ETL 和 ELT 之间的主要区别在于数据转换发生的时间和地点 — 这些变化可能看起来很小,但会产生很大的影响!
ETL 和 ELT 是数据团队引入、转换并最终向利益干系人公开数据的两种主要方式。它们是与现代云数据仓库和 ETL 工具的开发并行发展的流程。
在任一过程中,ETL/ELT 中的字母代表:
这两个过程的分歧在于转换层的时间和位置。简而言之,在 ETL 过程中,原始数据的转换发生在数据仓库之前。在 ELT 流程中,原始数据已丢弃后,数据仓库中会发生转换;在这种方法中,原始数据和转换后的数据都位于数据仓库中。
这不仅仅是语义,转换发生的时间和地点的顺序在数据团队如何存储、治理、标准化、建模和测试数据方面起着至关重要的作用。使用此页面了解这两个过程的不同之处、每个选项的优点和缺点,以及哪种方法最适合您和您的团队。
ETL 和 ELT 之间的主要区别在于转换的时间和位置:它是在数据加载到数据仓库之前还是在存储之后发生。这种转换顺序对以下方面具有相当大的影响:
在我们深入了解这些差异的细节之前,让我们清楚地定义什么是 ETL 和 ELT,以及为什么 ELT 已成为分析行业的最新现象。
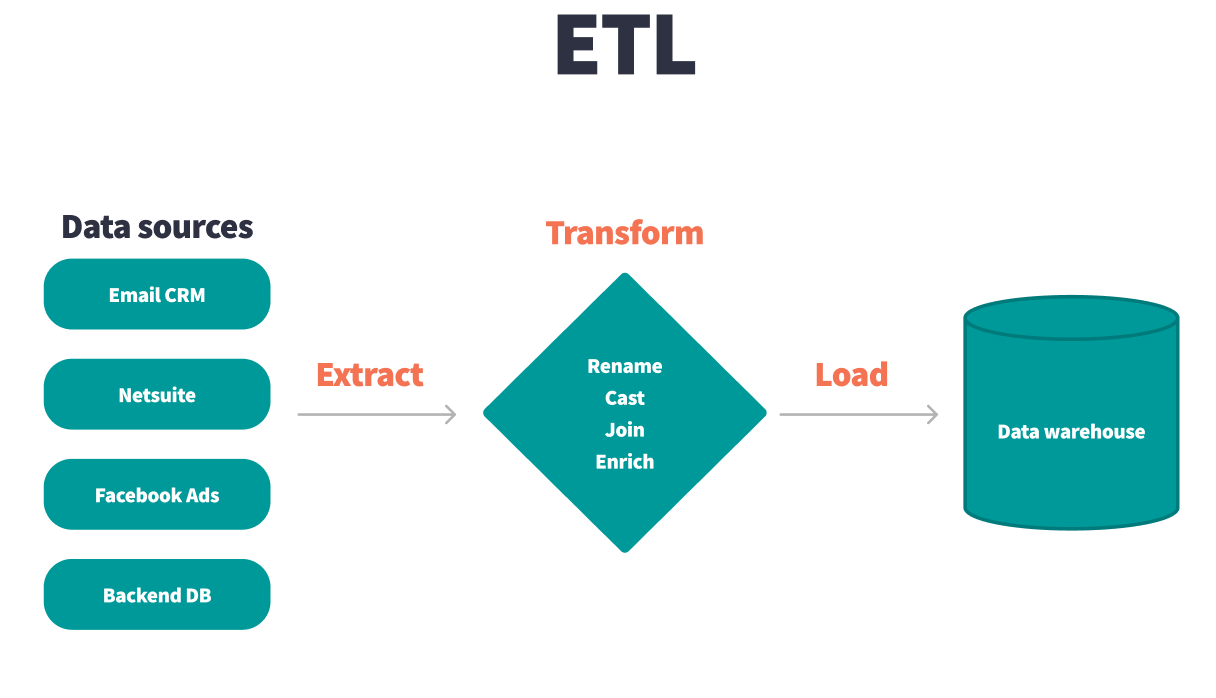
ETL 或“提取、转换、加载”是首先从数据源中提取数据,对其进行转换,然后将其加载到目标数据仓库的过程。在 ETL 工作流中,许多有意义的数据转换都发生在下游商业智能 (BI) 平台的此主要管道之外。
在许多方面,ETL 工作流可以重命名为 ETLT 工作流,因为相当一部分有意义的数据转换发生在数据管道之外。相同的转换可能发生在 ETL 和 ELT 工作流中,主要区别在于何时(在主 ETL 工作流内部或外部)以及转换数据的位置(ETL 平台/BI 工具/数据仓库)。
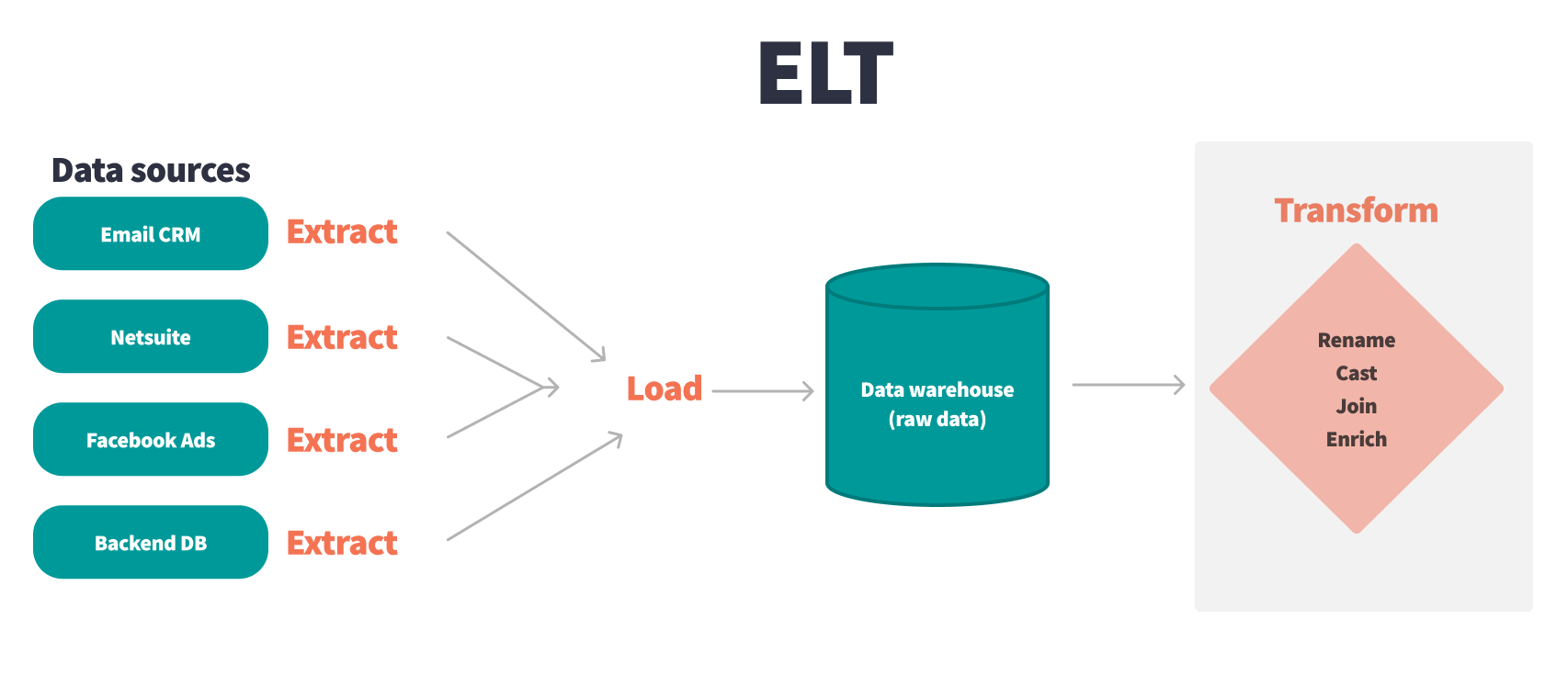
提取、加载、转换 (ELT) 是首先从不同数据源提取数据,然后将其加载到目标数据仓库中,最后转换数据的过程。
ELT 已成为如何在现代数据仓库中管理信息流的范例。这代表了以前处理数据的方式的根本转变,当时ETL是大多数公司实施的数据工作流。
从 ETL 过渡到 ELT 意味着您不再需要在将数据初始加载到数据仓库期间捕获转换。相反,您可以加载所有数据,然后在其上构建转换。数据团队报告说,与传统的 ETL 工作流相比,ELT 工作流有几个优点,我们将在下面的部分中介绍这些优势。
