
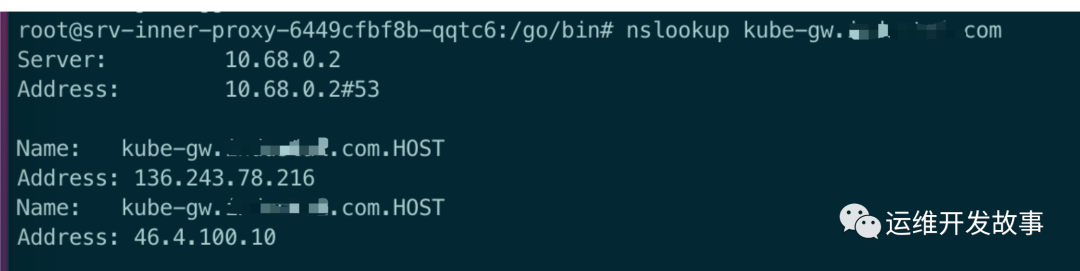
 进一步查看/etc/resolv.conf,发现搜索域中有一个HOST搜索域,因此解析域名会带上HOST
进一步查看/etc/resolv.conf,发现搜索域中有一个HOST搜索域,因此解析域名会带上HOST 又测试了几个域名,只要最后带HOST,都会解析到一个ip地址上,上网一搜,才知道这个HOST是个顶级域名,还会泛解析到某个ip上
又测试了几个域名,只要最后带HOST,都会解析到一个ip地址上,上网一搜,才知道这个HOST是个顶级域名,还会泛解析到某个ip上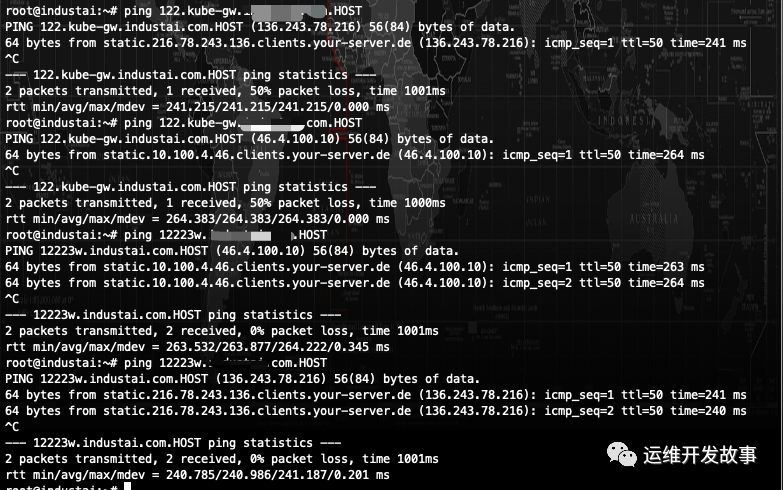 至此,导致本次故障的原因,已定位到,是由于pod中的搜索域中带了一个顶级域名HOST,产生的泛解析到了一个不是我们server端的地址上
至此,导致本次故障的原因,已定位到,是由于pod中的搜索域中带了一个顶级域名HOST,产生的泛解析到了一个不是我们server端的地址上cat /etc/resolv.conf
nameserver 10.68.0.2
search devops.svc.cluster.local. svc.cluster.local. cluster.local.
