我们在上篇文章哈希表的设计原理当中已经大体说明了哈希表的实现原理,在这篇文章当中我们将自己动手实现我们自己的HashMap,完整的代码在文章末尾。
在本篇文章当中主要通过线性探测法,从最基本的数组再到HashMap当中节点的设计,一步一步的实现一个能够实现Key、Value映射的容器,写出我们自己的哈希表MyHashMap,让可以具备HashMap最常见的两个功能,put和get方法。
在上篇哈希表的设计原理当中我们已经仔细说明,在HashMap当中我们是使用数组去存储具体的数据的,那么在我们的数组当中应该存储什么样的数据呢?假设在HashMap的数组当中存储的数据类型为Node,那么这个类需要有哪些字段呢?
首先一点我们肯定需要存储Value值,因为我们最终需要通过get方法从HashMap当中取出我们所需要的值。
第二点当我们通过get方法去取值的时候是通过Key(键值)去取的,当哈希值产生冲突的时候,我们不仅需要通过哈希值确定位置,还需要通过比较通过函数get传递的Key和数组当当中存储的数据的key是否相等,因此我们需要存储键值Key。
第三点为了避免重复计算哈希值(因为有的对象的哈希值计算还是比较费时间),我们可以使用一个字段去存储计算好的哈希值。
根据以上三点我们的Node类的设计如下:
private static class Node<K, V> {
/**
* 用于存储我们计算好的 key 的哈希值
*/
final int hash;
/**
* Key Value 中的 Key 对象
*/
final K key;
/**
* Key Value 中的 Value 对象
*/
V value;
/**
* hash 是键值 key 的哈希值 key 是键 value 是值
* @param hash
* @param key
* @param value
*/
public Node(int hash, K key, V value) {
this.hash = hash;
this.key = key;
this.value = value;
}
public V setValue(V newValue) {
V oldValue = newValue;
value = newValue;
return oldValue;
}
@Override
public String toString() {
return key + "=" + value;
}
}
在讨论这个问题之前我们首先来回归一下位运算的操作。在计算机当中数据都是二进制存储那么二进制运算是如何操作的呢?
int a = 7;
int b = 3;
System.out.println(a & b); // 输出结果为3
上述代码的位运算操作如下:

进行位运算是,二进制数的对应位置进行相应的操作,&运算的结果只有两个比特位的数据都是1时,运算结果才等于1,其余的情况都为0,因此3 & 7 = 3。
通过put函数放入HashMap当中的数据首先需要将key的哈希值与数组的长度进行取余运算得到对应的下标,再将数据放入到数组对应的下标当中。但是在实际的操作当中我们将底层数组的长度设置为2的整数次幂,并且使用位运算&去进行取余数操作,而这样操作主要有一下三点原因:
&的程序执行效率,比取余%操作更加高效,需要的时间越短。2的整数次幂的时候,得到的下标越均匀,造成的哈希冲突更少。a对\(2^n\)取余数得到的结果与a跟\(2^n - 1\)进行&操作结果是相等的,即:我们现在先来解释一下第三点,令a = 127,n = 4,那么:127%16 = 15,127 & 15 = 15。

首先我们需要明白求余数的意义是什么?127对16取余,就是用127一直减去16,直到某个结果小于16为止,得到的值为求余数结果。

上图当中红框当中包括的位置就是小于16的部分

上图当中红框框住的部分是16的倍数,因此在求余数的时候上图当中红框框住的部分就没有了,都为0,只会剩下小于16的部分,这跟15进行&操作得到的结果是一致的。这也就解释了上面提到的第三条。
在第二条中我们提到了使用数组长度为2的整数次幂可以在一定程度上减少哈希冲突,因为进行下标运算的时候是与\(2^n - 1\)进行&操作,而\(2^n - 1\)的二进制表示最后一部分位置上的数都是1。
比如下图中的数据都是2的整数次幂减一之后的结果:

因为我们需要数组的长度是2的整数次幂,而我们之后在初始化函数当中会允许用户输入一个数组长度的大小,但是用户输入的数字可能不是2的整数次幂,因此我们需要将用户输入的数据变成2的整数次幂,我们可以将用户输入的数据变成大于等于这个数的最小的2的整数次幂。
比如说如果用户输入的是12我们需要将其变成16,如果输入的是28我们需要将其变成32。我们可以通过下面这个函数做到这一点:
/**
* 返回第一个大于或者等于 capacity 且为 2 的整数次幂的那个数
* @param capacity
* @return
*/
static int roundUp(int capacity) {
int n = capacity - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
// 如果最终得到的数据小于 0 则初始长度为 1
// 如果长度大于我们所允许的最大的容量 则将初始长度设置为我们
// 所允许的最大的容量
// MAXIMUM_CAPACITY = 1 << 30;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
上面的代码还是很难理解的,让我们一点一点的来分析。首先我们使用一个2的整数次幂的数进行上面移位操作的操作!

