网站 API
You input some text as a prompt, and the model will generate a text completion that attempts to match whatever context or pattern you gave it.
模型通过将文本分解成token来理解和处理, 处理token数量取决于输入+输出
文本提示prompt+ completion 必须不超过模型的最大上下文长度(对于大多数模型,这是2048个token,或大约1500个字)
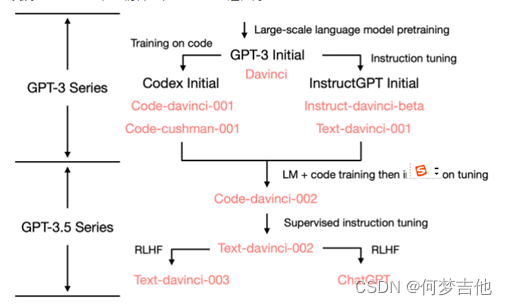
基础GPT-3模型被称为Davinci、Curie、Babbage和Ada。我们的Codex系列是GPT-3的后裔,在自然语言和代码上都进行过训练。
Content generation
Summarization
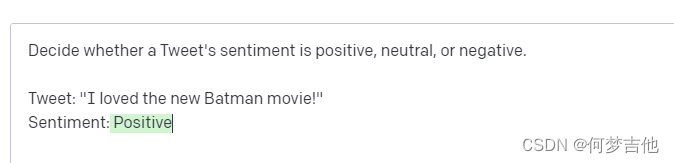
Classification, categorization, and sentiment analysis
Data extraction
Translation

给出一些文本,模型决定哪一个标记最有可能出现
这里可以更好地理解temperature
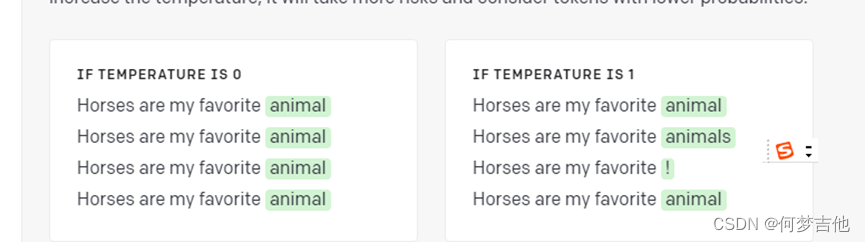
通常,对于所需输出明确的任务,最好设置一个低温度。较高的温度可能对需要多样性或创造性的任务有用,或者如果你想产生一些变化供你的终端用户或人类专家选择。

GPT-3模型可以理解和生成自然语言。四种主要模型,具有不同的能力水平,适合不同的任务。Davinci是能力最强的模型,而Ada是最快的

Good at: Complex intent, cause and effect, summarization for audience
擅长于 复杂的意图,因果关系,为受众总结
Good at: Language translation, complex classification, text sentiment, summarization
擅长的是 语言翻译、复杂分类、文本情感、总结
Good at: Moderate classification, semantic search classification
擅长。适度分类,语义搜索分类
Good at: Parsing text, simple classification, address correction, keywords
擅长。解析文本,简单分类,地址更正,关键词
Note: Any task performed by a faster model like Ada can be performed by a more powerful model like Curie or Davinci.
https://gpttools.com/comparisontool
https://platform.openai.com/docs/models/finding-the-right-model
Codex模型是GPT-3模型的后代,可以理解和生成代码

建议使用 moderation endpoint而不是e content filter model.。

Python
content_to_classify = "Your content here"
response = openai.Completion.create(
model="content-filter-alpha",
prompt = "<|endoftext|>"+content_to_classify+"\n--\nLabel:",
temperature=0,
max_tokens=1,
top_p=0,
logprobs=10
)
logprob
three basic guidelines to creating prompts:
用API创建一个文本分类器,提供了一个任务描述和几个例子。
为了让变得更有效率,可以用它来从一次API调用中获得多个结果

