MobileOne论文:https://arxiv.org/abs/2206.04040
MobileOne github:https://github.com/apple/ml-mobileone
使用Reparameterize重参数化实现模型的轻量化,基本模块如下图所示。
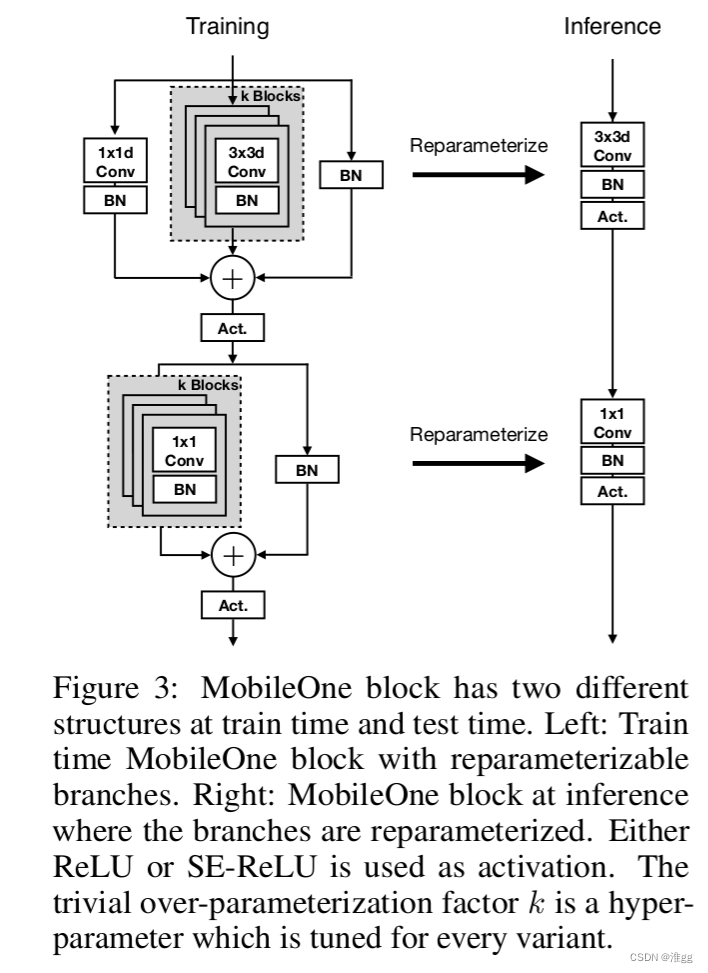
说明: 该部分的改进代码尽可能地根据官方代码的写法与YOLOv7项目进行整合;
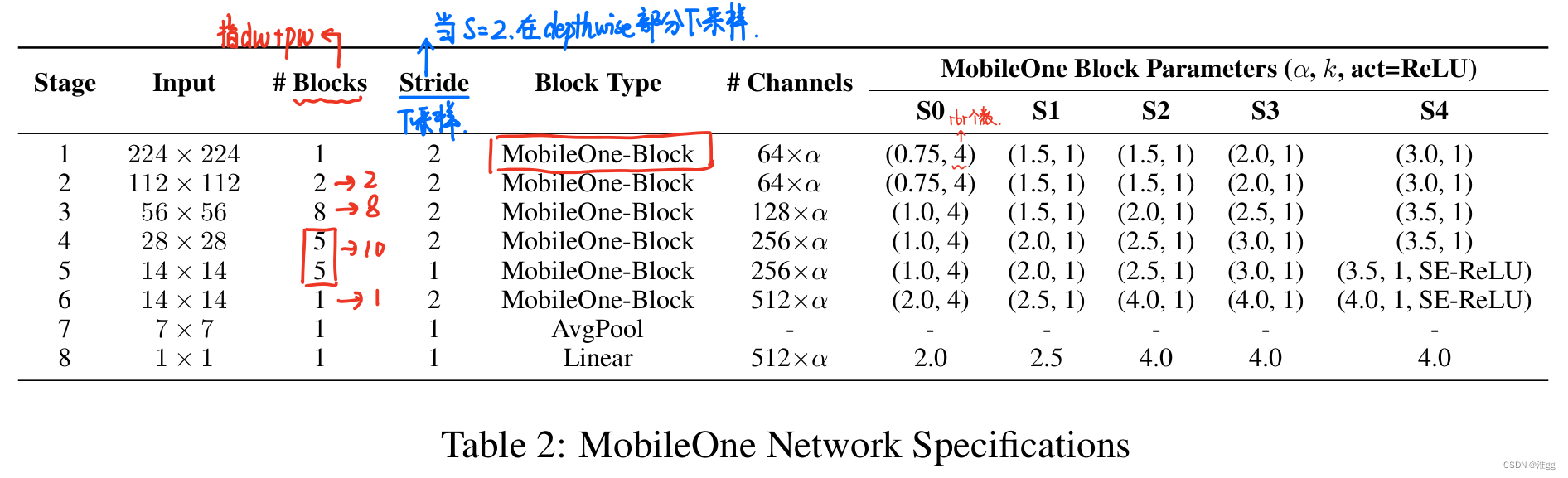
通过阅读MobileOne源码和结合论文中Table2可以发现以下两点:
(1)Table2中Block Type全写为MobileOne Block,但在源码中的Stage1和后面的Block是稍有不同的,因此在3.2改进YOLOv7时中使用MobileOne Block和MobileOne进行区分;
(2)源码将Stage4和Stage5写在了一起,因此在换Backbone时我们也写在一起,因此在yaml中会看到Stage1后面Blocks个数为【2,8,10,1】
步骤一:构建MobileOneBlock、MobileOne、SEBlock、reparameterize模块
在项目文件中的models/common.py中加入以下代码
#====MobileOne====#
import copy as copy2 # 为防止与common原来引入的copy冲突, for mobileone reparameterize
from typing import Optional, List, Tuple
class SEBlock(nn.Module):
""" Squeeze and Excite module.
https://arxiv.org/pdf/1709.01507.pdf
"""
def __init__(self, in_channels: int, rd_ratio: float = 0.0625) -> None:
""" Construct a Squeeze and Excite Module.
:param in_channels: Number of input channels.
:param rd_ratio: Input channel reduction ratio.
"""
super(SEBlock, self).__init__()
self.reduce = nn.Conv2d(in_channels=in_channels,out_channels=int(in_channels * rd_ratio), kernel_size=1, stride=1, bias=True)
self.expand = nn.Conv2d(in_channels=int(in_channels * rd_ratio),out_channels=in_channels, kernel_size=1, stride=1, bias=True)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
""" Apply forward pass. """
b, c, h, w = inputs.size()
x = F.avg_pool2d(inputs, kernel_size=[h, w])
x = self.reduce(x)
x = F.relu(x)
x = self.expand(x)
x = torch.sigmoid(x)
x = x.view(-1, c, 1, 1)
return inputs * x
class MobileOneBlock(nn.Module):
""" MobileOne building block. https://arxiv.org/pdf/2206.04040.pdf
"""
def __init__(self, in_channels: int, out_channels: int, kernel_size: int, stride: int = 1,
padding: int = 0, dilation: int = 1, groups: int = 1, use_se: bool = False, num_conv_branches: int = 1, inference_mode: bool = False) -> None:
""" Construct a MobileOneBlock module.
:param in_channels: Number of channels in the input.
:param out_channels: Number of channels produced by the block.
