最近需要读取Excel中的内容,然后进行后续操作,对于这块知识,博主以前以为自己不会涉及到,但是现在一涉及到,第一步就错了,搞了好久。真的心累。因此写了这篇博客。
目的:excel中存放着数据,如果要进行计算及其它操作,首先就要进行读取。
目录
总结
我们先来看一下python中能操作Excel的库对比(一共九个库):
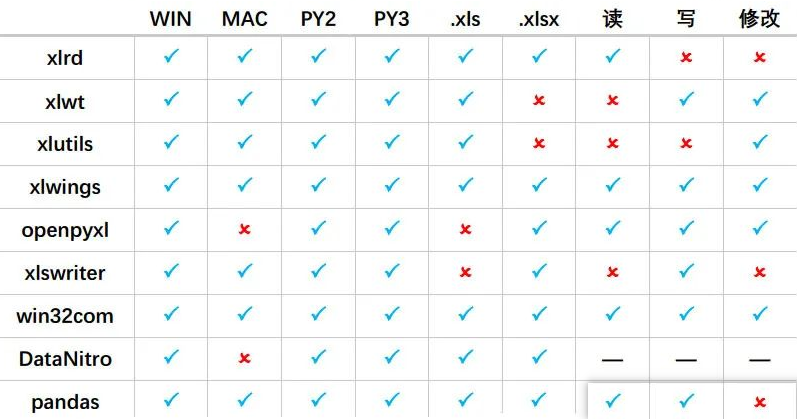
可以发现,还是挺多的
这里使用的是xlrd库。
这里首先就是导入这个包,
pip install xlrd==1.2.0xlrd包版本最好是1.2.0,因为笔者使用2.多版本的xlrd时,代码出现了类似下面的报错,也就是说xlrd版本太高会导致无法支持读取xlsx后缀的excel。
xlrd.biffh.XLRDError: Excel xlsx file; not supported
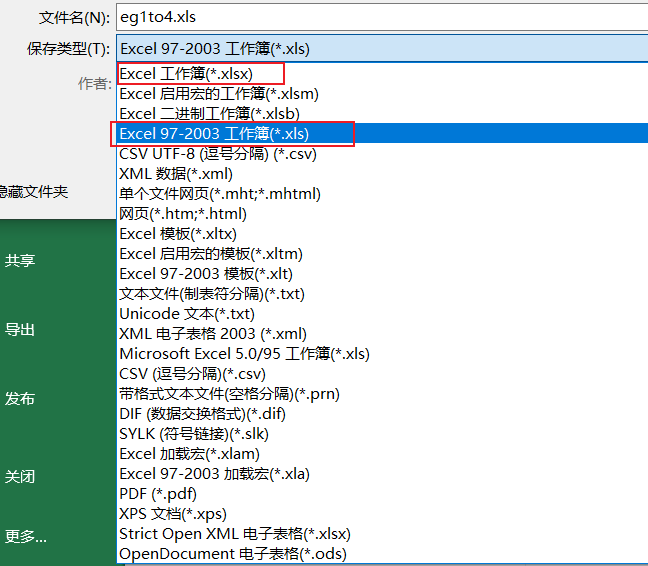
大家可以去试试将excel另存,看看保存类型。
目前笔者使用的是Excel2019版本的,默认保存类型为xlsx。
如果你之前已经安装xlrd高版本或更低版本了,建议先卸载一下,重新安装。
pip uninstall xlrd
pip install xlrd==1.2.0实例
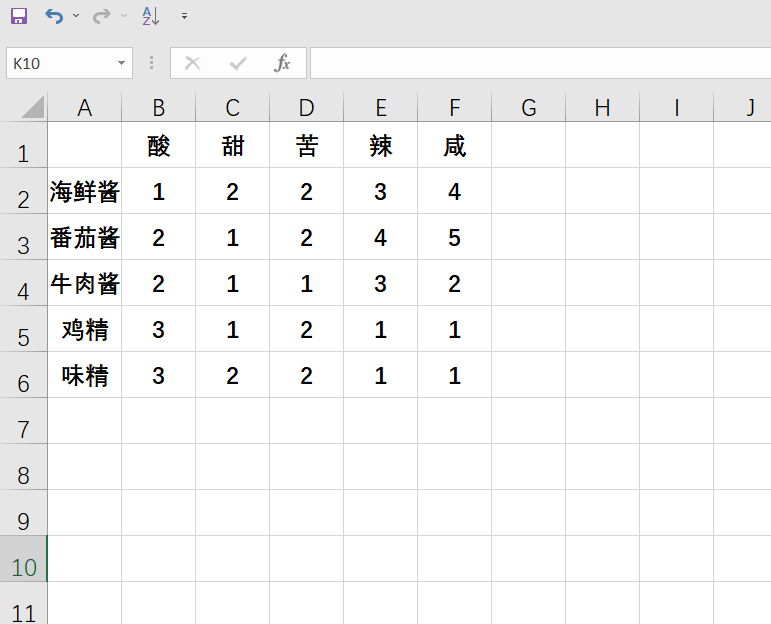
一个excel中有如上数据,我们需要将其提取出来,方便python进行后续操作。
代码如下:
def extract1(file,index=0):
workbook = xlrd.open_workbook(file)
worksheet = workbook.sheet_by_index(index)
rows = worksheet.nrows
all = []
for i in range(rows):
a = worksheet.row_values(i)[:]
all.append(a)
print(all)
cc = np.array(all)
print(cc)
return ccfile是文件的路径及名称,index就是当前sheet表的索引。 下图就是具体的索引。

当然也可以根据sheet表的名称。