您可以阅读交替使用 ETL 和 ELT 的其他文章或技术文档。在纸面上,唯一的区别是 T 和 L 出现的顺序。然而,这种简单的字母切换会彻底改变数据在企业系统中存在和流动的方式。
在这两个过程中,来自不同数据源的数据以类似的方式提取。但是,在 ELT 工作流中发生转换之前,数据将直接加载到目标仓库中。现在,原始数据和转换后的数据都可以存在于数据仓库中。在 ELT 工作流中,数据从业者在有机会探索和分析原始数据后,可以灵活地对数据进行建模。ETL 工作流可能更具限制性,因为转换在提取后立即发生。
下面,我们分解了两者之间的其他一些主要区别:
| 英语 | 电子离 | |
|---|---|---|
| 所需的编程技能 | 通常几乎不需要代码即可将数据提取并加载到数据仓库中。SQL 是转换背后的主要力量。 | 通常需要自定义脚本或相当大的数据工程提升,以便在加载之前提取和转换数据。Python,Scala和SQL通常用于转换数据本身。 |
| 关注点分离 | 提取层、加载层和转换层可以由不同的产品显式分离出来。 | ETL 过程通常封装在一个产品中。 |
| 变换的分布 | 由于转换是最后发生的,因此建模过程具有更大的灵活性。首先担心将数据放在一个地方,然后您有时间探索数据以了解转换数据的最佳方式。 | 由于转换发生在将数据加载到目标位置之前,因此团队必须先进行彻底的工作,然后才能确保正确转换数据。大量转换通常发生在 BI 层的下游。 |
| 数据团队角色 | ELT 工作流使了解 SQL 的数据团队成员能够创建自己的提取和加载管道及转换 | ETL 工作流通常需要具有更高技术技能的团队来创建和维护管道 |
为什么近年来ELT的采用增长如此之快?几个原因:
您已经阅读了本文,反思了当前数据堆栈的胜利和挣扎,并最终提出了一个黄金问题:哪个流程最适合您、您的数据团队和您的业务?
下面,我们分解了您在考虑如何通过数据增强团队和业务能力时应采取的关键考虑因素,以及 ELT/ELT 流程如何影响该方法。
以下内容对您有多重要?
如果这些事情对你以及你的数据、团队和业务的健康至关重要,请考虑更多地了解 dbt(鼓励数据从业者体现软件工程最佳实践的工具)如何改变现代分析空间。