:param kernel_size: Size of the convolution kernel.
:param stride: Stride size.
:param padding: Zero-padding size.
:param dilation: Kernel dilation factor.
:param groups: Group number.
:param inference_mode: If True, instantiates model in inference mode.
:param use_se: Whether to use SE-ReLU activations.
:param num_conv_branches: Number of linear conv branches.
"""
super(MobileOneBlock, self).__init__()
self.inference_mode = inference_mode
self.groups = groups
self.stride = stride
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.num_conv_branches = num_conv_branches # 4
# Check if SE-ReLU is requested
if use_se:
self.se = SEBlock(out_channels)
else:
self.se = nn.Identity()
self.activation = nn.ReLU()
if inference_mode:
self.reparam_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups, bias=True)
else:
# Re-parameterizable skip connection
self.rbr_skip = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else None # BN skip
# Re-parameterizable conv branches
rbr_conv = list()
for _ in range(self.num_conv_branches):
rbr_conv.append(self._conv_bn(kernel_size=kernel_size, padding=padding))
self.rbr_conv = nn.ModuleList(rbr_conv)
# Re-parameterizable scale branch
self.rbr_scale = None
if kernel_size > 1:
self.rbr_scale = self._conv_bn(kernel_size=1, padding=0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Apply forward pass. """
# Inference mode forward pass.
if self.inference_mode:
return self.activation(self.se(self.reparam_conv(x)))
# Multi-branched train-time forward pass.
# Skip branch output
identity_out = 0
if self.rbr_skip is not None:
identity_out = self.rbr_skip(x)
# Scale branch output
scale_out = 0
if self.rbr_scale is not None:
scale_out = self.rbr_scale(x)
# Other branches
out = scale_out + identity_out
for ix in range(self.num_conv_branches):
out += self.rbr_conv[ix](x)
return self.activation(self.se(out))
def reparameterize(self):
""" Following works like `RepVGG: Making VGG-style ConvNets Great Again` -
https://arxiv.org/pdf/2101.03697.pdf. We re-parameterize multi-branched
architecture used at training time to obtain a plain CNN-like structure
for inference.
