# Parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone by yoloair
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3STR, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3STR, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3STR, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3STR, [1024]], # 9 <--- ST2CSPB() Transformer module
[-1, 1, SPPF, [512, 512]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
在common.py中增加以下下代码:
class SwinTransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers, window_size=8):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
# remove input_resolution
self.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2) for i in range(num_layers)])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# print(attn.dtype, v.dtype)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
#print(attn.dtype, v.dtype)
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class SwinTransformerLayer(nn.Module):
def __init__(self, dim, num_heads, window_size=8, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.SiLU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
# if min(self.input_resolution) <= self.window_size:
# # if window size is larger than input resolution, we don't partition windows
# self.shift_size = 0
# self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def create_mask(self, H, W):
# calculate attention mask for SW-MSA
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
# reshape x[b c h w] to x[b l c]
_, _, H_, W_ = x.shape
Padding = False
if min(H_, W_) < self.window_size or H_ % self.window_size!=0 or W_ % self.window_size!=0:
Padding = True
# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')
pad_r = (self.window_size - W_ % self.window_size) % self.window_size
pad_b = (self.window_size - H_ % self.window_size) % self.window_size
x = F.pad(x, (0, pad_r, 0, pad_b))
# print('2', x.shape)
B, C, H, W = x.shape
L = H * W
x = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c
# create mask from init to forward
if self.shift_size > 0:
attn_mask = self.create_mask(H, W).to(x.device)
else:
attn_mask = None
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h w
if Padding:
x = x[:, :, :H_, :W_] # reverse padding
return x
class C3STR(C3):
# C3 module with SwinTransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
在parse_model(d, ch)函数中增加C3STR
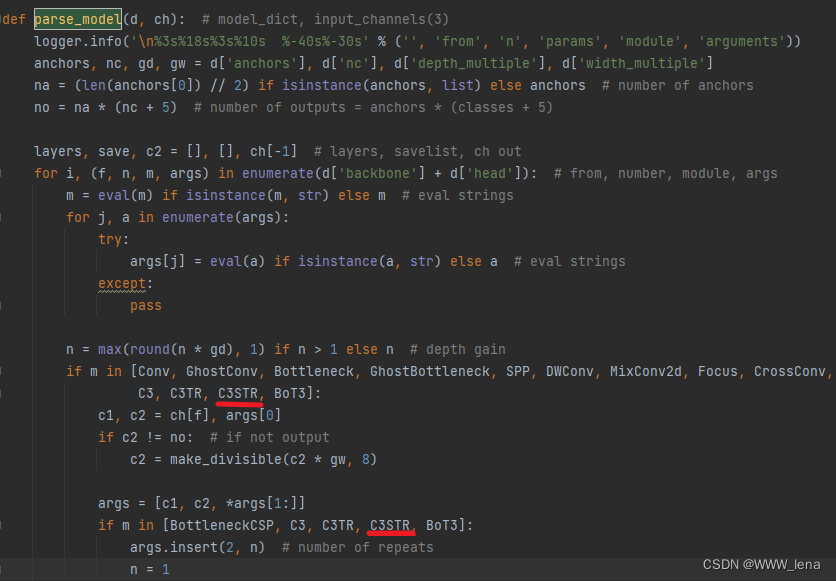
在if __name__ == '__main__':中更改cfg

1.NameError: name 'F' is not defined
在common.py中增加以下代码:
import torch.nn.functional as F2.File "D:\Projects\yoloair-main\models\common.py", line 1519, in __init__
super().__init__(c1, c2, c2, n, shortcut, g, e)
TypeError: __init__() takes from 3 to 7 positional arguments but 8 were given
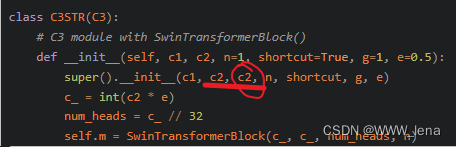
去掉一个c2。
3.NameError: name 'window_partition' is not defined
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
4.NameError: name 'window_reverse' is not defined
ef window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
我在开发的Rails3网站的一些搜索功能上遇到了一个小问题。我有一个简单的Post模型,如下所示:classPost我正在使用acts_as_taggable_on来更轻松地向我的帖子添加标签。当我有一个标记为“rails”的帖子并执行以下操作时,一切正常:@posts=Post.tagged_with("rails")问题是,我还想搜索帖子的标题。当我有一篇标题为“Helloworld”并标记为“rails”的帖子时,我希望能够通过搜索“hello”或“rails”来找到这篇帖子。因此,我希望标题列的LIKE语句与acts_as_taggable_on提供的tagged_with方法
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我需要从基于ruby的应用程序使用AmazonSimpleNotificationService,但不知道从哪里开始。您对从哪里开始有什么建议吗?
