提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
使用neo4j来完成人员关系
公司项目有一个功能需要将各个人员关系列出,在参加评选的时候,进行展示和筛选
neo4j是高性能的NOSQL图形数据库,在neo4j中,社区版本只能使用一个database。在neo4j中不存在表的概念,我们只需要注意两个东西,一个是节点,一个是关系。不同节点和相同节点都可以产生关系。
https://neo4j.com/download-center/
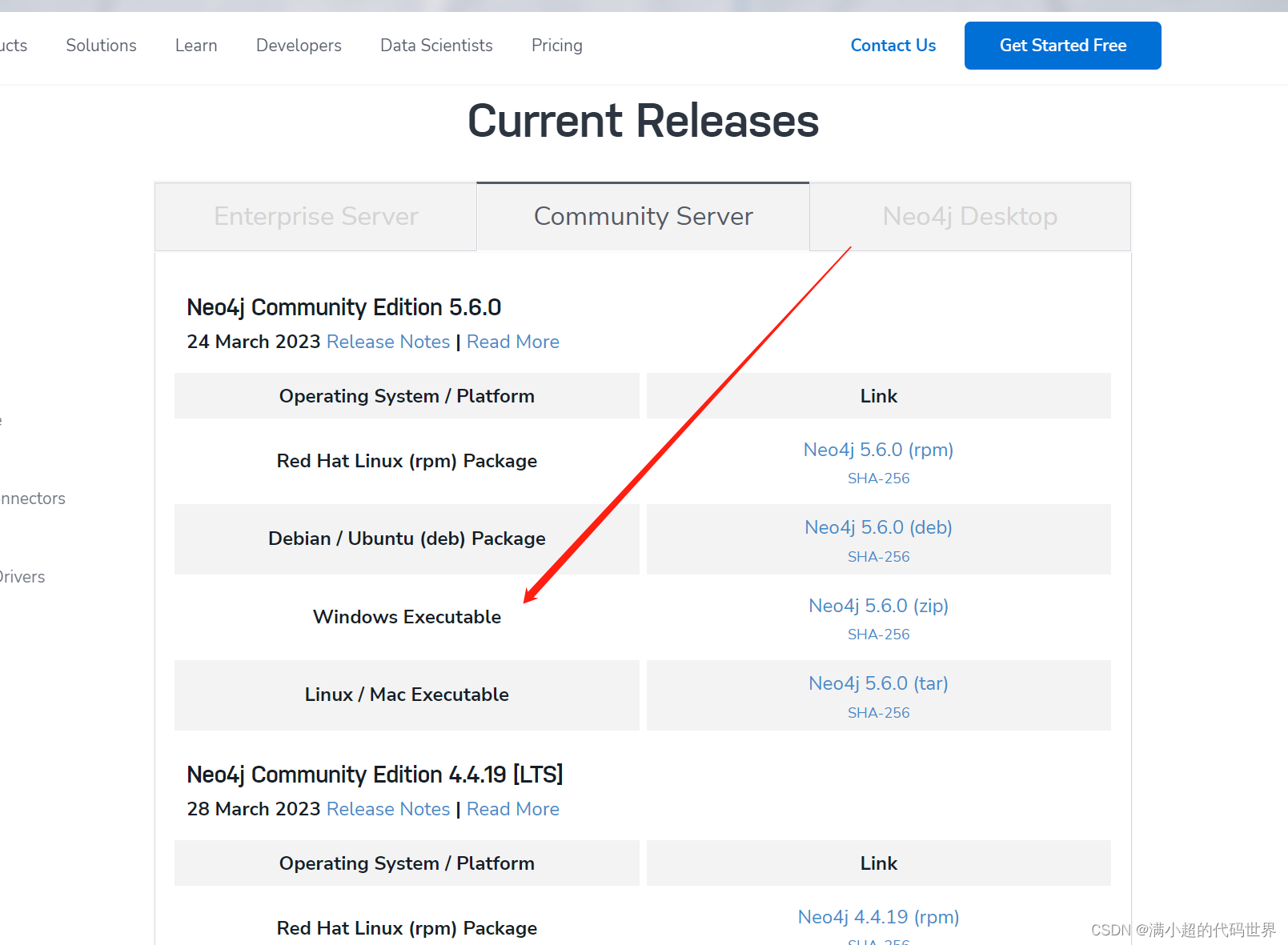
我下载的是3.5.28,超过4.x,jdk版本需要11
在bin目录下使用cmd命令 在命令框中执行 neo4j.bat console启动数据库
1.登录管理页面 http://localhost:7474
2.第一次登录账号密码都是neo4j
1.创建节点 create (:node1{nodeId:1,name:'王大'})
2.修改节点 merge (a:node1{nodeId:1}) set a.name='王小二' return a //如果节点不存在就创建
3.删除节点 match (a:node1{nodeId:1}) delete a
4.查询节点 match (a:node1{nodeId:1}) return a
5.创建关系 create (a:node1{nodeId:1})-[:relationShip{shipId:1,shipName:'好友'}]->(b:node1{nodeId:2})
6.查询关系 match (a:node1)-[r:relationShip]->(b:node1) return a.name,r.shipName,b.name
7.在查询关系时可以在a和关系以及b中设置查询条件,或者在b后跟where条件来筛选
本项目是springboot框架进行开发的,所以在项目中添加pom依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
这个功能是对人员进行关系筛选,人员身份是两类,一种是评委,一种是选手,所以,我们使用PersonNode对象,并且使用type来区分
可以使用neo4j框架自带的注解进行标注,NodeEntity是存在neo4j数据库种node的节点名称,Property是存放在数据库的名称,Relationship是节点关系的属性,包括节点类型和指向。指向默认是向外,也可以向内和双向。personRelationship是另一个关系类的名称
@Data
@NodeEntity(label = "PersonNode")
public class PersonNode {
@Id
@GeneratedValue
private Long id;
@Property(name = "type")
private Integer type;
@Property(name = "personId")
private String personId;
@Property(name = "name")
private String name;
@Property(name = "idCard")
private String idCard;
@Relationship(type = "personRelationship",direction = Relationship.OUTGOING) //这是关系
private List<PersonRelationship> relationship;
}
@Data
@RelationshipEntity(type = "personRelationship")
public class PersonRelationship {
@Id
@GeneratedValue
private Long id;
@StartNode
private PersonNode startNode;
@EndNode
private PersonNode endNode;
/**
@Property 注解用于定义单个属性,通常用于标注在实体类的字段上,指定该字段映射到节点或关系的一个属性
@Properties 注解用于定义多个属性,通常用于标注在实体类的方法上,指定该方法返回一个 Map<String, Object>
使用@Property注解时,如果属性名与注解的值相同,则可以省略注解的值
*/
@Property
private String relationName; //关系类型
private String typeName; //分类名称
private String level; //等级
}
1.创建一个PersonNodeRepository继承Neo4jRepository
2.在PersonNodeRepository可以使用注解@query来写cql语句
3.比如创建人员信息:我使用MERGE来实现,存在就更新
MERGE (n:PersonNode{personId: $personNode.personId}) SET n.name= $personNode.name,n.idCard=$personNode.idCard,n.type=$personNode.type return n
PersonNode saveOrUpdate(@Param("personNode")PersonNode personNode);
4.创建关系:先根据条件进行查询,在使用merge创建关系
@Query("Match (s:PersonNode{personId: $relationExcel.startPersonId}),(e:PersonNode{personId:$relationExcel.endPersonId})" +
"MERGE (s)-[:personRelationship {relationName:${relationExcel.relationName},typeName:${relationExcel.typeName},relationId:${relationExcel.relationId}]->(e) ")
void createPersonRelation(PersonRelationExcel relationExcel);
5.在neo4j种,查询后的数据是一个特殊的格式类型。所以往往需要对这个格式进行处理,我们可以使用apoc插件来使返回的结果呈现多层关系一样 的树状结构,在这个查询条件中,使用p来接收查询的结果,with将单个元素组组成列表,最后使用apoc生成树状数据。personRelationship中带有*表示查询所有层级的数据。如果不带 * ,那么只会返回两层数据
MATCH p=(n:PersonNode)-[:personRelationship*]->(m:PersonNode)
with collect(p) as ps call apoc.convert.toTree(ps) yield value return value
为什么要这样,因为前端的框架需要所有的节点list和所有的关系list
1.首先返回node节点,根据relationName,relationIdList,expertIdList,auditPersonIdList来筛选,ALL(rel IN r WHERE rel.relationName IN $dto.relationName ) ,r是一个列表,需要遍历r来判断是否存在。使用关系后,使用WITH和relationships ,relationship将获取到p中所有 的关系,并且形成集合。UNWIND 将集合展开。可能有人问,集合展开和集合有什么关系:
有的集合长这样['a','b','c','d','e'] ,有的集合长这样:[['a','b','c'],['d','e']]
对于with形成的集合就长[['a','b','c'],['d','e']] , UNWIND 展开的集合长:['a','b','c','d','e']
最后我们得到了rs这样的集合,rs存在startNode和endNode的id,我们可以通过这两个属性来查询节点
我们使用collect来生成集合,并且使用distinct去重来获取到startNode的节点和endNode的节点
最后我们将这两个集合展开成一个集合返回
@Query("MATCH p=(n:PersonNode)-[r:personRelationship*]->(m:PersonNode) " +
"WHERE 1=1 " +
"AND CASE WHEN size($dto.relationName) <> 0 THEN ALL(rel IN r WHERE rel.relationName IN $dto.relationName ) ELSE true END " +
"AND CASE WHEN size($dto.relationIdList) <> 0 THEN ALL(rel IN r WHERE rel.relationId IN $dto.relationIdList ) ELSE true END " +
"AND CASE WHEN size($dto.expertIdList) <> 0 THEN n.personId IN $dto.expertIdList ELSE true END " +
"AND CASE WHEN size($dto.auditPersonIdList) <> 0 THEN m.personId IN $dto.auditPersonIdList ELSE true END " +
"AND CASE WHEN $dto.other ='Y' THEN length(p) > 1 ELSE true END " +
"WITH n, m, relationships(p) AS rels " +
"UNWIND rels AS rs " +
"match (a:PersonNode{personId:startNode(rs).personId}),(b:PersonNode{personId:endNode(rs).personId}) "+
"WITH collect(distinct {personId:a.personId,type:a.type,name:a.name}) + collect(distinct {personId:b.personId,type:b.type,name:b.name}) as nodes1 "+
"UNWIND nodes1 as nodes " +
"RETURN DISTINCT nodes")
List getNode(@Param("dto") RelationConditionDto dto);
2.获取关系的集合
和获取对象一样,注意,我们将r展开,还需要去重。match的结果关系可能有很多重复项
@Query("MATCH p=(n:PersonNode)-[r:personRelationship*]->(m:PersonNode) " +
"WHERE 1=1 " +
"AND CASE WHEN size($dto.relationName) <> 0 THEN ALL(rel IN r WHERE rel.relationName IN $dto.relationName ) ELSE true END " +
"AND CASE WHEN size($dto.relationIdList) <> 0 THEN ALL(rel IN r WHERE rel.relationId IN $dto.relationIdList ) ELSE true END " +
"AND CASE WHEN size($dto.expertIdList) <> 0 THEN n.personId IN $dto.expertIdList ELSE true END " +
"AND CASE WHEN SIZE($dto.auditPersonIdList) <> 0 THEN m.personId IN $dto.auditPersonIdList ELSE true END " +
"AND CASE WHEN $dto.other ='Y' THEN length(p) > 1 ELSE true END " +
"UNWIND r AS rels " +
"with distinct(rels) as rs "+
"match (a:PersonNode{personId:startNode(rs).personId}),(b:PersonNode{personId:endNode(rs).personId}) "+
"return a.personId as startId,a.name as startName,b.personId as endId,b.name as endName,rs.typeName as typeName,rs.relationName as relationName,rs.relationId as relationId")
List<Map> getRelationList(@Param("dto") RelationConditionDto dto);
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
📢博客主页:https://blog.csdn.net/weixin_43197380📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由Loewen丶原创,首发于CSDN,转载注明出处🙉📢现在的付出,都会是一种沉淀,只为让你成为更好的人✨文章预览:一.分辨率(Resolution)1、工业相机的分辨率是如何定义的?2、工业相机的分辨率是如何选择的?二.精度(Accuracy)1、像素精度(PixelAccuracy)2、定位精度和重复定位精度(RepeatPrecision)三.公差(Tolerance)四.课后作业(Post-ClassExercises)视觉行业的初学者,甚至是做了1~2年