Albert是A Lite Bert的缩写,确实Albert通过词向量矩阵分解,以及transformer block的参数共享,大大降低了Bert的参数量级。在我读Albert论文之前,因为Albert和蒸馏,剪枝一起被归在模型压缩方案,导致我一直以为Albert也是为了优化Bert的推理速度,但其实Albert更多用在模型参数(内存)压缩,以及训练速度优化,在推理速度上并没有提升。如果说蒸馏任务是把Bert变矮瘦,那Albert就是把Bert变得矮胖。正在施工中的文本分类库里也加入了Albert预训练模型,有在chinanews上已经微调好可以开箱即用的模型,同时支持半监督,领域迁移,降噪loss,蒸馏等模型优化项,感兴趣戳这里SimpleClassification
Albert主要有以下三点创新
下面我们分别介绍这三个部分
其实与其说是分解,个人觉得词向量重映射的叫法更合适一些。在之前BERT等预训练模型中,词向量的维度E和之后隐藏层的维度H是相同的,因为在Self-Attention的过程中Embedding维度是一直保持不变的,所以要增加隐藏层维度,词向量维度也需要变大。但是从包含的信息量来看,词向量本身只包含上下文无关的信息,并不需要像隐藏层一样存储大量的上下文语义,所以相同维度的限制在词向量部分存在一定的参数冗余。所以作者对词向量做了一层映射,词向量本身的参数变成Vocab * E,映射层是E* H,这样本身的复杂度O(Vocab * H),就降低成了O(Vocab * E + E*H ),相当于把隐藏层大小和词向量部分的参数做了解耦。
这个Trick其实之前在之前的NER系列中出现过多次,比如用在词表增强时,不同词表Embeeding维度的对齐,以及针对维度太高/太低的词表输入,进行适当的降维/升维等等~
以下作者分别对比了在参数共享/不共享的情况下,词向量维度E对模型效果的影响,从768压缩到64,非共享参数下有1个点的下降,共享参数时影响较小。这个在下面参数共享处会再提到,和模型整体能处理的信息量级有一定关系,整体上在共享参数的设定下词向量压缩影响有限~
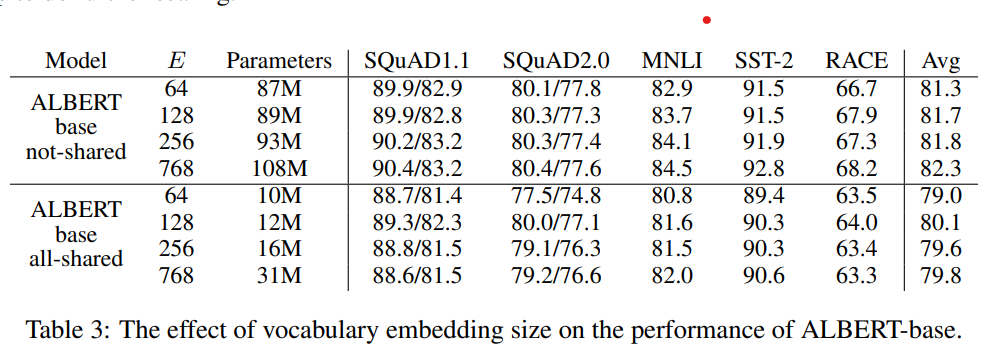
