官方文档链接:MultiheadAttention — PyTorch 1.12 documentation
目录
MultiheadAttention,翻译成中文即为多注意力头,是由多个单注意头拼接成的
它们的样子分别为:👇
单头注意力的图示如下:
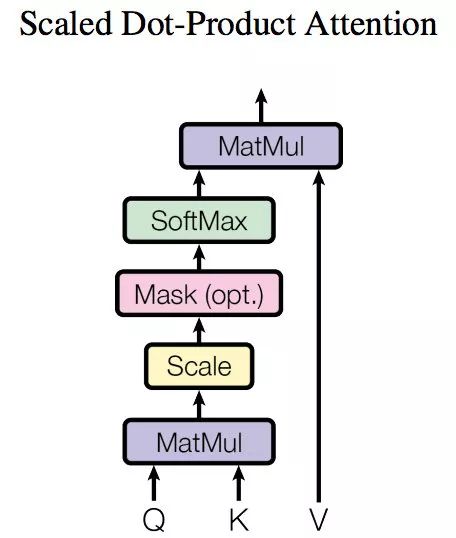
整体称为一个单注意力头,因为运算结束后只对每个输入产生一个输出结果,一般在网络中,输出可以被称为网络提取的特征,那我们肯定希望提取多种特征,[ 比如说我输入是一个修狗狗图片的向量序列,我肯定希望网络提取到特征有形状、颜色、纹理等等,所以单次注意肯定是不够的 ]
于是最简单的思路,最优雅的方式就是将多个头横向拼接在一起,每次运算我同时提到多个特征,所以多头的样子如下:
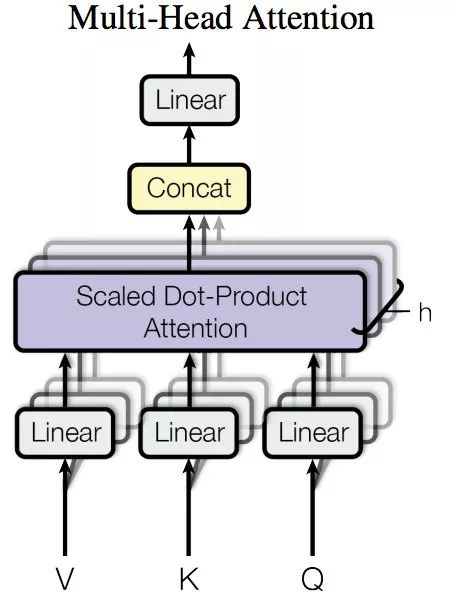
其中的紫色长方块(Scaled Dot-Product Attention)就是上一张单注意力头,内部结构没有画出,如果拼接h个单注意力头,摆放位置就如图所示。
因为是拼接而成的,所以每个单注意力头其实是各自输出各自的,所以会得到h个特征,把h个特征拼接起来,就成为了多注意力的输出特征。

首先可以看出我们调用的时候,只要写torch.nn.MultiheadAttention就好了,比如👇
import torch
import torch.nn as n
# 先决定参数
dims = 256 * 10 # 所有头总共需要的输入维度
heads = 10 # 单注意力头的总共个数
dropout_pro = 0.0 # 单注意力头
# 传入参数得到我们需要的多注意力头
layer = torch.nn.MultiheadAttention(embed_dim = dims, num_heads = heads, dropout = dropout_pro)embed_dim - Total dimension of the model 模型的总维度(总输入维度)
所以这里应该输入的是每个头输入的维度×头的数量
num_heads - Number of parallel attention heads. Note that embed_dim will be split across num_heads (i.e. each head will have dimension embed_dim // num_heads).
num_heads即为注意头的总数量
注意看括号里的这句话,每个头的维度为 embed_dim除num_heads
也就是说,如果我的词向量的维度为n,(注意不是序列的维度),我准备用m个头提取序列的特征,则embed_dim这里的值应该是n×m,num_heads的值为m。
【更新】这里其实还是有点小绕的,虽然官文说每个头的维度需要被头的个数除,但是自己在写网络定义时,如果你在输入到多注意力头前到特征为256(举例),这里定义时仍然写成256即可!!,假如你用了4个头,在源码里每个头的特征确实会变成64维,最后又重新拼接成为64乘4=256并输出,但是这个内部过程不用我们自己操心。
还有其他的一些参数可以手动设置:
dropout – Dropout probability on attn_output_weights. Default: 0.0 (no dropout).
bias – If specified, adds bias to input / output projection layers. Default: True.
add_bias_kv – If specified, adds bias to the key and value sequences at dim=0. Default: False.
add_zero_attn – If specified, adds a new batch of zeros to the key and value sequences at dim=1. Default: False.
kdim – Total number of features for keys. Default: None (uses kdim=embed_dim).
vdim – Total number of features for values. Default: None (uses vdim=embed_dim).
batch_first – If True, then the input and output tensors are provided as (batch, seq, feature). Default: False (seq, batch, feature).
