python读写excel的方式有很多,不同的模块在读写的方法上稍有区别:
用xlrd和xlwt进行excel读写;
用openpyxl进行excel读写;
用pandas进行excel读写;、
这是一个第三方库,可以处理xlsx格式的Excel文件。pip install openpyxl安装。如果使用Aanconda,应该自带了。
假设操作的表如下:放在D盘的test.xlsx文件
| 姓名 | 性别 |
| 张三 | 男 |
| 李四 | 女 |
读取Excel文件
需要导入相关函数。
#coding=gbk
from openpyxl import load_workbook
wb = load_workbook('D:/test.xlsx')
获取工作表--Sheet
# 获得所有sheet的名称
print(wb.get_sheet_names())
# 根据sheet名字获得sheet
a_sheet = wb.get_sheet_by_name('Sheet1')
# 获得sheet名
print(a_sheet.title)
# 获得当前正在显示的sheet, 也可以用wb.get_active_sheet()
sheet = wb.active
获取单元格
# 获取某个单元格的值,观察excel发现也是先字母再数字的顺序,即先列再行
b3 = worksheet['B3'] print('B3是----',b3) # 返回的数字就是int型 print(f'({b3.column}, {b3.row}) is {b3.value}') # 返回的数字就是int型结果为:
B3是---- <Cell 'Sheet1'.B3>
(2, 3) is 女
cell_2_2=worksheet.cell(row=2,column=2) cell_2_2_value=worksheet.cell(row=2,column=2).value print('第2行第2列',cell_2_2) print('第2行第2列值',cell_2_2_value)返回结果:
第2行第2列 <Cell 'Sheet1'.B2>
第2行第2列值 男
获得最大行和最大列
# 获得最大列和最大行
print('最大行数---', worksheet.max_row) print('最大列数---', worksheet.max_column)返回结果:
最大行数--- 3
最大列数--- 2
获取行和列
row3=[item.value for item in list(worksheet.rows)[2]] print('第3行值',row3) col2=[item.value for item in list(worksheet.columns)[1]] print('第2列值',col2)结果是:
第3行值 ['李四', '女']
第2列值 ['性别', '男', '女']
获取列表说有数据:
# print('通过worksheet.cell获取所有数据方法一:') # for i in range(1, 4): # for j in range(1, 3): # print(worksheet.cell(row=i, column=j)) print('通过worksheet.cell获取所有数据方法二:') for row_cell in worksheet['A1':'B3']: for cell in row_cell: print(cell)通过worksheet.cell获取所有数据方法二:
<Cell 'Sheet1'.A1>
<Cell 'Sheet1'.B1>
<Cell 'Sheet1'.A2>
<Cell 'Sheet1'.B2>
<Cell 'Sheet1'.A3>
<Cell 'Sheet1'.B3>
将数据写入Excel
需要导入WorkBook
from openpyxl import Workbook
wb = Workbook()
这样就新建了一个新的工作表(只是还没被保存)。
若要指定只写模式,可以指定参数write_only=True。一般默认的可写可读模式就可以了。
print(wb.get_sheet_names()) # 提供一个默认名叫Sheet的表,office2016下新建提供默认Sheet1
# 直接赋值就可以改工作表的名称
sheet.title = 'Sheet1'
# 新建一个工作表,可以指定索引,适当安排其在工作簿中的位置
wb.create_sheet('Data', index=1) # 被安排到第二个工作表,index=0就是第一个位置
# 删除某个工作表
wb.remove(sheet)
del wb[sheet]
写入单元格
还可以使用公式哦
# 直接给单元格赋值就行
sheet['A1'] = 'good'
# B9处写入平均值
sheet['B9'] = '=AVERAGE(B2:B8)'
wb.save(r'D:\example.xlsx')
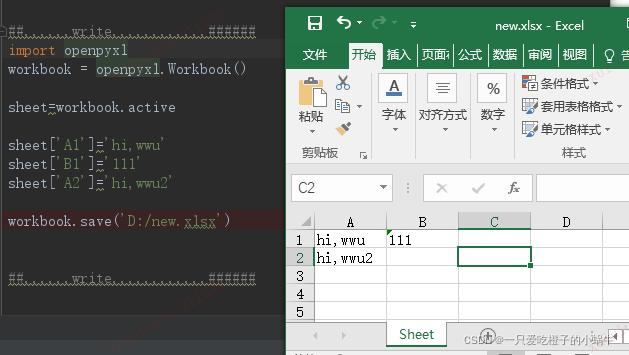
wb.save(r'D:\example.xlsx')
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A