希望我没有误解“ducktyping”的含义,但从我读到的内容来看,这意味着我应该根据对象如何响应方法而不是它是什么类型/类来编写代码。代码如下:defconvert_hash(hash)ifhash.keys.all?{|k|k.is_a?(Integer)}returnhashelsifhash.keys.all?{|k|k.is_a?(Property)}new_hash={}hash.each_pair{|k,v|new_hash[k.id]=v}returnnew_hashelseraise"CustomattributekeysshouldbeID'sorPropertyo
我有一个基本的Rails应用程序测试,其中包含一个用回形针处理的照片字段的用户模型。我创建了能够创建/编辑用户的View,并且照片上传工作正常。Editinguseruser_path(@user),:html=>{:method=>"put",:multipart=>true}do|f|%>|然后,我想将SWFUpload集成到我的应用程序中。我试着按照这个tutorial并运行testproject没有任何成功:浏览按钮不会打开文件对话框,并抛出错误#2176,这是关于selectFiles()方法的。首先,问题是Flashv.10与项目中包含的旧版本SWFUpload(2.1.0
我正在尝试使Authlogic和FacebookConnect(使用Facebook)发挥良好的作用,以便您可以通过正常注册方式或使用Facebookconnect创建帐户。我已经能够让连接以一种方式工作,但注销只会在facebook而不是我的网站上注销,我必须删除cookie才能使其正常工作。任何帮助都会很棒,谢谢! 最佳答案 这是我使用FacebookConnect扩展、authlogic和OpenID制作的示例应用程序。它仍然需要一些工作,但它确实起作用了。http://big-glow-mama.heroku.com/htt
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我正在用Ruby编写DSL来控制我正在处理的Arduino项目;巴尔迪诺。这是一只酒吧猴子,将由软件控制来提供饮料。Arduino通过串行端口接收命令,告诉Arduino要打开什么泵以及打开多长时间。它目前正在读取一个食谱(见下文)并将其打印出来。串行通信的代码以及我在下面提到的其他一些想法仍然需要改进。这是我的第一个DSL,我正在处理之前的示例,所以它的边缘非常粗糙。任何批评、代码改进(是否有任何关于RubyDSL最佳实践或习语的良好引用?)或任何一般性评论。我目前有DSL的粗略草稿,因此饮料配方如下所示(Githublink):desc"Simpleglassofwater"rec
亚马逊的documentation提供有关如何使用DynamoDBLocal的Java、.NET和PHP示例。你如何用AWSRubySDK做同样的事情??我的猜测是你在初始化时传入了一些参数,但我不知道它们是什么。dynamo_db=AWS::DynamoDB.new(:access_key_id=>'...',:secret_access_key=>'...') 最佳答案 您使用的是SDK的v1还是v2?您需要找出答案;从上面的简短片段来看,它看起来像v2。为了以防万一,我已经包含了这两个答案。v1答案:AWS.config(us
我正在尝试使用ruby改进来应用Rails钩子(Hook)。我想避免猴子补丁。当猴子修补时它会这样工作ActiveRecord::Base.class_evaldoafter_finddo#dosomethingwithmy_methodenddefmy_method#somethingusefulendend我已经能够通过做这样的事情来拥有类方法:moduleActiveRecordRefinementsrefineActiveRecord::Base.singleton_classdodefmy_method#somethingcoolendendend但我无法运行钩子(Hoo
我想知道这个问题已经有一段时间了,但还没有真正找到答案。为什么要在Rails应用程序中使用Backbone.jsexaclty?是为了扩展功能、为您的JS提供更多MVC模式、构建更好的API......?目前我看不出你为什么要用它来做什么,因为我不认为我理解Backbone.js的概念 最佳答案 Rails的一大优势在于您拥有一个平台和一种语言,可以处理服务器代码并生成客户端代码(使用View)。毫无疑问,一旦您想使用javascript和jquery改善用户体验,这种理论上的优势就会迅速消失。所以实际上你还是要学习两种语言。但仍然