文章目录
分支语句
循环语句
goto语句
C语句可分为以下五类:
1. 表达式语句
2. 函数调用语句
3. 控制语句
4. 复合语句
5. 空语句
本章后面介绍的是控制语句。
控制语句用于控制程序的执行流程,以实现程序的各种结构方式(C语言支持三种结构:顺序结构、选择结构、循环结构),它们由特定的语句定义符组成,C语言有九种控制语句。
可分成以下三类:
1. 条件判断语句也叫分支语句:if语句、switch语句;
2. 循环执行语句:do while语句、while语句、for语句;
3. 转向语句:break语句、goto语句、continue语句、return语句。
如果你好好学习,校招时拿一个好offer,走上人生巅峰。
如果你不学习,毕业等于失业,回家卖红薯。
这就是选择!

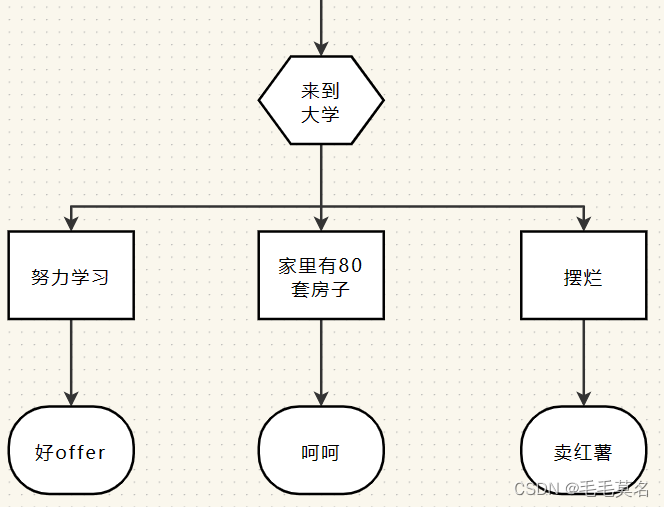
*那if语句的语法结构是怎么样的呢?
语法结构:
if(表达式)
语句;
if(表达式)
语句1;
else
语句2;
//多分支
if(表达式1)
语句1;
else if(表达式2)
语句2;
else
语句3;
代码演示:
#include <stdio.h>
//代码1
int main()
{
int age = 0;
scanf("%d", &age);
if(age<18)
{
printf("未成年\n");
}
}
//代码2
#include <stdio.h>
int main()
{
int age = 0;
scanf("%d", &age);
if(age<18)
{
printf("未成年\n");
}
else
{
printf("成年\n");
}
}
//代码3
#include <stdio.h>
int main()
{
int age = 0;
scanf("%d", &age);
if(age<18)
{
printf("少年\n");
}
else if(age>=18 && age<30)
{
printf("青年\n");
}
else if(age>=30 && age<50)
{
printf("中年\n");
}
else if(age>=50 && age<80)
{
printf("老年\n");
}
else
{
printf("老寿星\n");
}
}
解释一下:
如果表达式的结果为真,则语句执行。
在C语言中如何表示真假?