如下面代码第一行按照的是索引方式,第二行按照的是sheet名称。大家可自行选择
worksheet = workbook.sheet_by_index(0)
worksheet = workbook.sheet_by_name("sheet1")
rows = worksheet.nrows返回的是sheet表的行数,ncols则是列数
all = []
for i in range(rows):
a = worksheet.row_values(i)[:]
all.append(a)首先定义一个空列表,然后遍历每行,将里面的数据写入列表中,
row_values()是用来返回给定行中单元格值的切片。
最后将其转换成数组类型即可。(按要求来,大家也可以不换)
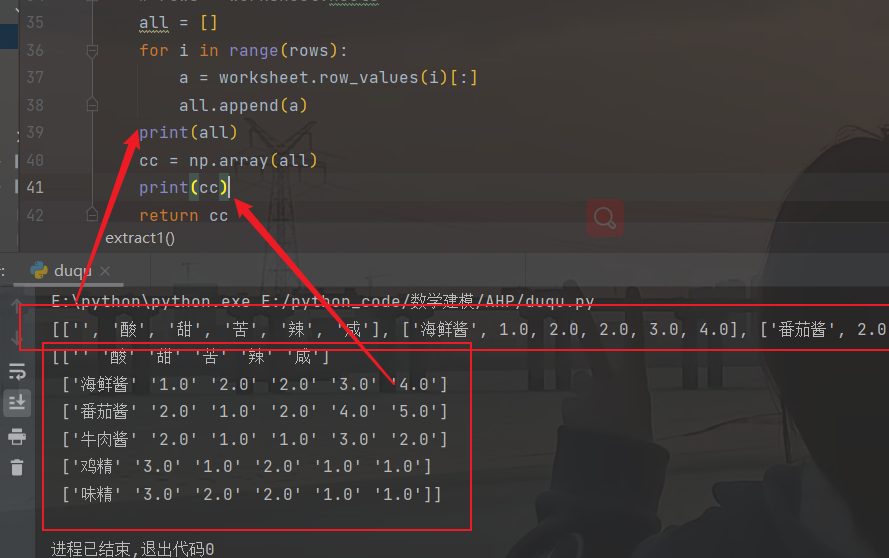
下图是结果:
换个高级的写法,用推导式写(浓缩才是精华)
def extract(file,index=0):
workbook = xlrd.open_workbook(file)
worksheet = workbook.sheet_by_index(index)
rows = worksheet.nrows
c = tuple(worksheet.row_values(i)[:] for i in range(rows))
a = np.array(c)
print(a)
return a代码行数瞬间缩短了。
最好调用一下函数即可
file = r'C:\Users\knighthood\OneDrive\桌面\11.xlsx'
extract1(file)要求:假如我excel只要图中框出来的区域。
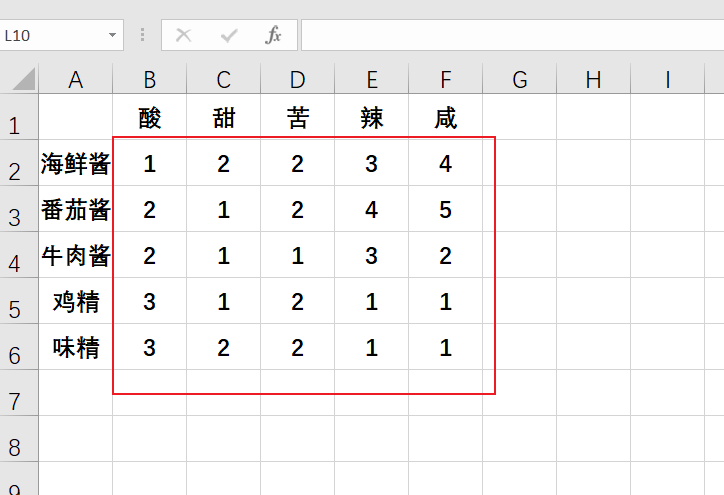
以下为了看的较为简便,我使用推导式的代码
def confine_array(file,index=0):
workbook = xlrd.open_workbook(file)
worksheet = workbook.sheet_by_index(index)
rows = worksheet.nrows
c = tuple(worksheet.row_values(i)[1:] for i in range(1, rows))
a = np.array(c)
