全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程.
那么实现全文搜索的主要2个方向
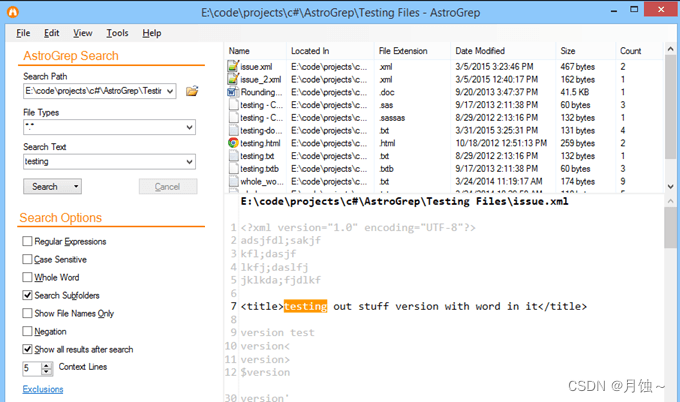
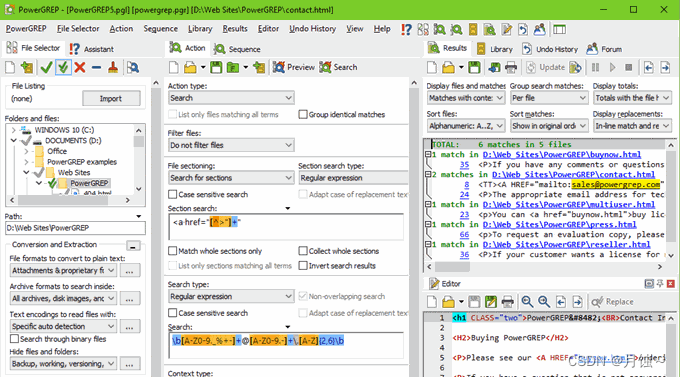
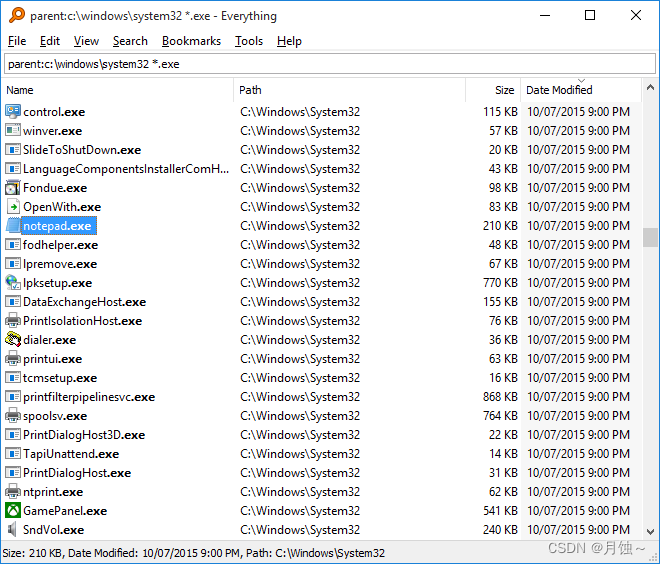
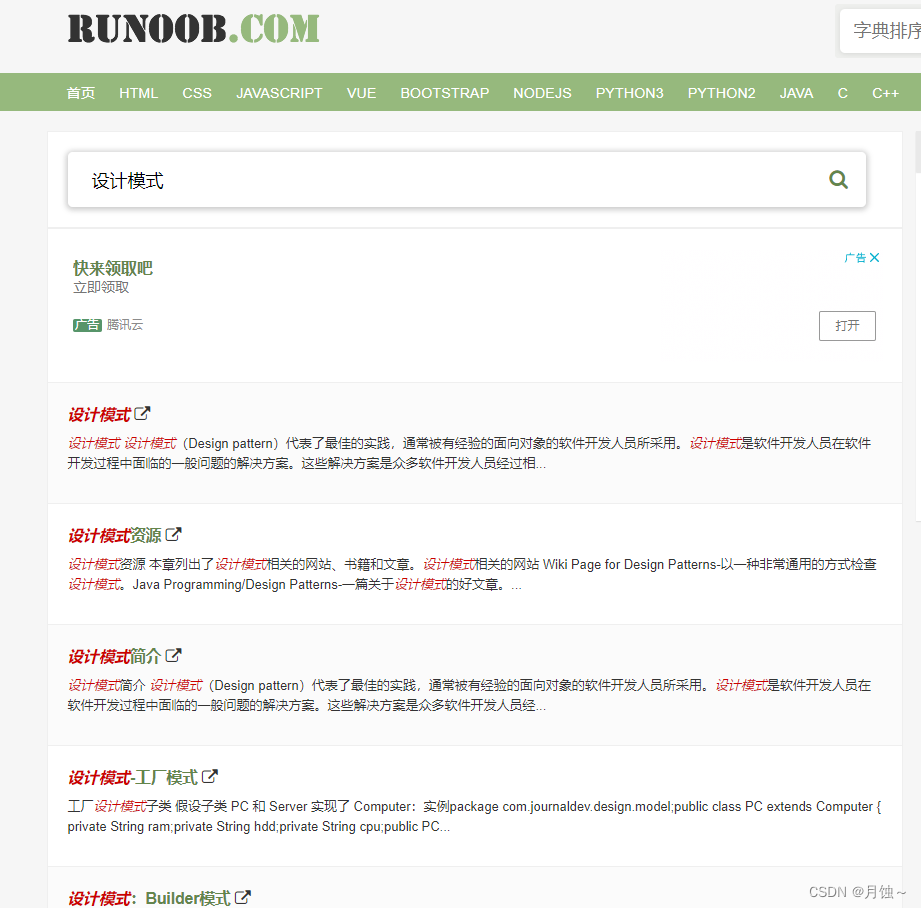
内容摘自:https://www.cnblogs.com/hanease/p/15900190.html
毫无疑问,Lucene是目前最受欢迎的Java全文搜索框架,准确地说,它是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene为开发人员提供了相当完整的工具包,可以非常方便地实现强大的全文检索功能。下面有几款搜索引擎框架也是基于Lucene实现的。
官方网站:http://lucene.apache.org/
Nutch 是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
利用Nutch,你可以做到以下这些功能:
每个月取几十亿网页
为这些网页维护一个索引
对索引文件进行每秒上千次的搜索
提供高质量的搜索结果
以最小的成本运作
官方网站:http://nutch.apache.org/
ElasticSearch就是一款基于Lucene框架的分布式搜索引擎,并且也是一款为数不多的基于JSON进行索引的搜索引擎。ElasticSearch特别适合在云计算平台上使用。
官方网站:http://www.elasticsearch.org/
Solandra 是一个实时的分布式搜索引擎,基于 Apache Solr 和 Apache Cassandra 构建。
其特性如下:
支持Solr的大多数默认特性 (search, faceting, highlights)
数据复制,分片,缓存及压缩这些都由Cassandra来进行
Multi-master (任意结点都可供读写)
实时性高,写操作完成即可读到
Easily add new SolrCores w/o restart across the cluster 轻松添加及重启结点
官方网站:https://github.com/tjake/Solandra