0表示假,非0表示真。
如果条件成立,要执行多条语句,怎应该使用代码块。
#include <stdio.h>
int main()
{
if(表达式)
{
语句列表1;
}
else
{
语句列表2;
}
return 0;
}
这里的一对 { } 就是一个代码块。
当你写了这个代码
#include <stdio.h>
int main()
{
int a = 0;
int b = 2;
if(a == 1)
if(b == 2)
printf("hehe\n");
else
printf("haha\n");
return 0;
}
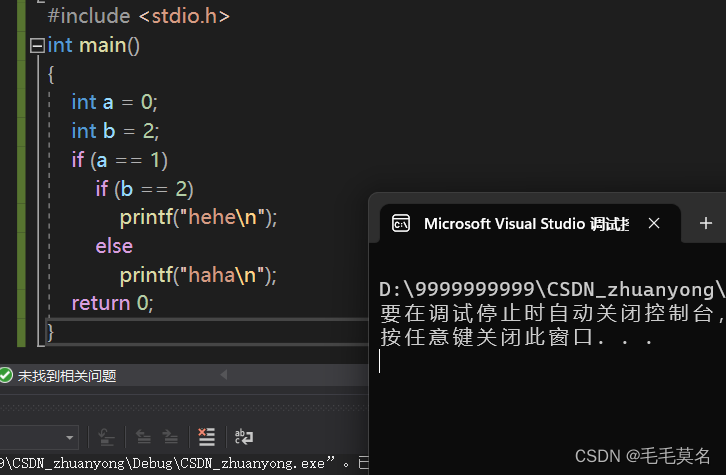
改正:
//适当的使用{}可以使代码的逻辑更加清楚。
//代码风格很重要
#include <stdio.h>
int main()
{
int a = 0;
int b = 2;
if(a == 1)
{
if(b == 2)
{
printf("hehe\n");
}
}
else
{
printf("haha\n");
}
return 0;
}
else的匹配:else是和它离的最近的if匹配的。
//代码1
if (condition) {
return x;
}
return y;
//代码2
if(condition)
{
return x;
}
else
{
return y;
}
//代码3
int num = 1;
if(num == 5)
{
printf("hehe\n");
}
//代码4
int num = 1;
if(5 == num)
{
printf("hehe\n");
}
代码2和代码4更好,逻辑更加清晰,不容易出错
switch语句也是一种分支语句。
常常用于多分支的情况。
比如
输入1,输出星期一
输入2,输出星期二
输入3,输出星期三
输入4,输出星期四
输入5,输出星期五
输入6,输出星期六
输入7,输出星期日
那我没写成 if…else if …else if 的形式太复杂,那我们就得有不一样的语法形式。
这就是switch语句。
switch(整型表达式)
{
语句项;
}
而语句项是什么呢?
//是一些case语句:
//如下:
case 整形常量表达式:
语句;
在switch语句中,我们没办法直接实现分支,搭配break使用才能实现真正的分支。
比如:
#include <stdio.h>
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
printf("星期一\n");
break;
case 2:
printf("星期二\n");
break;
case 3:
printf("星期三\n");
break;
case 4:
printf("星期四\n");
break;
case 5:
printf("星期五\n");
break;
case 6:
printf("星期六\n");
break;
case 7:
printf("星期天\n");
break;
}
return 0;
}
有时候我们的需求变了:
- 输入1-5,输出的是“weekday”;
- 输入6-7,输出“weekend”
所以我们的代码就应该这样实现了:
#include <stdio.h>
//switch代码演示
int main()
{
int day = 0;
scanf("%d", &day);
switch (day)
{
case 1:
case 2:
case 3:
case 4:
case 5:
printf("weekday\n");
break;
case 6:
case 7:
printf("weekend\n");
break;
}
return 0;
}
break语句 的实际效果是把语句列表划分为不同的分支部分。
编程好习惯
在最后一个 case 语句的后面加上一条 break语句。
(之所以这么写是可以避免出现在以前的最后一个 case 语句后面忘了添加 break语句)。
如果表达的值与所有的case标签的值都不匹配怎么办?
其实也没什么,结构就是所有的语句都被跳过而已。
程序并不会终止,也不会报错,因为这种情况在C中并不认为是个错误。
但是,如果你并不想忽略不匹配所有标签的表达式的值时该怎么办呢?
你可以在语句列表中增加一条default子句,把下面的标签
default:
写在任何一个case标签可以出现的位置。
当switch表达式的值并不匹配所有case标签的值时,这个default子句后面的语句就会执行。
所以,每个switch语句中只能出现一条default子句。
但是它可以出现在语句列表的任何位置,而且语句流会像执行一个case标签一样执行default子句。
编程好习惯
在每个 switch 语句中都放一条default子句是个好习惯,甚至可以在后边再加一个 break 。
计算结果:
#include <stdio.h>
int main()
{
int n = 1;
int m = 2;
switch (n)
{
case 1:
m++;
case 2:
n++;
case 3:
switch (n)
{//switch允许嵌套使用
case 1:
n++;
case 2:
m++;
n++;
break;
}
case 4:
m++;
break;
default:
break;
}
printf("m = %d, n = %d\n", m, n);
return 0;
}

我们已经掌握了,if语句:
if(条件)
语句;
当条件满足的情况下,if语句后的语句执行,否则不执行。
但是这个语句只会执行一次。
由于我们发现生活中很多的实际的例子是:同一件事情我们需要完成很多次。
那我们怎么做呢?