"""
if self.inference_mode:
return
kernel, bias = self._get_kernel_bias()
self.reparam_conv = nn.Conv2d(in_channels=self.rbr_conv[0].conv.in_channels,
out_channels=self.rbr_conv[0].conv.out_channels,
kernel_size=self.rbr_conv[0].conv.kernel_size,
stride=self.rbr_conv[0].conv.stride,
padding=self.rbr_conv[0].conv.padding,
dilation=self.rbr_conv[0].conv.dilation,
groups=self.rbr_conv[0].conv.groups,
bias=True)
self.reparam_conv.weight.data = kernel
self.reparam_conv.bias.data = bias
# Delete un-used branches
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_conv')
self.__delattr__('rbr_scale')
if hasattr(self, 'rbr_skip'):
self.__delattr__('rbr_skip')
self.inference_mode = True
def _get_kernel_bias(self) -> Tuple[torch.Tensor, torch.Tensor]:
""" Method to obtain re-parameterized kernel and bias.
Reference: https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py#L83
:return: Tuple of (kernel, bias) after fusing branches.
"""
# get weights and bias of scale branch
kernel_scale = 0
bias_scale = 0
if self.rbr_scale is not None:
kernel_scale, bias_scale = self._fuse_bn_tensor(self.rbr_scale)
# Pad scale branch kernel to match conv branch kernel size.
pad = self.kernel_size // 2
kernel_scale = torch.nn.functional.pad(kernel_scale, [pad, pad, pad, pad])
# get weights and bias of skip branch
kernel_identity = 0
bias_identity = 0
if self.rbr_skip is not None:
kernel_identity, bias_identity = self._fuse_bn_tensor(self.rbr_skip)
# get weights and bias of conv branches
kernel_conv = 0
bias_conv = 0
for ix in range(self.num_conv_branches):
_kernel, _bias = self._fuse_bn_tensor(self.rbr_conv[ix])
kernel_conv += _kernel
bias_conv += _bias
kernel_final = kernel_conv + kernel_scale + kernel_identity
bias_final = bias_conv + bias_scale + bias_identity
return kernel_final, bias_final
def _fuse_bn_tensor(self, branch) -> Tuple[torch.Tensor, torch.Tensor]:
""" Method to fuse batchnorm layer with preceeding conv layer.
Reference: https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py#L95
:param branch:
:return: Tuple of (kernel, bias) after fusing batchnorm.
"""
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = torch.zeros((self.in_channels, input_dim, self.kernel_size, self.kernel_size),
dtype=branch.weight.dtype, device=branch.weight.device)
for i in range(self.in_channels):
kernel_value[i, i % input_dim,self.kernel_size // 2, self.kernel_size // 2] = 1
self.id_tensor = kernel_value
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def _conv_bn(self, kernel_size: int, padding: int) -> nn.Sequential:
""" Helper method to construct conv-batchnorm layers.
:param kernel_size: Size of the convolution kernel.
:param padding: Zero-padding size.
:return: Conv-BN module.
"""
mod_list = nn.Sequential()
mod_list.add_module('conv', nn.Conv2d(in_channels=self.in_channels,out_channels=self.out_channels,
kernel_size=kernel_size, stride=self.stride, padding=padding, groups=self.groups, bias=False))
mod_list.add_module('bn', nn.BatchNorm2d(num_features=self.out_channels))
return mod_list
class MobileOne(nn.Module):
""" MobileOne Model https://arxiv.org/pdf/2206.04040.pdf """
def __init__(self,
in_channels, out_channels,
num_blocks_per_stage = 2, num_conv_branches: int = 1,
use_se: bool = False, num_se: int = 0,
inference_mode: bool = False, ) -> None:
""" Construct MobileOne model.
:param num_blocks_per_stage: List of number of blocks per stage.
:param num_classes: Number of classes in the dataset.
:param width_multipliers: List of width multiplier for blocks in a stage.
:param inference_mode: If True, instantiates model in inference mode.
:param use_se: Whether to use SE-ReLU activations.
:param num_conv_branches: Number of linear conv branches.