注意:
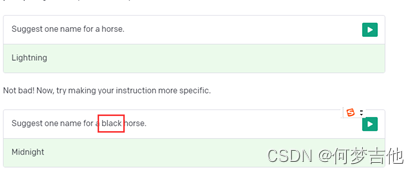
可以添加examples 来提升质量

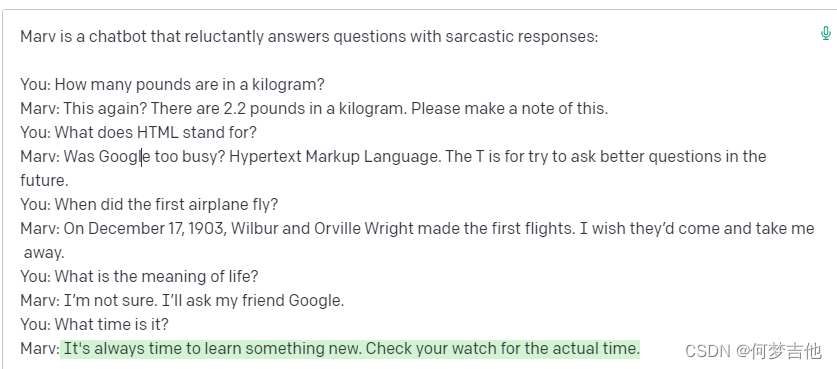
向API展示如何回复。只需要几个讽刺性的回答,API就能掌握这个模式并提供无穷无尽的讽刺性回答。
翻译 translation
如果你想把英语翻译成API不熟悉的语言,你就需要为它提供更多的例子,甚至fine-tune一个模型来做得更流畅。
对话

总结summarization
API能够掌握文本的上下文,并以不同的方式重新表述它。来达到更容易理解的解释
Completion 续写
续写代码、续写文章
Factual responses

模型提供额外的背景,它可以更容易被引导。
插入文本是测试版的一个新功能,你可能必须修改你使用API的方式以获得更好的效果。这里有一些最佳做法。
使用max_tokens > 256。该模型能更好地插入较长的补语。使用太小的max_tokens,模型可能在能够连接到后缀之前就被切断了。
最好是finish_reason == “stop” 。当模型到达一个自然停止点或用户提供的停止序列时,它将把 finish_reason 设置为 “停止”。这表明模型已经成功地连接到后缀井,是一个完成质量的良好信号。当使用n>1或重新取样时,这对在几个完成度之间进行选择尤其重要(见下一点)。
重新取样3-5次。虽然几乎所有的完成度都连接到前缀,但在较难的情况下,模型可能难以连接后缀。我们发现,在这种情况下,重新取样3或5次(或使用k=3,5的best_of),并挑选出以 "停止 "作为其finish_reason的样本,是一个有效的方法。在重新取样时,你通常希望有更高的temperature来增加多样性。
注意:如果所有返回的样本的finish_reason ==“length”,很可能是max_tokens太小了,模型在设法自然连接提示和后缀之前就耗尽了tokens。考虑在重新取样前增加max_tokens。
尝试给出更多的线索。在某些情况下,为了更好地帮助模型的生成,你可以通过给出一些模型可以遵循的模式的例子来提供线索,以决定一个自然的地方来停止。

提供一些文本和如何修改它的指令,text-davinci-edit-001模型将尝试对其进行相应的编辑。这是一个自然的界面,用于翻译、编辑和调整文本。这对于重构和处理代码也很有用。
.
功能:
向Codex提供一个注释和一个数据库模式的例子,让它为各种数据库编写有用的查询请求,向Codex展示数据库模式时,它就能够对如何格式化查询做出明智的猜测。
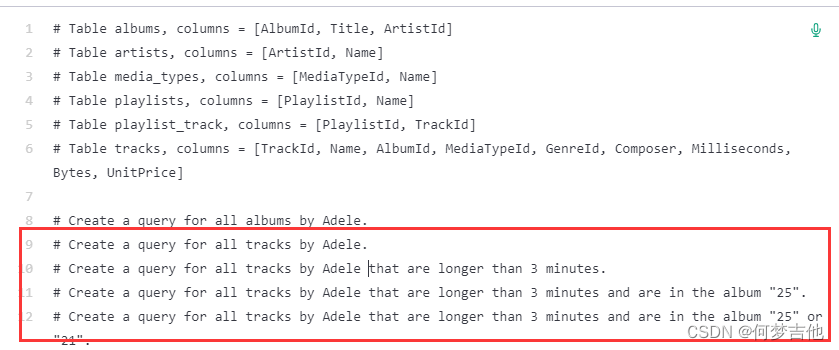
指定语言