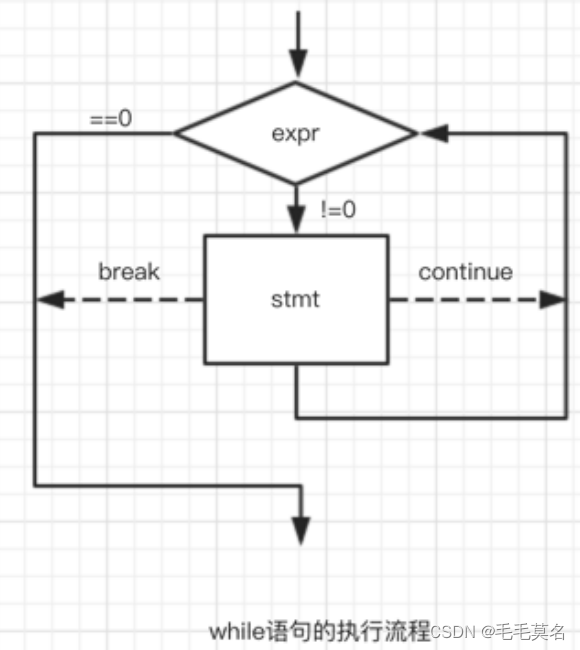
C语言中给我们引入了: while 语句,可以实现循环。
//while 语法结构
while(表达式)
循环语句;
while语句执行的流程:
比如我们实现:
在屏幕上打印1-10的数字。
#include <stdio.h>
int main()
{
int i = 1;
while(i<=10)
{
printf("%d ", i);
i = i+1;
}
return 0;
}
上面的代码已经帮我了解了while语句的基本语法,那我们再了解一下:
break介绍
//break 代码实例
#include <stdio.h>
int main()
{
int i = 1;
while(i<=10)
{
if(i == 5)
break;
printf("%d ", i);
i = i+1;
}
return 0;
}
代码输出结果:
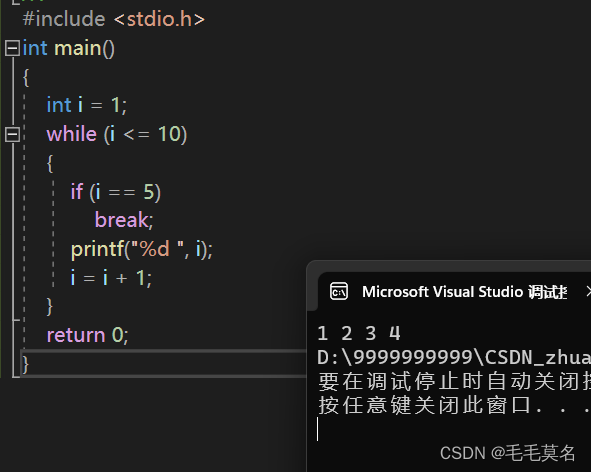
总结:
break在while循环中的作用:
其实在循环中只要遇到break,就停止后期的所有的循环,直接终止循环。
所以:while中的break是用于永久终止循环的。
continue介绍
//continue 代码实例1
#include <stdio.h>
int main()
{
int i = 1;
while(i<=10)
{
if(i == 5)
continue;
printf("%d ", i);
i = i+1;
}
return 0;
}
代码输出结果:
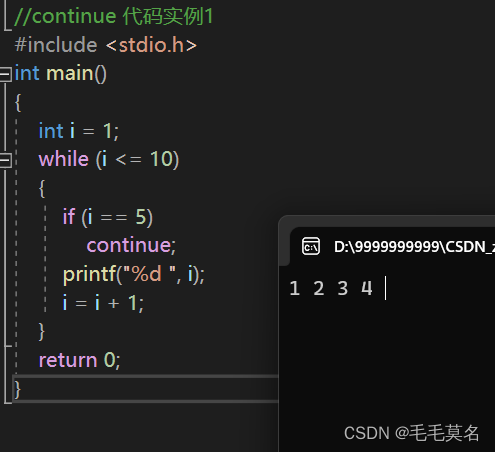
//continue 代码实例2
#include <stdio.h>
int main()
{
int i = 1;
while(i<=10)
{
i = i+1;
if(i == 5)
continue;
printf("%d ", i);
}
return 0;
}
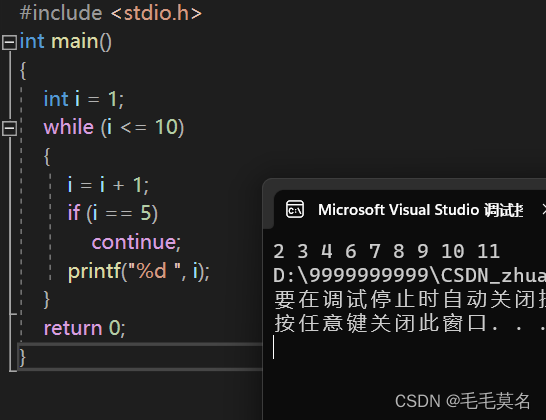
上面两个例子对比思考,加深理解。
总结:
continue在while循环中的作用就是:
continue是用于终止本次循环的,也就是本次循环中continue后边的代码不会再执行,而是直接跳转到while语句的判断部分。进行下一次循环的入口判断。
