 简而言之,他能远程让被黑掉的特斯拉汽车执行:
简而言之,他能远程让被黑掉的特斯拉汽车执行: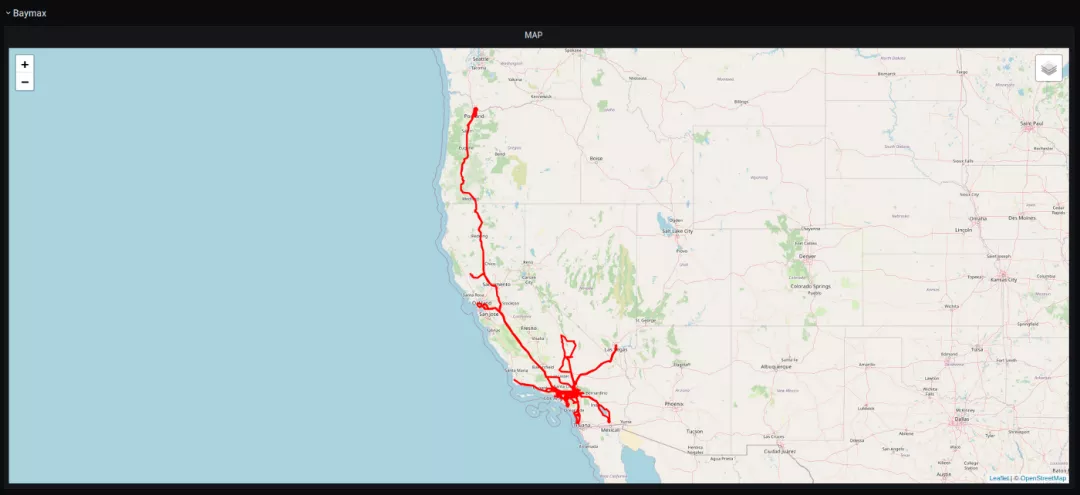 一辆特斯拉Model Y在加州
一辆特斯拉Model Y在加州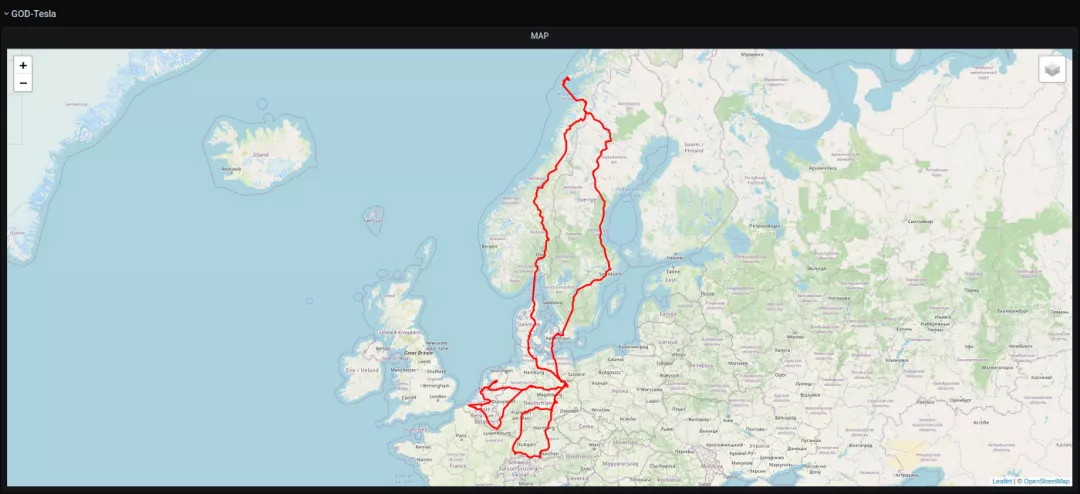 一辆特斯拉在欧洲
一辆特斯拉在欧洲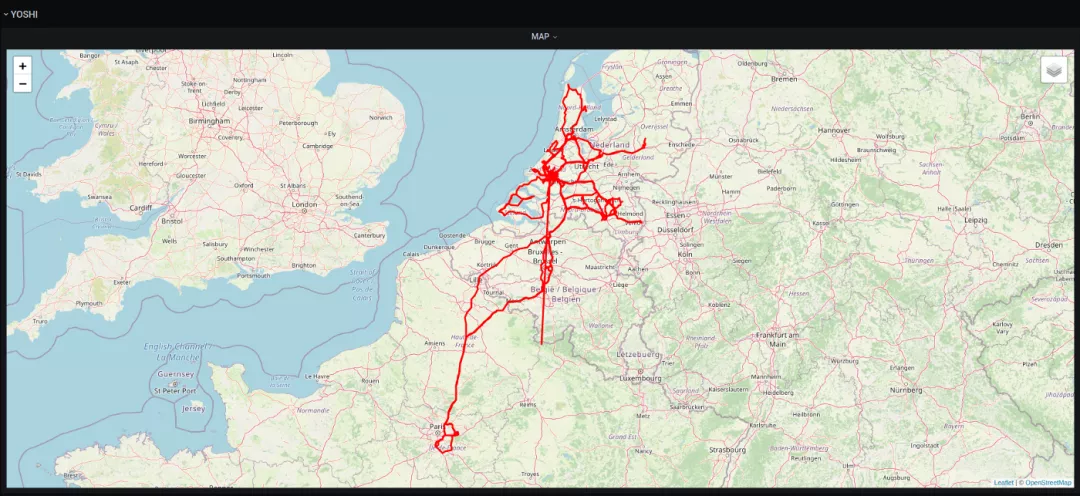 一辆特斯拉Model 3在比利时(大部分时间)
一辆特斯拉Model 3在比利时(大部分时间)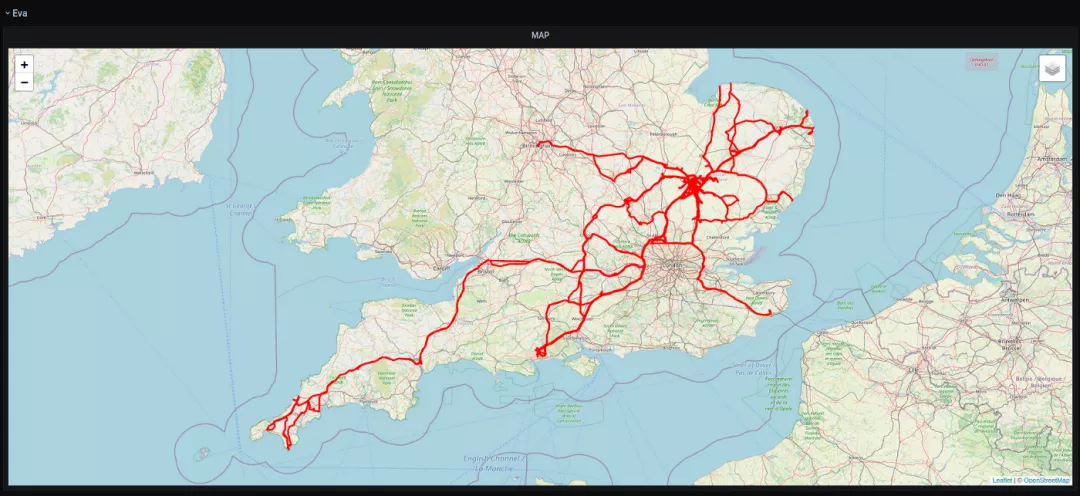 一辆特斯拉Model 3在英国(数过伦敦而不入)
一辆特斯拉Model 3在英国(数过伦敦而不入)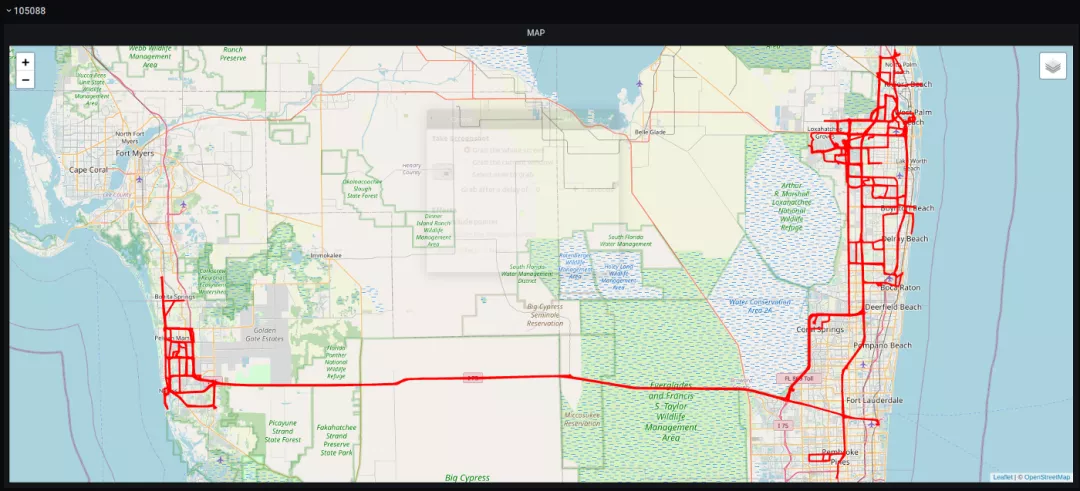 一辆特斯拉Model Y在佛罗里达州
一辆特斯拉Model Y在佛罗里达州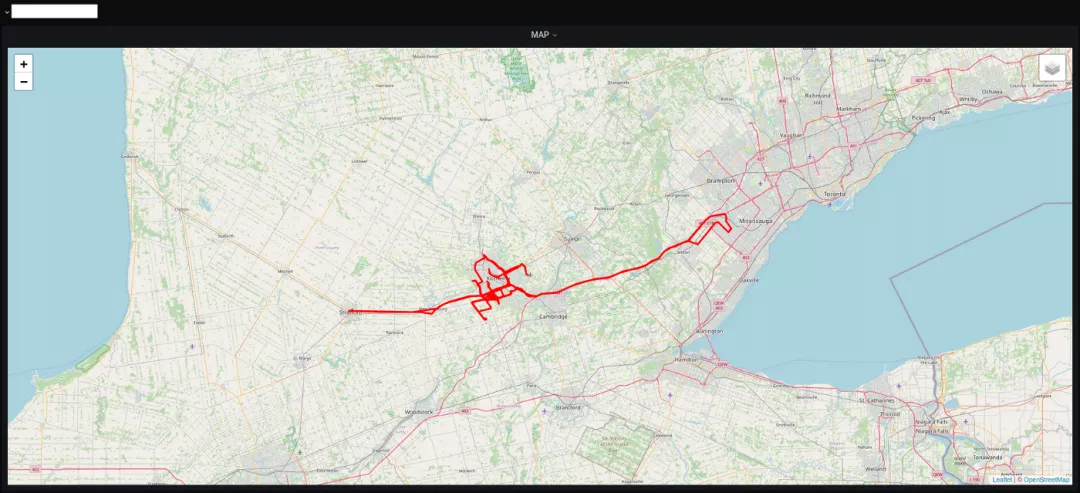 一辆特斯拉Model Y在加拿大的基奇纳及周边地区Colombo在几个小时内就找到了来自13个国家的25辆以上的特斯拉。包括德国、比利时、芬兰、丹麦、英国、美国、加拿大、意大利、爱尔兰、法国、奥地利和瑞士。还有大约至少30多个来自中国,不过Colombo非常谨慎,并没有对这些车下手。
一辆特斯拉Model Y在加拿大的基奇纳及周边地区Colombo在几个小时内就找到了来自13个国家的25辆以上的特斯拉。包括德国、比利时、芬兰、丹麦、英国、美国、加拿大、意大利、爱尔兰、法国、奥地利和瑞士。还有大约至少30多个来自中国,不过Colombo非常谨慎,并没有对这些车下手。 在做一些基本的子域列举时,他发现了一个「backup.redacted.com」域名。但除了一个普通的「this works」页面外,没有任何东西在运行。在进行了一个非常简单的nmap扫描之后产生了一些结果,但只是发现了remoteanything和一些「游戏服务器」端口。事情似乎有些奇怪。