root-8-67:~# kubectl get svc -n kube-system |grep dns
kube-dns ClusterIP 10.68.0.2 <none> 53/UDP,53/TCP,9153/TCP 106d
curl b
// search 内容类似如下(不同的pod,第一个域会有所不同)
search devops.svc.cluster.local svc.cluster.local cluster.local
// curl b,可以一次性找到(b +devops.svc.cluster.local)
b.devops.svc.cluster.local
// curl b.devops,第一次找不到( b.devops + devops.svc.cluster.local)
b.devops.devops.svc.cluster.local
// 第二次查找( b.devops + svc.cluster.local),可以找到
b.devops.svc.cluster.local
// 1、找到容器ID,并打印它的NS ID
docker inspect --format "{{.State.Pid}}" 16938de418ac
// 2、进入此容器的网络Namespace
nsenter -n -t 54438
// 3、抓DNS包
tcpdump -i eth0 udp dst port 53|grep baidu.com
nslookup baidu.com 114.114.114.114
11:46:26.843118 IP srv-device-manager-7595d6795c-8rq6n.60857 > kube-dns.kube-system.svc.cluster.local.domain: 19198+ A? baidu.com.devops.svc.cluster.local. (49)
11:46:26.843714 IP srv-device-manager-7595d6795c-8rq6n.35998 > kube-dns.kube-system.svc.cluster.local.domain: 53768+ AAAA? baidu.com.devops.svc.cluster.local. (49)
11:46:26.844260 IP srv-device-manager-7595d6795c-8rq6n.57939 > kube-dns.kube-system.svc.cluster.local.domain: 48864+ A? baidu.com.svc.cluster.local. (45)
11:46:26.844666 IP srv-device-manager-7595d6795c-8rq6n.35990 > kube-dns.kube-system.svc.cluster.local.domain: 43238+ AAAA? baidu.com.svc.cluster.local. (45)
11:46:26.845153 IP srv-device-manager-7595d6795c-8rq6n.58745 > kube-dns.kube-system.svc.cluster.local.domain: 59086+ A? baidu.com.cluster.local. (41)
11:46:26.845543 IP srv-device-manager-7595d6795c-8rq6n.32910 > kube-dns.kube-system.svc.cluster.local.domain: 30930+ AAAA? baidu.com.cluster.local. (41)
11:46:26.845907 IP srv-device-manager-7595d6795c-8rq6n.55367 > kube-dns.kube-system.svc.cluster.local.domain: 58903+ A? baidu.com. (27)
11:46:26.861714 IP srv-device-manager-7595d6795c-8rq6n.32900 > kube-dns.kube-system.svc.cluster.local.domain: 58394+ AAAA? baidu.com. (27)
/prometheus $ cat /etc/resolv.conf
nameserver 10.66.0.2
search monitor.svc.cluster.local. svc.cluster.local. cluster.local.
options ndots:5
a.b.c.d.e.devops.svc.cluster.local. ->
a.b.c.d.e.svc.cluster.local. ->
a.b.c.d.e.cluster.local.
// 对域名 a.b.c.d.com 进行DNS解析请求
root-xxx-7595d6795c-8rq6n:/go/bin# nslookup a.b.c.d.com
Server: 10.68.0.2
Address: 10.68.0.2#53
** server can't find a.b.c.d.com: NXDOMAIN
// 抓包数据如下:
root-device-manager-7595d6795c-8rq6n:/go/bin# tcpdump -i eth0 udp dst port 53 -c 20 |grep a.b.c.d.com
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
20 packets captured16:14:40.053575 IP srv-device-manager-7595d6795c-8rq6n.37359 > kube-dns.kube-system.svc.cluster.local.domain: 29842+ A? a.b.c.d.com.cluster.local. (43)
16:14:40.054083 IP srv-device-manager-7595d6795c-8rq6n.34813 > kube-dns.kube-system.svc.cluster.local.domain: 19104+ AAAA? a.b.c.d.com.cluster.local. (43)
25 packets received by filter16:14:40.054983 IP srv-device-manager-7595d6795c-8rq6n.37303 > kube-dns.kube-system.svc.cluster.local.domain: 53902+ A? a.b.c.d.com.devops.svc.cluster.local. (51)
16:14:40.055465 IP srv-device-manager-7595d6795c-8rq6n.40766 > kube-dns.kube-system.svc.cluster.local.domain: 34453+ AAAA? a.b.c.d.com.devops.svc.cluster.local. (51)
0 packets dropped by kernel
16:14:40.055946 IP srv-device-manager-7595d6795c-8rq6n.35443 > kube-dns.kube-system.svc.cluster.local.domain: 24829+ A? a.b.c.d.com.svc.cluster.local. (47)
