众所周知,ChatGPT可以帮助研发人员编写或者Debug程序代码,但是在执行过程中,ChatGPT会将程序代码的一些相关文字解释和代码段混合着返回,如此,研发人员还需要自己进行编辑和粘贴操作,效率上差强人意,本次我们试图将ChatGPT直接嵌入到代码业务中,让ChatGPT生成可以直接运行的代码。
首先,我们向ChatGPT提出一个简单的代码需求:
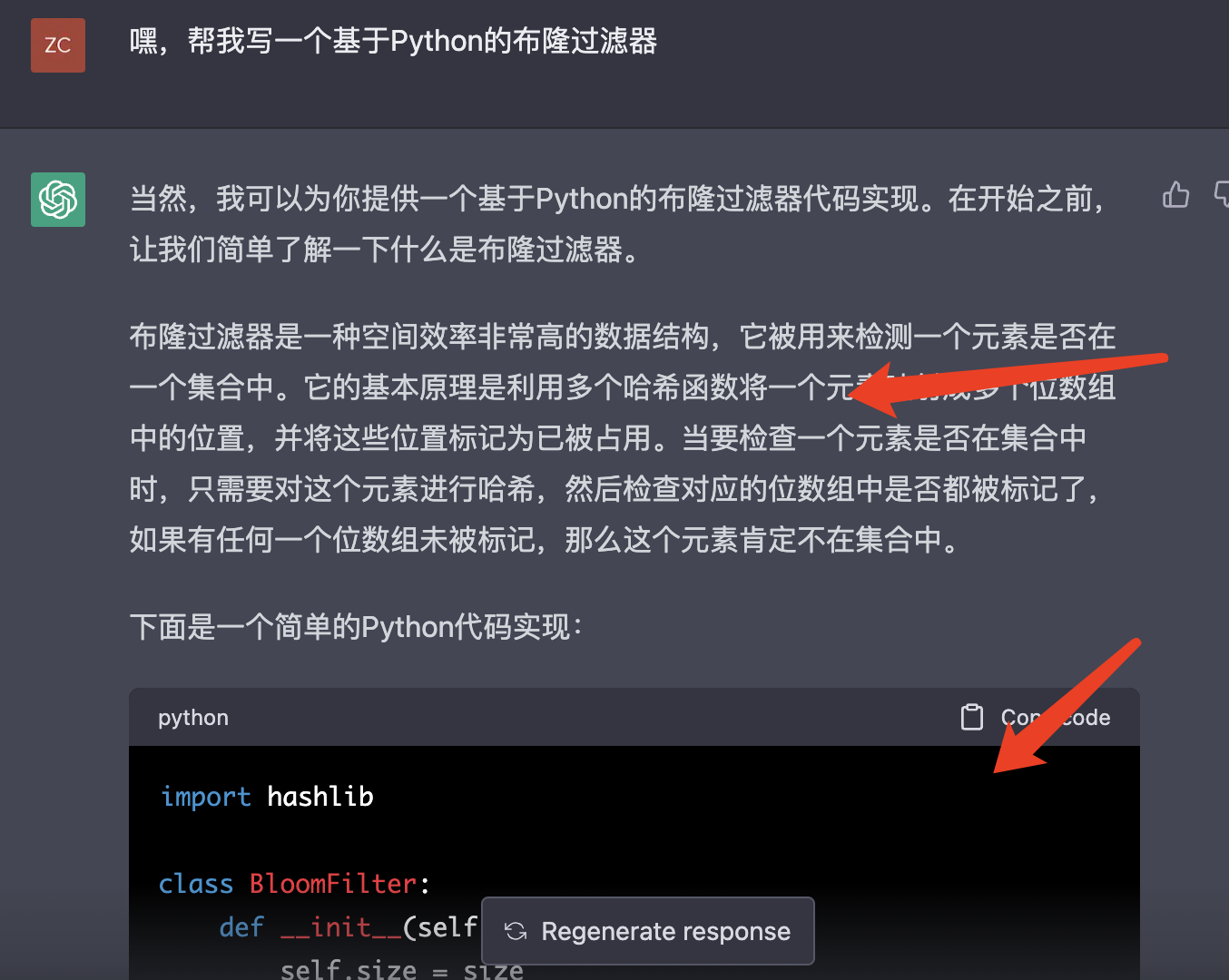
可以看到,就像上文所描述的那样,ChatGPT会将文字描述和代码片段混合着返回,其实对于真正的需求者来说,文字描述本身是不必要的,因为如果提问者不知道什么是布隆过滤器,也就不会提出布隆过滤器相关的代码需求。
再看ChatGPT返回的布隆过滤器代码:
import hashlib
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = [False] * size
def add(self, string):
for seed in range(self.hash_count):
result = hashlib.sha256((string + str(seed)).encode()).hexdigest()
index = int(result, 16) % self.size
self.bit_array[index] = True
def __contains__(self, string):
for seed in range(self.hash_count):
result = hashlib.sha256((string + str(seed)).encode()).hexdigest()
index = int(result, 16) % self.size
if not self.bit_array[index]:
return False
return True
大体上,没有毛病。但是主观性太强,什么是主观性?就是ChatGPT其实不是站在需求者的视角来编写代码,而是站在自己的角度上,它没有考虑业务的上下文关系,也就是类和方法命名、方法参数、以及参数类型或者返回值以及类型,这些东西是否符合需求者当前的代码业务。
当然,这并不是ChatGPT的错,主要是输入的问题描述不够明确和详细,但如果每次都需要将代码业务逻辑转化为文字告诉ChatGPT,又有些画蛇添足,狗尾续貂之感。
那么怎样将ChatGPT融入业务代码?首先创建Openai接入函数:
import openai
openai.api_key = "apikey"
def generate_code(func, docstring):
init_prompt = "You are a Python expert who can implement the given function."
definition = f"def {func}"
prompt = f"Read this incomplete Python code:\n```python\n{definition}\n```"
prompt += "\n"
prompt += f"Complete the Python code that follows this instruction: '{docstring}'. Your response must start with code block '```python'."
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
temperature=0,
max_tokens=1024,
top_p=1,
messages=[
{
"role": "system",
"content": init_prompt,
},
{
"role": "user",
"content": prompt,
},
],
)
codeblock = response.choices[0].message.content
code = next(filter(None, codeblock.split("```python"))).rsplit("```", 1)[0]
code = code.strip()
return code
诀窍就是提前设置好引导词:
init_prompt = "You are a Python expert who can implement the given function."
definition = f"def {func}"
prompt = f"Read this incomplete Python code:\n```python\n{definition}\n```"
prompt += "\n"
prompt += f"Complete the Python code that follows this instruction: '{docstring}'. Your response must start with code block '```python'."
这里我们提前设置两个参数func和docstring,也就是函数名和功能描述,要求ChatGPT严格按照参数的输入来返回代码,现在运行函数:
if __name__ == '__main__':
print(generate_code("test","Sum two numbers"))
程序返回:
➜ chatgpt_write_code /opt/homebrew/bin/python3.10 "/Users/liuyue/wodfan/work/chatgpt_write_code/chatgpt_write_code.p
y"
def test(a, b):
return a + b
如此一来,ChatGPT就不会返回废话,而是直接交给我们可以运行的代码。
事实上,函数调用环节也可以省略,我们可以使用Python装饰器的闭包原理,直接将所定义函数的参数和描述传递给ChatGPT,随后再直接运行被装饰的函数,提高效率:
import inspect
from functools import wraps
def chatgpt_code(func):
@wraps(func)
def wrapper(*args, **kwargs):
signature = f'{func.__name__}({", ".join(inspect.signature(func).parameters)}):'
docstring = func.__doc__.strip()
code = generate_code(signature, docstring)
print(f"generated code:\n```python\n{code}\n```")
exec(code)
return locals()[func.__name__](*args, **kwargs)
return wrapper
将方法定义好之后,使用基于ChatGPT的装饰器:
if __name__ == '__main__':
@chatgpt_code
def sum_two(num1,num2):
"""
Sum two numbers.
"""
print(sum_two(1,2))
程序返回:
➜ chatgpt_write_code /opt/homebrew/bin/python3.10 "/Users/liuyue/wodfan/work/chatgpt_write_code/chatgpt_write_code.p
y"
sum_two(num1, num2):
generated code:
def sum_two(num1, num2):
"""
Sum two numbers.
"""
return num1 + num2
3
直接将业务逻辑和运行结果全部返回。
那么现在,回到开篇的关于布隆过滤器的问题:
if __name__ == '__main__':
@chatgpt_code
def bloom(target:str,storage:list):
"""
Use a Bloom filter to check if the target is in storage , Just use this func , no more class
"""
print(bloom("你好",["你好","Helloworld"]))
程序返回:
➜ chatgpt_write_code /opt/homebrew/bin/python3.10 "/Users/liuyue/wodfan/work/chatgpt_write_code/chatgpt_write_code.p
y"
generated code:
def bloom(target, storage):
# Initialize the Bloom filter with all zeros
bloom_filter = [0] * len(storage)
# Hash the target and set the corresponding bit in the Bloom filter to 1
for i in range(len(storage)):
if target in storage[i]:
bloom_filter[i] = 1
# Check if all the bits corresponding to the target are set to 1 in the Bloom filter
for i in range(len(storage)):
if target in storage[i] and bloom_filter[i] == 0:
return False
return True
True
➜ chatgpt_write_code
丝滑流畅,和业务衔接得天衣无缝,拉链般重合,不需要挑挑拣拣,也不必复制粘贴。
毫无疑问,ChatGPT确然是神兵利器,吹毛可断,无坚不摧。但工具虽好,也需要看在谁的手里,所谓工具无高下,功力有高深,类比的话,如果倚天剑握在三岁孩童手中,不仅毫无增益,还可能伤其自身,但是握在峨眉掌门灭绝师太手里,那就可以横扫千军如卷席了,那才能体现大宗匠的手段。最后,奉上项目代码,与众乡亲同飨:github.com/zcxey2911/chatgptapi_write_code
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在