print(a)
return a如上,可以发现,代码变化之处就下面这一行。
c = tuple(worksheet.row_values(i)[1:] for i in range(1, rows))一步步讲解:
①for i in range(1, rows)
首先对于后面的for循环,i控制的就是获取的行,更改其范围就会更改获取到的行、行数。
如果是上面说的(1,rows),则对应着获取第二行到最后一行,(0表示第一行)
②worksheet.row_values(i)[1:]
最后的[1:](本来的代码中是没有或者是[:])表示的是i行的元素从第2列(个)获取到最后一行(个)。
因此我们只需要更改这两处就可以获得不同的内容矩阵(如下)。
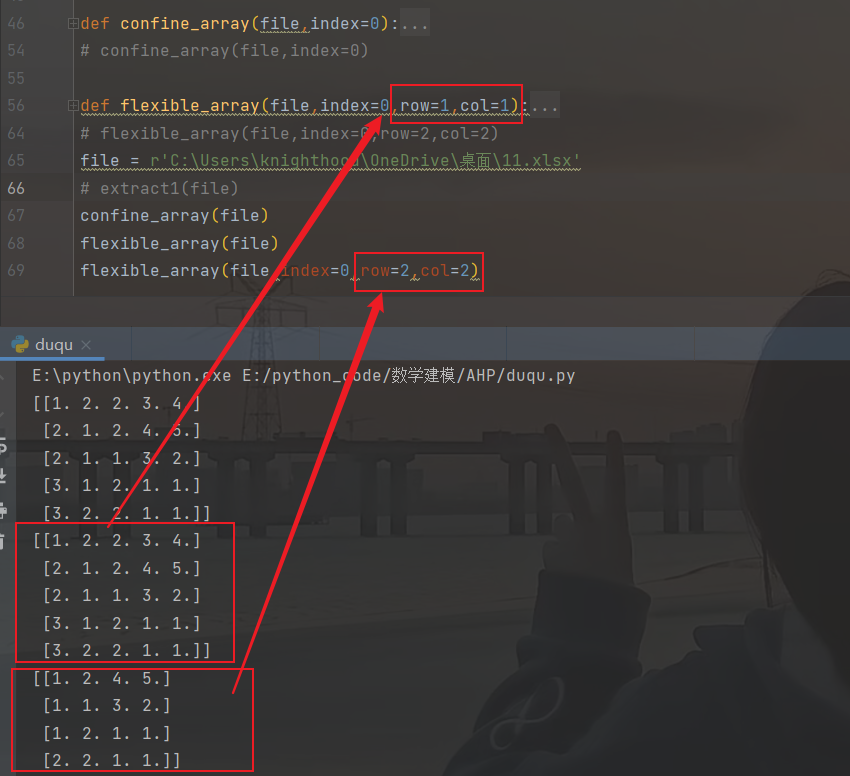
def flexible_array(file,index=0,row=1,col=1):
workbook = xlrd.open_workbook(file)
worksheet = workbook.sheet_by_index(index)
rows = worksheet.nrows
c = tuple(worksheet.row_values(i)[col:] for i in range(row,rows))
a = np.array(c)
print(a)
return a结果如下图
要求:能不能更简化一点,根据我从哪个位置要数据,如第二行第二列开始,将这后面的数据进行读取。每次这样对来对去,容易出错,还是根据行列开始计算比较方便。
这里为了防止行列一样,我就多加了一列。
def flexible1_array(file,index=0,row=1,col=1):
workbook = xlrd.open_workbook(file)
worksheet = workbook.sheet_by_index(index)
rows = worksheet.nrows
c = tuple(worksheet.row_values(i)[col-1:] for i in range(row-1,rows))
a = np.array(c)
print(a)
return a代码也主要变化了这一行