IndexTank是一套基于Java的索引-实时全文搜索引擎实现,IndexTank有以下几个特点:
索引更新实时生效
地理位置搜索
支持多种客户端语言
Ruby, Rails, Python, Java, PHP, .NET & more!
支持灵活的排序与评分控制
支持自动完成
支持面搜索(facet search)
支持匹配高亮
支持海量数据扩展(Scalable from a personal blog to hundreds of millions of documents! )
支持动态数据
官方网站:https://github.com/linkedin/indextank-engine
Compass是一个强大的,事务的,高性能的对象/搜索引擎映射(OSEM:object/search engine mapping)与一个Java持久层框架.Compass包括:
搜索引擎抽象层(使用Lucene搜索引荐)
OSEM (Object/Search Engine Mapping) 支持
事务管理
类似于Google的简单关键字查询语言
可扩展与模块化的框架
简单的API
官方网站:http://www.compass-project.org/
Solr也是基于Java实现的,并且是基于Lucene实现的,Solr的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果。值得注意的是,Solr还提供一款很棒的Web界面来管理索引的数据。
官方网站:http://lucene.apache.org/solr/
LIRE是一款基于Java的图片搜索框架,其核心也是基于Lucene的,利用该索引就能够构建一个基于内容的图像检索(content- based image retrieval,CBIR)系统,来搜索相似的图像。
官方网站:http://www.semanticmetadata.NET/lire/
Egothor是一个用Java编写的开源而高效的全文本搜索引擎。借助Java的跨平台特性,Egothor能应用于任何环境的应用,既可配置为单独的搜索引擎,又能用于你的应用作为全文检索之用。
JAVA开发中常用的Eclipse (CTRL+SHIFT+R) 和IDEA(SHIFT+SHIFT) 进行文件搜索时,同样也可以算做一个全文搜索. 如果你也有一个全文搜索的功能需求, 那么怎么实现呢?