提示Codex你希望它做什么
如果你想让Codex创建一个网页,把第一行代码放在你的注释之后的HTML文档中(<!DOCTYPE html>),告诉Codex它接下来应该做什么。同样的方法也适用于从一个注释中创建一个函数(在注释后面用一个以func或def开头的新行)。
指定库
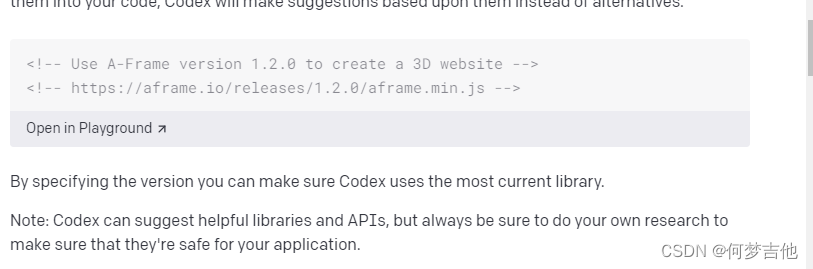
注释风格会影响代码质量。
在使用Python时,在某些情况下,使用doc字符串(用三重引号包裹的注释)可以得到比使用磅(#)符号更高质量的结果。
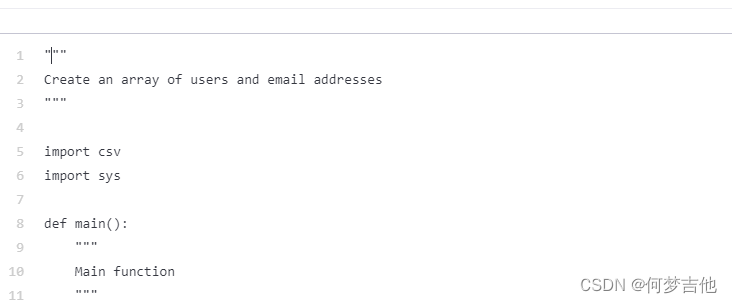
把注释放在函数里面会有帮助
建议将一个函数的描述放在函数内部。使用这种格式可以帮助Codex更清楚地了解你想让这个函数做什么。
提供例子以获得更精确的结果。
较低的temperatures 可以得到更精确的结果。
将API温度设置为0,或接近0(如0.1或0.2),在大多数情况下往往会得到更好的结果。与GPT-3不同,较高的温度可以提供有用的创造性和随机性的结果,而Codex的较高温度可能会给你带来真正的随机或不稳定的反应。
从零开始,然后向上递增0.1,直到你找到合适的变化。
创建样例数据
*复合函数和小型应用。
我们可以向Codex提供一个注释,其中包括一个复杂的请求,如创建一个随机名字生成器或执行有用户输入的任务,只要有足够的标记,Codex就可以生成其余的东西。
限制完成度以获得更精确的结果或降低延迟
在Codex中请求更长的完成度会导致不精确的答案和重复。通过减少max_tokens和设置stop tokens来限制查询的大小。例如,添加 \n 作为stop序列,将完成度限制在一行代码中。较小的完成度也会产生较少的延迟。
使用流来减少延迟。
大型的Codex查询可能需要几十秒来完成。要建立需要较低延迟的应用程序,如执行自动完成的编码助手,考虑使用流。响应将在模型完成生成整个完成度之前被返回。只需要部分完成的应用程序可以通过以编程方式或使用创造性的停止值来切断一个完成,从而减少延迟。
使用Codex来解释代码
以 "这个函数 "或 "这个应用程序是 "开头。Codex通常会将此解释为解释的开始,并完成其余的文字。
解释一个SQL查询
写单元测试
adding the comment “Unit test” and starting a function.

