大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布;据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起;结果这两个品类的销量都有明显的增长;分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品。
不论这个案例是否是真实的,案例中分析顾客购买记录的方式就是关联规则分析法Association Rules。
关联规则分析也被称为购物篮分析,用于分析数据集各项之间的关联关系。
项集:item的集合,如集合{牛奶、麦片、糖}是一个3项集,可以认为是购买记录里物品的集合。
频繁项集:顾名思义就是频繁出现的item项的集合。如何定义频繁呢?用比例来判定,关联规则中采用支持度和置信度两个概念来计算比例值
支持度:共同出现的项在整体项中的比例。以购买记录为例子,购买记录100条,如果商品A和B同时出现50条购买记录(即同时购买A和B的记录有50),那边A和B这个2项集的支持度为50%
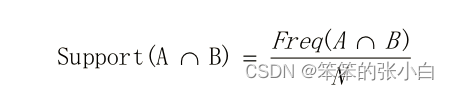
置信度:购买A后再购买B的条件概率,根据贝叶斯公式,可如下表示:
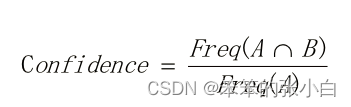
提升度:为了判断产生规则的实际价值,即使用规则后商品出现的次数是否高于商品单独出现的评率,提升度和衡量购买X对购买Y的概率的提升作用。如下公式可见,如果X和Y相互独立那么提升度为1,提升度越大,说明X->Y的关联性越强
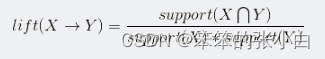
1. Apriori算法的基本思想
对数据集进行多次扫描,第一次扫描得到频繁1-项集的集合L1,第k次扫描首先利用第k-1次扫描的结果Lk-1产生候选k-项集Ck,在扫描过程中计算Ck的支持度,在扫描结束后计算频繁k-项集Lk,算法当候选k-项集的集合Ck为空的时候结束。
2. Apriori算法产生频繁项集的过程
(1)连接步
(2)剪枝步
3.Apriori算法的主要步骤
(1) 扫描全部数据,产生候选1-项集的集合C1
(2) 根据最小支持度,由候选1-项集的集合C1产生频繁1-项集的集合L1
(3) 对k>1,重复步骤(4)(5)(6)
(4) 由Lk执行连接和剪枝操作,产生候选(k+1)-项集Ck+1
(5) 根据最小支持度,由候选(k+1)-项集的集合Ck+1产生频繁(k+1)-项集的集合Lk+1
(6) 若L不为空集,则k = k+1,跳往步骤(4),否则跳往步骤(7)
(7) 根据最小置信度,由频繁项集产生强关联规则
Apriori算法是经典的关联规则算法。Apriori算法的目标是找到最大的K项频繁集。Apriori算法从寻找1项集开始,通过最小支持度阈值进行剪枝,依次寻找2项集,3项集直到没有更过项集为止。
本次算法实现我们借助了mlxtend第三方包,pip install mlxtend安装一下即可
编译工具:jupyter notebook
首先导入本次项目用到的第三方包:
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import warnings
warnings.filterwarnings('ignore')接下来我将使用两个小案例给大家示范如何使用关联规则算法
准备数据
order = {'001': '面包,黄油,尿布,啤酒',
'002': '咖啡,糖,小甜饼,鲑鱼,啤酒',
'003': '面包,黄油,咖啡,尿布,啤酒,鸡蛋',
'004': '面包,黄油,鲑鱼,鸡',
'005': '鸡蛋,面包,黄油',
'006': '鲑鱼,尿布,啤酒',
'007': '面包,茶,糖鸡蛋',
'008': '咖啡,糖,鸡,鸡蛋',
'009': '面包,尿布,啤酒,盐',
'010': '茶,鸡蛋,小甜饼,尿布,啤酒'}
data_set = []
id_set= []
shopping_basket = {}
for key in order:
item = order[key].split(',')
id_set.append(key)
data_set.append(item)
shopping_basket['ID'] = id_set
shopping_basket['Basket'] = data_set
shopping_basket
将数据转换为DataFrame类型
data = pd.DataFrame(shopping_basket)
