实验室工作站被多人使用导致需求不同的cuda版本,一直没找到一个完全完整靠谱的教程,这是我参考几个博客完成测试的全过程记录,方便以后操作,无任何商业用途,如有侵权,请联系删除。
注:其中好多摘录自其他博客,我在操作过程中大部分未保存结果,只能用其他博客中我认为合适的图片等代替
安装前需先确定显卡驱动、CUDA、cuDNN等之间的对应关系。由于我的帐户没有管理员权限,不能安装显卡驱动,只能根据现有驱动的版本来选择CUDA版本,输入指令 cat /proc/driver/nvidia/version 查看当前服务器版本号

文中目录结构解释如下:
用户名为zb;
目录 /home/zb/cuda/用于存放不同的cuda版本,每安装一个版本的CUDA就在该目录下新建一个文件夹,如cuda-8.0,并安装在相应的目录下;
安装包下载到 /home/zb/cuda/ 目录下,安装完成后就删除安装包;
目录 /home/zb/cuda/tem/ 目录用于cuDNN的解压,安装完成后就删除该目录;
注意:不同版本cuda对应的NVIDIA驱动版本
CUDA与Driver的对应版本:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
cuda10.0与Linux系统以及GCC的对应关系:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html
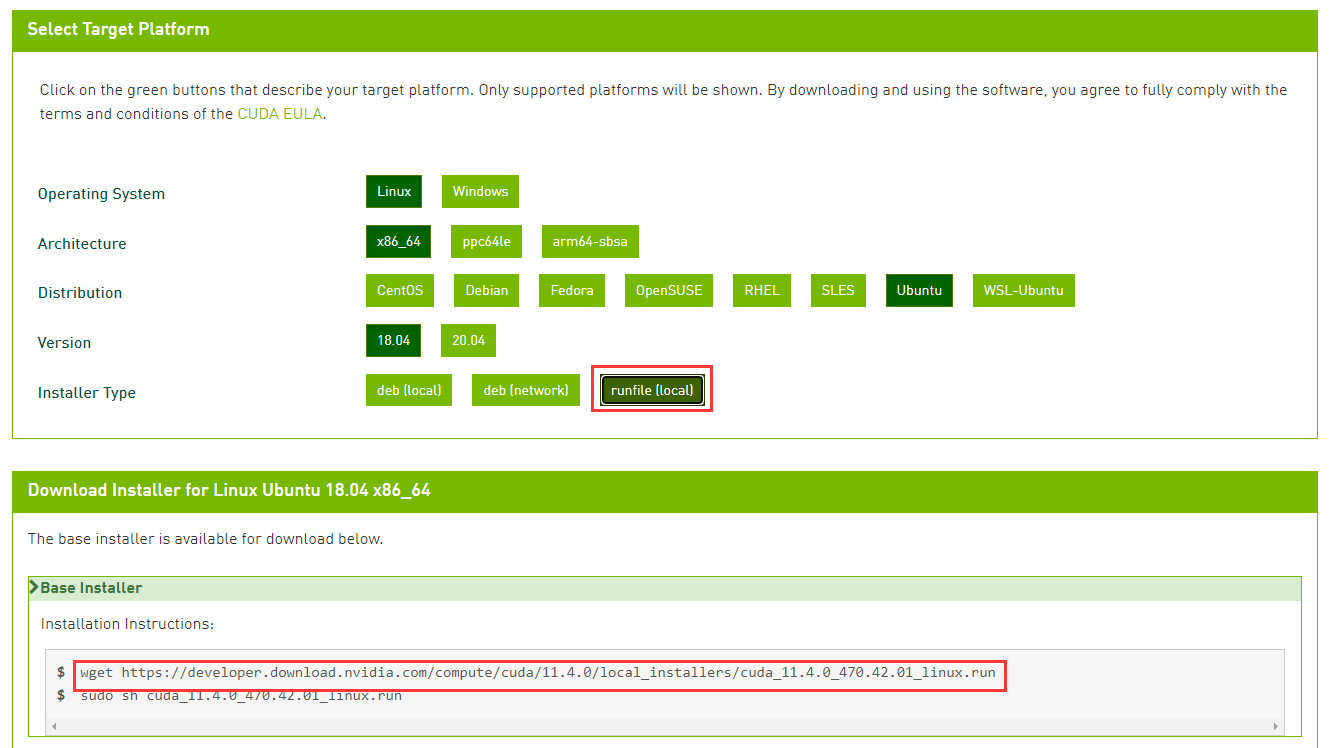
cuda的下载地址: https://developer.nvidia.com/cuda-toolkit-archive
使用指令wget -c XXX 将安装包下载到服务器上
cudnn的下载地址: https://developer.nvidia.com/rdp/cudnn-archive
注:由于下载cuDNN需要登录帐户,直接在终端用指令下载可能会失败,可以先在windows上注册个帐户下载好再上传到服务器。(使用MobaXterm等软件连接服务器后可以很方便地把windows上的文件通过拖动的方式上传到服务器上)
先执行下面的命令安装相关依赖,否则会出现 Missing recommended library 错误。
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
这时还可能报如下图错误

可以尝试执行 sudo apt-get update 和 sudo apt-get upgrade --fix-missing,如果报如下图错误或者还是无法安装相关依赖。
解决方案为手动下载或者更换软件源(我的选择)
(1)手动下载