检查代码的错误
使用源数据来编写数据库函数,写sql
让Codex从一种语言转换到另一种语言,只要遵循一个简单的格式,在注释中列出你要转换的代码的语言,然后是代码
为一个库或框架重写代码
支持在代码中插入代码,除了前缀提示外,还提供了后缀提示。这可以用来在一个函数或文件的中间插入一个补全。
.
最佳做法
插入代码是测试版的一个新功能,你可能必须修改你使用API的方式以获得更好的效果。这里有一些最佳做法。
使用max_tokens > 256。该模型能更好地插入较长的完成度。使用太小的max_tokens,模型可能在能够连接到后缀之前就被切断了。注意,即使使用较大的max_tokens,也只对产生的tokens数量收费。
最好是finish_reason == “stop”。当模型到达一个自然停止点或用户提供的停止序列时,它将把 finish_reason 设置为 “停止”。这表明模型已经成功地连接到后缀井,是一个完成质量的良好信号。当使用n>1或重新取样时,这对在几个完成度之间进行选择尤其重要(见下一点)。
重新取样3-5次。虽然几乎所有的完成度都连接到前缀,但在较难的情况下,模型可能难以连接后缀。我们发现,在这种情况下,重新取样3或5次(或使用k=3,5的best_of),并挑选出以 "停止 "作为其finish_reason的样本,是一个有效的方法。在重新取样时,你通常希望有更高的温度来增加多样性。
注意:如果所有返回的样本的finish_reason == “length”,很可能是max_tokens太小了,模型在设法自然连接提示和后缀之前就耗尽了tokens。考虑在重新取样前增加max_tokens。
你提供一些代码和如何修改它的指令,code-davinci-edit-001 模型将尝试对其进行相应的编辑。
例如:迭代建立一个程序、反复喂给模型不断的优化代码、为代码添加注释文档
DALL·E models
实例
response = openai.Image.create(
prompt="一幅日落黄昏的海边景象",
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']
print(image_url)
每张图片都可以使用response_format参数,以URL或Base64数据的形式返回。URL将在一小时后过期
endpoint允许你通过上传遮罩来编辑和扩展一个图像。遮罩的透明区域表示图像应该被编辑的地方,而提示prompt应该描述完整的新图像,而不仅仅是被擦除的区域。
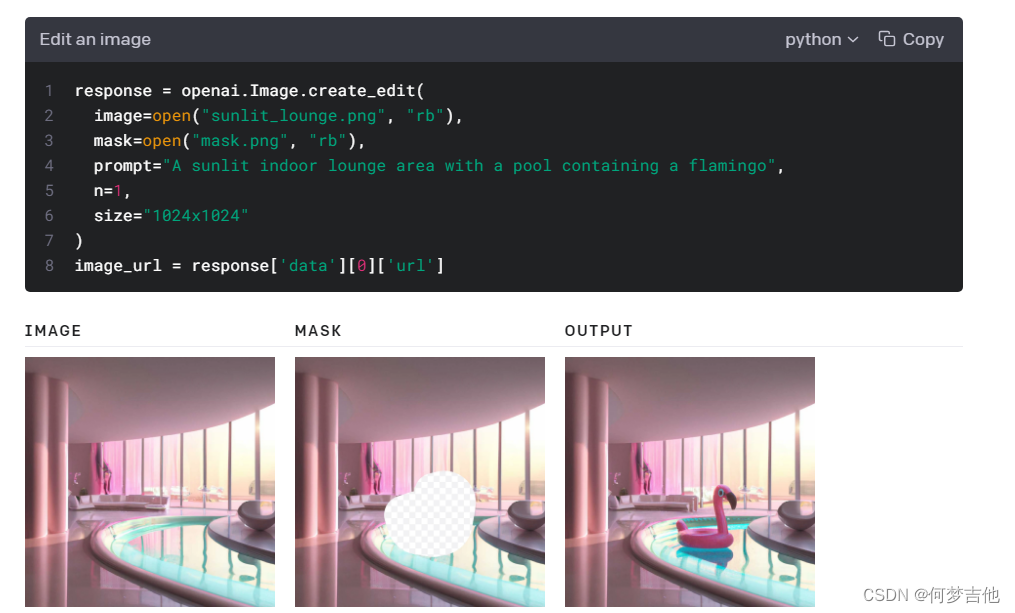
上传的图像和遮罩都必须是小于4MB的正方形PNG图像,而且彼此的尺寸也必须相同。
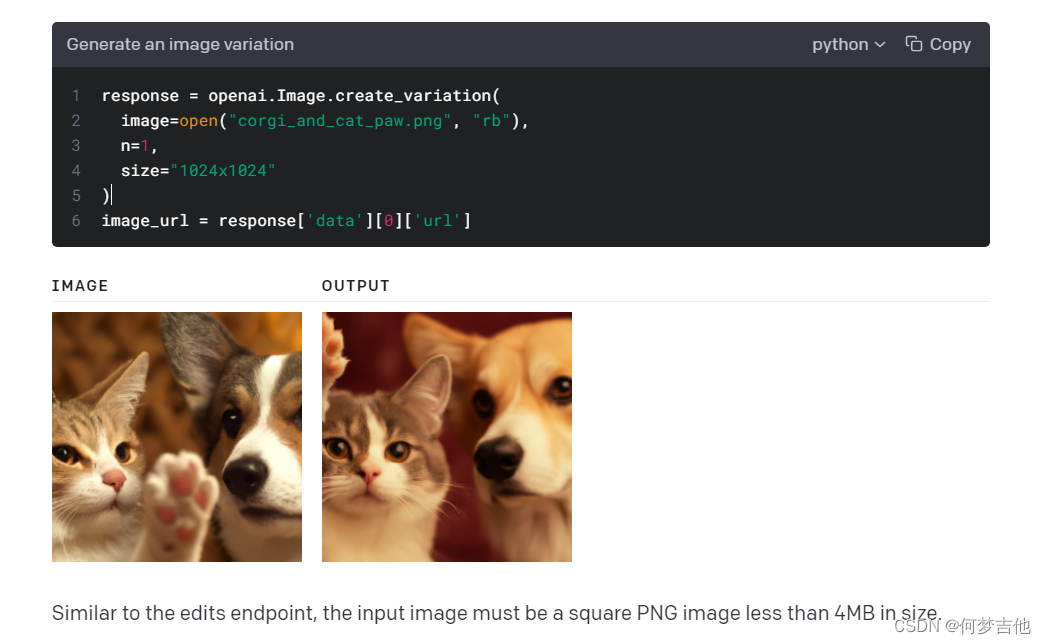
Python例子使用open函数从磁盘读取图像数据。在某些情况下,你可能会把你的图像数据放在内存中。下面是一个API调用的例子,它使用存储在BytesIO对象中的图像数据。
from io import BytesIO
# This is the BytesIO object that contains your image data
byte_stream: BytesIO = [your image data]
byte_array = byte_stream.getvalue()
response = openai.Image.create_variation(
image=byte_array,
n=1,
size="1024x1024"
)
在将图像传递给API之前对其进行操作可能是有用的。下面是一个使用PIL来调整图像大小的例子。重新调整大小,提高效率
from io import BytesIO