data 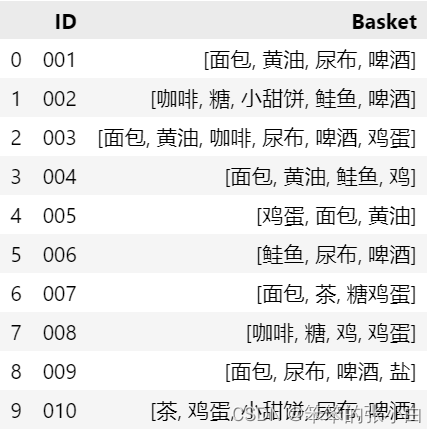
接着我们需要将Basket的数据转换为one-hot(0,1)编码
这一步主要就是对数据的ID和Basket进行划分处理,最后进行合并
data_id = data.drop('Basket',1)
data_basket = data['Basket'].str.join(',')
data_basket = data_basket.str.get_dummies(',')
new_data = data_id.join(data_basket)
new_data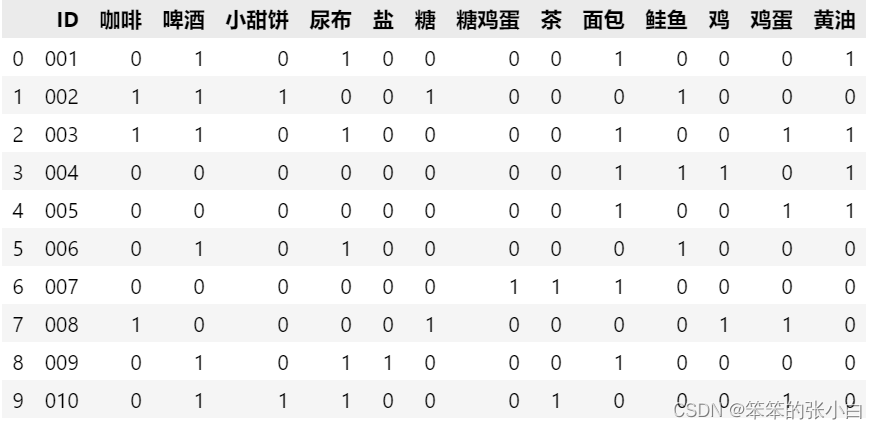
调用apriori算法
apriori()中min_support也就是最小支持度默认为0.5,所以我们要修改的话直接修改这个值
frequent_itemsets = apriori(new_data.drop('ID',1),min_support=0.5,use_colnames=True)
frequent_itemsets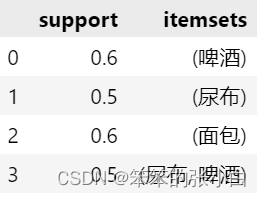
从结果中,我们发现在二项集中,出现了尿布和啤酒,说明尿布和啤酒的关联性很大。
接着我们查看其具体的关联规则
association_rules(frequent_itemsets,metric='lift')
我们看出尿布和啤酒的提升度值也很大(大于1) ,更一步说明了尿布和啤酒的关联性很强,所有在销售的时候,应该将其放在一起售卖,或者适当增加一下促销方式。
步骤跟案例一相似
准备数据
shopping_backet = {'ID':[1,2,3,4,5,6],
'Basket':[['Beer','Diaper','Pretzels','Chips','Aspirin'],
['Diaper','Beer','Chips','Lotion','Juice','BabyFood','Milk'],
['Soda','Chips','Milk'],
['Soup','Beer','Diaper','Milk','IceCream'],
['Soda','Coffee','Milk','Bread'],
['Beer','Chips']
]
}
data = pd.DataFrame(shopping_backet)
data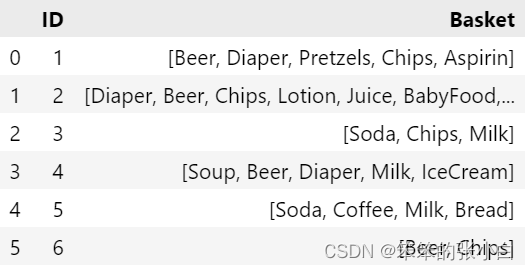
将数据转换为apriori算法要求的数据类型
data_id = data.drop('Basket',1)
data_basket = data['Basket'].str.join(',')
data_basket = data_basket.str.get_dummies(',')
new_data = data_id.join(data_basket)
new_data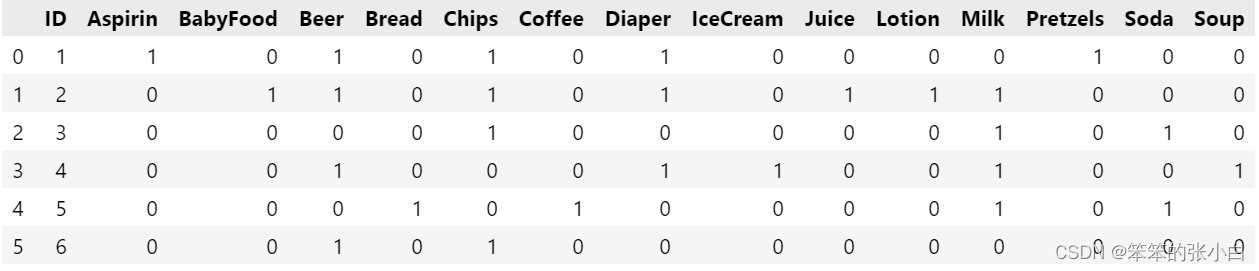
调用apriori算法
frequent_itemsets = apriori(new_data.drop('ID',1),min_support=0.5,use_colnames=True)
frequent_itemsets 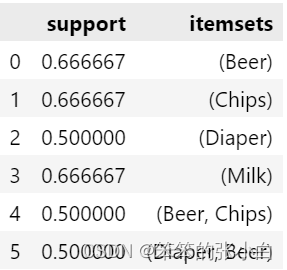
如果光考虑support支持度,那么[Beer, Chips]和[Diaper, Beer]都是很频繁的,那么哪一种组合更相关呢?
association_rules(frequent_itemsets,metric='lift')
显然[Diaper, Beer]的lift值更大,说明这个组合更相关
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
目前,Itembelongs_toCompany和has_manyItemVariants。我正在尝试使用嵌套的fields_for通过Item表单添加ItemVariant字段,但是使用:item_variants不显示该表单。只有当我使用单数时才会显示。我检查了我的关联,它们似乎是正确的,这可能与嵌套在公司下的项目有关,还是我遗漏了其他东西?提前致谢。注意:下面的代码片段中省略了不相关的代码。编辑:不知道这是否相关,但我正在使用CanCan进行身份验证。routes.rbresources:companiesdoresources:itemsenditem.rbclassItemi
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的