大家好,我是树哥。
在之前的文章里,我们讨论了关于 MySQL 的许多问题,包括:
在这些文章中,我们大致了解了一些加锁的情况。但实际上 MySQL 的加锁规则是怎样的,我还不是特别清楚。所以今天我们就来深入了解下 MySQL 的加锁规则。
MySQL 的加锁规则到底是怎样的?
为了弄清楚这些加锁规则,我查阅了许多资料。但在这些资料中,我觉得比较有质量的只有两个:一个是极客时间《MySQL 45 讲》第 20/21 节讲得内容,另一个是一篇从源码角度解析加锁规则的文章。
《MySQL 45 讲》是丁奇老师出的一个专栏,现在是腾讯云数据库负责人。在该专栏的第 21、22 节中讲到了具体的加锁规则,并且也举了非常多的例子。本文也将摘取其中一些内容,来跟大家讨论学习。
另一篇从源码角度讲加锁规则的,是网名为「小孩子」的网友写得一篇文章,其后续出了一本书叫《从根上了解 MySQL》,内容非常多并且很详细。这篇文章从源码角度从头到尾分析了整个加锁规则,讲得还是比较详细。
在看着两份资料之前,我总是尝试去找到一个简单好记的加锁规律,但看完之后觉得:这或许不太可能。丁奇大神在其专栏也提到他是怎么去分析加锁规则的。
首先说明一下,这些加锁规则我没在别的地方看到过有类似的总结,以前我自己判断的时候都是想着代码里面的实现来脑补的。这次为了总结成不看代码的同学也能理解的规则,是我又重新刷了代码临时总结出来的。
可以看到,就连大神也是想着代码脑补加锁规律的。再结合「小孩子」从源码角度去分析加锁规则,我一下子就觉得:或许还是该深入到源码角度,才能一窥真相。
即使后面丁奇老师为了方便我们理解,也总结出了一些加锁(如下图所示)。但实际上这些加锁规则也没啥规律,只能是记着就好。此外,他也提出:我们需要用动态的眼光去看加锁。言外之意就是,这些规则可能都是变化的,也不一定是完全正确的。

图片来自极客时间专栏
看到这里,我会想:那我们应该怎么学习 MySQL 的加锁规则呢?
我思考了片刻,给出的答案是:我们可以按照丁奇老师总结出的加锁规则先行学习,后续再深入源码层面不断地补足一些细节。
在讲一些具体加锁规则之前,我觉得有必要先给大家一个 MySQL 加锁的全局视角。这个是丁奇老师在文章中没讲到的,但我觉得如果不知道全局视角,那么会影响到对一些规则的理解。
我们知道 MySQL 分成了 Server 层和存储引擎两部分,每当执行一个查询时,Server 层负责生成执行计划,然后交给存储引擎去执行。其整个过程可以这样描述:
通过上面这个过程,我想让大家明白两个重要的认识:
弄懂了上面两个认识,会对后续大家理解有很大帮助。例如:对于 select * from user where id >= 5 进行分析的时候,为什么会出现说第一次加锁是精确查询?它明明是范围查询呀!这是因为第一次是要寻找到 id = 5 的记录,对于 Innodb 来说,它就是精确查找,不是范围查找。随后找到 id = 5 的记录之后,就要找 id > 5 的记录了,此时就变成了范围查找了。
这里的加锁规则,我直接引用丁奇老师的总结:两个原则、两个优化、一个 bug。
对于原则 1 说的:加锁的基本单位是 Next-Key 锁,意思是默认都是先加上 Next-Key,之后根据 2 个优化点选择性退化为行锁或间隙锁。
对于原则 2 说的:访问到的对象才会加锁,意思是如果直接索引覆盖到了,不需要回表,那么就不会对聚簇索引加锁。这样的话,其他事务就可以对聚簇索引进行操作,而不会阻塞。
为了解释这些规则,建立表 t 并插入一些数据。
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
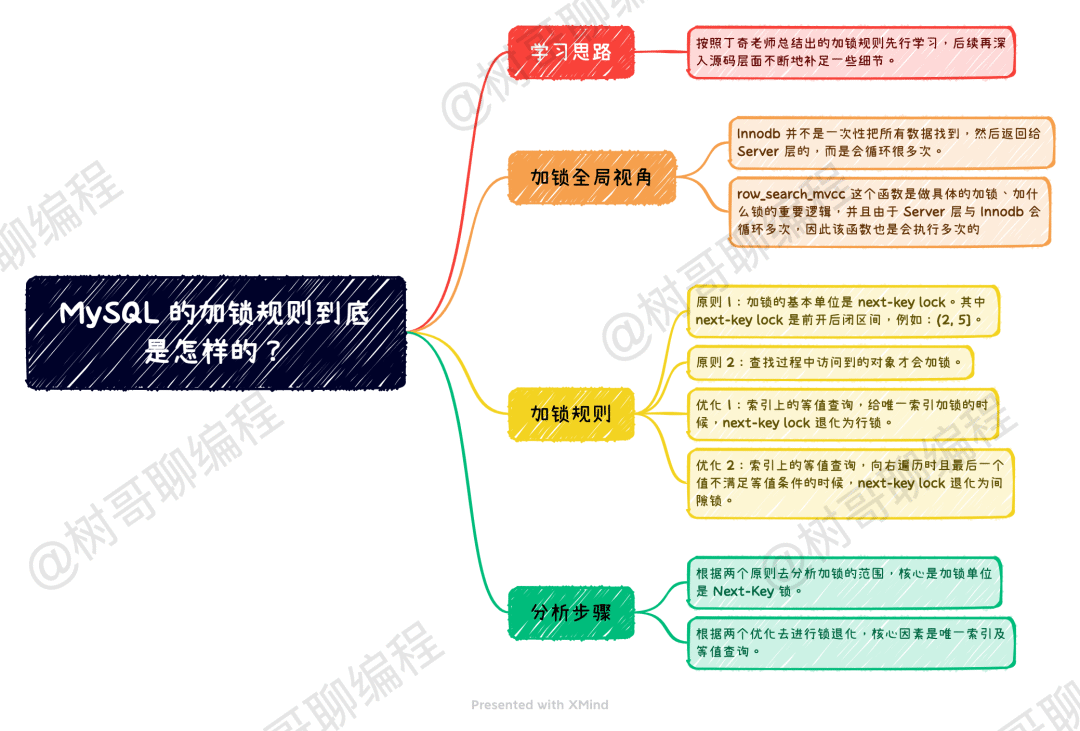
(10,10,10),(15,15,15),(20,20,20),(25,25,25);如下图所示的例子,是一个等值条件加间隙锁的例子。

图片来自极客时间专栏
在事务 A 中,要查找 id = 7 的记录,其查找过程为:从左到右查找 id 聚簇索引,依次对比 0、5 两个索引,发现不对。接着,对比 10 这个索引,发现 7 <10,于是停止搜索。根据原则 1 默认给其加上一个 Next-Key 锁,即 (5, 10]。根据优化 2 退化为间隙锁,即 (5,10)。
所以,session B 要插入 id=8 的记录会被锁住,而 session 修改 id=10 这行是可以的。
图片来自极客时间专栏
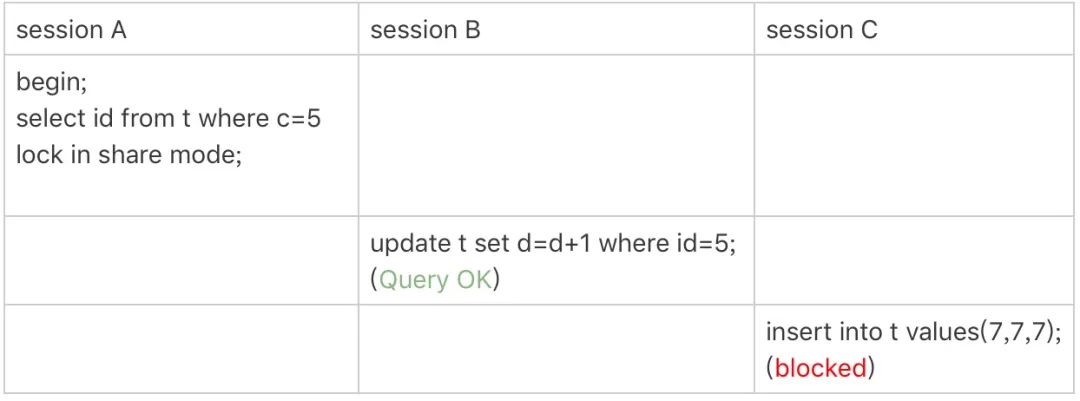
在事务 A 中,要查找 c=5 的记录,其中 c 是非唯一索引。其查找过程为:从左到右查找 c 索引,找到了 c=5 的索引,根据原则 1 对其加 Next-Key 锁,即 (0,5]。
由于普通索引可能重复,因此其还会继续往后搜索,接着搜索到 10,根据原则 2,访问到的都要加锁,因此再给其加 Next-Key 锁,即 (5,10]。由于这个还负责优化 2:等值判断,向右遍历,最后一个不满足等值条件,因此退化为间隙锁 (5,10)。
此外,根据原则 2,只有访问到的对象才会加锁。这个查询使用查询覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁。也就是说 (0,5] 和 (5,10) 这两个锁,只在索引 c 上加锁,并不在主键索引上加锁,因此 session B 可以执行。
session C 中插入一个 c 为 7 的值,c 为 7 的值在 (5,10) 之间,因此会被锁住。
对于我们这个表 t,下面这两条查询语句,加锁范围相同吗?
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;在逻辑上,这两条查语句肯定是等价的,但是它们的加锁规则不太一样。现在,我们就让 session A 执行第二个查询语句,来看看加锁效果。

图片来自极客时间专栏
我们来分析一下整体的加锁规则吧。
事务 A 开始执行的时候,要找到 id 为 10 的记录,于是从左到右找到了 id 为 10 的索引。根据原则 1 会给其加 Next-Key 锁,即 (5,10]。根据优化 1,id = 10 是等值查询,因此其退化为行锁,即只对 id = 10 这行加了行锁。
接着继续进行范围查找,找到 id=15 这一行,继续加 Next-Key 锁 (10,15]。这时候 id=15 大于 11,因此其不再查找。TODO
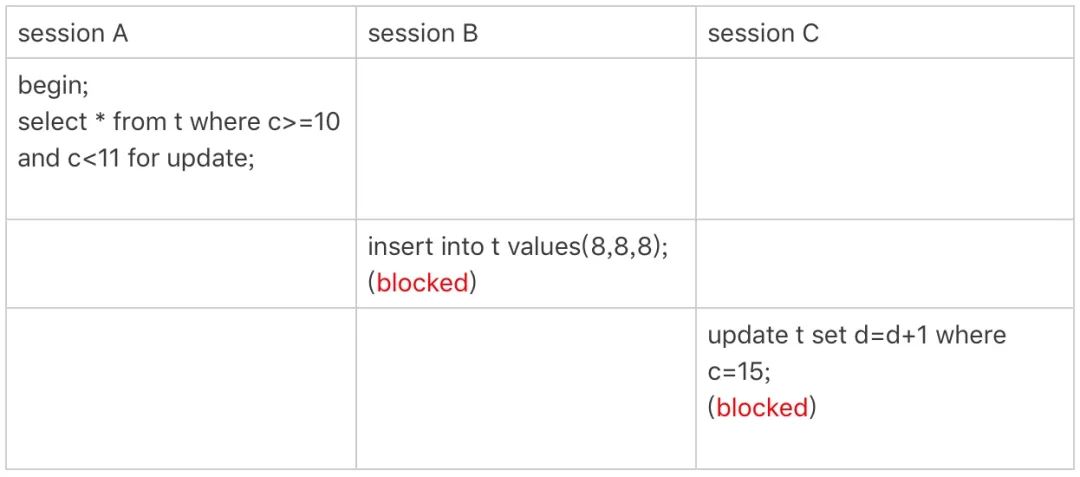
下面的 c 字段是非唯一普通索引,使用了范围查询。
图片来自极客时间专栏
事务 A 开始执行的时候,要找到 id 为 10 的记录,于是根据原则 1 加了 Next-Key 锁,即 (5,10]。由于索引 C 是非唯一索引,没有优化规则,因此不会退化为行锁。因此对于事务 A 来说,索引 C 上加的是 (5,10] 和 (10,15] 两个 Next-Key 锁。
所以当 session B 和 session C 要操作 c 值为 8 和 15 的数据时会被阻塞。
最后我们总结一下 MySQL 的加锁规则:
其中「两个原则、两个优化」是:
通过上面这样的加锁规则,我们就可以有一个大致的分析思路,至少能开始分析加锁规律了。
但要注意的是,实际上的情况非常复杂,例如 limit 参数也会影响加锁的范围,非唯一索引多个值夜会影响锁范围。简单地说,就是有很多特例的情况,我们还需要继续去积累。
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
我有以下代码#coloursarandomcellwithacorrectcolourdefcolour_random!whiletruedocol,row=rand(columns),rand(rows)cell=self[row,col]ifcell.empty?thencell.should_be_filled??cell.colour!(1):cell.colour!(0)breakendendend做什么并不重要,尽管它应该很明显。关键是Rubocop给了我一个警告Neveruse'do'withmulti-line'while为什么我不应该那样做?那我该怎么办呢?
我正在尝试绕过rails配置这个极其复杂的迷宫。到目前为止,我设法在ubuntu上设置了rvm(出于某种原因,ruby在ubuntu存储库中已经过时了)。我设法建立了一个Rails项目。我希望我的测试项目使用mysql而不是mysqlite。当我尝试“rakedb:migrate”时,出现错误:“!!!缺少mysql2gem。将其添加到您的Gemfile:gem'mysql2'”当我尝试“geminstallmysql”时,出现错误,告诉我需要为安装命令提供参数。但是,参数列表很大,我不知道该选择哪些。如何通过在ubuntu上运行的rvm和mysql获取rails3?谢谢。
一文解决关于VLAN所有的疑惑VLAN基本概念为什么需要VLAN?怎么在交换机上划分VLAN,VLAN的工作原理有了子网,已经隔离了广播,还需要VLAN干啥?只进行子网划分,不进行VLAN划分VLAN划分与子网划分附加VLAN信息的方法VLAN划分交换机的端口类型(Access和Trunk)一、访问链接二、汇聚链接汇聚链接VLAN间通信为什么要进行VLAN间通信?路由器实现VLAN间通信路由器和交换机的连接方式通信细节三层交换机实现VLAN间通信加速VLAN间通信三层交换机与路由器三层交换机路由器路由器和交换机配合构建LAN的实例使用VLAN设计局域网的特点VLAN增加网络的灵活性不使用VLA
目录1、yum安装mysql修改密码(1)在mysql里面修改(2)第二种方式,利用mysqladmin修改密码2、没有密码,登录mysql修改密码3、mysql的安全设置1、yum安装mysql在CentOS中默认安装有MariaDB(MySQL的一个分支),安装完成之后可以直接覆盖MariaDB。rpm-qa|grepmariadb查询是否安装了mariadbrpm-e--nodepsmariadb-libs-5.5.60-1.el7_5.x86_64卸载mariadwgethttp://dev.mysql.com/get/mysql57-community-release-el7-11.
我正在myrapwebsite上实现全文搜索功能,我遇到了一些关于说唱歌手和歌曲名称的问题。例如,某人可能想使用查询“camron”(省略中间单词撇号)来搜索说唱歌手“Cam'ron”。同样,有人可能会使用查询“3peat”来搜索歌曲“3Peat”。“TheNotoriousB.I.G.”有点奇怪:“TheNotoriousBIG”和“TheNotoriousB.I.G.”两者都有效(我猜是因为solr.StandardFilterFactory从首字母缩略词中删除了点?),但“TheNotoriousB.I.G”(即减去结尾的点)没有。理想情况下,这些名称的所有合理变体都应该有效。我
我是Ruby的新手。我安装了DataMapper并且正在尝试安装dm-mysql-adapter-1.0.2gem。但是当我尝试安装时,出现以下错误。我正在使用ubuntu操作系统。vinoth@vinoth-laptop:~/Downloads$geminstalldm-mysql-adapter-1.0.2----with-mysql-lib=/usr/lib/mysql----with-mysql-conf=/usr/bin/mysqlWARNING:Installingto~/.gemsince/home/vinoth/gemsand/home/vinoth/gems/bina
我有这个验证规则的注册表单:validates:email,:presence=>{:message=>'cannotbeblank.'},:allow_blank=>true,:format=>{:with=>/\A[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]+\z/,:message=>'addressisnotvalid.Please,fixit.'},:uniqueness=>true此规则检查,如果用户填写注册表单电子邮件地址(+其正确格式)。现在我正尝试添加使用Twitter登录的机会。Twitter不提供用户的电子邮件地址。在这种情