我们已经知道了while循环,但是我们为什么还要一个for循环呢?
首先来看看for循环的语法:
for(表达式1; 表达式2; 表达式3)
循环语句;
表达式1
表达式1为初始化部分,用于初始化循环变量的。
表达式2
表达式2为条件判断部分,用于判断循环时候终止。
表达式3
表达式3为调整部分,用于循环条件的调整。
实际的问题:
使用for循环 在屏幕上打印1-10的数字。
#include <stdio.h>
int main()
{
int i = 0;
//for(i=1/*初始化*/; i<=10/*判断部分*/; i++/*调整部分*/)
for(i=1; i<=10; i++)
{
printf("%d ", i);
}
return 0;
}
for循环的执行流程图:
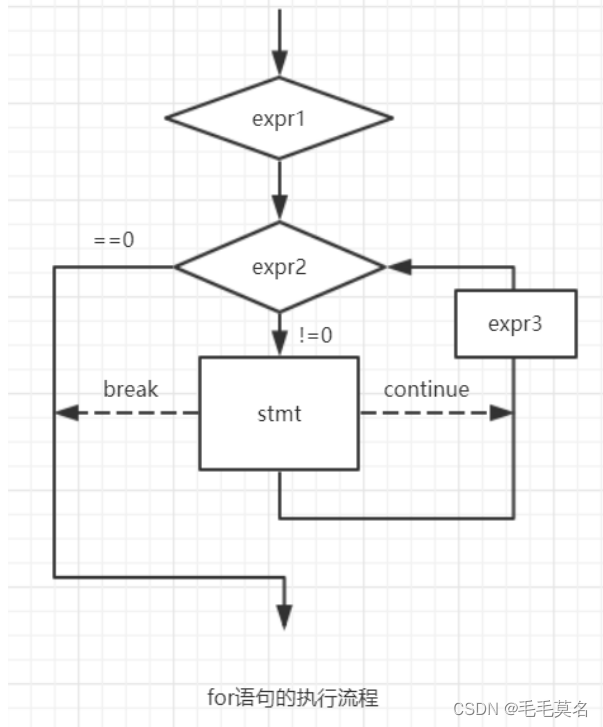
现在我们对比一下for循环和while循环。
int i = 0;
//实现相同的功能,使用while
i=1;//初始化部分
while(i<=10)//判断部分
{
printf("hehe\n");
i = i+1;//调整部分
}
//实现相同的功能,使用while
for(i=1; i<=10; i++)
{
printf("hehe\n");
}
可以发现在while循环中依然存在循环的三个必须条件,但是由于风格的问题使得三个部分很可能偏离较远,这样查找修改就不够集中和方便。所以,for循环的风格更胜一筹;for循环使用的频率也最高。
建议:
- 不可在for 循环体内修改循环变量,防止 for 循环失去控制。
- 建议for语句的循环控制变量的取值采用“前闭后开区间”写法。
int i = 0;
//前闭后开的写法
for(i=0; i<10; i++)
{}
//两边都是闭区间
for(i=0; i<=9; i++)
{}
#include <stdio.h>
int main()
{
//代码1
for(;;)
{
printf("hehe\n");
}
//for循环中的初始化部分,判断部分,调整部分是可以省略的,但是不建议初学时省略,容易导致问
题。
//代码2
int i = 0;
int j = 0;
//这里打印多少个hehe?
for(i=0; i<10; i++)
{
for(j=0; j<10; j++)
{
printf("hehe\n");
}
}
//代码3
int i = 0;
int j = 0;
//如果省略掉初始化部分,这里打印多少个hehe?
for(; i<10; i++)
{
for(; j<10; j++)
{
printf("hehe\n");
}
}
//代码4-使用多余一个变量控制循环
int x, y;
for (x = 0, y = 0; x<2 && y<5; ++x, y++)
{
printf("hehe\n");
}
return 0;
}
请问循环要循环多少次?
#include <stdio.h>
int main()
{
int i = 0;
int k = 0;
for(i =0,k=0; k=0; i++,k++)
k++;
return 0;
}
答案是“0次”,直接死循环了。
do
循环语句;
while(表达式);
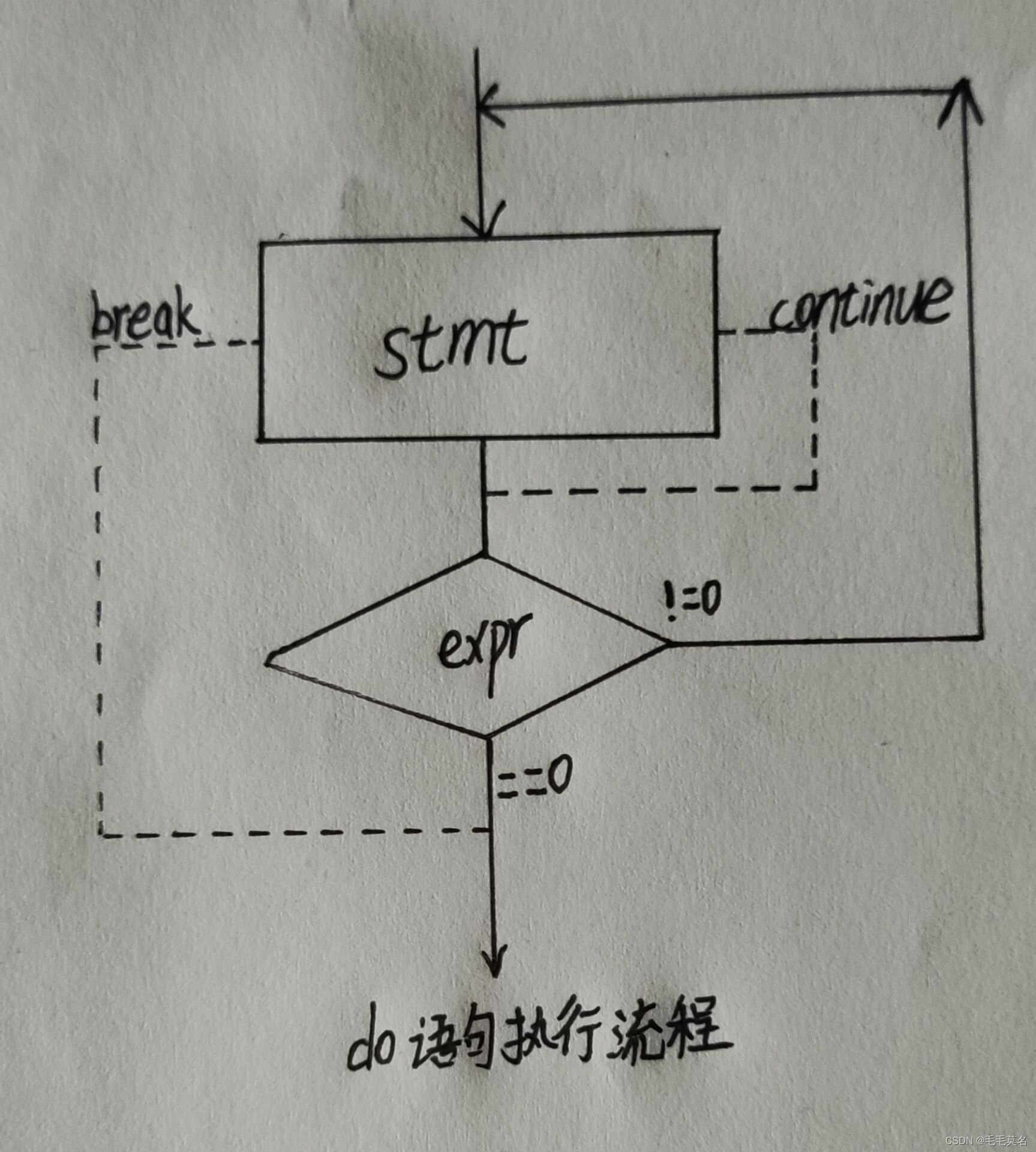
循环至少执行一次,使用的场景有限,所以不是经常使用。
#include <stdio.h>
int main()
{
int i = 1;
do
{
printf("%d ", i);
i=i+1;
}while(i<=10);
return 0;
}
#include <stdio.h>
int main()
{
int i = 1;
do
{
if(5 == i)
break;
printf("%d ", i);
i=i+1;
}while(i<=10);
return 0;
}
#include <stdio.h>
int main()
{
int i = 1;
do
{
if(5 == i)
continue;
printf("%d ", i);
i=i+1;
}while(i<=10);
return 0;
}
C语言中提供了可以随意滥用的 goto语句和标记跳转的标号。
从理论上 goto语句是没有必要的,实践中没有goto语句也可以很容易的写出代码。
但是某些场合下goto语句还是用得着的,最常见的用法就是终止程序在某些深度嵌套的结构的处理过程。
例如:一次跳出两层或多层循环。
多层循环这种情况使用break是达不到目的的。它只能从最内层循环退出到上一层的循环。
goto语言真正适合的场景如下:
for(...)
for(...)
{
for(...)