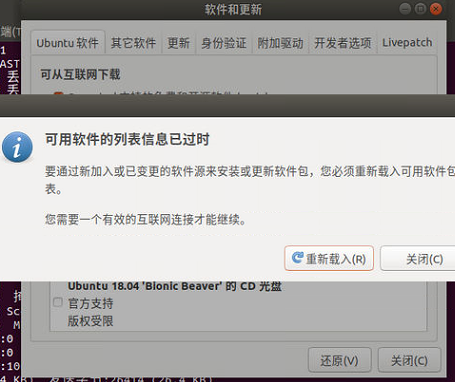
在使用上述方法后还是无法下载,出现的报错信息如下所示:

直接在浏览器中尝试打开无法下载的这个deb链接,自动弹出了下载页面,如下图所示:
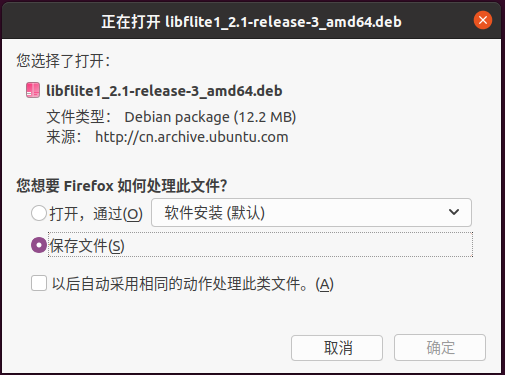
那就很简单了,直接下载保存,默认应该是直接下载到“下载”文件夹下了。然后,打开该文件所在目录,打开一个终端,执行如下命令,将下载的deb文件(依据自己包的名称进行修改)放到ubuntu apt-get下载文件存放的目录(即 /var/cache/apt/archives )下,这样在install的时候,就能被自动检测到了。
sudo mv libflite1_2.1-release-3_amd64.deb /var/cache/apt/archives
完成后,再次执行安装命令:
sudo apt install ffmpeg
如果显示页面载入出错,链接被重置等问题,如下图所示:

看下一个方法吧。
(2)更换软件源
如果链接真的不存在,那有可能是链接更新了,但是源里的链接没有同步更新了导致的。既然这个源行不通,那我们就换一个源试试。打开软件和更新,在ubuntu软件页面下,可以看到有下载自这个选项:
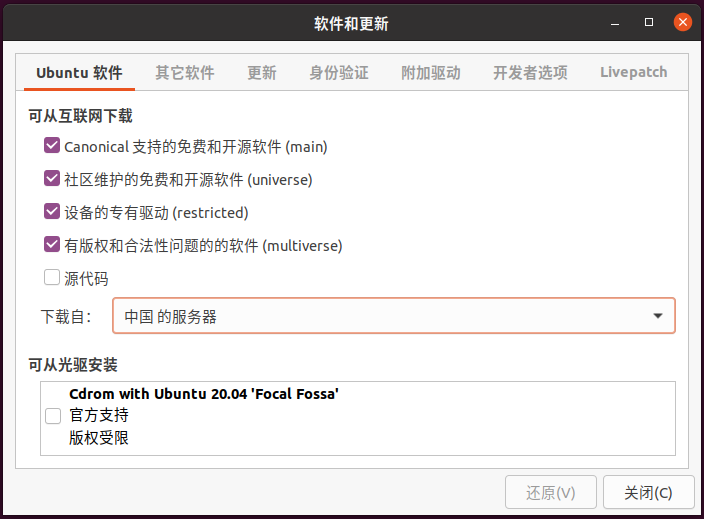
现在使用的源在这里名为“中国 的服务器”,点开下拉列表,选择其他站点,可以看到有很多选项:
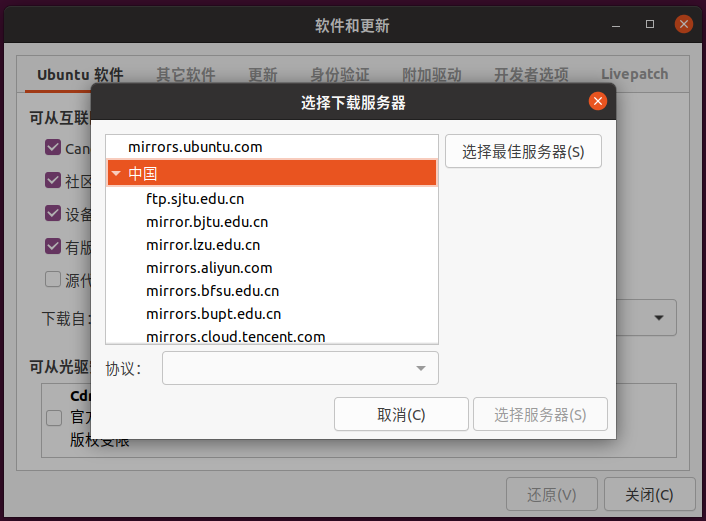
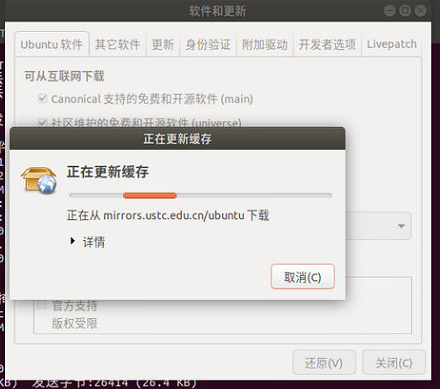
更换后在终端执行如下命令进行更新:sudo apt-get update
如果还是没法安装,就多换几次源尝试,总有一个适合你(当然也可能都不行,直接放弃)
回到正题,安装cuda
在安装包所在目录下输入指令 sudo sh XXX 进行安装,如:sudo sh cuda_11.4.0_470.42.01_linux.run
注:如图中一样选择就行。
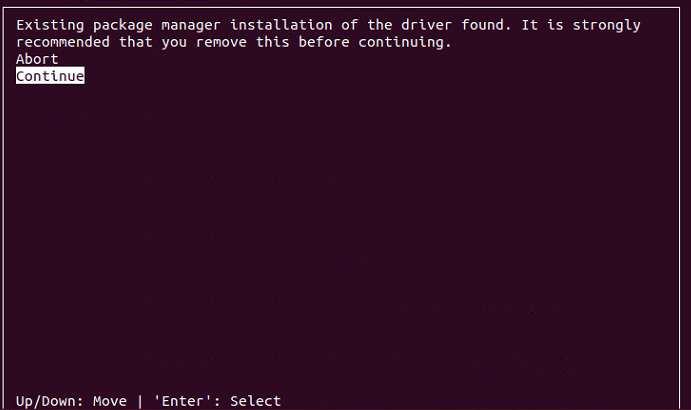
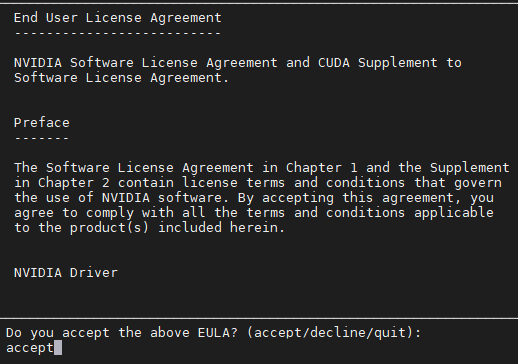
按空格根据需要选择要安装的模块,有“X”的表示安装,没有的表示不安装,我这里已经安装过418.116的显卡驱动了,所以选择不安装驱动 (最终的结果和此处的图一致,如果不一致请保持一致的选择):

按上下键移动到CUDA Toolkit 10.1上,然后按“A”键,出现:
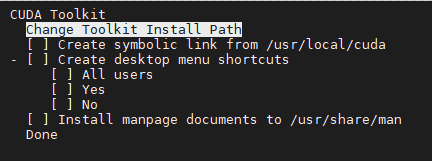
全部不安装并更改Toolkit Install Path:
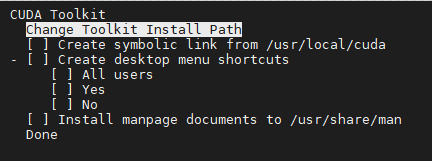
再返回主界面然后选择Options->Library install path:
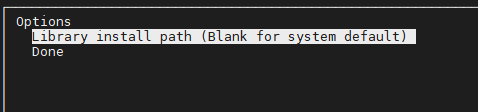

然后确定,返回选择Install
使用指令tar -xzvf /home/zb/cuda/cudnn-8.0-linux-x64-v7.1.tgz -C /home/zb/cuda/tem/ 将cuDNN解压到tem文件夹并执行以下指令
cp /home/zb/cuda/tem/cuda/include/cudnn.h /home/zb/cuda/cuda-8.0/include/
cp /home/zb/cuda/tem/cuda/lib64/libcudnn* /home/zb/cuda/cuda-8.0/lib64
chmod a+r /home/zb/cuda/cuda-8.0/include/cudnn.h /home/zb/cuda/cuda-8.0/lib64/libcudnn*
在安装了多个cuda版本后,可以在/usr/local/目录下查看自己安装的cuda版本。
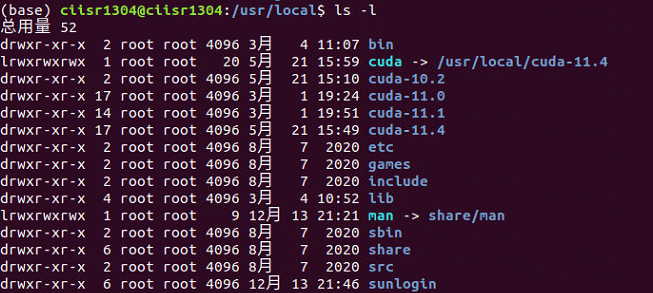
这里,cuda-11.0和cuda-11.4就是我们安装的两个cuda版本了,而cuda是一个软链接,它指向我们指定的cuda版本(注意上面在设置环境变量时,使用的是cuda,而不是cuda-11.0和cuda-11.4,这主要是为了方便我们切换cuda版本,可以让我们不用每次都去该环境变量的值)
可以使用stat命令查看当前cuda软链接指向的哪个cuda版本
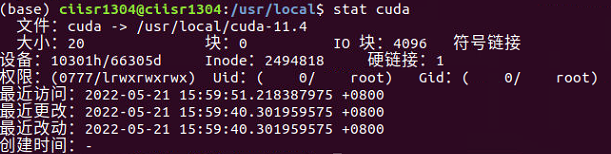
可以看到,文件类型是symbolic link,而指向的目录正是/usr/local/cuda-11.4,当我们想使用cuda-11.0版本时,只需要删除该软链接,然后重新建立指向cuda-11.0版本的软链接即可(注意名称还是cuda,因为要与bashrc文件里设置的保持一致)
sudo rm -rf cuda
sudo ln -s /usr/local/cuda-11.4 /usr/local/cuda
想切换其他版本的cuda,只需要改动建立软链接时cdua的正确路径即可。
(1)不使用上述的多个版本切换
修改个人用户目录下的.bashrc文件,sudo gedit ~/.bashrc
export PATH=/home/zb/cuda/cuda-8.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/home/zb/cuda/cuda-8.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
(2)使用上述的多个版本切换
修改个人用户目录下的.bashrc文件,sudo gedit ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
最后输入指令 source .bashrc 使新配置的环境变量生效.
查看cuda版本 : nvcc -V
查看位置 : which nvcc
查看NVIDIA动态使用情况: watch -n 1 nvidia-smi
cuda 版本 : cat /usr/local/cuda/version.txt
cudnn 版本 : cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
NVIDIA 驱动版本 : cat /proc/driver/nvidia/version
1,https://blog.csdn.net/hizengbiao/article/details/88625044
2,https://blog.csdn.net/ksws0292756/article/details/80120561
3,https://blog.csdn.net/qq_34638161/article/details/80845366
4,https://blog.csdn.net/ksws0292756/article/details/80120561
5,https://blog.csdn.net/weixin_44120025/article/details/122317808
6,https://www.cnblogs.com/Uni-Hoang/p/12901597.html
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我正在从erb文件切换到HAML。我将hamlgem添加到我的系统中。我创建了app/views/layouts/application.html.haml文件。我应该只删除application.html.erb文件吗?此外,仍然有/public/index.html文件被呈现为默认页面。我想创建自己的默认index.html.haml页面。我应该把它放在哪里以及如何使系统呈现该文件而不是默认索引文件?谢谢! 最佳答案 是的,您可以删除任何已转换为HAML的View的ERB版本。至于你的另一个问题,删除public/index/h
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(