import pyspark.pandas as ps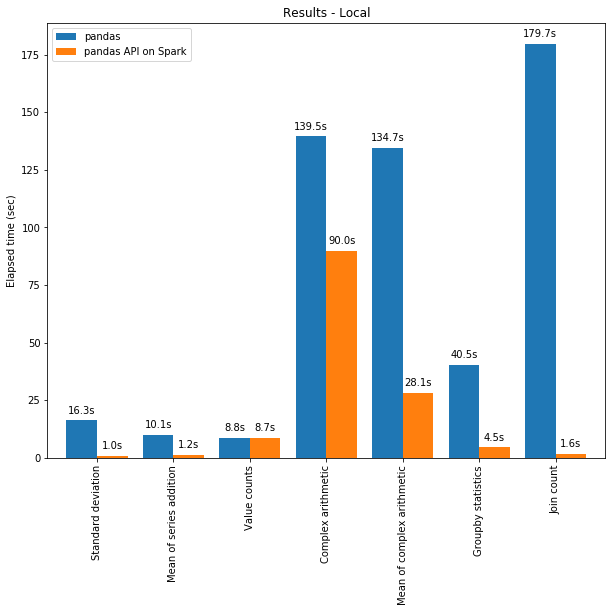 多线程和 Spark SQL Catalyst Optimizer 都有助于优化性能。例如,Join count 操作在整个阶段代码生成时快 4 倍:没有代码生成时为 5.9 秒,代码生成时为 1.6 秒。Spark 在链式操作(chaining operations)中具有特别显着的优势。Catalyst 查询优化器可以识别过滤器以明智地过滤数据并可以应用基于磁盘的连接(disk-based joins),而 Pandas 倾向于每一步将所有数据加载到内存中。现在是不是迫不及待的想尝试如何在 Spark 上使用 Pandas API 编写一些代码?我们现在就开始吧!
多线程和 Spark SQL Catalyst Optimizer 都有助于优化性能。例如,Join count 操作在整个阶段代码生成时快 4 倍:没有代码生成时为 5.9 秒,代码生成时为 1.6 秒。Spark 在链式操作(chaining operations)中具有特别显着的优势。Catalyst 查询优化器可以识别过滤器以明智地过滤数据并可以应用基于磁盘的连接(disk-based joins),而 Pandas 倾向于每一步将所有数据加载到内存中。现在是不是迫不及待的想尝试如何在 Spark 上使用 Pandas API 编写一些代码?我们现在就开始吧!# import Pandas-on-Spark
import pyspark.pandas as ps
# 使用 Pandas-on-Spark 创建一个 DataFrame
ps_df = ps.DataFrame(range(10))
# 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe
pd_df = ps_df.to_pandas()
# 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe
ps_df = ps.from_pandas(pd_df)# 使用 Pandas-on-Spark 创建一个 DataFrame
ps_df = ps.DataFrame(range(10))
# 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe
spark_df = ps_df.to_spark()
# 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe
ps_df_new = spark_df.to_pandas_on_spark()>>> sdf = spark.createDataFrame([
... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)),
... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date')
>>> sdfDataFrame[tinyint: tinyint, decimal: decimal(10,0),
float: float, double: double, integer: int,
long: bigint, short: smallint, timestamp: timestamp,
string: string, boolean: boolean, date: date]psdf = sdf.pandas_api()
psdf.dtypestinyint int8
decimal object
float float32
double float64
integer int32
long int64
short int16
timestamp datetime64[ns]
string object
boolean bool
date object