参数共享是ALbert提高参数利用率的核心。作者对比了各个block只共享Attention,只共享FFN,和共享所有参数,结果如下~
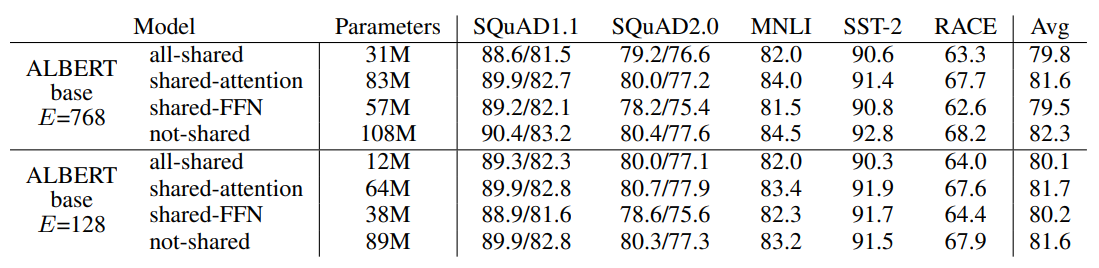
共享参数多少都会影响模型表现,其中效果损失主要来自共享FFN参数。以及在压缩词向量之后,共享参数带来的影响会降低。这里感觉和之前在做词表增强时观察到的现象有些相似,也就是模型的天花板受到输入层整体信息量的影响,因为压缩了词向量维度,限制了输入侧的信息量,模型需要处理的信息降低,从而参数共享带来的损失影响也被降低了
最终作者的选择更多是for最大程度压缩参数量级,share attenion缩减的参数有限,索性就共享了全部的参数。
在第三章讲到Roberta的时候,提到过Roberta在优化Bert的训练策略时,提出NSP任务没啥用在预训练中只使用了MLM目标。当时就提到NSP没有用一定程度上是它构造负样本的方式过于easy,NSP中连续上下文为正样本,从任意其他文档中采样的句子为负样本,所以模型可以简单通过topic信息来判断,而这部分信息基本已经被MLM任务学到。Albert改良了NSP中的负样本生成方式,AB为正样本,BA为负样本,模型需要判别论述的逻辑顺序和前后句子的合理语序。
作者也进行了对比,在预训练任务上,加入NSP训练的模型在SOP目标上和只使用MLM没啥区别,这里进一步证明了NSP并没有学到预期中的句子关联和逻辑顺序,而加入SOP训练的模型在NSP上表现要超过只使用MLM。在下游依赖上下文推理的几个任务上,加入SOP的模型整体表现略好。不过差异没有想象中的明显,感觉在如何构建负样本上应该还有优化的空间。个人感觉只是AB,BA的构造方式可能有些过于局部了

Albert在以上三点改良之外,在训练中也进行了一些优化,例如使用了SpanBert的MASK策略,用了LAMB optimizer来加速训练等等,Albert总共放出了以下几种参数的模型,和BERT之间的效果对比如下~
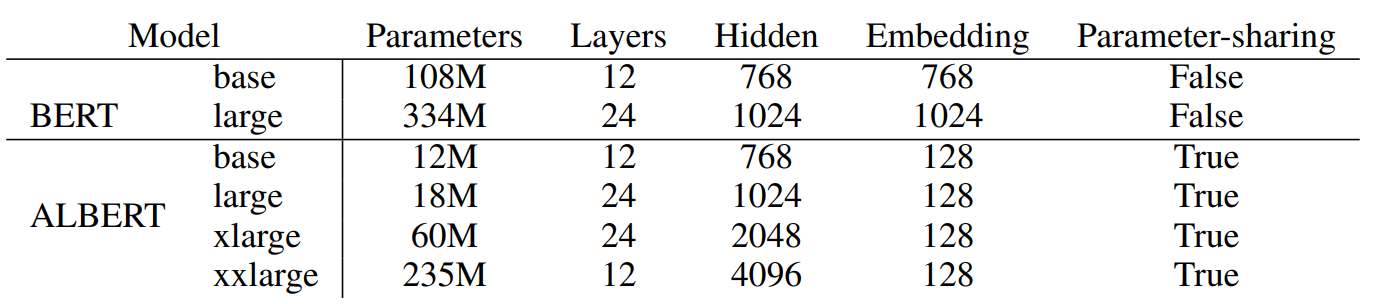
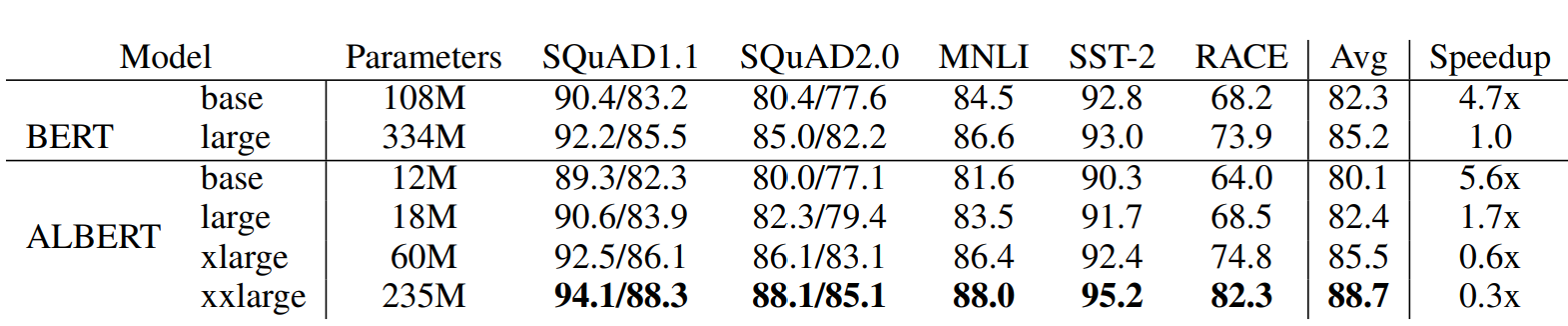
需要注意最后一列是训练速度的对比哈,哈哈之前看paper没带脑子,想都没想就给当成了推理速度,琢磨半天也没明白这为啥就快了???