在特定的文件存储目录中 ,建立关于文件的索引信息
遍历该文件夹的所有文件, 创建文件的索引信息 , 可以使用 Files.walkFileTree
文件的删除, 重命名,目录变更需要更改索引信息
监听该文件夹,对于文件发生的变更即时更新索引信息 , 可以使用 apache commons-io包的 FileAlterationObserver
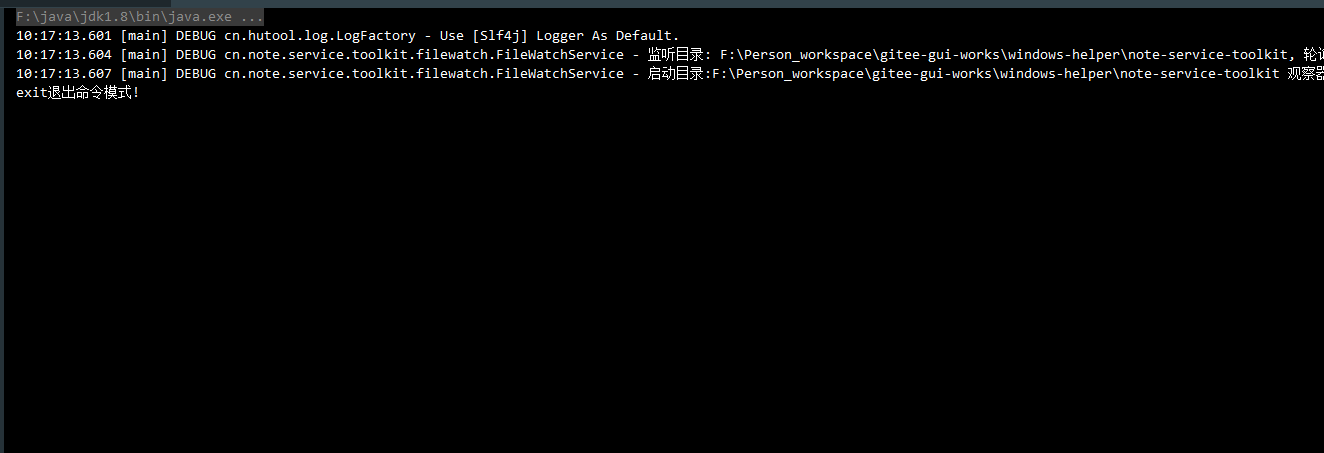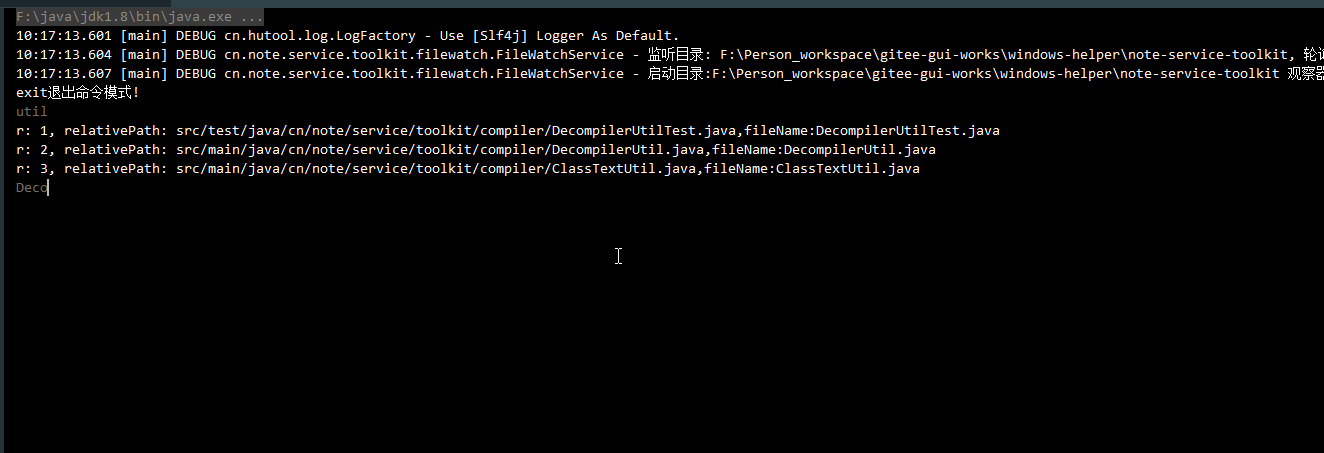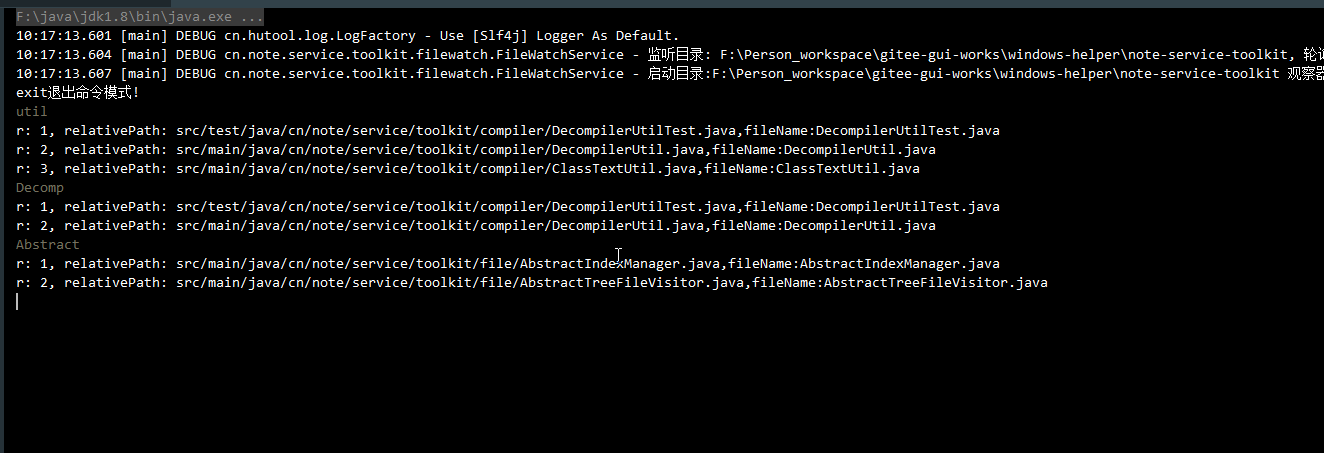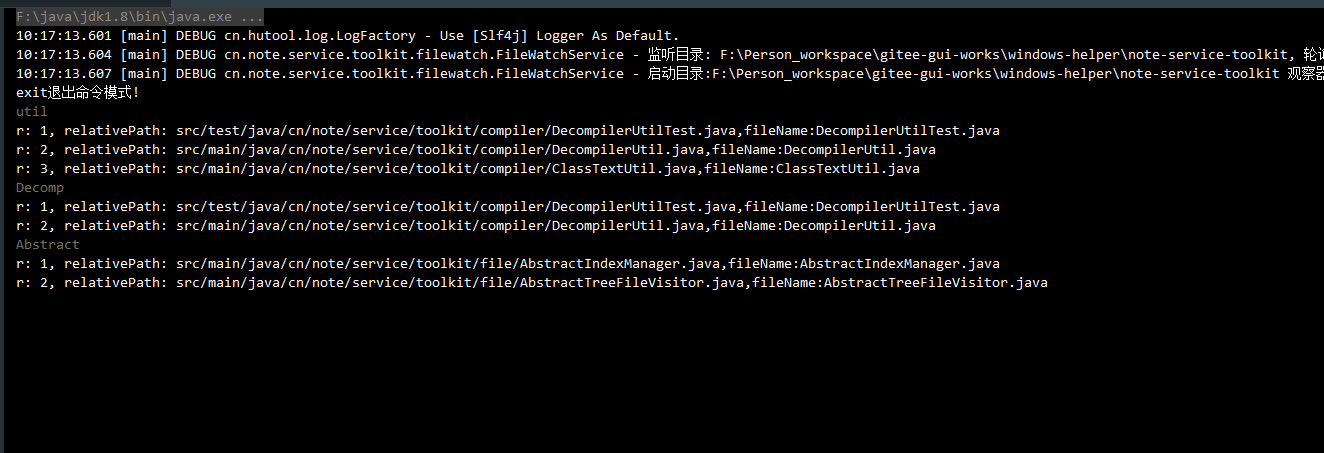
FileWatchService
import cn.hutool.log.StaticLog;
import org.apache.commons.io.filefilter.FileFilterUtils;
import org.apache.commons.io.filefilter.IOFileFilter;
import org.apache.commons.io.monitor.FileAlterationListener;
import org.apache.commons.io.monitor.FileAlterationMonitor;
import org.apache.commons.io.monitor.FileAlterationObserver;
import javax.annotation.Nonnull;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author jee
* @description: 文件观察服务
* <p>
* + 定义轮询时间 和文件过滤器
* + 指定监听目录
* + 自定义文件监听动作
* <pre>
* // 自定义文件监听事件
* FileWatchAdapter fileWatchAdapter = new FileWatchAdapter(true);
* List<FileAlterationListener> listeners = CollUtil.newArrayList(fileWatchAdapter);
*
* // 创建文件监听
* FileWatchService monitorFile = new FileWatchService.WatchBuilder().dirPath(dirPath)
* .listeners(listeners).build();
*
* monitorFile.start();
*
* // 自定义频率和过滤器