dtype: object# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("Spark") \
.getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps# SPARK
sdf = spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()# SPARK
sdf.dropDuplicates(["sepal_length","sepal_width"]).show()
# PANDAS-ON-SPARK
pdf[["sepal_length", "sepal_width"]].drop_duplicates()# SPARK
sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show()
# PANDAS-ON-SPARK
pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()# SPARK
sdf.filter(sdf.flower_type == "Iris-virginica").count()
# PANDAS-ON-SPARK
pdf.loc[pdf.flower_type == "Iris-virginica"].count()# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()#SPARK
sdf.union(sdf)
# PANDAS-ON-SPARK
pdf.append(pdf)DataFrame.transform()
DataFrame.apply()
DataFrame.pandas_on_spark.transform_batch()
DataFrame.pandas_on_spark.apply_batch()
Series.pandas_on_spark.transform_batch()# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return pser + 1 # 应该总是返回与输入相同的长度。
psdf.transform(pandas_plus)
# apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser):
return pser[pser % 2 == 1] # 允许任意长度
psdf.apply(pandas_plus)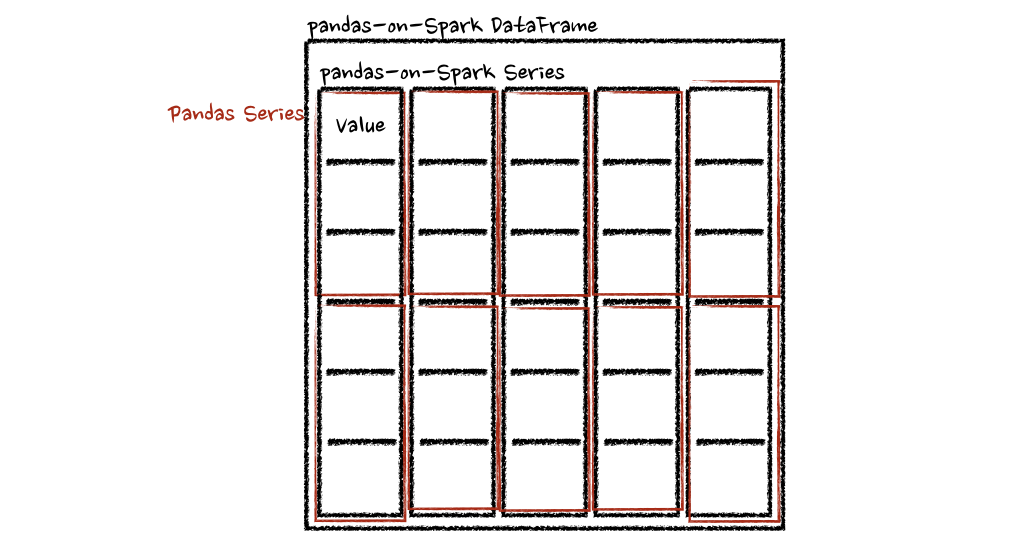 在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return sum(pser) # 允许任意长度
psdf.apply(pandas_plus, axis='columns')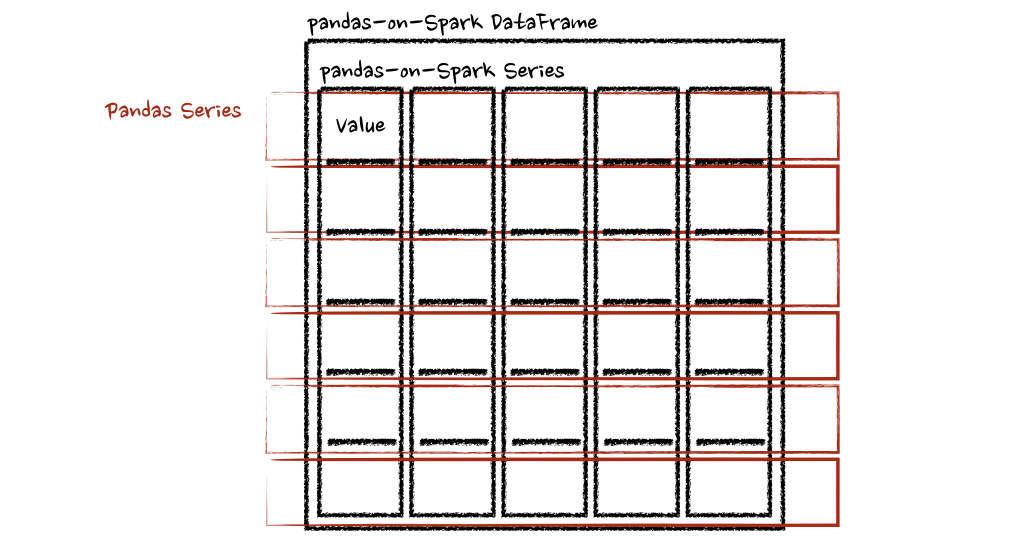
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1 # 应该总是返回与输入相同的长度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1] # 允许任意长度
psdf.pandas_on_spark.apply_batch(pandas_plus)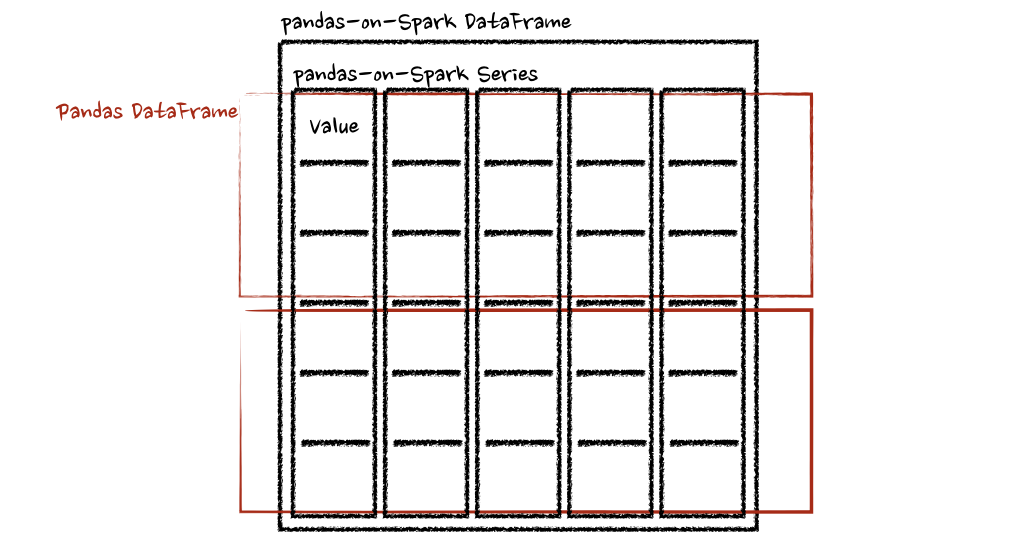
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]Reference 'a' is ambiguous, could be: a, a.;import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})Reference 'a' is ambiguous, could be: a, a.;from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate()