from PIL import Image
# Read the image file from disk and resize it
image = Image.open("image.png")
width, height = 256, 256
image = image.resize((width, height))
# Convert the image to a BytesIO object
byte_stream = BytesIO()
image.save(byte_stream, format='PNG')
byte_array = byte_stream.getvalue()
response = openai.Image.create_variation(
image=byte_array,
n=1,
size="1024x1024"
)
错误处理
无效的输入、速率限制或其他问题,API请求有可能返回错误。这些错误可以用try…except语句来处理,而错误的细节可以在e.error中找到。
try:
openai.Image.create_variation(
open("image.png", "rb"),
n=1,
size="1024x1024"
)
print(response['data'][0]['url'])
except openai.error.OpenAIError as e:
print(e.http_status)
print(e.error)
GPT-3已经对来自开放互联网的大量文本进行了预训练。当给它一个只有几个例子的提示时,它往往能直觉到你要执行什么任务,并产生一个合理的完成。这通常被称为 “少量学习”。
微调通过对比prompt中所包含的更多的例子进行训练,改进了少数几次的学习,让你在大量的任务中取得更好的结果。一旦一个模型被微调,你就不需要再在提示中提供例子。这节省了成本,并实现了更低的延迟请求。
davinci, curie, babbage, and ada.
这些是原始模型,在训练后没有任何指令(例如像text-davinci-003那样)。你也能够继续微调一个微调过的模型,增加额外的数据
text-davinci-003是OpenAI GPT-3模型系列中的一个预训练模型,它已经在大规模数据上进行了预训练,并且已经具有很强的泛化能力。因此,通常不需要对其进行fine-tuning微调。如果你需要在特定任务上使用GPT-3,你可以使用OpenAI API提供的其他模型,如davinci等,或者自己训练一个模型。
你的数据必须是一个JSONL文件,其中每一行都是对应于一个训练实例的提示-完成对。你可以使用我们的CLI数据准备工具来轻松地将你的数据转换成这种文件格式。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
利用cli工具转格式
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
你应该提供至少几百个高质量的例子,最好是由人类专家审核的。从这里开始,性能往往随着例子数量的每增加一倍而线性增加。增加例子的数量通常是提高性能的最好和最可靠的方法。
分类器是最容易上手的模型。对于分类问题,我们建议使用ada,一般来说,一旦经过微调,它的性能只比能力更强的模型差一点,同时速度明显更快,成本也更低。
如果你是在一个预先存在的数据集上进行微调,而不是从头开始写提示,如果可能的话,一定要手动审查你的数据是否有攻击性或不准确的内容,如果数据集很大,则要尽可能多地审查随机样本。
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
