作者简介:在校大学生一枚,华为云享专家,阿里云星级博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~ . 博客主页:ぃ灵彧が的学习日志 . 本文专栏:机器学习 . 专栏寄语:若你决定灿烂,山无遮,海无拦 .(文章目录)

# 导入需要的包
import paddle
import os
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import sys
import pickle
from paddle.vision.transforms import ToTensor
import paddle.nn.functional as F
print("本教程基于Paddle的版本号为:"+paddle.__version__)
'''
参数配置
'''
train_parameters = {
"input_size": [3, 32, 32], #输入图片的shape
"src_path":"/home/aistudio/data/data9154/cifar-10-python.tar.gz", #原始数据集路径
"target_path":"/home/aistudio/cifar-10-batches-py", #要解压的路径
"num_epochs": 40, #训练轮数
"train_batch_size": 64, #批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.0001 #超参数学习率
}
}

def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至/home/aistudio/目录下
'''
if(not os.path.isdir(target_path)):
import tarfile
tar = tarfile.open(src_path,'r')
tar.extractall(PATH=target_path)
tar.close()
else:
print("文件已解压")
#参数初始化
src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
batch_size=train_parameters['train_batch_size']
image_size=train_parameters['input_size']
epoch_num=train_parameters['num_epochs']
lr=train_parameters['learning_strategy']['lr']
#解压原始数据到指定路径
unzip_data(src_path,target_path)
#定义数据序列化函数
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
print(unpickle("cifar-10-batches-py/data_batch_1").keys())
print(unpickle("cifar-10-batches-py/test_batch").keys())
'''
自定义数据集
'''
from paddle.io import Dataset
class MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, mode='train'):
"""
步骤二:实现构造函数,定义数据集大小
"""
super(MyDataset, self).__init__()
if mode == 'train':
xs=[]
ys=[]
self.data = []
self.label = []
#批量读入数据
for i in range(1,6):
train_dict=unpickle("cifar-10-batches-py/data_batch_%d" % (i,))
xs.append(train_dict[b'data'])
ys.append(train_dict[b'labels'])
#拼接数据
Xtr = np.concatenate(xs)
Ytr = np.concatenate(ys)
#数据归一化处理
for (x,y) in zip(Xtr,Ytr):
x= x.flatten().astype('float32')/255.0
x= x.reshape(image_size)
#将数据同一添加到data和label中
self.data.append(x)
self.label.append(np.array(y).astype('int64'))
else:
self.data = []
self.label = []
#读入数据
test_dict=unpickle("cifar-10-batches-py/test_batch")
X=test_dict[b'data']
Y=test_dict[b'labels']
for (x,y) in zip(X,Y):
#数据归一化处理
x= x.flatten().astype('float32')/255.0
x= x.reshape(image_size)
#将数据同一添加到data和label中
self.data.append(x)
self.label.append(np.array(y).astype('int64'))
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
#返回单一数据和标签
data = self.data[index]
label = self.label[index]
#注:返回标签数据时必须是int64
return data, np.array(label, dtype='int64')
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
#返回数据总数
return len(self.data)
# 测试定义的数据集
train_dataset = MyDataset(mode='train')
eval_dataset = MyDataset(mode='val')
print('=============train_dataset =============')
#输出数据集的形状和标签
print(train_dataset.__getitem__(1)[0].shape,train_dataset.__getitem__(1)[1])
#输出数据集的长度
print(train_dataset.__len__())
print('=============eval_dataset =============')
#输出数据集的形状和标签
for data, label in eval_dataset:
print(data.shape, label)
break
#输出数据集的长度
print(eval_dataset.__len__())
print('飞桨内置数据集:', paddle.vision.datasets.__all__)
Batch=0
Batchs=[]
all_train_accs = []
def draw_train_acc(Batchs, train_accs):
title="training accs"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("acc", fontsize=14)
plt.plot(Batchs, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
all_train_loss = []
def draw_train_loss(Batchs, train_loss):
title="training loss"
plt.title(title, fontsize=24)
plt.xlabel("batch", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.plot(Batchs, train_loss, color='red', label='training loss')
plt.legend()
plt.grid()
plt.show()
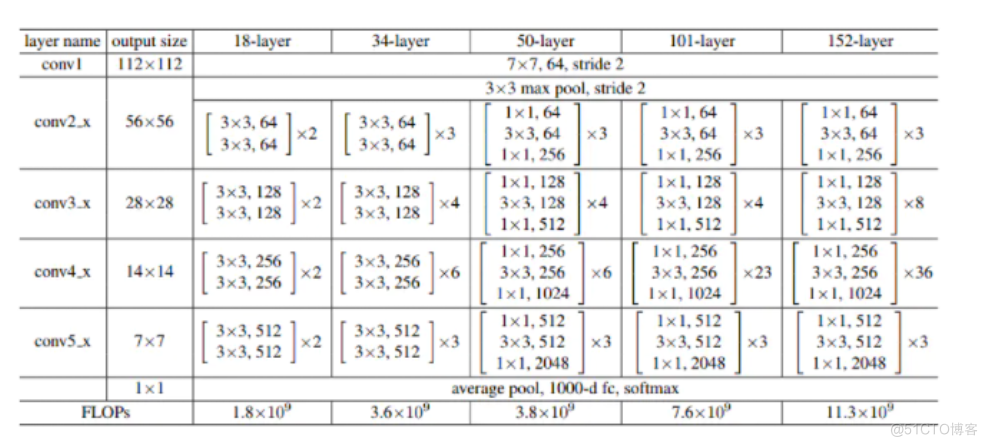 本示例直接调用飞桨API内置网络,resnet18进行训练!
本示例直接调用飞桨API内置网络,resnet18进行训练!
print('飞桨内置网络:', paddle.vision.models.__all__)
model = paddle.vision.models.resnet18()
paddle.summary(model,(1,3,32,32))
print('start training ... ')
# turn into training mode
model.train()
opt = paddle.optimizer.Adam(learning_rate=lr,
parameters=model.parameters())
train_loader = paddle.io.DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
valid_loader = paddle.io.DataLoader(eval_dataset, batch_size=batch_size)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = paddle.to_tensor(data[1])
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
loss = F.cross_entropy(logits, y_data)
acc = paddle.metric.accuracy(logits,y_data)#计算精度
if batch_id!=0 and batch_id%100==0:
Batch = Batch + 100
Batchs.append(Batch)
all_train_loss.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(epoch,batch_id,loss.numpy(),acc.numpy()))
loss.backward()
opt.step()
opt.clear_grad() #opt.clear_grad()来重置梯度
paddle.save(model.state_dict(),'resnet18')#保存模型
draw_train_acc(Batchs,all_train_accs)
draw_train_loss(Batchs,all_train_loss)
#模型评估
para_state_dict = paddle.load("resnet18")
model.set_state_dict(para_state_dict) #加载模型参数
model.eval() #训练模式
accs = []
for batch_id,data in enumerate(valid_loader()):#测试集
x_data = data[0]
y_data = paddle.to_tensor(data[1])
y_data = paddle.unsqueeze(y_data, 1)
logits = model(x_data)
acc = paddle.metric.accuracy(logits, y_data)
accs.append(acc.numpy())
avg_acc = np.mean(accs)
print("当前模型在验证集上的准确率为:",avg_acc)
# 图片预处理
def load_image(file):
'''
预测图片预处理
'''
#打开图片
im = Image.open(file)
#将图片调整为跟训练数据一样的大小 32*32,设定ANTIALIAS,即抗锯齿.resize是缩放
im = im.resize((32, 32), Image.ANTIALIAS)
#建立图片矩阵 类型为float32
im = np.array(im).astype(np.float32)
#矩阵转置
im = im.transpose((2, 0, 1))
#将像素值从【0-255】转换为【0-1】
im = im / 255.0
#print(im)
im = np.expand_dims(im, axis=0)
# 保持和之前输入image维度一致
print('im_shape的维度:',im.shape)
return im
'''
模型预测
'''
para_state_dict = paddle.load("resnet18")
model = paddle.vision.models.resnet18()
model.set_state_dict(para_state_dict) #加载模型参数
model.eval() #训练模式
#展示预测图片
infer_path='/home/aistudio/data/data7940/dog.png'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
#对预测图片进行预处理
infer_img = load_image(infer_path)
infer_img = infer_img.reshape(3,32,32)
#定义标签列表
label_list = [ "airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse","ship", "truck"]
data = infer_img
dy_x_data = np.array(data).astype('float32')
dy_x_data=dy_x_data[np.newaxis,:, : ,:]
img = paddle.to_tensor (dy_x_data)
out = model(img)
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
print(label_list[lab])
#step3:训练模型
# 用Model封装模型
model = paddle.Model(model)
# 定义损失函数
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=epoch_num, # 总的训练轮次
batch_size = batch_size, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
save_dir='./chk_points/', # 分阶段的训练模型存储路径
callbacks=[visualdl]) # 回调函数使用
#保存模型
model.save('model_save_dir')
model.evaluate(eval_dataset, batch_size=batch_size, verbose=1)
#定义标签列表
label_list = [ "airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse","ship", "truck"]
#读入测试图片并展示
infer_path='/home/aistudio/data/data7940/dog.png'
img = Image.open(infer_path)
plt.imshow(img)
plt.show()
#载入要预测的图片
infer_img = load_image(infer_path)
infer_img = infer_img.reshape(1,1,3,32,32)
#将图片变为数组
# infer_img=np.array(infer_img).astype('float32')
#进行预测
result = model.predict(infer_img)
# 输出预测结果
# print('results',result)
print("infer results: %s" % label_list[np.argmax(result[0][0])])

我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我刚刚安装了带有RVM的Ruby2.2.0,并尝试使用它得到了这个:$rvmuse2.2.0--defaultUsing/Users/brandon/.rvm/gems/ruby-2.2.0dyld:Librarynotloaded:/usr/local/lib/libgmp.10.dylibReferencedfrom:/Users/brandon/.rvm/rubies/ruby-2.2.0/bin/rubyReason:Incompatiblelibraryversion:rubyrequiresversion13.0.0orlater,butlibgmp.10.dylibpro