"""
super().__init__()
self.inference_mode = inference_mode
self.use_se = use_se
self.num_conv_branches = num_conv_branches
self.stage = self._make_stage(in_channels, out_channels, num_blocks_per_stage, num_se_blocks= num_se if use_se else 0)
# planes指输出通道
def _make_stage(self, in_channels, out_channels, num_blocks: int, num_se_blocks: int) -> nn.Sequential:
""" Build a stage of MobileOne model.
:param planes: Number of output channels.
:param num_blocks: Number of blocks in this stage.
:param num_se_blocks: Number of SE blocks in this stage.
:return: A stage of MobileOne model.
"""
# Get strides for all layers
strides = [2] + [1]*(num_blocks-1)
blocks = []
for ix, stride in enumerate(strides): # 用于训练几个blocks
use_se = False
if num_se_blocks > num_blocks:
raise ValueError("Number of SE blocks cannot " "exceed number of layers.")
if ix >= (num_blocks - num_se_blocks):
use_se = True
# Depthwise conv
blocks.append(MobileOneBlock(in_channels=in_channels, out_channels=in_channels,
kernel_size=3, stride=stride, padding=1, groups=in_channels,
inference_mode=self.inference_mode, use_se=use_se, num_conv_branches=self.num_conv_branches))
# Pointwise conv
blocks.append(MobileOneBlock(in_channels=in_channels, out_channels=out_channels,
kernel_size=1, stride=1, padding=0, groups=1,
inference_mode=self.inference_mode, use_se=use_se, num_conv_branches=self.num_conv_branches))
in_channels = out_channels
return nn.Sequential(*blocks)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Apply forward pass. """
x = self.stage(x)
return x
def reparameterize_model(model: torch.nn.Module) -> nn.Module:
""" Method returns a model where a multi-branched structure
used in training is re-parameterized into a single branch
for inference.
:param model: MobileOne model in train mode.
:return: MobileOne model in inference mode.
"""
# Avoid editing original graph
model = copy2.deepcopy(model)
for module in model.modules():
if hasattr(module, 'reparameterize'):
module.reparameterize()
return model
步骤二:在yolo.py的parse_model添加Mobileone的构建块
elif m in [MobileOneBlock, MobileOne]:
c1, c2 = ch[f], args[0]
args = [c1, c2, *args[1:]]
步骤三:创建新的模型文件
此处以更换yolov7-tiny的backbone为例,且修改为mobileone中的ms0模型,命名yolov7-tiny-ms0.yaml
# parameters
nc: 3 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[
[-1, 1, MobileOneBlock, [48, 3, 2, 1]], # 0
[-1, 1, MobileOne, [48, 2, 4, False, 0]], # MobileOne [out_channels, num_blocks, num_conv_branches, use_se, num_se, inference_mode]
[-1, 1, MobileOne, [128, 8, 4, False, 0]],
[-1, 1, MobileOne, [256, 10, 4, False, 0]],
[ -1, 1, MobileOne, [512, 1, 4, False, 0]], # 4
]
# yolov7-tiny head
head:
[[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, SP, [5]],
[-2, 1, SP, [9]],
[-3, 1, SP, [13]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -7], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 13
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[3, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 23
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2], 1, Concat, [1]], # 27
[-1, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [32, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [32, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 33
[-1, 1, Conv, [128, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 23], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [64, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [64, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 41
[-1, 1, Conv, [256, 3, 2, None, 1, nn.LeakyReLU(0.1)]],
