java.util.regex 包主要包括以下三个类:Pattern类、Matcher类和PatternSyntaxException类
Pattern类
Pattern对象是一个正则表达式对象。Pattern类没有公共构造方法,要创建一个Pattern对象,调用其公共静态方法,它返回一个Pattern对象。该方法接收一个正则表达式作为它的第一个参数,比如:Pattern r = Pattern.compile(pattern);
Matcher类
Matcher对象是对输入字符串进行解释和匹配的引擎。与Pattern类一样,Matcher类也没有公共构造方法。需要调用Pattern对象的matcher方法来获得一个Matcher对象
PatternSyntaxException类
PatternSyntaxException是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
JAVA正则表达式, matcher.find()和 matcher.matches()的区别
package li.regexp;
import java.util.regex.Pattern;
//演示matcher方法,用于整体匹配(注意是整个文本的匹配),在验证输入的字符串是否满足条件使用
public class PatternMethod {
public static void main(String[] args) {
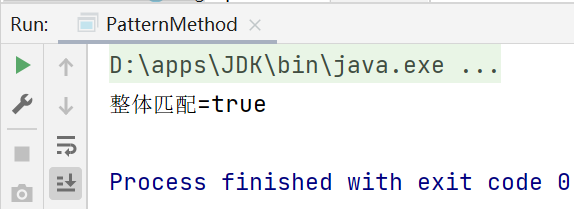
String content="hello abc hello,侬好";
//String regStr="hello";//false
String regStr="hello.*";//true
boolean matches = Pattern.matches(regStr, content);
System.out.println("整体匹配="+matches);
}
}
matches方法的底层源码:
public static boolean matches(String regex, CharSequence input) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);
return m.matches();
}
可以看到,底层还是创建了一个正则表达式对象,以及使用matcher方法,最后调用matcher类的matches方法(该方法才是真正用来匹配的)


package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//Matcher类的常用方法
public class MatcherMethod {
public static void main(String[] args) {
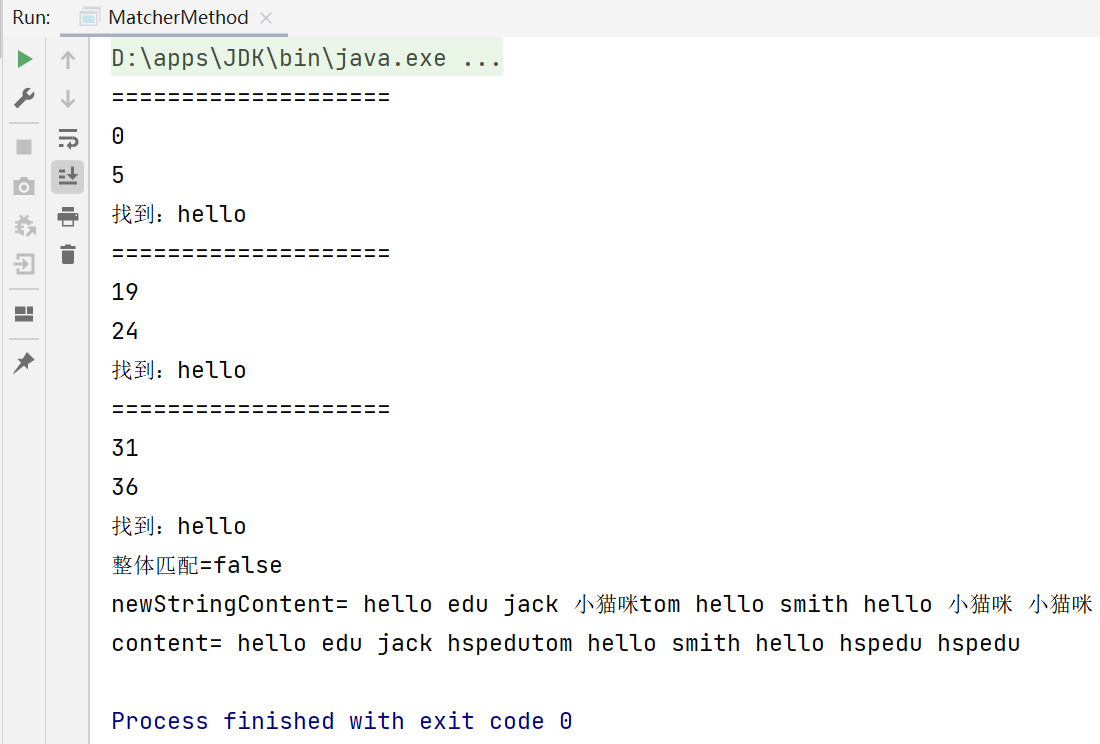
String content = "hello edu jack tom hello smith hello";
String reStr = "hello";
Pattern pattern = Pattern.compile(reStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("====================");
System.out.println(matcher.start());
System.out.println(matcher.end());
System.out.println("找到:" + content.substring(matcher.start(), matcher.end()));
}
//整体匹配方法,常用于校验某个字符串是否满足某个规则
//Pattern的matches方法底层调用的就是Matcher类的matches方法
System.out.println("整体匹配=" + matcher.matches());//false
content = "hello edu jack hspedutom hello smith hello hspedu hspedu";
//如果content有字符串 hspedu,就将其替换为 小猫咪