如果看定义的话应该可以发现:torch.nn.MultiheadAttention是一个类
我们刚刚输入多注意力头的参数,只是’实例化‘出来了我们想要规格的一个多注意力头,
那么想要在训练的时候使用,我们就需要给它喂入数据,也就是调用forward函数,完成前向传播这一动作。
forward函数的定义如下:
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None, average_attn_weights=True)
下面是所传参数的解读👇
前三个参数就是attention的三个基本向量元素Q,K,V
query – Query embeddings of shape for unbatched input,
when
batch_first=False or when
batch_first=True, where is the target sequence length,
is the batch size, and
is the query embedding dimension
embed_dim. Queries are compared against key-value pairs to produce the output. See “Attention Is All You Need” for more details.
翻译一下就是说,如果输入不是以batch形式的,query的形状就是,
是目标序列的长度,
就是query embedding的维度,也就是输入词向量被变换成q后,q的维度,这个注释说是embed_dim, 说明输入词向量和q维度一致;
若是以batch形式输入,且batch_first=False 则query的形状为,若
batch_first=True,则形状为。【batch_first是’实例化‘时可以设置的,默认为False】
key – Key embeddings of shape for unbatched input,
when
batch_first=False or when
batch_first=True, where S is the source sequence length,is the batch size, and
is the key embedding dimension
kdim. See “Attention Is All You Need” for more details.
key也就是K,同理query,以batch形式,且batch_first=False,则key的形状为。
是key embedding的维度,默认也是与
相同,
则是原序列的长度(source sequence length)
value – Value embeddings of shape for unbatched input,
when
batch_first=False or when
batch_first=True, where is the source sequence length,
is the batch size, and
is the value embedding dimension
vdim. See “Attention Is All You Need” for more details.
value是V,与key同理
其他的参数先不赘述
key_padding_mask – If specified, a mask of shape (N, S)(N,S) indicating which elements within key to ignore for the purpose of attention (i.e. treat as “padding”). For unbatched query, shape should be (S)(S). Binary and byte masks are supported. For a binary mask, a True value indicates that the corresponding key value will be ignored for the purpose of attention. For a byte mask, a non-zero value indicates that the corresponding key value will be ignored.
need_weights – If specified, returns attn_output_weights in addition to attn_outputs. Default: True.
attn_mask – If specified, a 2D or 3D mask preventing attention to certain positions. Must be of shape (L, S)(L,S) or (N\cdot\text{num\_heads}, L, S)(N⋅num_heads,L,S), where NN is the batch size, LL is the target sequence length, and SS is the source sequence length. A 2D mask will be broadcasted across the batch while a 3D mask allows for a different mask for each entry in the batch. Binary, byte, and float masks are supported. For a binary mask, a True value indicates that the corresponding position is not allowed to attend. For a byte mask, a non-zero value indicates that the corresponding position is not allowed to attend. For a float mask, the mask values will be added to the attention weight.
average_attn_weights – If true, indicates that the returned attn_weights should be averaged across heads. Otherwise, attn_weights are provided separately per head. Note that this flag only has an effect when need_weights=True. Default: True (i.e. average weights across heads)
层的输出格式:
attn_output - Attention outputs of shape when input is unbatched,
when
batch_first=False or when
batch_first=True, where is the target sequence length,
is the batch size, and
is the embedding dimension
embed_dim.
以batch输入,且batch_first=False,attention输出的形状为,
是目标序列长度,
是batch的大小,
是embed_dim(第一步实例化设置的)
attn_output_weights - Only returned when need_weights=True. If average_attn_weights=True, returns attention weights averaged across heads of shape ) when input is unbatched or
, where NN is the batch size,
is the target sequence length, and S is the source sequence length. If
average_weights=False, returns attention weights per head of shapewhen input is unbatched or
.
只有当need_weights的值为True时才返回此参数。
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output, attn_output_weights = multihead_attn(query, key, value)
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h