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdfa A
0 1 3
1 2 4>>> import pandas as pd
>>> max(pd.Series([1, 2, 3]))
3
>>> min(pd.Series([1, 2, 3]))
1
>>> sum(pd.Series([1, 2, 3]))
6>>> import pyspark.pandas as ps
>>> ps.Series([1, 2, 3]).max()
3
>>> ps.Series([1, 2, 3]).min()
1
>>> ps.Series([1, 2, 3]).sum()
6import pandas as pd
data = []
countries = ['London', 'New York', 'Helsinki']
pser = pd.Series([20., 21., 12.], index=countries)
for temperature in pser:
assert temperature > 0
if temperature > 1000:
temperature = None
data.append(temperature ** 2)
pd.Series(data, index=countries)London 400.0
New York 441.0
Helsinki 144.0
dtype: float64import pyspark.pandas as ps
import numpy as np
countries = ['London', 'New York', 'Helsinki']
psser = ps.Series([20., 21., 12.], index=countries)
def square(temperature) -> np.float64:
assert temperature > 0
if temperature > 1000:
temperature = None
return temperature ** 2
psser.apply(square)London 400.0
New York 441.0
Helsinki 144.0只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建
在我的一些Controller中,我有一个before_filter检查用户是否登录?用于CRUD操作。application.rbdeflogged_in?unlesscurrent_userredirect_toroot_pathendendprivatedefcurrent_user_sessionreturn@current_user_sessionifdefined?(@current_user_session)@current_user_session=UserSession.findenddefcurrent_userreturn@current_userifdefine
require'pp'p*1..10这会打印出1-10。为什么这么简洁?您还可以用它做什么? 最佳答案 它是“splat”运算符。它可用于分解数组和范围并在赋值期间收集值。这里收集赋值中的值:a,*b=1,2,3,4=>a=1b=[2,3,4]在此示例中,内部数组([3,4])中的值被分解并收集到包含数组中:a=[1,2,*[3,4]]=>a=[1,2,3,4]您可以定义将参数收集到数组中的函数:deffoo(*args)pargsendfoo(1,2,"three",4)=>[1,2,"three",4]
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。在我在网上找到的每个基准测试中,Ruby似乎都很慢,比Java慢得多。Ruby的人只是说这无关紧要。您能举个例子说明RubyonRails(以及Ruby本身)的速度真的无关紧要吗?