reStr = "hspedu";
pattern = Pattern.compile(reStr);
matcher = pattern.matcher(content);
//注意:返回的字符串newStringContent才是替换后的字符,原来的字符串content是不变化的
String newStringContent = matcher.replaceAll("小猫咪");
System.out.println("newStringContent= " + newStringContent);
System.out.println("content= " + content);
}
}
请看下面的问题:
给定一段文本,请找出所有四个数字连在一起的子串,并且这四个数字要满足:
在解决前面的问题之前,我们需要了解正则表达式的几个概念:
分组
我们可以用圆括号组成一个比较复杂的匹配模式,那么一个圆括号的部分我们可以看作是一个子表达式/分组
捕获
把正则表达式中的 子表达式/分组 匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。组0代表的是整个正则式
-详见5.4.6
反向引用
圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个我们称为反向引用,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用使用\\\分组号,外部反向引用使用$分组号
捕获组(Expression)在匹配成功时,会将子表达式匹配到的内容,保存到内存中一个以数字编号的组里,可以简单的认为是对一个局部变量进行了赋值,这时就可以通过反向引用方式,引用这个局部变量的值。一个捕获组(Expression)在匹配成功之前,它的内容可以是不确定的,一旦匹配成功,它的内容就确定了,反向引用的内容也就是确定的了。
反向引用必然要与捕获组一同使用的,如果没有捕获组,而使用了反向引用的语法,不同语言的处理方式不一致,有的语言会抛异常,有的语言会当作普通的转义处理。
例子:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//反向引用
public class RegExp12 {
public static void main(String[] args) {
String content = "ke7887k5225e he12341551l12321-333999111lo ja11ck yy22y xx33333x";
//1. 要匹配两个连续的相同数字 (\\d)\\1
//String regStr="(\\d)\\1";
//2. 要匹配五个连续的相同数字 (\\d)\\1{4}
//String regStr="(\\d)\\1{4}";
//3. 要匹配个位与千位相同,十位与百位相同的数 (\\d)(\\d)\\2\\1
//String regStr="(\\d)(\\d)\\2\\1";
//在字符串中检索商品编号,形式如:12321-333999111这样的号码,
// 要求满足前面是一个五位数,然后一个-号,然后是一个九位数,连续的每三位要相同
String regStr="\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到:"+matcher.group(0));
}
}
}
经典的结巴程序
把类似 “我.....我我要......学学学学.......编程java!”
这样一句话,通过正则表达式将其修改成“我要学编程java!”
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//去重
public class RegExp13 {
public static void main(String[] args) {
String content = "我.....我我要......学学学学.......编程java!";
//1.去掉所有的 .
Pattern pattern = Pattern.compile("\\.");
Matcher matcher = pattern.matcher(content);
content = matcher.replaceAll("");//用空串替换掉.