所以整体感觉albert的实际应用价值比较有限,最常用的地方就是因为模型小,可以直接放在仓库里上传,对一些和外部交互不方便的场景,可以直接从内部加载模型,除此之外应用的地方比较少。不过ALbert提出的两个点还有进一步深挖的价值,其一NSP任务负样本是否有进一步改造的空间,其二如何更有效地利用Bert的参数?
BERT手册相关论文和博客详见BertManual
Reference
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
是否有任何可用于Ruby的开源压缩/解压库?有没有人实现过LZW?或者,是否有任何使用压缩组件的开源库可以提取出来独立使用?编辑——感谢您的回答!我应该提到我必须压缩的是只驻留在数据库中的长字符串(我不会压缩文件)。此外,如果可以执行此操作的任何库都具有用于客户端压缩/分解的等效JavaScript实现,那将是理想的,因为这将用于Web应用程序。 最佳答案 您会在rubystdlib下找到所有已交付的ruby库的一个很好的列表.我会使用zlib库,它是开放的,无处不在,您会发现几乎所有语言的库!
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
我有一个包含100多个zip文件的目录,我需要读取zip文件中的文件以进行一些数据处理,而无需解压缩存档。是否有一个Ruby库可以在不解压缩文件的情况下读取zip存档中的文件内容?使用rubyzip报错:require'zip'Zip::File.open('my_zip.zip')do|zip_file|#Handleentriesonebyonezip_file.eachdo|entry|#Extracttofile/directory/symlinkputs"Extracting#{entry.name}"entry.extract('here')#Readintomemoryc
在部署在heroku上的Rails应用程序(v:3.1)中,我在内存中获得了更多具有相同ID的对象。我的heroku控制台日志:>>Project.find_all_by_id(92).size=>2>>ActiveRecord::Base.connection.execute('select*fromprojectswhereid=92').to_a.size=>1这怎么可能?可能是什么问题? 最佳答案 解决方案根据您的SQL查询,您的数据库中显然没有重复条目。也许您的类项目中的size或length方法已被覆盖。我试过find_
我的两个不同的Rails应用程序的内存有一些奇怪的问题。这两个应用程序都使用rails3.0.7。每个Controller请求分配20-30-50MB的内存。在生产模式下,这个数量减少到5-10。但这是同样的事情。这是两个应用程序使用的gem列表:gem'pg'gem'haml'gem'sass'gem'devise'gem'simple_form'gem'state_machine'gem"globalize3","0.1.0.beta"gem"easy_globalize3_accessors"gem'paperclip'gem'andand'关闭所有这些gem不会给我任何结果。我
我有一个正在HerokuCedar堆栈上部署的Rails3.2应用程序。这意味着应用程序本身负责为其静态Assets提供服务。我希望对这些Assets进行gzip压缩,所以我在production.rb的中间件堆栈中插入了Rack::Deflater:middleware.insert_after('Rack::Cache',Rack::Deflater)...curl告诉我这与宣传的一样有效。但是,由于Heroku将全力运行rakeassets:precompile,生成一堆预gzipAssets,我很想使用它们(而不是让Rack::Deflater再次完成所有工作)。我已经看到使用