首先,Hadoop会把输入数据划分成等长的输入分片(input split) 或分片发送到MapReduce。Hadoop为每个分片创建一个map任务,由它来运行用户自定义的map函数以分析每个分片中的记录。在我们的单词计数例子中,输入是多个文件,一般一个文件对应一个分片,如果文件太大则会划分为多个分片。map函数的输入以<key, value>形式做为输入,value为文件的每一行,key为该行在文件中的偏移量(一般我们会忽视)。这里map函数起到的作用为将每一行进行分词为多个word,并在context中写入<word, 1>以代表该单词出现一次。
map过程的示意图如下:
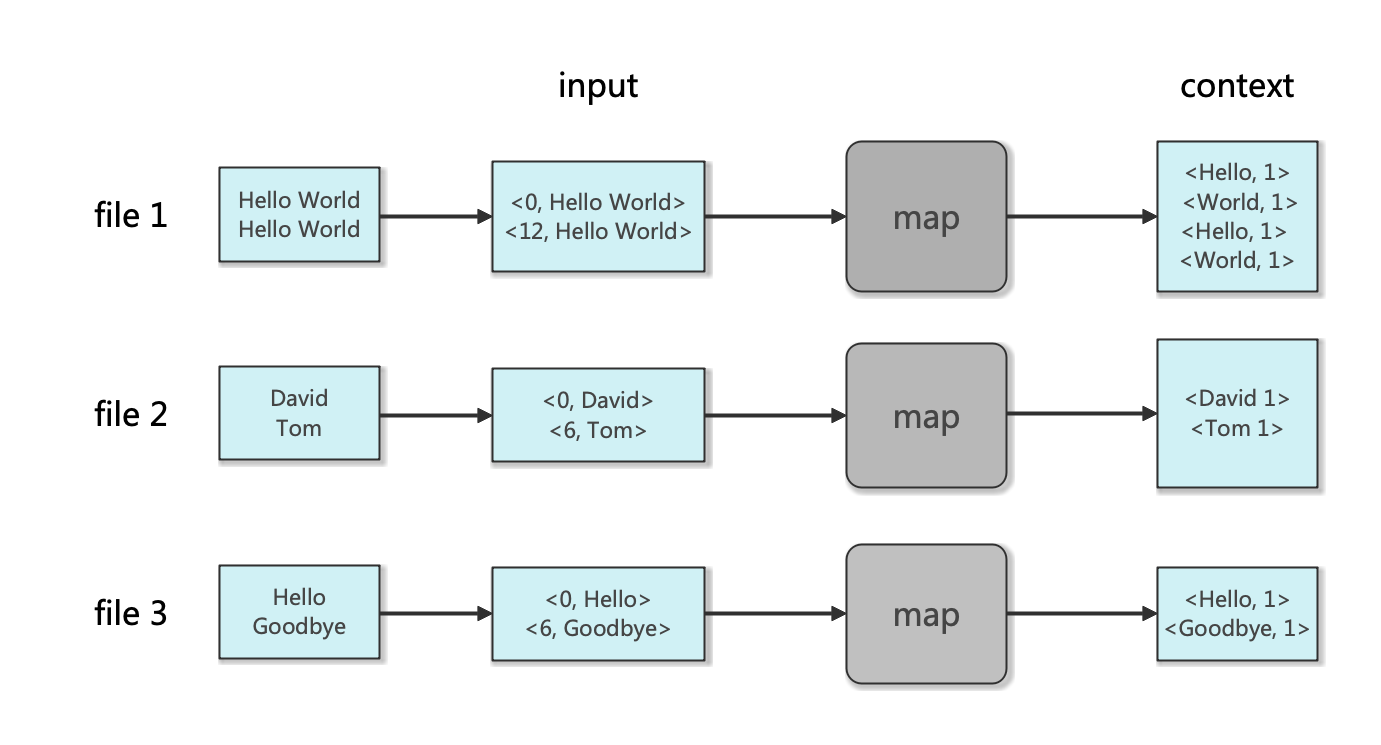
mapper代码编写如下:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//每次处理一行,一个mapper里的value为一行,key为该行在文件中的偏移量
StringTokenizer iter = new StringTokenizer(value.toString());
while (iter.hasMoreTokens()) {
word.set(iter.nextToken());
// 向context中写入<word, 1>
context.write(word, one);
System.out.println(word);
}
}
}
如果我们能够并行处理分片(不一定是完全并行),且分片是小块的数据,那么处理过程将会有一个好的负载平衡。但是如果分片太小,那么管理分片与map任务创建将会耗费太多时间。对于大多数作业,理想分片大小为一个HDFS块的大小,默认是64MB。
map任务的执行节点和输入数据的存储节点相同时,Hadoop的性能能达到最佳,这就是计算机系统中所谓的data locality optimization(数据局部性优化)。而最佳分片大小与块大小相同的原因就在于,它能够保证一个分片存储在单个节点上,再大就不能了。
接下来我们看reducer的编写。reduce任务的多少并不是由输入大小来决定,而是需要人工单独指定的(默认为1个)。和上面map不同的是,reduce任务不再具有本地读取的优势————一个reduce任务的输入往往来自于所有mapper的输出,因此map和reduce之间的数据流被称为 shuffle(洗牌) 。Hadoop会先按照key-value对进行排序,然后将排序好的map的输出通过网络传输到reduce任务运行的节点,并在那里进行合并,然后传递到用户定义的reduce函数中。
reduce 函数示意图如下:
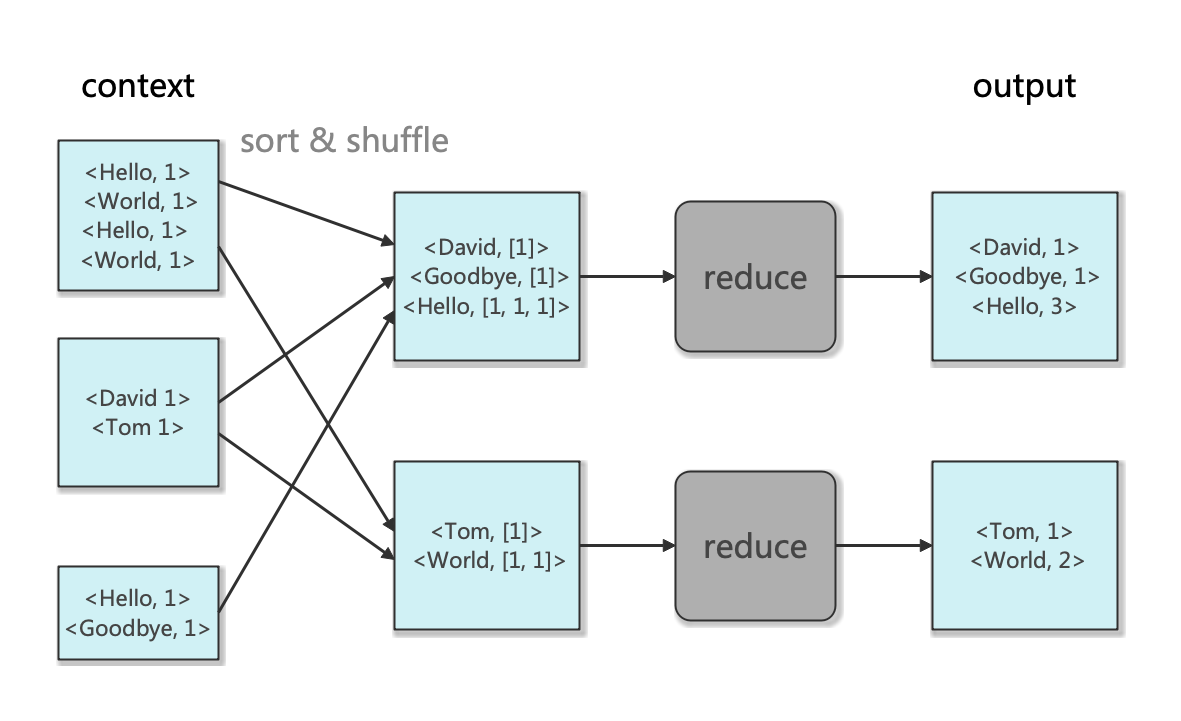
reducer代码编写如下:
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
关于VSCode+Java+Maven+Hadoop开发环境搭建,可以参见我的博客《VSCode+Maven+Hadoop开发环境搭建》,此处不再赘述。这里展示我们的项目架构图:
Word-Count-Hadoop
├─ input
│ ├─ file1
│ ├─ file2
│ └─ file3
├─ output
├─ pom.xml
├─ src
│ └─ main
│ └─ java
│ └─ WordCount.java
└─ target
WordCount.java代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount{