* * FileWatchService monitorFile = new FileWatchService.WatchBuilder(3,FileFilterUtils.suffixFileFilter(".txt")).dirPath(dirPath)
* * .listeners(listeners).build();
*
*
* </pre>
* <p>
* 指定文件过滤监听示例
* <pre>
*
* // txt过滤器
* IOFileFilter filefilter = FileFilterUtils.suffixFileFilter(".txt");
* // 子目录的txt后缀
* IOFileFilter subFilefilter = FileFilterUtils.or(FileFilterUtils.directoryFileFilter(), filefilter);
* //根目录和子目录变化
* IOFileFilter filter = FileFilterUtils.or(filefilter, subFilefilter);
*
* // 创建文件监听
* FileWatchService monitorFile = new FileWatchService.WatchBuilder(5, filter).dirPath(dirPath)
* .listeners(listeners).build();
* monitorFile.start();
*
* </pre>
*/
public class FileWatchService {
/*监听目录*/
private final File fileDir;
/*循环周期*/
private long cycleTime;
/*监听操作*/
private final List<FileAlterationListener> listeners;
/*文件过滤器*/
private final IOFileFilter fileFilter;
/*监听器*/
private final FileAlterationMonitor monitor;
/*监听适配器*/
private final FileAlterationObserver observer;
public FileWatchService(WatchBuilder builder) {
this.fileDir = builder.fileDir;
this.cycleTime = builder.cycleTime;
StaticLog.debug("监听目录: {}, 轮询时间: {}ms", fileDir, cycleTime);
this.listeners = builder.listeners;
this.fileFilter = builder.fileFilter;
observer = new FileAlterationObserver(fileDir, fileFilter);
listeners.forEach(observer::addListener);
monitor = new FileAlterationMonitor(cycleTime, observer);
}
/**
* 启动目录观察器
*
* @throws Exception 实例化observer失败异常
*/
public void start() throws Exception {
StaticLog.debug("启动目录:{} 观察器", fileDir);
monitor.start();
}
/**
* 停止监控
*/
public void destroy() {
try {
if (monitor != null) {
monitor.stop();
StaticLog.debug("停止目录:{} 观察器", fileDir);
}
} catch (Exception e) {
StaticLog.error(e, "文件停止监控失败");
}
}
/**
* @author jee
* @description: builder模式
*/
public static class WatchBuilder {
/*轮询时间*/
private final long cycleTime;
/*文件拦截器*/
private final IOFileFilter fileFilter;
/*文件目录*/
private File fileDir;
/*自定义文件监听器*/
private List<FileAlterationListener> listeners;
/**
* 默认3s轮询一次 ,监听整个目录
*/
public WatchBuilder() {
this(3);
}
/**
* 自定义轮询时间
*
* @param cycleTime 轮询时间
*/
public WatchBuilder(long cycleTime) {
this(cycleTime, FileFilterUtils.trueFileFilter());
}
/**
* 自定义轮询时间和文件过滤器
*
* @param cycleTime 默认轮询时间,单位秒
* @param fileFilter 轮询文件过滤器
*/
public WatchBuilder(long cycleTime, IOFileFilter fileFilter) {
this.cycleTime = TimeUnit.SECONDS.toMillis(cycleTime);
this.fileFilter = fileFilter;
this.listeners = new ArrayList<>();
}
/**
* 设置监听文件目录
*
* @param dirPath 目录绝对路径
* @return WatchBuilder
* @throws IOException 非目录或目录不存在异常!
*/
public WatchBuilder dirPath(String dirPath) throws IOException {
this.fileDir = new File(dirPath);
if (!fileDir.exists()) {
throw new FileNotFoundException("not found: " + fileDir.getAbsolutePath());
}
if (!fileDir.isDirectory()) {
throw new IOException("not a directory: " + fileDir.getAbsolutePath());
}
return this;
}
/**
* 设置监听器
*
* @param listeners 文件监听器集合
* @return WatchBuilder
*/
public WatchBuilder listeners(@Nonnull List<FileAlterationListener> listeners) {
this.listeners.addAll(listeners);
return this;
}
public FileWatchService build() {
return new FileWatchService(this);
}
}
}
应该如何搜索索引?
public abstract List searchIndex(String indexContext);
基本的文件对象, 建立索引时,需要存储哪些东西?
public abstract T fileToIndexObject(File file);
索引信息,怎么反向转换为文件
public abstract File indexToFileObject(T index);
import cn.hutool.core.collection.CollUtil;
import cn.note.service.toolkit.filestore.FileStore;
import cn.note.service.toolkit.filestore.RelativeFileStore;
import cn.note.service.toolkit.filewatch.FileWatchService;
import lombok.Getter;
import lombok.Setter;
import org.apache.commons.io.filefilter.FileFilterUtils;
import org.apache.commons.io.filefilter.IOFileFilter;
import org.apache.commons.io.monitor.FileAlterationListener;
import org.apache.commons.io.monitor.FileAlterationListenerAdaptor;
import java.io.File;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* 文件索引管理器
* 可以用来管理文件基本信息的索引
*
* @param <T> 某种文件性质类型的存储管理器
* @see FileIndexManager
*/
@Getter
@Setter
public abstract class AbstractIndexManager<T> {
/*文件存储对象*/
private FileStore fileStore;
/*文件索引*/
private Map<String, T> indexes;
/*是否初始化完成*/
private boolean initCompleted;
public AbstractIndexManager(String homeDir) {
this(new RelativeFileStore(homeDir));
}
public AbstractIndexManager(FileStore fileStore) {
this.fileStore = fileStore;
this.indexes = new ConcurrentHashMap<>();
}
/**
* 移除文件
*
* @param file 文件
*/
protected void deleteIndex(File file) {
indexes.remove(file.getAbsolutePath());
}
/**
* 添加文件
*
* @param file 文件
*/
protected void addIndex(File file) {
String filePath = file.getAbsolutePath();
indexes.put(filePath, fileToIndexObject(file));
}
/**
* 递归遍历文件和子目录生成索引文件 ,默认所有文件和目录
*/
public void initialize() throws Exception {
initialize(FileFilterUtils.trueFileFilter(), null);
}
/**
* 指定文件过滤器,递归遍历文件和子目录生成索引文件
*
* @param fileFilter 指定文件过滤器
*/
public void initialize(IOFileFilter fileFilter) throws Exception {
initialize(fileFilter, null);
}
/**
* 遍历文件至目录
*
* @param fileFilter 文件过滤器
* @param ignoreDirs 忽略目录
* @throws Exception 遍历文件时发生IO异常, 创建监听器时发生异常
*/
public void initialize(IOFileFilter fileFilter, List<String> ignoreDirs) throws Exception {
AbstractTreeFileVisitor fileVisitor = new AbstractTreeFileVisitor() {
@Override
public void addNode(Path path, boolean isDir) {
File file = path.toFile();
// if (!file.equals(fileStore.homeDir())) {
if (!isDir) {
addIndex(file);
}
}
};
fileVisitor.setFileFilter(fileFilter);
if (ignoreDirs != null) {
fileVisitor.setIgnoreDirs(ignoreDirs);
}
Files.walkFileTree(fileStore.homeDir().toPath(), fileVisitor);
createFileWatch(fileFilter);
}
/**
* 创建文件监听
*/
protected void createFileWatch(IOFileFilter fileFilter) throws Exception {
// 定义拦截动作
FileAlterationListenerAdaptor fileAlterationListenerAdaptor = new FileAlterationListenerAdaptor() {
@Override
public void onFileCreate(final File file) {
addIndex(file);
}
@Override
public void onFileDelete(final File file) {