c = tuple(worksheet.row_values(i)[col-1:] for i in range(row-1,rows))这里笔者就不多解释了。
 现在就可以根据需要的起始单元格所在的行列进行选取所要的内容。
现在就可以根据需要的起始单元格所在的行列进行选取所要的内容。
要求:不需要最后一列
这里的话,笔者就设置了最后需要的行和列作为结束的读取。
def flexible2_array(file,index=0,row=1,col=1,end_row=None,end_col=None):
workbook = xlrd.open_workbook(file)
worksheet = workbook.sheet_by_index(index)
rows = worksheet.nrows
if end_row is None:
c = tuple(worksheet.row_values(i)[col-1:end_col] for i in range(row-1, rows))
else:
c = tuple(worksheet.row_values(i)[col - 1:end_col] for i in range(row - 1, end_row))
a = np.array(c)
print(a)
return a上述代码意思是,如果不输入结束的行和列,读取到的是包含数据的行列,如果输入了行和列(或者其中一个),就读取相应的内容。由于end_row放在range()函数中,因此需要加个if判断。
结果如下:
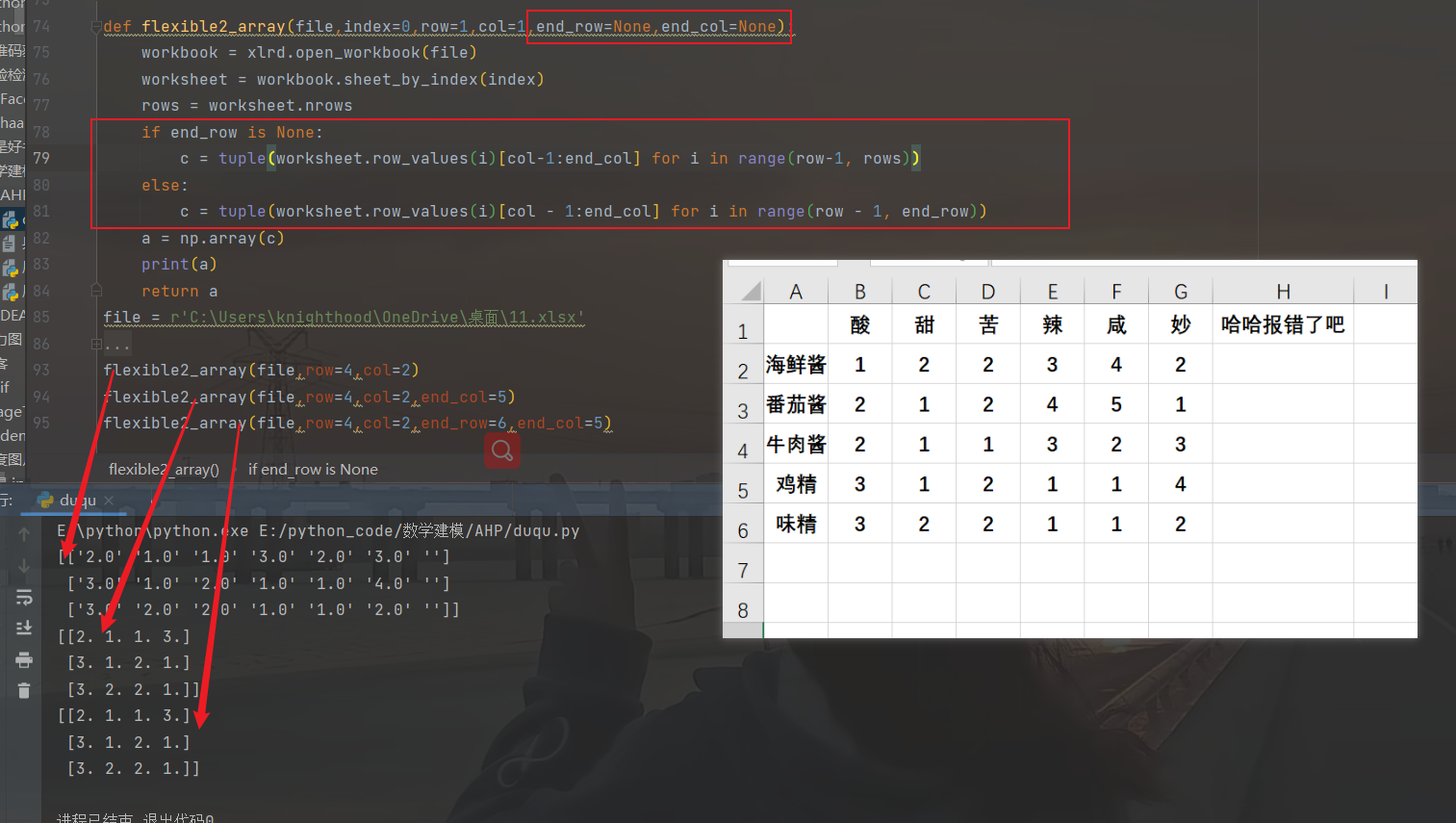
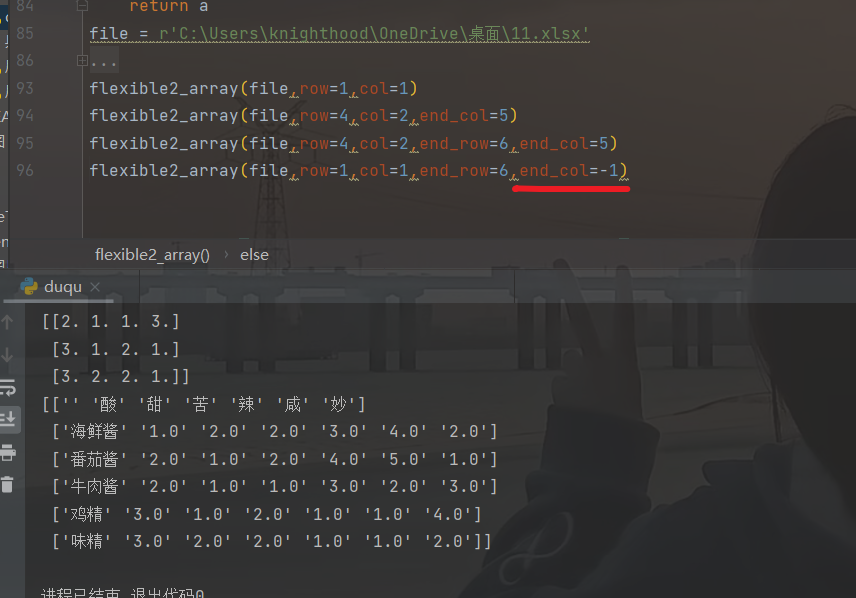
此外,我还发现,end_col由于放在[]中,可输入负数(不懂的可以去看看python列表负索引)。
不过这里的-1,其实际是排除了最后一列,从你输入的行列到,你输入的结束行和倒数第二列。
有些人可能会觉得别扭(比如我,更喜欢-1表示从起始列到最后一列,-2表示从起始列到倒数第二列)
def flexible3_array(file,index=0,row=1,col=1,end_row=None,end_col=None):
workbook = xlrd.open_workbook(file)