在做一些基本的子域列举时,他发现了一个「backup.redacted.com」域名。但除了一个普通的「this works」页面外,没有任何东西在运行。在进行了一个非常简单的nmap扫描之后产生了一些结果,但只是发现了remoteanything和一些「游戏服务器」端口。事情似乎有些奇怪。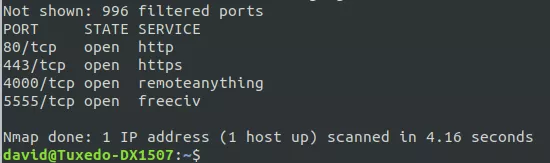 Colombo尝试通过telnet连接,但没有成功。
Colombo尝试通过telnet连接,但没有成功。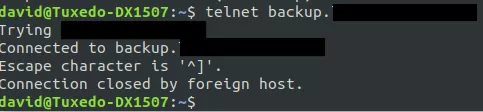 不过,当通过浏览器访问时,就会发现这些端口竟然指向了——TeslaMate。
不过,当通过浏览器访问时,就会发现这些端口竟然指向了——TeslaMate。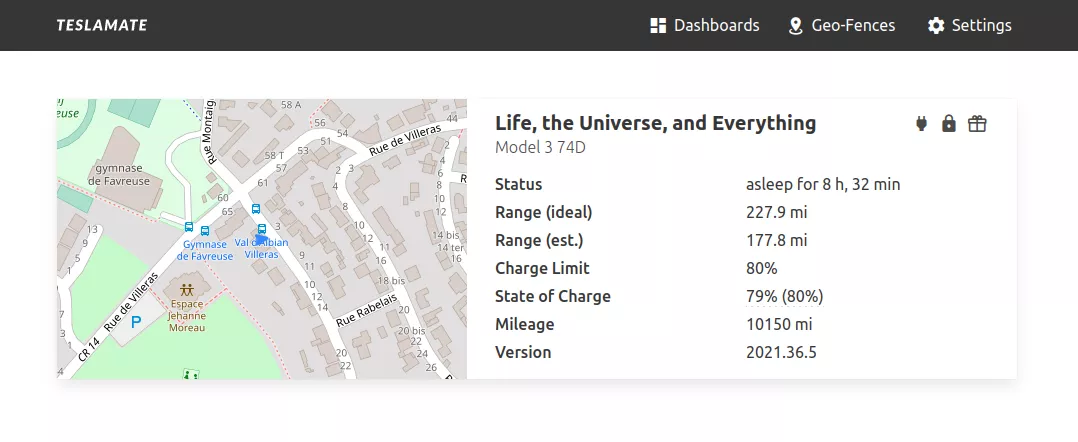 现在看起来,就有趣多了。然而,尝试访问Dashboard时,只给了一个错误,并没有成功。
现在看起来,就有趣多了。然而,尝试访问Dashboard时,只给了一个错误,并没有成功。 但是,好奇心再一次发挥了作用。TeslaMate是特斯拉的一个自我托管的数据记录器,而且它是开源的。理论上,它只用于提取数据和存储以及显示,并不能运行任何命令,比如使用TeslaMate解锁车门。通过查看Docker文件,Colombo发现它还带来了一个Grafana的安装。端口5555,访问了一下试试?
但是,好奇心再一次发挥了作用。TeslaMate是特斯拉的一个自我托管的数据记录器,而且它是开源的。理论上,它只用于提取数据和存储以及显示,并不能运行任何命令,比如使用TeslaMate解锁车门。通过查看Docker文件,Colombo发现它还带来了一个Grafana的安装。端口5555,访问了一下试试?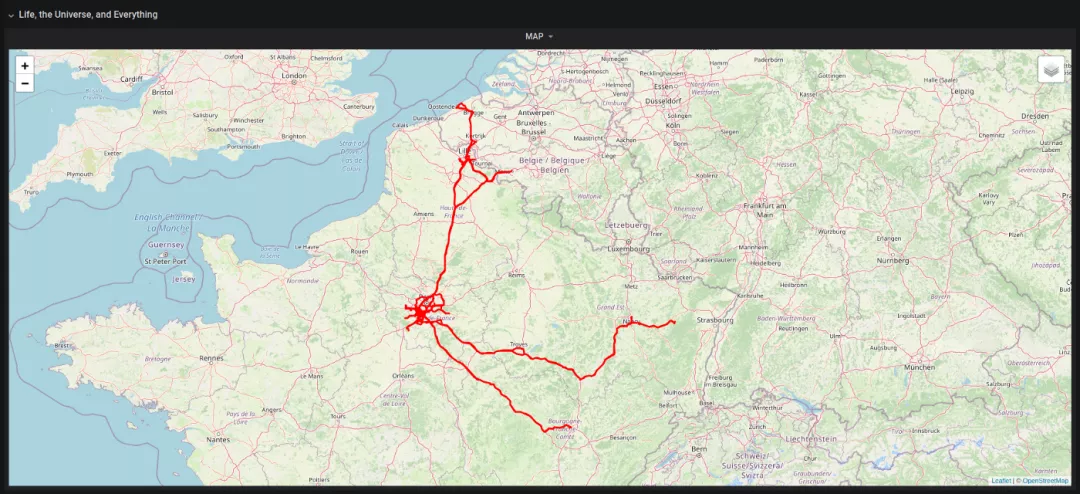 果然成了。