System.out.println("去掉所有的\".\"=" + content);
//2.去掉重复的字
//思路:
//2.1使用(.)\\1+去匹配连续重复的字
//2.2使用反向引用$1来替换匹配到的内容
//--注意:这里的正则表达式匹配的是多个重复的字,但是捕获的内容是重复的字中的一个,即圆括号
pattern = Pattern.compile("(.)\\1+");//分组的捕获内容记录到$1中
matcher = pattern.matcher(content);//因为正则表达式改变了,需要重置 matcher
while (matcher.find()) {
System.out.println("找到=" + matcher.group(0));
}
//使用反向引用$1来替换匹配到的内容
//注意:虽然上面的正则表达式是匹配到的连续重复的字,但是捕获的是圆括号里面的内容,所以捕获的组里面的字只有一个,
//因此使用replaceAll("$1")的意思是:用捕获到的单个字去替换匹配到的多个重复的字
content = matcher.replaceAll("$1");
System.out.println("去掉重复的字=" + content);
//2.相当于:
// content = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");
// System.out.println(content);
}
}

使用正则表达式替换字符串可以直接调用 public String replaceAll(String regex,String replacement) ,它的第一个参数是正则表达式,第二个参数是要替换的字符串。
给出一段文本:
/*
2000年5月,JDK1.3、JDK1.4和J2SE1.3相继发布,几周后其获得了Apple公司Mac OS X的工业标准的支持。2001年9月24日,J2EE1.3发布。2002年2月26日,J2SE1.4发布。自此Java的计算能力有了大幅提升。
*/
将这段文字中的 JDK1.3 JDK1.4 统一替换成 JDK
package li.regexp;
//替换
public class RegExp14 {
public static void main(String[] args) {
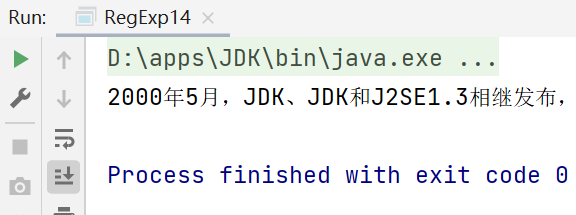
String content = "2000年5月,JDK1.3、JDK1.4和J2SE1.3相继发布,几周后其获得了" +
"Apple公司Mac OS X的工业标准的支持。2001年9月24日,J2EE1.3发布。2002" +
"年2月26日,J2SE1.4发布。自此Java的计算能力有了大幅提升。";
//使用正则表达式,将JDK1.3/JDK1.4 统一替换成 JDK
content = content.replaceAll("JDK1.[34]", "JDK");
System.out.println(content);
}
}
String类 public boolean matches(String regex)
验证一个手机号码,要求必须是以138、139开头的
package li.regexp;
//匹配
public class RegExp14 {
public static void main(String[] args) {
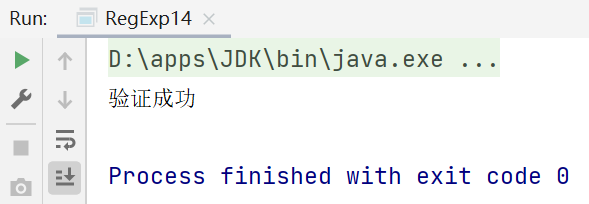
//验证一个手机号码,要求必须是以138、139开头的十一位数字
String content="13899988880";
if (content.matches("13[89]\\d{8}")) {//matches是整体匹配,不用加定位符
System.out.println("验证成功");
}else {
System.out.println("验证失败");
}
}
}
String类 public String[] split(String regex)
例子
有如下字符串,要求按照#或者-或者~或者数字来分割
“hello#abc-jack12smith~北京”
package li.regexp;
//分割
public class RegExp14 {
public static void main(String[] args) {
//要求按照# 或者- 或者~ 或者数字 来分割
String content = "hello#abc-jack12smith~北京";
String[] split = content.split("#|-|~|\\d+");