{
if(disaster)
goto error;
}
}
…
error:
if(disaster)
// 处理错误情况
下面是使用goto语句的一个例子,然后使用循环的实现方式替换goto语句:
一个关机程序
#include <stdio.h>
int main()
{
char input[10] = {0};
system("shutdown -s -t 60");
again:
printf("电脑将在1分钟内关机,如果输入:我是猪,就取消关机!\n请输入:>");
scanf("%s", input);
if(0 == strcmp(input, "我是猪"))
{
system("shutdown -a");
}
else
{
goto again;
}
return 0;
}
而如果不适用goto语句,则可以使用循环:
#include <stdio.h>
#include <stdlib.h>
int main()
{
char input[10] = {0};
system("shutdown -s -t 60");
while(1)
{
printf("电脑将在1分钟内关机,如果输入:我是猪,就取消关机!\n请输入:>");
scanf("%s", input);
if(0 == strcmp(input, "我是猪"))
{
system("shutdown -a");
break;
}
}
return 0;
}
关于shutdown命令的拓展
本章完,感谢您的阅读,如果觉的有用的话,请点赞支持一下,谢谢您。
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我注意到类定义,如果我打开classMyClass,并在不覆盖的情况下添加一些东西我仍然得到了之前定义的原始方法。添加的新语句扩充了现有语句。但是对于方法定义,我仍然想要与类定义相同的行为,但是当我打开defmy_method时似乎,def中的现有语句和end被覆盖了,我需要重写一遍。那么有什么方法可以使方法定义的行为与定义相同,类似于super,但不一定是子类? 最佳答案 我想您正在寻找alias_method:classAalias_method:old_func,:funcdeffuncold_func#similartoca
在添加一些空格以使代码更具可读性时(与上面的代码对齐),我遇到了这个:classCdefx42endendm=C.new现在这将给出“错误数量的参数”:m.x*m.x这将给出“语法错误,意外的tSTAR,期待$end”:2/m.x*m.x这里的解析器到底发生了什么?我使用Ruby1.9.2和2.1.5进行了测试。 最佳答案 *用于运算符(42*42)和参数解包(myfun*[42,42])。当你这样做时:m.x*m.x2/m.x*m.xRuby将此解释为参数解包,而不是*运算符(即乘法)。如果您不熟悉它,参数解包(有时也称为“spl
我想从then子句中访问case语句表达式,即food="cheese"casefoodwhen"dip"then"carrotsticks"when"cheese"then"#{expr}crackers"else"mayo"end在这种情况下,expr是食物的当前值(value)。在这种情况下,我知道,我可以简单地访问变量food,但是在某些情况下,该值可能无法再访问(array.shift等)。除了将expr移出到局部变量然后访问它之外,是否有直接访问caseexpr值的方法?罗亚附注我知道这个具体示例很简单,只是一个示例场景。 最佳答案
我是Ruby的新手,有些闭包逻辑让我感到困惑。考虑这段代码:array=[]foriin(1..5)array[5,5,5,5,5]这对我来说很有意义,因为i被绑定(bind)在循环之外,所以每次循环都会捕获相同的变量。使用每个block可以解决这个问题对我来说也很有意义:array=[](1..5).each{|i|array[1,2,3,4,5]...因为现在每次通过时都单独声明i。但现在我迷路了:为什么我不能通过引入一个中间变量来修复它?array=[]foriin1..5j=iarray[5,5,5,5,5]因为j每次循环都是新的,我认为每次循环都会捕获不同的变量。例如,这绝对
如何在Ruby的if语句中检查bash命令的返回值(true/false)。我想要这样的东西,if("/usr/bin/fswscell>/dev/null2>&1")has_afs="true"elsehas_afs="false"end它会提示以下错误含义,它总是返回true。(irb):5:warning:stringliteralincondition正确的语法是什么?更新:/usr/bin/fswscell寻找afs安装和运行状态。它会抛出这样的字符串,Thisworkstationbelongstocell如果afs没有运行,命令以状态1退出 最
我最近与一位同事讨论了以下Ruby语法:value=ifa==0"foo"elsifa>42"bar"else"fizz"end我个人并没有看到太多这种逻辑,但我的同事指出,这实际上是一种相当普遍的Rubyism。我试着用谷歌搜索这个主题,但没有找到任何文章、页面或SO问题来讨论它,这让我相信这可能是一种非常实际的技术。然而,另一位同事发现语法令人困惑,而是将上面的逻辑写成这样:ifa==0value="foo"elsifa>42value="bar"elsevalue="fizz"end缺点是value=的重复声明和隐式elsenil的丢失,如果我们想使用它的话。这也感觉它与Ruby
这段代码没有像我预期的那样执行:casewhen->{false}then"why?"else"ThisiswhatIexpect"end#=>"why?"这也不是casewhen->(x){false}then"why?"else"ThisiswhatIexpect"end#=>"why?"第一个then子句在两种情况下都被执行,这意味着我提供给when子句的lambda没有被调用。我知道无论when子句的主题是什么,都应该调用大小写相等运算符===。我想知道当没有为case提供参数时,===的另一边会发生什么。我在想它可能是nil,但它不可能是:->{false}===nil#=>