摘要:花10分钟开发一个极简版的Java线程池,让小伙伴们更好的理解线程池的核心原理。
本文分享自华为云社区《放大招了,冰河带你10分钟手撸Java线程池,yyds,赶快收藏吧》,作者:冰 河。
看过Java线程池源码的小伙伴都知道,在Java线程池中最核心的类就是ThreadPoolExecutor,而在ThreadPoolExecutor类中最核心的构造方法就是带有7个参数的构造方法,如下所示。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)各参数的含义如下所示。
并且Java的线程池是通过 生产者-消费者模式 实现的,线程池的使用方是生产者,而线程池本身就是消费者。
Java线程池的核心工作流程如下图所示。
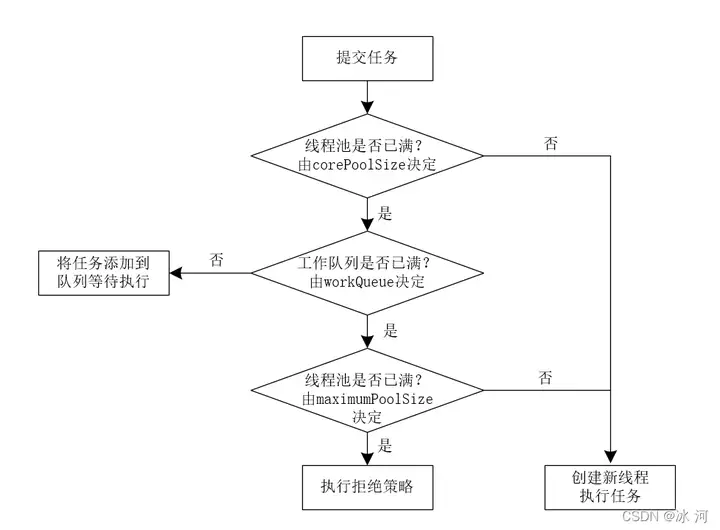
我们自己手动实现的线程池要比Java自身的线程池简单的多,我们去掉了各种复杂的处理方式,只保留了最核心的原理:线程池的使用者向任务队列中添加任务,而线程池本身从任务队列中消费任务并执行任务。
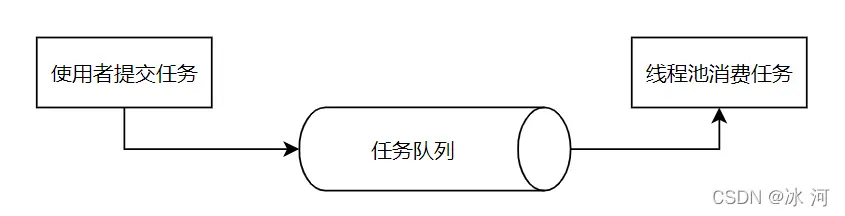
只要理解了这个核心原理,接下来的代码就简单多了。在实现这个简单的线程池时,我们可以将整个实现过程进行拆解。拆解后的实现流程为:定义核心字段、创建内部类WorkThread、创建ThreadPool类的构造方法和创建执行任务的方法。

首先,我们创建一个名称为ThreadPool的Java类,并在这个类中定义如下核心字段。
核心代码如下所示。
//默认阻塞队列大小
private static final int DEFAULT_WORKQUEUE_SIZE = 5;
//模拟实际的线程池使用阻塞队列来实现生产者-消费者模式
private BlockingQueue<Runnable> workQueue;
//模拟实际的线程池使用List集合保存线程池内部的工作线程
private List<WorkThread> workThreads = new ArrayList<WorkThread>();在ThreadPool类中创建一个内部类WorkThread,模拟线程池中的工作线程。主要的作用就是消费workQueue中的任务,并执行任务。由于工作线程需要不断从workQueue中获取任务,所以,这里使用了while(true)循环不断尝试消费队列中的任务。
核心代码如下所示。
//内部类WorkThread,模拟线程池中的工作线程
//主要的作用就是消费workQueue中的任务,并执行
//由于工作线程需要不断从workQueue中获取任务,使用了while(true)循环不断尝试消费队列中的任务
class WorkThread extends Thread{
@Override
public void run() {
//不断循环获取队列中的任务
while (true){
//当没有任务时,会阻塞
try {
Runnable workTask = workQueue.take();
workTask.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}这里,我们为ThreadPool类创建两个构造方法,一个构造方法中传入线程池的容量大小和阻塞队列,另一个构造方法中只传入线程池的容量大小。
核心代码如下所示。
//在ThreadPool的构造方法中传入线程池的大小和阻塞队列
public ThreadPool(int poolSize, BlockingQueue<Runnable> workQueue){
this.workQueue = workQueue;
//创建poolSize个工作线程并将其加入到workThreads集合中
IntStream.range(0, poolSize).forEach((i) -> {
WorkThread workThread = new WorkThread();
workThread.start();
workThreads.add(workThread);
});
}
//在ThreadPool的构造方法中传入线程池的大小
public ThreadPool(int poolSize){
this(poolSize, new LinkedBlockingQueue<>(DEFAULT_WORKQUEUE_SIZE));
}在ThreadPool类中创建执行任务的方法execute(),execute()方法的实现比较简单,就是将方法接收到的Runnable任务加入到workQueue队列中。
核心代码如下所示。
//通过线程池执行任务
public void execute(Runnable task){
try {
workQueue.put(task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}这里,我们给出手动实现的ThreadPool线程池的完整源代码,如下所示。
package io.binghe.thread.pool;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.stream.IntStream;
/**
* @author binghe
* @version 1.0.0
* @description 自定义线程池
*/
public class ThreadPool {
//默认阻塞队列大小
private static final int DEFAULT_WORKQUEUE_SIZE = 5;
//模拟实际的线程池使用阻塞队列来实现生产者-消费者模式
private BlockingQueue<Runnable> workQueue;
//模拟实际的线程池使用List集合保存线程池内部的工作线程
private List<WorkThread> workThreads = new ArrayList<WorkThread>();
//在ThreadPool的构造方法中传入线程池的大小和阻塞队列
public ThreadPool(int poolSize, BlockingQueue<Runnable> workQueue){
this.workQueue = workQueue;
//创建poolSize个工作线程并将其加入到workThreads集合中
IntStream.range(0, poolSize).forEach((i) -> {
WorkThread workThread = new WorkThread();
workThread.start();
workThreads.add(workThread);
});
}
//在ThreadPool的构造方法中传入线程池的大小
public ThreadPool(int poolSize){
this(poolSize, new LinkedBlockingQueue<>(DEFAULT_WORKQUEUE_SIZE));
}
//通过线程池执行任务
public void execute(Runnable task){
try {
workQueue.put(task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//内部类WorkThread,模拟线程池中的工作线程
//主要的作用就是消费workQueue中的任务,并执行
//由于工作线程需要不断从workQueue中获取任务,使用了while(true)循环不断尝试消费队列中的任务
class WorkThread extends Thread{
@Override
public void run() {
//不断循环获取队列中的任务
while (true){
//当没有任务时,会阻塞
try {
Runnable workTask = workQueue.take();
workTask.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}没错,我们仅仅用了几十行Java代码就实现了一个极简版的Java线程池,没错,这个极简版的Java线程池的代码却体现了Java线程池的核心原理。
接下来,我们测试下这个极简版的Java线程池。
测试程序也比较简单,就是通过在main()方法中调用ThreadPool类的构造方法,传入线程池的大小,创建一个ThreadPool类的实例,然后循环10次调用ThreadPool类的execute()方法,向线程池中提交的任务为:打印当前线程的名称--->> Hello ThreadPool。
整体测试代码如下所示。
package io.binghe.thread.pool.test;
import io.binghe.thread.pool.ThreadPool;
import java.util.stream.IntStream;
/**
* @author binghe
* @version 1.0.0
* @description 测试自定义线程池
*/
public class ThreadPoolTest {
public static void main(String[] args){
ThreadPool threadPool = new ThreadPool(10);
IntStream.range(0, 10).forEach((i) -> {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "--->> Hello ThreadPool");
});
});
}
}接下来,运行ThreadPoolTest类的main()方法,会输出如下信息。
Thread-0--->> Hello ThreadPool
Thread-9--->> Hello ThreadPool
Thread-5--->> Hello ThreadPool
Thread-8--->> Hello ThreadPool
Thread-4--->> Hello ThreadPool
Thread-1--->> Hello ThreadPool
Thread-2--->> Hello ThreadPool
Thread-5--->> Hello ThreadPool
Thread-9--->> Hello ThreadPool
Thread-0--->> Hello ThreadPool至此,我们自定义的Java线程池就开发完成了。
线程池的核心原理其实并不复杂,只要我们耐心的分析,深入其源码理解线程池的核心本质,你就会发现线程池的设计原来是如此的优雅。希望通过这个手写线程池的小例子,能够让你更好的理解线程池的核心原理。
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.