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//每次处理一行,一个mapper里的value为一行,key为该行在文件中的偏移量
StringTokenizer iter = new StringTokenizer(value.toString());
while (iter.hasMoreTokens()) {
word.set(iter.nextToken());
// 向context中写入<word, 1>
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word_count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
//此处的Combine操作意为即第每个mapper工作完了先局部reduce一下,最后再全局reduce
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第0个参数是输入目录,第1个参数是输出目录
//先判断output path是否存在,如果存在则删除
Path path = new Path(args[1]);//
FileSystem fileSystem = path.getFileSystem(conf);
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);
}
//设置输入目录和输出目录
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
pom.xml中记得配置Hadoop的依赖环境:
...
<!-- 集中定义版本号 -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<hadoop.version>3.3.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- 导入hadoop依赖环境 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
...
</project>
此外,因为我们的程序自带输入参数,我们还需要在VSCode的launch.json中配置输入参数intput(代表输入目录)和output(代表输出目录):
...
"args": [
"input",
"output"
],
...
编译运行完毕后,可以查看output文件夹下的part-r-00000文件:
David 1
Goodbye 1
Hello 3
Tom 1
World 2
可见我们的程序正确地完成了单词计数的功能。
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
尝试在我的RoR应用程序中实现计数器缓存列时出现错误Unknownkey(s):counter_cache。我在这个问题中实现了模型关联:Modelassociationquestion这是我的迁移:classAddVideoVotesCountToVideos0Video.reset_column_informationVideo.find(:all).eachdo|p|p.update_attributes:videos_votes_count,p.video_votes.lengthendenddefself.downremove_column:videos,:video_vot
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模