16:14:40.057698 IP srv-device-manager-7595d6795c-8rq6n.44180 > kube-dns.kube-system.svc.cluster.local.domain: 23046+ AAAA? a.b.c.d.com.svc.cluster.local. (47)
16:14:40.058062 IP srv-device-manager-7595d6795c-8rq6n.56986 > kube-dns.kube-system.svc.cluster.local.domain: 42008+ A? a.b.c.d.com. (29)
16:14:40.075579 IP srv-device-manager-7595d6795c-8rq6n.55738 > kube-dns.kube-system.svc.cluster.local.domain: 32284+ AAAA? a.b.c.d.com. (29)
// 结论:
// 点数少于5个,先走search域,最后将其视为绝对域名进行查询
// 对域名 a.b.c.d.e.com 进行DNS解析请求
root-xxx-7595d6795c-8rq6n:/go/bin# nslookup a.b.c.d.e.com
Server: 10.68.0.2
Address: 10.68.0.2#53
** server can't find a.b.c.d.e.com: NXDOMAIN
// 抓包数据如下:
root-device-manager-7595d6795c-8rq6n:/go/bin# tcpdump -i eth0 udp dst port 53 -c 20 |grep a.b.c.d.e.com
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:32:39.624305 IP srv-device-manager-7595d6795c-8rq6n.56274 > kube-dns.kube-system.svc.cluster.local.domain: 43582+ A? a.b.c.d.e.com. (31)
20 packets captured16:32:39.805470 IP srv-device-manager-7595d6795c-8rq6n.56909 > kube-dns.kube-system.svc.cluster.local.domain: 27206+ AAAA? a.b.c.d.e.com. (31)
16:32:39.833203 IP srv-device-manager-7595d6795c-8rq6n.33370 > kube-dns.kube-system.svc.cluster.local.domain: 14881+ A? a.b.c.d.e.com.cluster.local. (45)
21 packets received by filter16:32:39.833779 IP srv-device-manager-7595d6795c-8rq6n.40814 > kube-dns.kube-system.svc.cluster.local.domain: 43047+ AAAA? a.b.c.d.e.com.cluster.local. (45)
16:32:39.834363 IP srv-device-manager-7595d6795c-8rq6n.53053 > kube-dns.kube-system.svc.cluster.local.domain: 17994+ A? a.b.c.d.e.com.iot.svc.cluster.local. (53)
0 packets dropped by kernel16:32:39.834740 IP srv-device-manager-7595d6795c-8rq6n.47803 > kube-dns.kube-system.svc.cluster.local.domain: 15951+ AAAA? a.b.c.d.e.com.iot.svc.cluster.local. (53)
16:32:39.835177 IP srv-device-manager-7595d6795c-8rq6n.60845 > kube-dns.kube-system.svc.cluster.local.domain: 38541+ A? a.b.c.d.e.com.svc.cluster.local. (49)
16:32:39.835611 IP srv-device-manager-7595d6795c-8rq6n.36086 > kube-dns.kube-system.svc.cluster.local.domain: 49809+ AAAA? a.b.c.d.e.com.svc.cluster.local. (49)
// 结论:
// 点数>=5个,直接视为绝对域名进行查找,只有当查询不到的时候,才继续走 search 域。
nslookup a.b.c.com.
root-device-manager-7595d6795c-8rq6n:/go/bin# tcpdump -i eth0 udp dst port 53 -c 20 |grep a.b.c.com.
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:39:31.771615 IP srv-device-manager-7595d6795c-8rq6n.50332 > kube-dns.kube-system.svc.cluster.local.domain: 50829+ A? a.b.c.com. (27)
20 packets captured16:39:31.793579 IP srv-device-manager-7595d6795c-8rq6n.51946 > kube-dns.kube-system.svc.cluster.local.domain: 25235+ AAAA? a.b.c.com. (27)
...
spec:
containers:
- env:
- name: GOENV
value: DEV
image: xxx/devops/srv-inner-proxy
imagePullPolicy: IfNotPresent
lifecycle: {}
livenessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 8000
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
name: srv-inner-proxy
ports:
- containerPort: 80
protocol: TCP
- containerPort: 8000
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /health
port: 8000
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsConfig:
options:
- name: timeout
value: "2"
- name: ndots
value: "2"
- name: single-request-reopen
dnsPolicy: ClusterFirst
...
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\