互联网是如何工作的呢?如何制作属于您自己的网站?
什么是网站主机? 什么是 Internet 服务提供商(ISP)?什么是 DNS?

如果你想学习更多关于HTML的知识请访问我们的 HTML 教程.
域名系统(英语:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
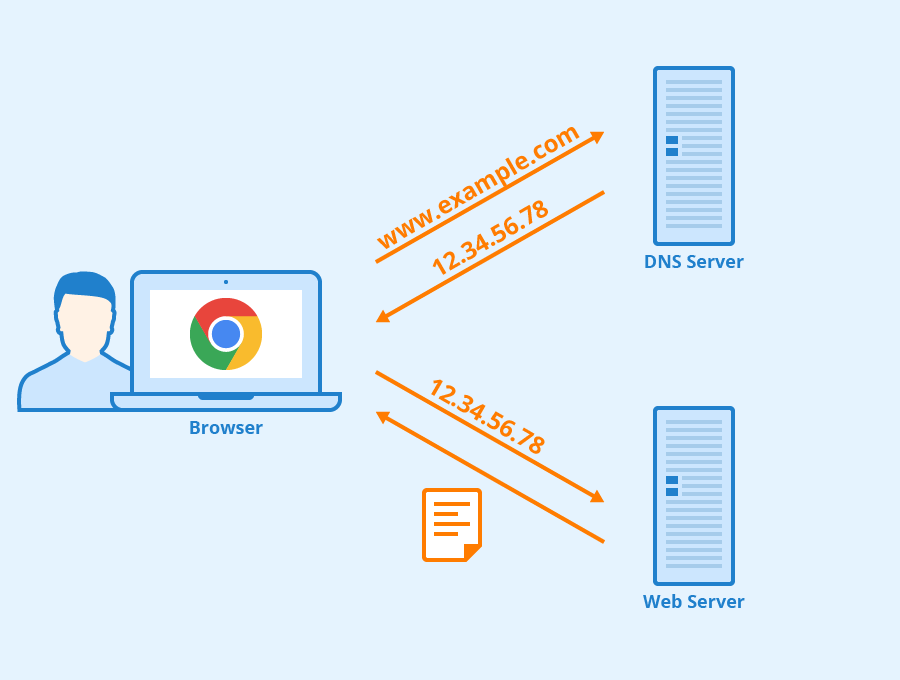
如果您希望其它人看到您的网站,就必须把网站拷贝到一个公共的服务器。即使您可以使用自己的 PC 来做 web 服务器,最常见的做法还是通过 ISP 来存放网站。
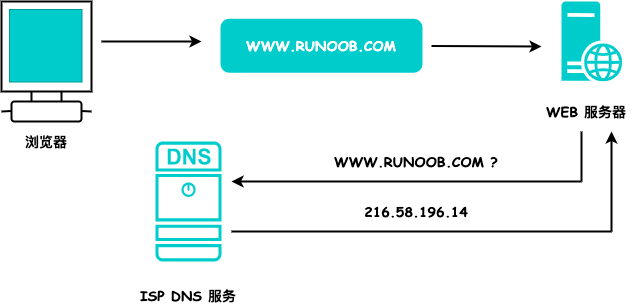
包含在 web 主机解决方案中的还有域名注册和标准的电子邮件服务。
您可以在接下来的章节阅读到更多有关域名注册、电子邮件和其他服务的内容。
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
在Ruby中可以使用哪些替代方法来ping一个ip地址?标准库“ping”库的功能似乎非常有限。我对在这里滚动我自己的代码不感兴趣。有没有好的gem?我应该接受它并忍受它吗?(我在Linux上使用Ruby1.8.6编写代码) 最佳答案 net-ping值得一看。它允许TCPping(如标准rubyping),但也允许UDP、HTTP和ICMPping。ICMPping需要root权限,但其他则不需要。 关于ruby-Pingruby网站?,我们在StackOverflow上找到一个类
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我正在使用DMOZ的listofurltopics,其中包含一些具有包含下划线的主机名的url。例如:608609TheOuterHeaven610InformationandimagegalleryofMcFarlane'sactionfiguresforTrigun,Akira,TenchiMuyoandotherJapaneseSci-Fianimations.611Top/Arts/Animation/Anime/Collectibles/Models_and_Figures/Action_Figures612虽然此url可以在网络浏览器中使用(或者至少在我的浏览器中可以使用:
我刚刚在我的Ubuntu9.10服务器上安装了TeamBox。我使用提供的服务器脚本在端口3000上启动并运行它。它的运行速度非常慢,从另一台计算机连接时每个HTTP请求最多需要30秒。我使用链接从shell加载TeamBox,一点也不花时间。然后我设置了一个SSH隧道,它再次运行得非常快。我通过此服务器上的apache以及SAMBA等运行了大约30个虚拟主机,没有任何问题。我该如何解决这个问题? 最佳答案 我的redmine(ruby,webrick)太慢了。现在我解决了这个问题:apt-getinstallmongrelruby
我需要从站点抓取数据,但它需要我先登录。我一直在使用hpricot成功地抓取其他网站,但我是使用mechanize的新手,我真的对如何使用它感到困惑。我看到这个例子经常被引用:require'rubygems'require'mechanize'a=Mechanize.newa.get('http://rubyforge.org/')do|page|#Clicktheloginlinklogin_page=a.click(page.link_with(:text=>/LogIn/))#Submittheloginformmy_page=login_page.form_with(:act
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
如何使用rubyonrails获取网络上某处其他网站的页面数据? 最佳答案 您可以使用httparty只是获取数据示例代码(来自example):requireFile.join(dir,'httparty')require'pp'classGoogleincludeHTTPartyformat:htmlend#google.comredirectstowww.google.comsothisislivetestforredirectionppGoogle.get('http://google.com')puts'','*'*7