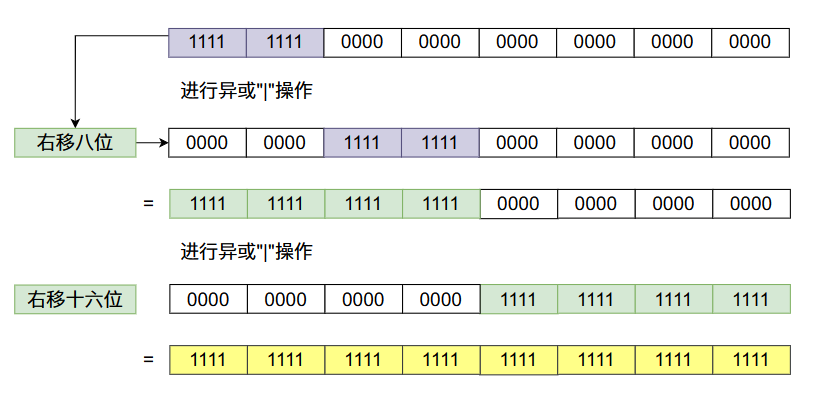
从上图当中我们会发现,我们咋一个数的二进制数的32位放一个1,经过移位之后最终32位的比特数字全部变成了1。根据上面数字变化的规律我们可以发现,任何一个比特经过上面移位的变化,这个比特后面的31个比特位都会变成1,像下图那样:
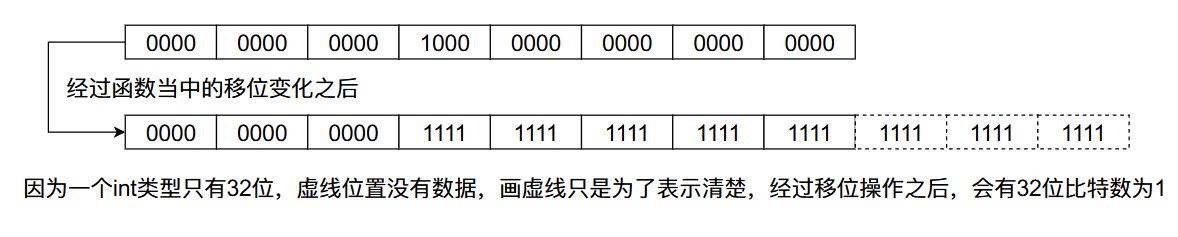
因此上述的移位操作的结果只取决于最高一位的比特值为1,移位操作后它后面的所有比特位的值全为1,而在上面函数的最后,如果最终的容量没有大于我们设置的最大容量MAXIMUM_CAPACITY,我们返回的结果就是上面移位之后的结果 +1。又因为移位之后最高位的1到最低位的1之间的比特值全为1,当我们+1之后他会不断的进位,最终只有一个比特位置是1,因此它是2的整数倍。
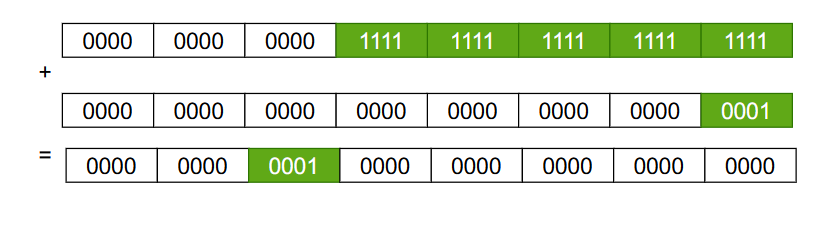
在roundUp函数当中,给初始容量减了个1,这样做的原因是让这个函数的返回值大于等于传入的参数capacity:
roundUp(4) == 4 // 就是当传入的数据已经是 2 的整数次幂的时候也返回传入的值
roundUp(3) == 4
roundUp(5) == 8
/**
* 这个 key 是 put 函数传进来的 key
* @param key
* @return
*/
static int hash(Object key) {
int h;
// 调用对象自己实现的 hashCode 方法
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
上面的函数之所以要将对象的哈希值右移16,是因为我们的数组的长度一般不会超过\(2^{16}\),因为\(2^{16}\)已经是一个比较大的值了,因此当哈希值与\(2^n - 1\)进行&操作的时候,高位通常没有使用到,这样做的原理是可以充分利用数据哈希值当中的信息。
当我们一直往HashMap加入数据的话,数组迟早会被用完,当数组用完之后我们就需要进行扩容,我们要记住一点扩容之后的数组长度也需要满足2的整数次幂,因为上面我们已经提到数组的长度需要是2的整数次幂,因此扩容之后的长度也需要保持是2的整数次幂。
但是在实际情况当中我们并不是当数组完全被使用完之后才进行扩容,因为如果数组快被使用完之后,再加入数据产生哈希冲突的可能性就会很大,因此我们通常会设置一个负载因子(load factor),当数组的使用率超过这个值的时候就进行扩容,即当(数组长度为L,数组当中数据个数为S,负载因子为F):
public class MyHashMap<K, V> {
/**
* 默认数组的容量
*/
static final int DEFAULT_CAPACITY = 16;
/**
* 默认负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 哈希表中数组的最大长度
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 真正存储数据的数组
*/
Node<K, V>[] hashTable;
/**
* 哈希表数组当中存储的数据的个数
*/
int size;
/**
* 哈希表当中的负载因子
*/
float loadFactor = 0.75f;
/**
* 哈希表扩容的阈值 = 哈希表的长度 x 负载因子
* 当超过这个值的时候进行扩容
*/
int threshold;
}
put函数的实现public void put(K key, V value) {
if (null == key)
throw new RuntimeException("哈希表的键值不能为空");
int hash = hash(key);
// 这表示使用了空参构造函数 而且是第一次调用 put 函数
if (null == hashTable) {
hashTable = (Node<K, V>[]) new Node[DEFAULT_CAPACITY];
// 计算数组长度对应的扩容阈值
threshold = (int)(hashTable.length * loadFactor);
// 进行 & 运算得到数据下标
hashTable[hash & (DEFAULT_CAPACITY - 1)] = new Node<K, V>(hash, key, value);
}else {
int n = hashTable.length;
int idx = hash & (n - 1);
// 如果数组不为空 说明已经有数据存在了
// 如果哈希值相同的话说明是同一个对象了
// 也可以进行跳出
while (null != hashTable[idx] && !key.equals(hashTable[idx].key))
idx = (idx + 1) & (n - 1);