进入之后Colombo看到了大量的数据,包括特斯拉途径的路线、曾充电位置、目前的位置、惯常停车位置、车辆行进时段、出行的速度、导航请求、软件更新的历史,甚至特斯拉汽车周围的天气历史等等。这真是......不妙啊。Colombo表示,显然自己不应该从这个端口知道,这家SaaS公司的CTO去年去哪里度假了。那么,如果TeslaMate能够提取所有的车辆数据,它可能也有办法向特斯拉发送命令?在产生这种想法之后,Colombo花了点时间阅读TeslaMate的源代码,以便弄清楚认证是如何进行的、特斯拉的证书如何在应用程序中流动、以及它在哪里存储用户的API密钥。结果有些出乎意料,TeslaMate将API密钥保存在了和所有其他数据相同的位置,既没有单独存储,也没有加密。
果然成了。进入之后Colombo看到了大量的数据,包括特斯拉途径的路线、曾充电位置、目前的位置、惯常停车位置、车辆行进时段、出行的速度、导航请求、软件更新的历史,甚至特斯拉汽车周围的天气历史等等。这真是......不妙啊。Colombo表示,显然自己不应该从这个端口知道,这家SaaS公司的CTO去年去哪里度假了。那么,如果TeslaMate能够提取所有的车辆数据,它可能也有办法向特斯拉发送命令?在产生这种想法之后,Colombo花了点时间阅读TeslaMate的源代码,以便弄清楚认证是如何进行的、特斯拉的证书如何在应用程序中流动、以及它在哪里存储用户的API密钥。结果有些出乎意料,TeslaMate将API密钥保存在了和所有其他数据相同的位置,既没有单独存储,也没有加密。 那么,如果Grafana可以访问车辆数据,而API密钥存储在车辆数据一边,Grafana可以读取和输出API密钥吗?用Grafana Explore来运行自定义查询试试?但这需要认证,真是无奈。不过,有没有听说过这个遥远的网络安全问题叫做「默认密码」?
