非线性规划问题是目标函数或约束条件中包含非线性函数的规划问题。一般说来,求解非线性规划问题比求解线性规划问题困难得多。而且,不像线性规划有单纯形法这一通用方法,非线性规划目前还没有适用于各种问题的一般算法,已有的各种方法都有其特定的适用范围。
利用间接法求解最优化问题的途径一般有两种:一种是在可行域内使目标函数下降的迭代算法,如可行点法;另一种是利用目标函数和约束条件构造增广目标函数,借此将约束最优化问题转化为无约束最优化问题,如罚函数法、乘子法、序列二次规划法等。
序列二次规划算法是目前公认的求解约束非线性优化问题最有效的方法之一。与其他算法相比,序列二次规划法的优点是收敛性好、计算效率高、边界搜索能力强,因此受到了广泛的重视及应用。在序列二次规划法的迭代过程中,每一步都需要求解一个或多个二次规划(QP)子问题。 一般地,由于二次规划子问题的求解难以利用原问题的稀疏性、对称性等良好特性,随着问题规模的扩大,其计算工作量和所需存储量是非常大的。因此,目前的序列二次规划算法一般只适用与中小规模问题。
序列二次规划(SQP)算法是将复杂的非线性约束最优化问题转化为比较简单的二次规划(QP)问题求解的算法。所谓二次规划问题,就是目标函数为二次函数,约束函数为线性函数的最优化问题。
公式1-1
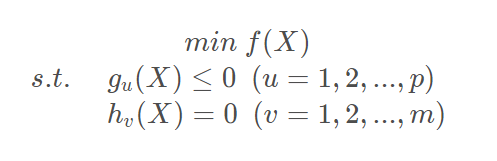
序列二次规划的基本思想即是利用泰勒展开将非线性约束问题(1-1)的目标函数在迭代点Xk处简化成二次函数,将约束条件简化成线性函数。得到如下二次规划问题:
公式1-2
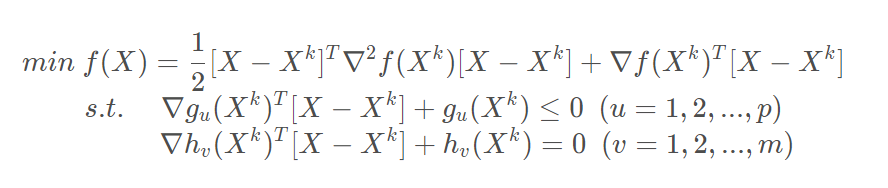
由于(1-2)只是原问题的近似问题,求得的解并不是原问题的最优解,只是一个在局部更好的一个解。为此,令:

将上述二次规划问题变成关于变量 S 的问题,即:
公式1-3
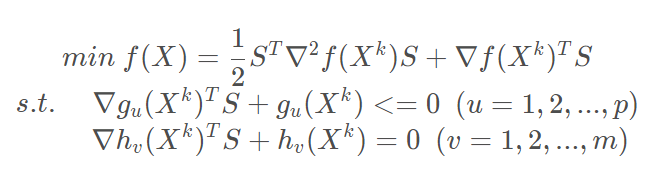
令:
公式1-4

将式(1-4)写成二次规划问题的一般形式,即:
公式1-5
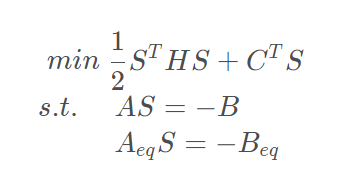
求解此二次规划问题,将其 最优解 S* 作为原问题的下一个 搜索方向 Sk,并在该方向上进行原约束问题目标函数的约束一维搜索,这样就可以得到原约束问题的一个近似解 Xk+1 。
反复这一过程,就可以得到原问题的最优解。
上述思想得以实现的关键在于如何计算函数的二阶导数矩阵 H(DFP、BFGS),以及如何求解式(1-5)所示的二次规划问题。
问题的求解主要分为两个部分:第一个部分为通过泰勒展开,将原非线性优化问题转换为简单的二次优化问题;第二个部分为对简单的二次优化问题进行迭代搜索求解。
迭代求解的步骤如下所示:

根据约束条件的不同,二次规划可分为等式约束二次规划问题和不等式约束二次规划问题。等式约束二次规划问题即只含有等式约束,常见的解法有直接消去法、广义消去法、拉格朗日(Lagrange)法;对于不等式约束二次规划问题,其基本思想是把不等式约束转化为等式约束再求解,常见解法有有效集(active set)方法,有效集方法在每步迭代中把有效约束作为等式约束,然后可以用拉格朗日法求解,重复直到求得最优解。二次规划问题的求解待更新
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
我有一个存储JSON数据的列。当它处于编辑状态时,我不知道如何显示它。serialize:value,JSON=f.fields_for:valuedo|ff|.form-group=ff.label:short=ff.text_field:short,class:'form-control'.form-group=ff.label:long=ff.text_field:long,class:'form-control' 最佳答案 代替=f.fields_for:valuedo|ff|请使用以下代码:=f.fields_for:va
在RubyonRails中,如果数组为空,则具有序列化数组字段的模型将不会在.save()上更新,而它之前有数据。我正在使用:ruby2.2.1rails4.2.1sqlite31.3.10我创建了一个字段设置为文本的新模型:railsgmodel用户名:stringexample:text在我添加的User.rb文件中:serialize:example,Array我实例化了User类的一个新实例:test=User.new然后我保存用户以确保它正确保存:test.save()(0.1ms)begintransactionSQL(0.4ms)INSERTINTO"users"("cr
是否可以在使用YAML.load_file时强制Ruby调用初始化方法?我想调用该方法以便为我不序列化的实例变量提供值。我知道我可以将代码分解成一个单独的方法并在调用YAML.load_file之后调用该方法,但我想知道是否有更优雅的方法来处理这个问题。 最佳答案 我认为你做不到。由于您要添加的代码确实特定于要反序列化的类,因此您应该考虑在类中添加该功能。例如,让Foo成为您要反序列化的类,您可以添加一个类方法,例如:classFoodefself.from_yaml(yaml)foo=YAML::load(yaml)#editth
我有以下工厂:FactoryGirl.definedofactory:foodosequence(:name){|n|"Foo#{n}"}trait:ydosequence(:name){|n|"Fooy#{n}"}endendend如果我跑create:foocreate:foocreate:foo,:y我得到Foo1,Foo2,Fooy1。但我想要Foo1,Foo2,Fooy3。我怎样才能做到这一点? 最佳答案 经过smile2day'sanswer的一些提示后和thisanswer,我得出以下解决方案:FactoryGirl.
我正在对用户的提要进行分页,并想模拟我正在使用的API的响应。API可以返回奇怪的结果,所以我想确保如果API返回我已经看到的项目,请停止分页。我使用minitest在第一次调用方法get_next_page时stub,但我想在第二次和第三次用不同的值调用它时stub。我应该只使用rSpec吗?ruby新手...这是片段test"crawlerdoesnotpaginateifnonewitemsinnextpage"do#1:A,B#2:B,D=>D#3:A=>stopcrawler=CrawlJob.newfirst_page=[{"id"=>"item-A"},{"id"=>"i
我有两个Foo对象列表。每个Foo对象都有一个时间戳,Foo.timestamp。两个列表最初都按时间戳降序排列。我想以最终列表也按时间戳降序排序的方式合并Foo对象的两个列表。实现这个并不难,但我想知道是否有任何内置的Ruby方法可以做到这一点,因为我认为内置方法会产生最佳性能。谢谢。 最佳答案 这会起作用,但不会提供很好的性能,因为它不会利用事先已经排序的列表:list=(list1+list2).sort_by(&:timestamp)我不知道有任何内置函数可以满足您的需求。 关于