// 如果是通过 null != hashTable[idx] 条件跳出则是新添加数据
// 如果是通过 !key.equals(hashTable[idx].key) 条件跳出
// 则是因为 put 函数的 key 已经存在这次操作是更新数据
hashTable[idx] = new Node<K, V>(hash, key, value);
}
// 如果数组当中使用过的数据超过阈值
if (++size > threshold) {
resize();
}
}
resize函数)实现 /**
* 如果你已经看懂 put 函数的代码,那这个代码就比较简单了
* 因为只是单纯的将原数组的数据重新进行哈希并且加入到新数组
*/
private void resize() {
int n = (hashTable.length << 1);
threshold = (int) (n * loadFactor);
Node<K, V>[] oldTable = hashTable;
hashTable = (Node<K, V>[]) new Node[n];
for (int i = 0; i < oldTable.length; i++) {
if (null == oldTable[i])
continue;
Node<K, V> node = oldTable[i];
int idx = node.hash & (n - 1);
while (null != hashTable[idx] && !node.key.equals(hashTable[idx].key))
idx = (idx + 1) & (n - 1);
hashTable[idx] = node;
}
}
get函数实现public V get(K key) {
if (null == key)
throw new RuntimeException("查询的键值不能为空");
int hash = hash(key);
int n = hashTable.length;
int idx = hash & (n - 1);
if (null == hashTable[idx])
return null;
// 这里同样需要进行线性探测
// 因为哈希值相同时 key 值
// 不一定相同 因为会有哈希冲突
for (;;) {
// 当数组当中的数据不为空
// 且数据当中的哈希值和传入 key
// 的哈希值相等 而且键值相等
// 就是找到了对应的数据
if (null != hashTable[idx]
&& hash == hashTable[idx].hash
&& key.equals(hashTable[idx].key))
break;
idx = (idx + 1) & (n -1);
}
return hashTable[idx].value;
}
import java.util.*;
public class MyHashMap<K, V> {
/**
* 默认数组的容量
*/
static final int DEFAULT_CAPACITY = 16;
/**
* 默认负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 哈希表中数组的最大长度
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 真正存储数据的数组
*/
Node<K, V>[] hashTable;
/**
* 哈希表数组当中存储的数据的个数
*/
int size;
/**
* 哈希表当中的负载因子
*/
float loadFactor = 0.75f;
/**
* 哈希表扩容的阈值 = 哈希表的长度 x 负载因子
* 当超过这个值的时候进行扩容
*/
int threshold;
/**
* 返回第一个大于或者等于 capacity 且为 2 的整数次幂的那个数
* @param capacity
* @return
*/
static int roundUp(int capacity) {
int n = capacity - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
// 如果最终得到的数据小于 0 则初始长度为 1
// 如果长度大于我们所允许的最大的容量 则将初始长度设置为我们
// 所允许的最大的容量
// MAXIMUM_CAPACITY = 1 << 30;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
private static class Node<K, V> {
/**
* 用于存储我们计算好的 key 的哈希值
*/
final int hash;
/**
* Key Value 中的 Key 对象
*/
final K key;
/**