worksheet = workbook.sheet_by_index(index)
rows = worksheet.nrows
if end_row is None:
c = tuple(worksheet.row_values(i)[col-1:end_col if end_col > 0 else end_col+1] for i in range(row-1, rows))
else:
c = tuple(worksheet.row_values(i)[col-1:end_col if end_col > 0 else end_col+1] for i in range(row - 1, end_row))
a = np.array(c)
print(a)
return a这里,代码中将判断end_col是否为负,使用了if-else写在一行。减少了很多代码判断量,使看起来更简洁。

这里看个人喜好是否使用这个方法。
还有一个end_col参数使用负数的原因是,end_row由于在excel中对应的是行,其用的是数字表示,而excel中列用字母表示,因此如果当数据列数太多的时候(如下图),去数列还是挺麻烦的

上述内容是一步一步进行修改添加的,对应着平时要求的逐渐添加,功能的逐渐完善。
笔者在上篇构建层次分析法,用到的数据矩阵,可以和这篇一起结合,通过excel读取转为数组,然后进行层次分析法的操作。
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
请帮助我理解范围运算符...和..之间的区别,作为Ruby中使用的“触发器”。这是PragmaticProgrammersguidetoRuby中的一个示例:a=(11..20).collect{|i|(i%4==0)..(i%3==0)?i:nil}返回:[nil,12,nil,nil,nil,16,17,18,nil,20]还有:a=(11..20).collect{|i|(i%4==0)...(i%3==0)?i:nil}返回:[nil,12,13,14,15,16,17,18,nil,20] 最佳答案 触发器(又名f/f)是
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit