随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。
解读下上面的话:
1.随机森林属于集成算法,属于集成算法中的bagging,另一种就是boosting了,集成意味着着该算法是多个算法组合而成
2.随机森林是由决策树集成的,这个很好理解,单木为树,多木成林。所以它叫森林,所以你想弄明白什么是随机森林,就必须先整明白什么是决策树。
其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
随机森林的出现是为了解决决策树泛化能力比较弱的特点,因为决策树就有一棵树,它的决策流只有一条, 泛化能力弱。而随机森林就比较好解决了这个问题。
森林我们知道是什么了,那么随机是什么? 随机主要是2个方面,一个是随机选取特征,一个是随机样本。比如我们有N条数据,每条数据M个特征,随机森林会随机X条选取样本数据和Y个特征,然后组成多个决策树。
bagging即通过随机采样的方式生成众多并行式的分类器,通过少数服从多数的原则来确定最终结果。借鉴了一张图来说明下(来自刘建平Pinard):
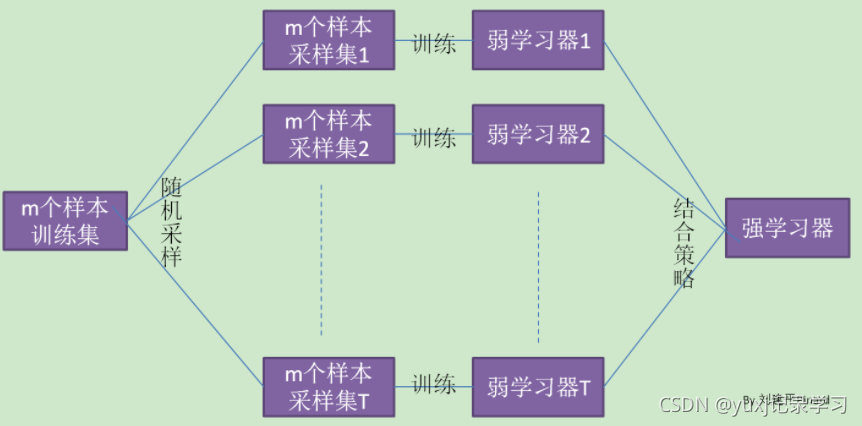
这里我们要注意的一点是bagging采样后,是将采过的样本放回总样本集的,而boosting是不放的。
1) 训练可以高度并行化,对于大数据时代的大样本训练速度有优势。个人觉得这是的最主要的优点。
2) 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
3) 在训练后,可以给出各个特征对于输出的重要性
4) 由于采用了随机采样,训练出的模型的方差小,泛化能力强。
5) 相对于Boosting系列的Adaboost和GBDT, RF实现比较简单。
6) 对部分特征缺失不敏感。
RF的主要缺点有:
1)在某些噪音比较大的样本集上,RF模型容易陷入过拟合。
2) 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
相同点:
都是由多棵树组成,最终的结果都是由多棵树一起决定。
不同点:
先说下RandomForestClassifier这个模型算法是干啥用的,他最大的作用是分类预测
首先是官网
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier其次是方法
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)最后开始解释,还是挑重要的说
n_estimators :树的数量,默认是10,这个很好理解就是你准备在你的森林里种多少树。这个参数的大小决定了最后的准确性,但是也会让你的运行速度变的很慢,所以需要不断的测试去决定。
max_features:随机森林允许单个决策树使用特征的最大数量。
Auto/None/sqrt :简单地选取所有特征,每颗树都可以利用他们。这种情况下,每颗树都没有任何的限制。默认是auto
int:是整数
float:百分比选取
log2:所有特征数的log2值
最主要的两个参数是n_estimators和max_features,n_estimators理论上是越大越好,但是计算时间也相应增长。所以,并不是取得越大就会越好,预测效果最好的将会出现在合理的树个数;max_features每个决策树在随机选择的这max_features特征里找到某个“最佳”特征,使得模型在该特征的某个值上分裂之后得到的收益最大化。max_features越少,方差就会减少,但同时偏差就会增加。如果是回归问题,则max_features=n_features,如果是分类问题,则max_features=sqrt(n_features),其中,n_features 是输入特征数
criterion : criterion:分裂节点所用的标准,可选“gini”, “entropy”,默认“gini”。
max_depth:树的最大深度。如果为None,则将节点展开,直到所有叶子都是纯净的(只有一个类),或者直到所有叶子都包含少于min_samples_split个样本。默认是None
min_samples_split:拆分内部节点所需的最少样本数:如果为int,则将min_samples_split视为最小值。如果为float,则min_samples_split是一个分数,而ceil(min_samples_split * n_samples)是每个拆分的最小样本数。默认是2
min_samples_leaf:在叶节点处需要的最小样本数。仅在任何深度的分割点在左分支和右分支中的每个分支上至少留下min_samples_leaf个训练样本时,才考虑。这可能具有平滑模型的效果,尤其是在回归中。如果为int,则将min_samples_leaf视为最小值。如果为float,则min_samples_leaf是分数,而ceil(min_samples_leaf * n_samples)是每个节点的最小样本数。默认是1。
当确定了使用的模型,如果调整参数达到最优效果请看这里
调用的话就很简单了
rfMod = RandomForestClassifier(n_estimators=100, criterion='gini', max_depth=None, min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto',
max_leaf_nodes=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0)
rfMod.fit(X_train,Y_train)调用完后的属性
estimators_ : 使用 - rfMod.estimators_ , 拟合的子估计器的集合
classes_ :使用 - rfMod.classes_ ,类别标签(单一输出问题),或者类别标签的数组序列(多输出问题)。
n_classes_ :使用 - rfMod.n_classes_ ,类别的数量(单输出问题),或者一个序列,包含每一个输出的类别数量(多输出问题)。
n_features_ :使用 - rfMod.n_features_ ,执行拟合时的特征数量。
n_outputs_ :使用 - rfMod.n_outputs_ ,执行拟合时的输出数量。
feature_importances_ :使用 - rfMod.feature_importances_ ,特征的重要性(值越高,特征越重要)。这个非常有用,可以看出特征的重要性。
oob_score_ :使用 - rfMod.oob_score_ ,使用袋外估计获得的训练数据集的得分。
oob_decision_function_ :使用 - rfMod.oob_decision_function_ ,在训练集上用袋外估计计算的决策函数。如果n_estimators很小的话,那么在有放回抽样中,一个数据点也不会被忽略是可能的。在这种情况下,oob_decision_function_ 可能包括NaN。
get_params :获取此估算器的参数,返回的是映射值的参数名
predict ( X ):预测
predict_log_proba ( X )
:输入样本的预测类别对数概率被计算为森林中树木的平均预测类别概率的对数。
predict_proba ( X )
:输入样本的预测类别概率被计算为森林中树木的平均预测类别概率。 单个树的类概率是叶中同一类的样本的分数。
score :返回均准确度
官网
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html#sklearn-ensemble-randomforestregressor方法调用
class sklearn.ensemble.RandomForestRegressor(n_estimators=100, *, criterion='mse', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None)RandomForestRegressor是个回归方法,主要是做连续变量的预测,在数据处理补充连续变量缺失值的时候,用的比较多。
因为RandomForestRegressor和RandomForestClassifier的参数、属性和方法差不多都一样,主要介绍不一样的。
criterion
目标函数一共2个,一个是均方误差mean squared error(MSE),另一个是绝对平均误差MAE(mean absolute error)
1)输入"mse"使用均方误差mean squared error(MSE),父节点和叶子节点之间的均方误差的差额将被用来作为特征选择的标准,这种方法通过使用叶子节点的均值来最小化L2损失,基本上都用这个
2)输入"mae"使用绝对平均误差MAE(mean absolute error),这种指标使用叶节点的中值来最小化L1损失。0.18版本之后加入的
值得一提的是,虽然均方误差永远为正,但是sklearn当中使用均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss),因此在sklearn当中,都以负数表示。真正的均方误差MSE的数值,其实就是neg_mean_squared_error去掉负号的数字。
参考:sklearn随机森林分类类RandomForestClassifier_w952470866的专栏-CSDN博客_randomforestclassifier
https://sklearn.apachecn.org/docs/master/12.html?h=RandomForestClassifier
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我想在ruby中生成一个64位整数。我知道在Java中你有很多渴望,但我不确定你会如何在Ruby中做到这一点。另外,64位数字中有多少个字符?这是我正在谈论的示例......123456789999。@num=Random.rand(9000)+Random.rand(9000)+Random.rand(9000)但我认为这是非常低效的,必须有一种更简单、更简洁的方法来做到这一点。谢谢! 最佳答案 rand可以将范围作为参数:pa=rand(2**32..2**64-1)#=>11093913376345012184putsa.
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:HowdoIgeneratealistofnuniquerandomnumbersinRuby?我想做的事:Random.rand(0..10).timesdoputsRandom.rand(0..10)end但如果随机数已经显示过,则无法再次显示。如何最轻松地做到这一点?