2003-2004年,Google公布了部分GFS和MapReduce思想的细节,受此启发的Doug Cutting等人用2年的业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。然后Yahoo招安Doug Gutting及其项目。
2005年,Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会。
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
在Hadoop 1.0时代,Hadoop由两部分组成,一部分是做为分布式文件系统的HDFS,另一部分是作为分布式计算引擎的MapReduce。
Hadoop的研发团队在研发初期就意识到了NameNode的重要性,故将其部分功能拆离出来作为Secondary NameNode。Secondary NameNode作为NameNode的一个冷备节点,定期将NameNode的操作日志合并成集群的状态快照,这样在NameNode重启时可以加快启动速度。HDFS的整体架构图如下:

Hadoop 2.0对Hadoop 1.0中的每个组件都进行了升级扩展。就HDFS来说,它的整体架构并没有太大的改变,其新增的特性为HA(高可用)和Federation(联邦模式),这两个特性主要集中在NameNode中。
在Hadoop 2.0中,支持用两个NameNode提供HA功能,这两个NameNode分别为Active NameNode和Standby NameNode,前者负责对外提供服务,后则作为前者的热备节点,它们通过一个共享的存储结构QJM(Quorum Journal Manager)实现数据同步。
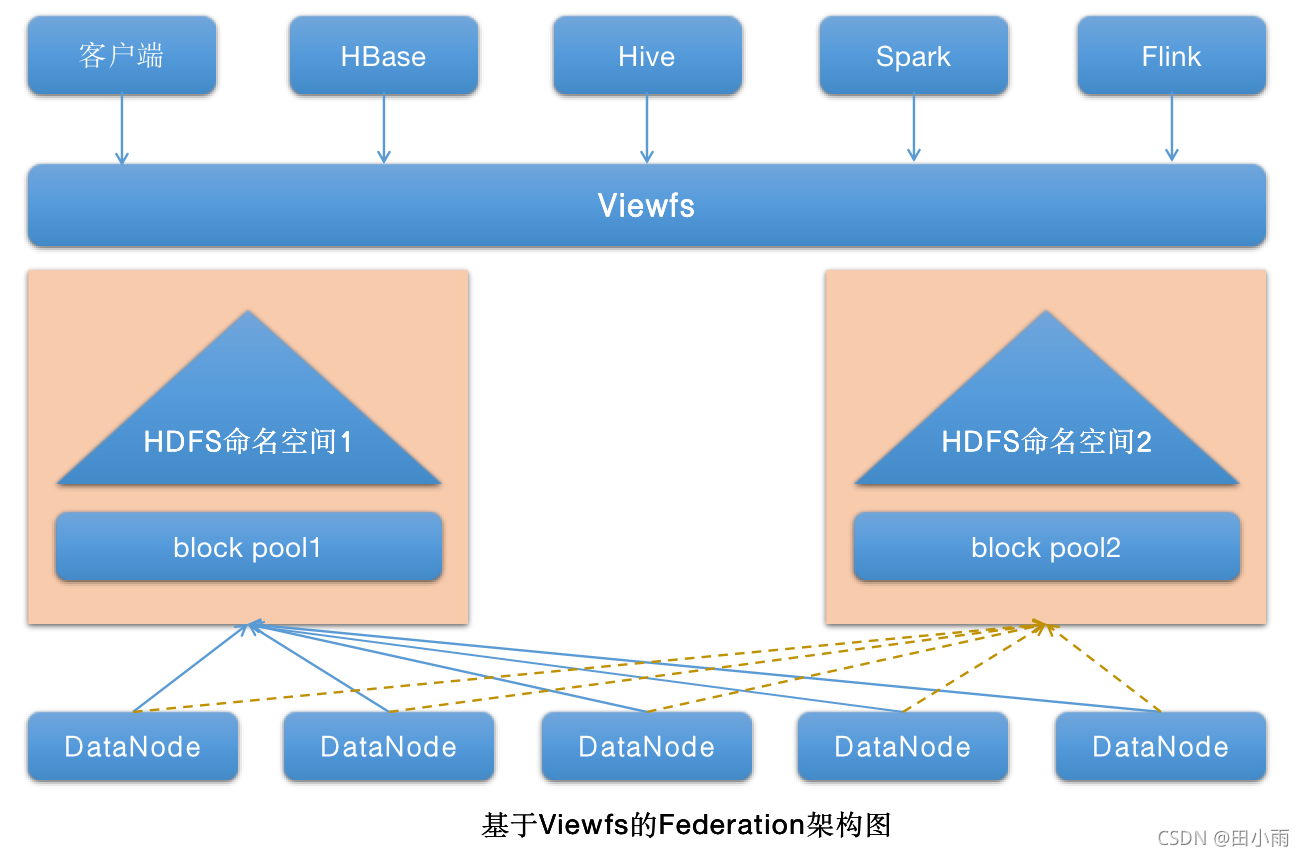
虽然NameNode的稳定性通过HA得到了增强,但是随着集群规模的扩大,NameNode的内存逐渐成为影响其扩容的主要因素,而Federation为其提供了横向扩展的能力。在Federation中,viewfs负责提供N个小集群的整体视图,对普通用户屏蔽内部架构细节,这样也方便集群管理员管理集群。基于Viewfs的Federation的整体架构如图所示:
Hadoop 2.0的另一个亮点是将Hadoop 1.0的MapReduce拆分为两个组件:一个组件专注于分布式计算,依然以MapReduce命名;另一个组件专注于资源管理,命名为YARN。
虽然Hadoop 2.0解决了很多问题,使其性能得以提升、集群规模得以扩大,但是在扩大的过程中,又出现了新的瓶颈,如:HDFS虽然在Federation下能够横向扩展,但是其使用方式并不利于维护,而且数据冗余存储的方式在大规模集群中暴露出了存储资源利用不足的问题。再则就是HDFS的横向扩展导致在集群达到一定规模时,ResourceManager对资源的调度成了新的瓶颈。为了解决这些问题,Hadoop3.0问世了。
Hadoop 3.0没有在架构上对Hadoop 2.0进行大的改动,而是将精力放在了如何提供系统的可扩展性和资源利用率上。因此,Hadoop 3.0提供了更高的性能、更强的容错能力以及更高的数据处理能力。