那么,如果Grafana可以访问车辆数据,而API密钥存储在车辆数据一边,Grafana可以读取和输出API密钥吗?用Grafana Explore来运行自定义查询试试?但这需要认证,真是无奈。不过,有没有听说过这个遥远的网络安全问题叫做「默认密码」? 是的,TeslaMate Docker的Grafana安装时带有默认凭证。也有可能在没有通过Grafana端登录的情况下,以未经授权的匿名用户身份查询token。试着用admin:admin登录,果然成功了。为Grafana(Explore)建立一个查询字符串,并查询API token,这之后就没有什么神奇了。所以说,软件用默认值初始化的默认值是为了让管理员方便去更改的,实际上并不安全。开发者通常选择默认值,让软件在开箱后尽可能地开放和易于使用。然而,当默认值不安全而管理员不改变它时,这种便利是有代价的。
是的,TeslaMate Docker的Grafana安装时带有默认凭证。也有可能在没有通过Grafana端登录的情况下,以未经授权的匿名用户身份查询token。试着用admin:admin登录,果然成功了。为Grafana(Explore)建立一个查询字符串,并查询API token,这之后就没有什么神奇了。所以说,软件用默认值初始化的默认值是为了让管理员方便去更改的,实际上并不安全。开发者通常选择默认值,让软件在开箱后尽可能地开放和易于使用。然而,当默认值不安全而管理员不改变它时,这种便利是有代价的。 获得对世界各地的随机特斯拉的访问的过程:
获得对世界各地的随机特斯拉的访问的过程: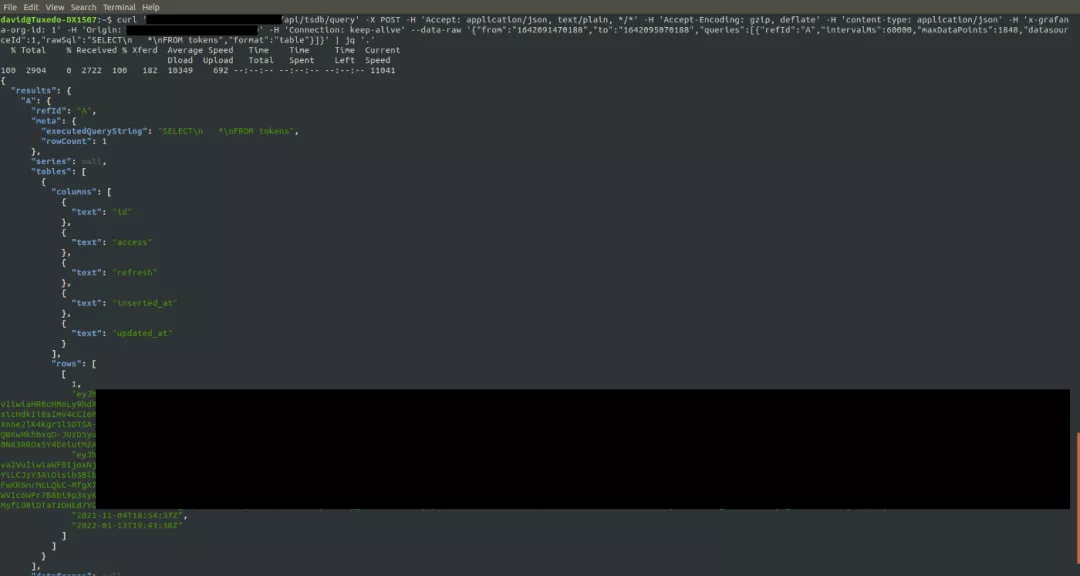 那么,如果发现了这样的漏洞,该怎么做?你应该将漏洞报告给负责的团队。如果找不到又该怎么办呢?那就发条推特吧~
那么,如果发现了这样的漏洞,该怎么做?你应该将漏洞报告给负责的团队。如果找不到又该怎么办呢?那就发条推特吧~ 抛开玩笑话不谈,Colombo表示,自己发那条推特只是因为很沮丧。花了一整天寻找后,只能联系到两位特斯拉车主并且告知他们。另外,对于这条推文可能引起的所有混乱和猜测,Colombo深表歉意。
抛开玩笑话不谈,Colombo表示,自己发那条推特只是因为很沮丧。花了一整天寻找后,只能联系到两位特斯拉车主并且告知他们。另外,对于这条推文可能引起的所有混乱和猜测,Colombo深表歉意。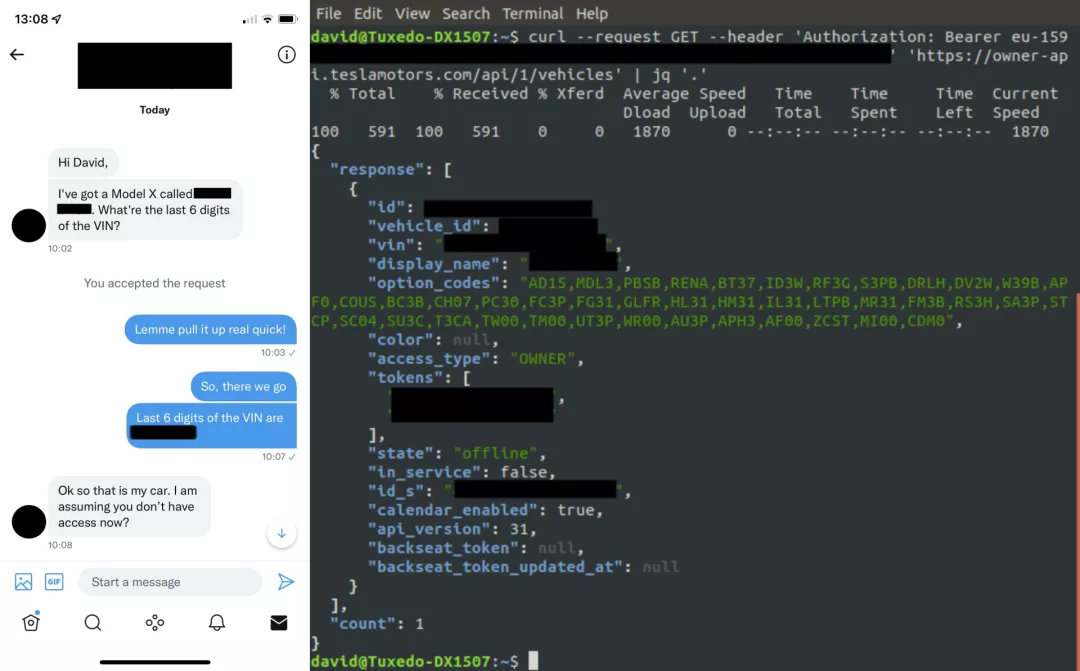 多亏了这条推文,Colombo找到了另一位来自爱尔兰的特斯拉车主。
多亏了这条推文,Colombo找到了另一位来自爱尔兰的特斯拉车主。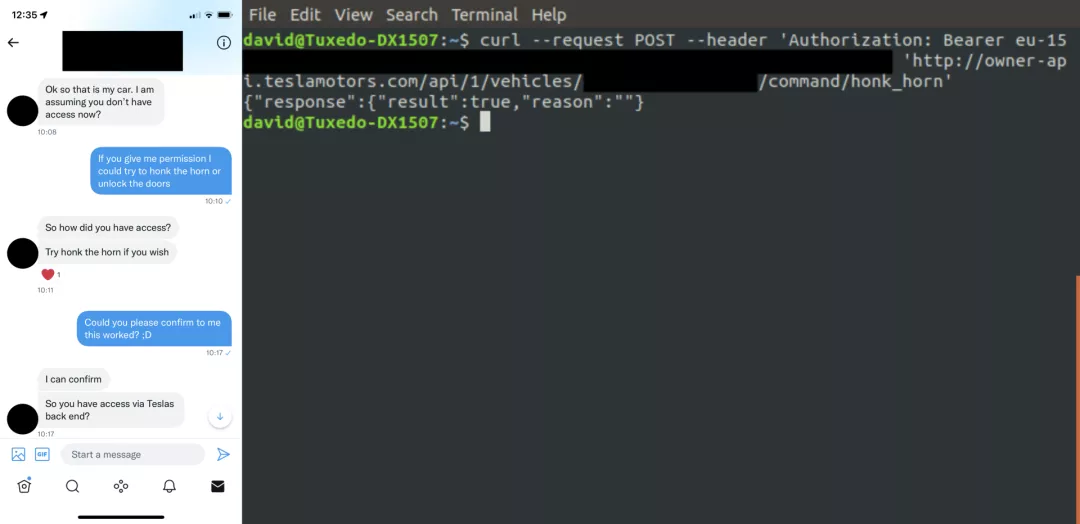 然而,车主多次重置特斯拉帐户密码后,也没能撤销API token。好在经过了4小时的不懈努力,终于通过一个未被记录的API端点撤销了密钥。联系特斯拉当Colombo发现没有合法的途径找到其他受影响的车主之后,便和特斯拉产品安全团队取得了联系。(推特上有网友「支招」,在特斯拉汽车屏幕上放「你被黑了」的视频)特斯拉表示他们正在调查这个问题,然后在不久之后就撤销了所有受影响的和遗留的token。据特斯拉安全团队称,截至2022年1月13日,所有被影响的用户应该都收到了电子邮件通知。所以如果特斯拉车主曾经安装过TeslaMate,就去检查一下你的邮箱。
然而,车主多次重置特斯拉帐户密码后,也没能撤销API token。好在经过了4小时的不懈努力,终于通过一个未被记录的API端点撤销了密钥。联系特斯拉当Colombo发现没有合法的途径找到其他受影响的车主之后,便和特斯拉产品安全团队取得了联系。(推特上有网友「支招」,在特斯拉汽车屏幕上放「你被黑了」的视频)特斯拉表示他们正在调查这个问题,然后在不久之后就撤销了所有受影响的和遗留的token。据特斯拉安全团队称,截至2022年1月13日,所有被影响的用户应该都收到了电子邮件通知。所以如果特斯拉车主曾经安装过TeslaMate,就去检查一下你的邮箱。 然而,特斯拉安全团队第二次撤销token后,一些特斯拉访问token仍然公开在互联网上,可能是因为用户又登录了易受攻击的TeslaMate.因此,Colombo写了一个Python脚本来自动从易受攻击的实例中撤销暴露的访问token。坏消息是,第3版token好像没有办法撤销。
然而,特斯拉安全团队第二次撤销token后,一些特斯拉访问token仍然公开在互联网上,可能是因为用户又登录了易受攻击的TeslaMate.因此,Colombo写了一个Python脚本来自动从易受攻击的实例中撤销暴露的访问token。坏消息是,第3版token好像没有办法撤销。
我已经开始学习Ruby,我已经阅读了一些教程,甚至还买了一本书(“ProgrammingRuby1.9-ThePragmaticProgrammers'Guide”),我遇到了一些以前从未见过的新东西使用我知道的任何其他语言(我是一名PHP网络开发人员)。block和过程。我想我明白它们是什么,但我不明白的是为什么它们如此伟大,以及我应该在何时何地使用它们。我到处都看到他们说block和过程是Ruby中的一个很棒的特性,但我不理解它们。这里有人能给像我这样的Ruby新手一些解释吗? 最佳答案 block有很多好处。电梯演讲:bloc
rails中View的解析过程是怎样的?我对View中erb标记中原始html与ruby代码的解析顺序部分感兴趣。我认为这是View代码被解析并最终发送给请求者的顺序:Controller调用ViewView代码从上到下解析当Rails在解析过程中遇到erb标记时:rails解析它并将结果附加到解析的html(这包括erb标签引用助手)一旦整个View被解析,整体结果将发送给请求者这似乎并非如此。看来View代码会扫描任何erb片段并首先解析那些片段(包括对助手的引用)。之后,rails然后从上到下解析所有View代码并将结果发送给请求者。以这个View为例:#_form.html
我正在尝试将ruby-debug19与Ruby1.9.1p376一起使用,但出现以下错误:test.rb:2:in`require':nosuchfiletoload--ruby-debug19(LoadError)fromtest.rb:2:in`'这是测试.rb:require'rubygems'require'ruby-debug19'这是“gemlist”的输出:***LOCALGEMS***ruby-debug19(0.11.6)(etc.)因此运行“rubytest.rb”会产生上述错误。我做错了吗?我认为这是运行ruby-debug19的正确方法(通过包含gem并
快速导航(持续更新中…)Cesium源码解析一(terrain文件的加载、解析与渲染全过程梳理)Cesium源码解析二(metadataAvailability的含义)Cesium源码解析三(metadata元数据拓展中行列号的分块规则解析)Cesium源码解析四(Quantized-Mesh(.terrain)格式文件在CesiumJS和UE中加载情况的对比)目录1.前言2.本篇的由来3.terrain文件的加载3.1更新环境3.2更新和执行渲染命令3.3数据优化3.4结束当前帧4.总结1.前言 目前市场上三维比较火的实现方案主要有两种,b/s的方案主要是Cesium,c/s的方案主要是u
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
听说PostgreSQL的可以用Ruby写存储过程但我一直没能找到更多关于它的信息,教人们如何实际去做。有人可以为此推荐好的资源。谢谢 最佳答案 显然,您需要安装PL/Ruby。之后,你可以写:CREATEFUNCTIONruby_max(int4,int4)RETURNSint4AS'ifargs[0].to_i>args[1].to_ireturnargs[0]elsereturnargs[1]end'LANGUAGE'plruby';查看其GitHubrepository安装说明。
我是Ruby新手。我正在学习ruby中的抽象原则。据我了解,过程抽象是对用户隐藏实现细节,或者只是专注于要点而忽略细节。我关心的是如何实现它1)是不是一个简单的函数调用就这样#functiontosortarray#@paramsarray[Array]tobesortdefmy_sort(array)returnarrayifarray.sizearray[i+1]array[i],array[i+1]=array[i+1],array[i]swapped=trueendendendarrayend然后这样调用sorted_array=my_sort([12,34,123,43,
我正在尝试找到一种更好的方法将IRB与我的常规ruby开发集成。目前我很少在我的代码中使用IRB。我只用它来验证语法或尝试一些小的东西。我知道我可以将我自己的代码加载到ruby中作为一个require'mycode'但这通常不符合我的编程风格。有时我要检查的变量超出范围或在循环内。有没有一种简单的方法可以启动我的脚本并在IRB内的某个点卡住?我想我正在寻找一种更简单的方法来调试我的ruby代码而不破坏我的F5(编译)键。也许有经验的ruby开发者可以和我分享一个更精简的开发方法。 最佳答案 安装ruby-debugg
为什么带有splat参数的Ruby(2.0)过程/block的行为与方法和lambda不同?deffoo(ids,*args)pidsendfoo([1,2,3])#=>[1,2,3]bar=lambdado|ids,*args|pidsendbar.call([1,2,3])#=>[1,2,3]baz=procdo|ids,*args|pidsendbaz.call([1,2,3])#=>1defqux(ids,*args)yieldids,*argsendqux([1,2,3]){|ids,*args|pids}#=>1这是对此行为的确认,但没有解释:http://makandra
我正在尝试创建一个haml模板,该模板使用我的ruby应用程序中的一些数据来填充一些内容。是否可以将参数传递给haml以使其正确呈现?以下是我获取haml模板并呈现它的方式:template=File.open('path/to/template.haml')html=Haml::Engine.new(template.read).render那么,是否可以将对象从本地Ruby脚本传递到模板文件中,以便正确呈现页面?或者,我可以让haml文件拉入对象吗?如果这不起作用,我唯一的其他想法是将模板构建为本地字符串,这对我来说似乎更乏味。那么,是否有一种不同的编码模式可以更有效地完成这项