for (int i = 0; i < split.length; i++) {
System.out.println(split[i]);
}
}
}

规定电子邮件格式为:
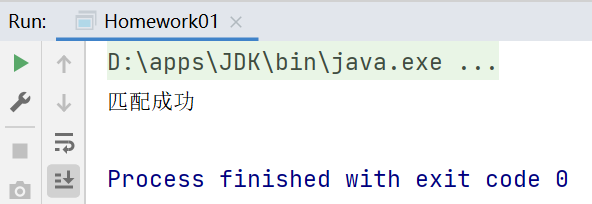
a-z A-Z 0-9_-字符package li.regexp;
public class Homework01 {
public static void main(String[] args) {
String content = "olien@tsinghua.org.cn";
//因此,String 的 marches方法是整体匹配,不用加定位符,但是建议加上
if (content.matches("^[\\w-]+@([a-zA-z]+\\.)+[a-zA-z]+$")) {
System.out.println("匹配成功");
} else {
System.out.println("匹配失败");
}
}
}
源码分析:
public boolean matches(String regex) {
return Pattern.matches(regex, this);
}
public static boolean matches(String regex, CharSequence input) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);
return m.matches();
}
/**
* Attempts to match the entire region against the pattern.-尝试将整个区域与模式匹配
*/
public boolean matches() {
return match(from, ENDANCHOR);
}
因此,String 的 marches方法是整体匹配,不用加定位符,但是建议加上
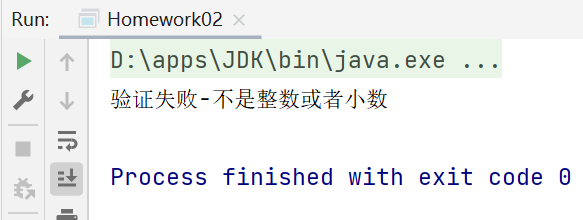
要求验证是不是整数或者小数
提示:这个题要考虑整数和负数
比如:123,-345,34.89,-87.0,-0.01,0.45等
package li.regexp;
public class Homework02 {
public static void main(String[] args) {
//要求验证是不是整数或者小数
//提示:这个题要考虑整数和负数
//比如:123,-345,34.89,-87.0,-0.01,0.45等
/**
* 思路:
* 1.先写出简单的正则表达式
* 2.再根据各种情况逐步地完善
* 2.1 [-+]? 考虑的是符号
* 2.2 小数点以及小数点后面的数字可以用 (\\.\\d+)?
* 2.3 小数点前面的应该存在数字,且分为两种情况:
* 2.3.1情况一:第一个应该以1-9开头,剩下的可能有0到多个数字, ([1-9]\\d*)
* 2.3.2情况二:小数点前面只有一位数字 0
* 两种情况整合起来就是 ([1-9]\\d*|0)
*/
String content = "-09.9";
//"^[-+]?([1-9]\\d*|0)(\\.\\d+)?$"
if (content.matches("^[-+]?([1-9]\\d*|0)(\\.\\d+)?$")) {
System.out.println("验证成功-是整数或者小数");
} else {
System.out.println("验证失败-不是整数或者小数");
}
}
}
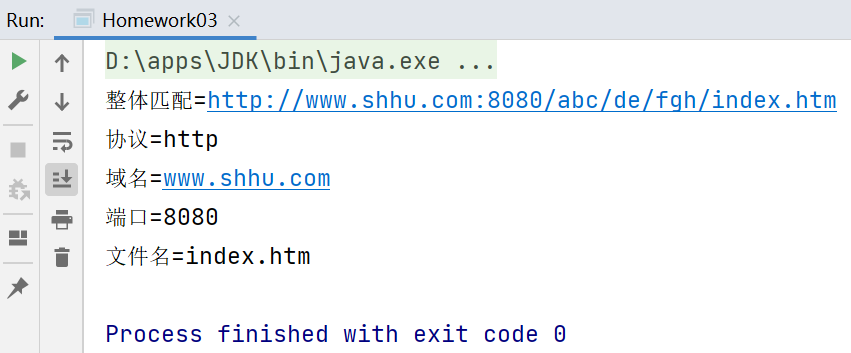
对一个url进行解析 http://www.shhu.com:8080/abc/index.htm
思路:分组,4组,分别获取到对应的值

package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Homework03 {
public static void main(String[] args) {
String content = "http://www.shhu.com:8080/abc/de/fgh/index.htm";
//如果名称中要求有特殊符号,就将特殊符号加入到中括号中
String regStr = "^([a-zA-Z]+)://([a-zA-Z.]+):(\\d+)[\\w-/]*/([\\w.]+)$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if (matcher.matches()) {//整体匹配,如果匹配成功,可以通过group(x),获取对应分组的内容