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我正在检查一个Rails项目。在ERubyHTML模板页面上,我看到了这样几行:我不明白为什么不这样写:在这种情况下,||=和ifnil?有什么区别? 最佳答案 在这种特殊情况下没有区别,但可能是出于习惯。每当我看到nil?被使用时,它几乎总是使用不当。在Ruby中,很少有东西在逻辑上是假的,只有文字false和nil是。这意味着像if(!x.nil?)这样的代码几乎总是更好地表示为if(x)除非期望x可能是文字false。我会将其切换为||=false,因为它具有相同的结果,但这在很大程度上取决于偏好。唯一的缺点是赋值会在每次运行
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
打印1:defsum(i)i=i+[2]end$x=[1]sum($x)print$x打印12:defsum(i)i.push(2)end$x=[1]sum($x)print$x后者是修改全局变量$x。为什么它在第二个例子中被修改而不是在第一个例子中?类Array的任何方法(不仅是push)都会发生这种情况吗? 最佳答案 变量范围在这里无关紧要。在第一段代码中,您仅使用赋值运算符=为变量i赋值,而在第二段代码中,您正在修改$x(也称为i)使用破坏性方法push。赋值从不修改任何对象。它只是提供一个名称来引用一个对象。方法要么是破坏性
Ruby中的Fixnum方法.next和.succ有什么区别?看起来它的工作原理是一样的:1.next=>21.succ=>2如果有什么不同,为什么有两种方法做同样的事情? 最佳答案 它们是等价的。Fixnum#succ只是Fixnum#next的同义词。他们甚至在thereferencemanual中共享同一block. 关于ruby-Ruby中.next和.succ的区别,我们在StackOverflow上找到一个类似的问题: https://stacko
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
在Ruby中,我试图理解to_enum和enum_for方法。在我提出问题之前,我提供了一些示例代码和两个示例来帮助理解上下文。示例代码:#replicatesgroup_bymethodonArrayclassclassArraydefgroup_by2(&input_block)returnself.enum_for(:group_by2)unlessblock_given?hash=Hash.new{|h,k|h[k]=[]}self.each{|e|hash[input_block.call(e)]示例#1:irb(main)>puts[1,2,3].group_by2.ins