在提供可扩展性方面,Hadoop 3.0为YARN提供了Federation,使其集群规模可以达到上万台。此外,它还为NameNode提供了多个Standby NameNode,这使得NameNode又多了一份保障。
另外,Hadoop 3.0中还新增了两个成员,分别是Hadoop Ozone和Hadoop Submarine。Hadoop Ozone是专门为Hadoop设计的、由HDDS(Hadoop Distributed Data Store)构建成的可扩展的分布式对象存储系统;Hadoop Submarine 是一个机器学习引擎,可以运行TensorFlow、PyToch、MXNet等框架,可以运行在YARN、Kubenetes等资源管理平台之上。这两个模块都是新增的,它们正处在开发中,之后会使Hadoop更加强大。
在Hadoop 2.0中,基于viewfs的Federation是以客户端为核心的解决方案,对Hadoop客户端影响较大,在落地应用时有较多的限制,对上层应用模式有较强的依赖。于是社区在Hadoop 3.0中提出了新的用于解决统一命名空间问题的方案:基于Router的Federation。
基于Router的Federation并不像viewfs那样在各个子集群之上新增视图,而是在所有子集群之上新增一个拦截转发层,架构如下图:

拦截转发层新增的两个组件分别为Router和Srate Store。其中State Store存储远程挂载表(与viewfs相似,但是在客户端之间共享)和有关子集群的负载、空间使用信息。Router实现了与NameNode相同的接口,根据State Store的元数据信息将客户端请求转发给正确的集群。
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
有人知道在发布新版本的Ruby和Rails时收到电子邮件的方法吗?他们有邮件列表,RubyonRails有一个推特,但我不想听到那些随之而来的喧嚣,我只想知道什么时候发布新版本,尤其是那些有安全修复的版本。 最佳答案 从therailsblog获取提要.http://weblog.rubyonrails.org/feed/atom.xml 关于ruby-on-rails-如何在发布新的Ruby或Rails版本时收到通知?,我们在StackOverflow上找到一个类似的问题:
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
如果我一直输入geminstallrails使用不同版本的Rails会怎样?例如,我可以输入:geminstallrails--verson3.2.10或geminstallrails这给了我版本3.2.12。问题每次安装都会覆盖之前的吗?它会删除所有旧文件并添加我正在安装的新版本吗?或者如果我运行它两次,它会保留一些文件吗?我正在使用Ubuntu。 最佳答案 它将安装两个独立的gem。实际的可执行文件rails将调用最新版本。你可以覆盖它__例如,rails_3.2.10_将执行Rails3.2.10。bundler顺便说一下,如