deleteIndex(file);
}
};
List<FileAlterationListener> listeners = CollUtil.newArrayList(fileAlterationListenerAdaptor);
// 文件过滤器
IOFileFilter subFileFilter = FileFilterUtils.or(FileFilterUtils.directoryFileFilter(), fileFilter);
//根目录和子目录变化
IOFileFilter filter = FileFilterUtils.or(fileFilter, subFileFilter);
// 创建文件监听
FileWatchService monitorFile = new FileWatchService.WatchBuilder(3, filter).dirPath(fileStore.homeDir().getAbsolutePath())
.listeners(listeners).build();
monitorFile.start();
this.initCompleted = true;
}
/**
* @param indexContext 索引内容
* @return 索引集合
*/
public abstract List<T> searchIndex(String indexContext);
/**
* 将文件转文件索引信息
*
* @param file 文件
* @return 文件索引信息
*/
public abstract T fileToIndexObject(File file);
/**
* 索引对象反向转文件对象
*
* @param index 索引对象
* @return 文件对象
*/
public abstract File indexToFileObject(T index);
}
/**
* 文件基本信息类
*/
@Setter
@Getter
public class FileIndex {
/* 文件名称*/
private String fileName;
/* 文件路径*/
private String relativePath;
/* 修改时间 */
private String modifiedDate;
/*是否目录*/
private boolean dir;
/**
* 对fileName 进行忽略大小写
*/
private String searchName;
@Override
public String toString() {
String fmt = StrUtil.format("{}( {})", fileName, relativePath);
return fmt;
}
}
import cn.hutool.core.util.StrUtil;
import cn.note.service.toolkit.filestore.FileStore;
import java.io.File;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
/**
* @description: 目录索引管理器
* @author: jee
*/
public class FileIndexManager extends AbstractIndexManager<FileIndex> {
public FileIndexManager(String homeDir) {
super(homeDir);
}
public FileIndexManager(FileStore fileStore) {
super(fileStore);
}
@Override
public List<FileIndex> searchIndex(String indexContext) {
if (!isInitCompleted()) {
throw new IllegalStateException("调用是否isInitCompleted 检查初始化是否完成!!!");
}
if (StrUtil.isBlank(indexContext)) {
return Collections.emptyList();
}
final String matchName = indexContext.toLowerCase();
return getIndexes().values().stream().filter(index -> !index.isDir() && index.getSearchName().contains(matchName)).collect(Collectors.toList());
}
@Override
protected FileIndex fileToIndexObject(File file) {
String fileName = file.getName();
String relativePath = getFileStore().getRelativePath(file);
String modifiedDate = getFileStore().getModifiedDate(file);
FileIndex fileIndex = new FileIndex();
fileIndex.setFileName(fileName);
fileIndex.setRelativePath(relativePath);
fileIndex.setModifiedDate(modifiedDate);
fileIndex.setDir(file.isDirectory());
fileIndex.setSearchName(fileName.toLowerCase());
return fileIndex;
}
@Override
public File indexToFileObject(FileIndex index) {
return getFileStore().getFile(index.getRelativePath());
}
}
/**
* 目录文件扫描测试
*/
public class FileIndexManagerTest {
public static void main(String[] args) throws Exception {
String home = SystemUtil.getUserInfo().getCurrentDir() + "/note-service-toolkit";
FileIndexManager fileIndexManager = new FileIndexManager(home);
fileIndexManager.initialize(FileFilterUtils.suffixFileFilter(".java"), CollUtil.newArrayList("target"));
CmdWindow.show((cmd) -> {
List<FileIndex> noteFileIndices = fileIndexManager.searchIndex(cmd);
if (noteFileIndices.size() == 0) {
Console.log("未匹配到结果!");
}
int i = 1;
for (FileIndex fileIndex : noteFileIndices) {
Console.log("r: {}, relativePath: {},fileName:{}", i, fileIndex.getRelativePath(), fileIndex.getFileName());
i++;
}
});
}
}
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解