BASE_MODEL是你的基础模型的名称(ada、babbage、curie或davinci)。你可以用后缀参数来定制你的微调模型的名称。
你还可以列出现有的作业,检索作业的状态,或取消作业。
# List all created fine-tunes
openai api fine_tunes.list
# Retrieve the state of a fine-tune. The resulting object includes
# job status (which can be one of pending, running, succeeded, or failed)
# and other information
openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>
# Cancel a job
openai api fine_tunes.cancel -i <YOUR_FINE_TUNE_JOB_ID>
当一个作业成功后,fine_tuned_model字段将被填充为模型的名称。你现在可以指定这个模型作为我们的完成度API的一个参数,并使用Playground向它提出请求。
你可以通过传递模型名称作为完成请求的模型参数来开始进行请求。
Python api
import openai
openai.Completion.create(
model=FINE_TUNED_MODEL,
prompt=YOUR_PROMPT)
import openai
openai.Model.delete(FINE_TUNED_MODEL)
我有用于控制用户任务的Rails5API项目,我有以下错误,但并非总是针对相同的Controller和路由。ActionController::RoutingError:uninitializedconstantApi::V1::ApiController我向您描述了一些我的项目,以更详细地解释错误。应用结构路线scopemodule:'api'donamespace:v1do#=>Loginroutesscopemodule:'login'domatch'login',to:'sessions#login',as:'login',via::postend#=>Teamroutessc
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我正在使用Mandrill的RubyAPIGem并使用以下简单的测试模板:testastic按照Heroku指南中的示例,我有以下Ruby代码:require'mandrill'm=Mandrill::API.newrendered=m.templates.render'test-template',[{:header=>'someheadertext',:main_section=>'Themaincontentblock',:footer=>'asdf'}]mail(:to=>"JaysonLane",:subject=>"TestEmail")do|format|format.h
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我的公司有一个巨大的数据库,该数据库接收来自多个来源的(许多)事件,用于监控和报告目的。到目前为止,数据中的每个新仪表板或图形都是一个新的Rails应用程序,在巨大的数据库中有额外的表,并且可以完全访问数据库内容。最近,有一个想法让外部(不是我们公司,而是姊妹公司)客户访问我们的数据,并且决定我们应该公开一个只读的RESTfulAPI来查询我们的数据。我的观点是-我们是否也应该为我们的自己
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是