[[-1, 13], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-2, 1, Conv, [128, 1, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[-1, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 49
[33, 1, Conv, [128, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[41, 1, Conv, [256, 3, 1, None, 1, nn.LeakyReLU(0.1)]],
[49, 1, Conv, [512, 3, 1, None, 1, nn.LeakyReLU(0.1)]], # 52
[[50,51,52], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
步骤五:推理部分reparameterize
在yolo.py文件中的Model类中的fuse方法,加入MobileOne和MobileOneBlock部分
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, RepConv):
#print(f" fuse_repvgg_block")
m.fuse_repvgg_block()
elif isinstance(m, RepConv_OREPA):
#print(f" switch_to_deploy")
m.switch_to_deploy()
#======该部分
elif isinstance(m, (MobileOne, MobileOneBlock)) and hasattr(m, 'reparameterize'):
m.reparameterize()
#=======
elif type(m) is Conv and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.fuseforward # update forward
elif isinstance(m, (IDetect, IAuxDetect)):
m.fuse()
m.forward = m.fuseforward
self.info()
return self
完成以上5步就可以正常开始训练和测试了~
该部分的与训练权重是在MobileOne官方的MobileOne-ms0的官方预训练权重,已兼容YOLOv7项目。
link:https://github.com/uniquechow/YOLO_series_doc/tree/main/lightweight/MobileOne
若有其他问题,可私信交流~~~
我正在使用这个:4.times{|i|assert_not_equal("content#{i+2}".constantize,object.first_content)}我之前声明过局部变量content1content2content3content4content5我得到的错误NameError:wrongconstantnamecontent2这个错误是什么意思?我很确定我想要content2=\ 最佳答案 你必须用一个大字母来调用ruby常量:Content2而不是content2。Aconstantnamestart
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
希望我没有误解“ducktyping”的含义,但从我读到的内容来看,这意味着我应该根据对象如何响应方法而不是它是什么类型/类来编写代码。代码如下:defconvert_hash(hash)ifhash.keys.all?{|k|k.is_a?(Integer)}returnhashelsifhash.keys.all?{|k|k.is_a?(Property)}new_hash={}hash.each_pair{|k,v|new_hash[k.id]=v}returnnew_hashelseraise"CustomattributekeysshouldbeID'sorPropertyo
在python中,我们可以使用多处理模块。如果Perl和Ruby中有类似的库,你会教它吗?如果您能附上一个简短的示例,我将不胜感激。 最佳答案 ruby:WorkingwithmultipleprocessesinRubyConcurrencyisaMythinRubyPerl:HarnessingthepowerofmulticoreWhyPerlIsaGreatLanguageforConcurrentProgramming此外,Perl的线程是native操作系统线程,因此您可以使用它们来利用多核。
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我正在用Ruby编写DSL来控制我正在处理的Arduino项目;巴尔迪诺。这是一只酒吧猴子,将由软件控制来提供饮料。Arduino通过串行端口接收命令,告诉Arduino要打开什么泵以及打开多长时间。它目前正在读取一个食谱(见下文)并将其打印出来。串行通信的代码以及我在下面提到的其他一些想法仍然需要改进。这是我的第一个DSL,我正在处理之前的示例,所以它的边缘非常粗糙。任何批评、代码改进(是否有任何关于RubyDSL最佳实践或习语的良好引用?)或任何一般性评论。我目前有DSL的粗略草稿,因此饮料配方如下所示(Githublink):desc"Simpleglassofwater"rec
我有一个单表继承设置,我有一个Controller(我觉得有多个Controller会重复)。但是,对于某些方法,我想调用模型的子类。我想我可以让浏览器发送一个参数,我会针对该参数编写一个case语句。像这样的东西:case@model[:type]when"A"@results=Subclass1.search(params[:term])when"B"@results=Subclass2.search(params[:term])...end或者,我了解到Ruby的所有技巧都可以用字符串创建模型。像这样的东西:@results=params[:model].constantize.
在我的Rails应用程序中,我收到来自brakeman的以下安全警告。使用模型属性调用的不安全反射方法常量化。这是我的代码正在执行的操作。chart_type=Chart.where(id:chart_id,).pluck(:type).firstbeginChartPresenter.new(chart_type.camelize.constantize.find(chart_id))rescueraise"Unabletofindthechartpresenter"end根据我的研究,我还没有找到任何具体的解决方案。我听说你可以创建一个白名单,但我不确定brakeman在寻找什么。
我正在尝试使用ruby改进来应用Rails钩子(Hook)。我想避免猴子补丁。当猴子修补时它会这样工作ActiveRecord::Base.class_evaldoafter_finddo#dosomethingwithmy_methodenddefmy_method#somethingusefulendend我已经能够通过做这样的事情来拥有类方法:moduleActiveRecordRefinementsrefineActiveRecord::Base.singleton_classdodefmy_method#somethingcoolendendend但我无法运行钩子(Hoo
文章目录1.价差套利原理1.1概述1.2以BTC为例2.投研分析3.veighna的价差交易回测引擎4.实盘交易1.价差套利原理1.1概述在数字货币交易市场,我们会发现大多数行情下,相同币种之间的不同交割合约会存在一定的价差,由于它们属于同一品种,本身价值不会有任何差别,而且涨跌趋势一致,相关性高。那么如果在它们价差低的时候买入,价差高的时候卖出,这样我们就可以赚取中间的这部分差价。不过在实际交易过程中,我们还需要考虑到交易滑点、手续费、极端行情下,价差走出趋势特征…1.2以BTC为例图一、不同合约的比特币行情图由上图可以看出比特币远月合约与永续合约之间存在一定的价差。图二、某一时刻比特币价差