我读过的关于Ruby符号的每一篇文章都在谈论符号相对于字符串的效率。但是,这不是1970年代。我的电脑可以处理一些额外的垃圾收集。我错了吗?我拥有最新最好的奔腾双核处理器和4GBRAM。我认为这应该足以处理一些字符串。 最佳答案 您的计算机可能能够处理“一点点额外的垃圾收集”,但是当“一点点”发生在运行数百万次的内部循环中时呢?如果它在内存有限的嵌入式系统上运行呢?有很多地方你可以随意使用字符串,但在某些地方你不能。这完全取决于上下文。 关于ruby-现代计算机的功能是否不足以处理字符串
我正在使用Windows并尝试运行一个现有的功能包,该功能包最初是在MacOS上构建的,这允许他们通过使用带空格的"\"来解决问题。我正在使用Ruby2.2.3和Cucumber。功能名称包含空格,我无法更改它。我尝试使用""和''来绕过空白,但每次都有同样的问题。这是问题的一个例子。如果我运行:cucumberfeatures/'Namecontainingwhitespaces.feature'它工作正常。但是当我运行时:cucumber-pmy_profile和cucumber.yml包含:my_profile:features/'Namecontainingwhitespace
单元测试的好方法是测试脚本在执行之间保持正确数据的能力——在使用Ctrl-C终止脚本然后重新运行之后?是否有针对执行类似操作的现有模块或脚本的任何测试可以针对最佳实践进行审查? 最佳答案 像http://avdi.org/devblog/2010/07/19/greenletters-painless-automation-and-testing-for-command-line-applications/一样使用库或者期望、运行、终止并重新运行您的程序,并检查它是否运行正确。好的做法是将程序设计为独立的模块,每个模块都经过良好测试
平时开发中我们经常会遇到这样的需求,在一个不限高度的盒子中会有很多内容,如果全部显示用户体验会非常不好,所以可以先折叠起来,当内容达到一定高度时,显示展开更多按钮,点击即可显示全部内容,先来看看效果图: 这样做用户体验瞬间得到提升,接下来看看具体细节。0">主要操作在内容这里{{item.username}},……展开更多样式大家可依据自己项目需求进行设计,这里就不贴了,主要说几个关键的。1、在data中定义三个属性isShowMore:false, //控制展开更多的显示与隐藏textHeight:null, //框中内容的高度status:false, //内容状态是否打开2.计算内容是否
我有这段代码:date_counter=Time.mktime(2011,01,01,00,00,00,"+05:00")@weeks=Array.new(date_counter..Time.now).step(1.week)do|week|logger.debug"WEEK:"+week.inspect@weeks从技术上讲,代码有效,输出:SatJan0100:00:00-05002011SatJan0800:00:00-05002011SatJan1500:00:00-05002011etc.但是执行时间完全是垃圾!每周计算大约需要四秒钟。我在这段代码中是否遗漏了一些奇怪的低效