数据,说明各损失函数在large errors段都表现很好。模型表现不一致的地方就在于small errors和medium errors段,例如,在NME为0.02的地方画一根竖线,相差甚远的。因此作者提出训练过程中应该更多关注samll or medium range errros样本。
可以使用ln x来增强小误差的影响,它的梯度是1/x,对于接近0的值就会越大,optimal step size为x的平方,这样gradient就由small errors“主导”,step size由large errors“主导”。这样可以恢复不同大小误差之间的平衡。
但是,为了防止在可能的错误方向上进行较大的更新步骤,重要的是不要过度补偿较小的定位错误的影响。这可以通过选择具有正偏移量的对数函数来实现。
但是这种类型的损失函数适用于处理相对较小的定位误差。在wild人脸关键点检测中,可能会处理极端姿势,这些姿势最初的定位误差可能非常大,在这种情况下,损失函数应促进从这些大错误中快速恢复。这表明损失函数的行为应更像L1或L2。由于L2对异常值敏感,因此选择了L1。
所以,对于小误差,它应该表现为具有偏移量的对数函数,而对于大误差,则应表现为L1。因此复合损失函数Wing Loss就诞生了。
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题
我正在使用rubydaemongem。想知道如何向停止操作添加一些额外的步骤?希望我能检测到停止被调用,并向其添加一些额外的代码。任何人都知道我如何才能做到这一点? 最佳答案 查看守护程序gem代码,它似乎没有用于此目的的明显扩展点。但是,我想知道(在守护进程中)您是否可以捕获守护进程在发生“停止”时发送的KILL/TERM信号...?trap("TERM")do#executeyourextracodehereend或者你可以安装一个at_exit钩子(Hook):-at_exitdo#executeyourextracodehe
我有一个定义类的Ruby脚本。我希望脚本执行语句BoolParser.generate:file_base=>'bool_parser'仅当脚本作为可执行文件被调用时,而不是当它被irbrequire(或通过-r在命令行上传递)时。我可以用什么来包装上面的语句,以防止它在我的Ruby文件加载时执行? 最佳答案 条件$0==__FILE__...!/usr/bin/ruby1.8classBoolParserdefself.generate(args)p['BoolParser.generate',args]endendif$0==_
我遇到了这种行为,想知道是否有其他人看到过它。我有一个解决方法,因此它不会成为阻碍。我使用Cedar堆栈在Heroku上创建了一个新应用程序。在演示多个环境时,我添加了以下配置变量:herokuconfig:addRACK_ENV=staging--appappname我目视验证环境变量已设置,然后将以下路由放入我的简单Sinatra示例中:get'/?'doENV['RACK_ENV']end当我在笔记本电脑上进行本地测试时,我收到了预期的开发。当我推送到Heroku并在herokuapp.com上点击相同的路线时,我得到了development而不是staging。我通过Procf
我有以下字符串,我想检测那里的换行符。但是Ruby的字符串方法include?检测不到它。我正在运行Ruby1.9.2p290。我哪里出错了?"/'ædres/\nYour".include?('\n')=>false 最佳答案 \n需要在双引号内,否则无法转义。>>"\n".include?'\n'=>false>>"\n".include?"\n"=>true 关于Ruby无法检测字符串中的换行符,我们在StackOverflow上找到一个类似的问题: h
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
我有一个连接到服务器的rubytcpsocket客户端。在发送数据之前如何检查套接字是否已连接?我是否尝试“拯救”断开连接的tcpsocket,重新连接然后重新发送?如果是这样,有没有人有一个简单的代码示例,因为我不知道从哪里开始:(我很自豪我设法在rails中获得了一个持久连接的客户端tcpsocket。然后服务器决定杀死客户端,一切都崩溃了;)编辑我已经使用此代码解决了一些问题-如果未连接,它将尝试重新连接,但如果服务器已关闭则不会处理这种情况(它将继续重试)。这是正确方法的开始吗?谢谢defself.write(data)begin@@my_connection.write(
我在一台Windows764位机器上使用Sass和Ruby(最新版本),我正在我的家庭服务器上处理一个共享文件夹。(但是,我不得不承认问题本身也出现在服务器上,因为我试图安装Ruby并直接-watch服务器上的文件)。问题如下:如果我第一次保存,检测到变化,我的style.css被直接覆盖。之后,我总是需要保存多达7次才能覆盖style.css。每次都会检测到更改,但不会编译任何内容。这是一个屏幕:>>>Sassiswatchingforchanges.PressCtrl-Ctostop.overwritestyle.css>>>Changedetectedto:E:/Websites