* Key Value 中的 Value 对象
*/
V value;
/**
* hash 是键值 key 的哈希值 key 是键 value 是值
* @param hash
* @param key
* @param value
*/
public Node(int hash, K key, V value) {
this.hash = hash;
this.key = key;
this.value = value;
}
public V setValue(V newValue) {
V oldValue = newValue;
value = newValue;
return oldValue;
}
@Override
public String toString() {
return key + "=" + value;
}
}
public MyHashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
public MyHashMap(int initialCapacity, float loadFactor) {
if (initialCapacity <= 0) {
throw new RuntimeException("初始化长度不能小于0");
}
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
initialCapacity = roundUp(initialCapacity);
hashTable = (Node<K, V>[]) new Node[initialCapacity];
this.loadFactor = loadFactor;
threshold = (int) (loadFactor * initialCapacity);
}
public MyHashMap(int capacity) {
this(capacity, DEFAULT_LOAD_FACTOR);
}
static int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public void put(K key, V value) {
if (null == key)
throw new RuntimeException("哈希表的键值不能为空");
int hash = hash(key);
if (null == hashTable) {
hashTable = (Node<K, V>[]) new Node[DEFAULT_CAPACITY];
threshold = (int)(hashTable.length * loadFactor);
hashTable[hash & (DEFAULT_CAPACITY - 1)] = new Node<K, V>(hash, key, value);
}else {
int n = hashTable.length;
int idx = hash & (n - 1);
while (null != hashTable[idx] && !key.equals(hashTable[idx].key))
idx = (idx + 1) & (n - 1);
hashTable[idx] = new Node<K, V>(hash, key, value);
}
if (++size > threshold) {
resize();
}
}
private void resize() {
int n = (hashTable.length << 1);
threshold = (int) (n * loadFactor);
Node<K, V>[] oldTable = hashTable;
hashTable = (Node<K, V>[]) new Node[n];
for (int i = 0; i < oldTable.length; i++) {
if (null == oldTable[i])
continue;
Node<K, V> node = oldTable[i];
int idx = node.hash & (n - 1);
while (null != hashTable[idx] && !node.key.equals(hashTable[idx].key))
idx = (idx + 1) & (n - 1);
hashTable[idx] = node;
}
}
public V get(K key) {
if (null == key)
throw new RuntimeException("查询的键值不能为空");
int hash = hash(key);
int n = hashTable.length;
int idx = hash & (n - 1);
if (null == hashTable[idx])
return null;