System.out.println("整体匹配=" + matcher.group(0));
System.out.println("协议=" + matcher.group(1));
System.out.println("域名=" + matcher.group(2));
System.out.println("端口=" + matcher.group(3));
System.out.println("文件名=" + matcher.group(4));
} else {
System.out.println("没有匹配成功");
}
}
}
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://
我需要一个非常简单的字符串验证器来显示第一个符号与所需格式不对应的位置。我想使用正则表达式,但在这种情况下,我必须找到与表达式相对应的字符串停止的位置,但我找不到可以做到这一点的方法。(这一定是一种相当简单的方法……也许没有?)例如,如果我有正则表达式:/^Q+E+R+$/带字符串:"QQQQEEE2ER"期望的结果应该是7 最佳答案 一个想法:你可以做的是标记你的模式并用可选的嵌套捕获组编写它:^(Q+(E+(R+($)?)?)?)?然后你只需要计算你获得的捕获组的数量就可以知道正则表达式引擎在模式中停止的位置,你可以确定匹配结束
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
这是一个例子:s="abcd+subtext@example.com"s.match(/+[^@]*/)Result=>"+subtext"问题是,我不想在其中包含“+”。我希望结果是“潜台词”,没有+ 最佳答案 您可以在正则表达式中使用括号来创建匹配组:s="abcd+subtext@example.com"s=~/\+([^@]*)/&&$1=>"subtext" 关于ruby-正则表达式-排除一个字符,我们在StackOverflow上找到一个类似的问题:
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
我正在尝试通过正则表达式拆分参数列表。这是一个带有我的参数列表的字符串:"a=b,c=3,d=[1,3,5,7],e,f=g"我想要的是:["a=b","c=3","d=[1,3,5,7]","e","f=g"]我试过先行,但Ruby不允许使用动态范围后行,所以这行不通:/(?如何让正则表达式忽略方括号中的所有内容? 最佳答案 也许这样的东西对你有用:str.scan(/(?:\[.*?\]|[^,])+/)编辑再三考虑。简单的非贪婪匹配器在某些嵌套括号的情况下会失败。 关于Ruby正则
我想找到给定字符串中的所有匹配项,包括重叠匹配项。我怎样才能实现它?#Example"a-b-c-d".???(/\w-\w/)#=>["a-b","b-c","c-d"]expected#Solutionwithoutoverlappedresults"a-b-c-d".scan(/\w-\w/)#=>["a-b","c-d"],but"b-c"ismissing 最佳答案 在积极的前瞻中使用捕获:"a-b-c-d".scan(/(?=(\w-\w))/).flatten#=>["a-b","b-c","c-d"]参见Rubyde
我想为名字验证编写一个正则表达式。正则表达式应包括所有字母(拉丁/法语/德语字符等)。但是我想从中排除数字并允许-。所以基本上它是\w(减)数(加)-。请帮忙。 最佳答案 ^[\p{L}-]+$\p{L}匹配anykindofletterfromanylanguage. 关于ruby-on-rails-rails中的正则表达式匹配[\w]和"-"但不匹配数字,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
这就是我做的a="%span.rockets#diamonds.ribbons.forever"a=a.match(/(^\%\w+)([\.|\#]\w+)+/)putsa.inspect这是我得到的#这就是我想要的#帮助?我尝试过但失败了:( 最佳答案 通常,您不能获得任意数量的捕获组,但如果您使用扫描,您可以为您想要捕获的每个标记获得一个匹配:a="%span.rockets#diamonds.ribbons.forever"a=a.scan(/^%\w+|\G[.|#]\w+/)putsa.inspect["%span","