for (;;) {
if (null != hashTable[idx]
&& hash == hashTable[idx].hash
&& key.equals(hashTable[idx].key))
break;
idx = (idx + 1) & (n -1);
}
return hashTable[idx].value;
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("[");
for (int i = 0; i < hashTable.length; i++) {
builder.append(hashTable[i]);
builder.append(", ");
}
builder.delete(builder.length() - 2, builder.length());
builder.append("]");
return builder.toString();
}
}
HashMap测试代码:
public static void main(String[] args) {
MyHashMap<String, Integer> map = new MyHashMap<>();
Random random = new Random();
HashMap<String, Integer> map1 = new HashMap<>();
ArrayList<String> strs = new ArrayList<>();
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000000; i++) {
String s = UUID.randomUUID().toString().substring(0, 4);
int n = random.nextInt(1000);
strs.add(s);
list.add(n);
}
System.out.println("开始测试插入 put 函数");
long start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
map1.put(strs.get(i), list.get(i));
}
long end = System.currentTimeMillis();
System.out.println("HashMap:花费的时间 = " + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
map.put(strs.get(i), list.get(i));
}
end = System.currentTimeMillis();
System.out.println("MyHashMap:花费的时间 = " + (end - start));
System.out.println("开始测试查找 get 函数");
start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
map.get(strs.get(i));
}
end = System.currentTimeMillis();
System.out.println("MyHashMap:花费的时间 = " + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
map1.get(strs.get(i));
}
end = System.currentTimeMillis();
System.out.println("HashMap:花费的时间 = " + (end - start));
}
输出结果:
开始测试插入 put 函数
HashMap:花费的时间 = 232
MyHashMap:花费的时间 = 324
开始测试查找 get 函数
MyHashMap:花费的时间 = 186
HashMap:花费的时间 = 222
从上面的结果可以看出来我们自己实现的HashMap在插入数据的时候花费的时间比较长,JDK的HashMap使用的是链地址法,他们扩容的次数肯定会比我们少,因为我们一个位置只能放一个数据,而JDK的能放多个。
但是我们查找的时候效率会高一点,因为JDK的哈希表还涉及链表的操作(可能还涉及红黑树),因此我们的效率可能会高一点。
在本篇文章当中我们自己实现了一个线性探测的哈希表,但是我们并没有实现remove函数,大家可以自己去实现这个函数,也不太困难!!!整篇文章的内容主要包含以下内容:
Node的设计。roundUp函数设计。本篇内容还是比较多的,希望大家有所收获,我是LeHung,我们下期再见!!!
更多精彩内容合集可访问:https://github.com/Chang-LeHung/CSCore
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg