java调用python的契机来自于一个项目需要用到算法,但是算法工程师们写的python,于是就有了java后端调用python脚本的需求,中间遇到了许多问题,特此记录整理了一次。
专门为java调用python2开发出来的类库,但由于不支持python3版本,python2和3之间的语法又不兼容导致jpython库并非特别通用。github有人问到过什么时候出python3版本的库,官方答复说是可行的但很困难(截止2022年8月份 jpython官方目前没有开发出支持python3的类库)
jpython的语法特别简单,使用PythonIntercepter即可简单的操作python文件。
<dependency>
<groupId>org.python</groupId>
<artifactId>jython-standalone</artifactId>
<version>2.7.0</version>
</dependency>PythonInterpreter interpreter = new PythonInterpreter();
interpreter.execfile("C:\\Users\\Dick\\Desktop\\demo.py");
// 调用demo.py中的method1方法
PyFunction func = interpreter.get("method1",PyFunction.class);
Integer a = 10;
Integer b = 10;
PyObject pyobj = func.__call__(new PyInteger(a), new PyInteger(b));
System.out.println("获得方法的返回值 = " + pyobj.toString());注:如无返回值 仅执行interpreter.execfile()方法即可
ProcessBuilder是jdk提供的脚本执行工具类,无论是python文件还是shell脚本还是其他的指令,都可以通过此类来执行,我们来看看它是如何调用python脚本的
/**
* 执行python脚本
* @param fileName 脚本文件名称
* @param params 脚本参数
* @throws IOException
*/
public static void execPythonFile(String fileName, String params) throws IOException {
// 获取python文件所在目录地址
String windowsPath = ClassUtils.getDefaultClassLoader().getResource("").getPath().substring(1) + "py/";
// windows执行脚本需要使用 cmd.exe /c 才能正确执行脚本
Process process = new ProcessBuilder("cmd.exe", "/c", "python", windowsPath + fileName, params).start();
logger.info("读取python文件 开始 fileName={}", fileName);
BufferedReader errorReader = null;
// 脚本执行异常时的输出信息
errorReader = new BufferedReader(new InputStreamReader(process.getErrorStream()));
List<String> errorString = read(fileName, errorReader);
logger.info("读取python文件 异常 fileName={}&errorString={}", fileName, errorString);
// 脚本执行正常时的输出信息
BufferedReader inputReader = null;
inputReader = new BufferedReader(new InputStreamReader(process.getInputStream()));
List<String> returnString = read(fileName, inputReader);
logger.info("读取python文件 fileName={}&returnString={}", fileName, returnString);
try {
logger.info("读取python文件 wait fileName={}", fileName);
process.waitFor();
} catch (InterruptedException e) {
logger.error("读取python文件 fileName="+fileName+" 等待结果返回异常", e);
}
logger.info("读取python文件 fileName={} == 结束 ==", fileName);
}
private static List<String> read(String fileName, BufferedReader reader) {
List<String> resultList = Lists.newArrayList();
String res = "";
while (true) {
try {
if (!((res = reader.readLine()) != null)) break;
} catch (IOException e) {
logger.error("读取python文件 fileName=" + fileName + " 读取结果异常", e);
}
resultList.add(res);
}
return resultList;
}上述代码仅考虑了windows,而在Linux中情况会比较复杂一点。
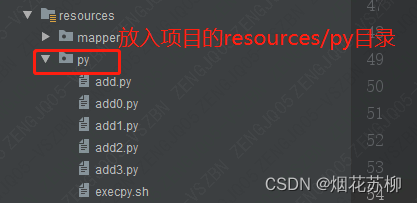
我们知道常规的项目部署是将项目打成jar包,然后直接放入Linux 或者通过docker等容器进行部署,这个时候resources下的py文件就在jar包里了,但我们执行python脚本时使用的是:
python3 脚本文件所在地此时python脚本在jar包里面,不能通过 jar路径/BOOT-INF/classes/py/xxx.py进行访问【我测试过一段时间 发现python3 (python指令也不行) 指令无法调用在jar里面的脚本】,所以我能想到的方案是将python脚本文件直接放入服务器的某个文件夹中,方便后续访问。如果是docker部署,只需要在dockerfile中加入一个COPY指令 将py文件放到指定目录下:
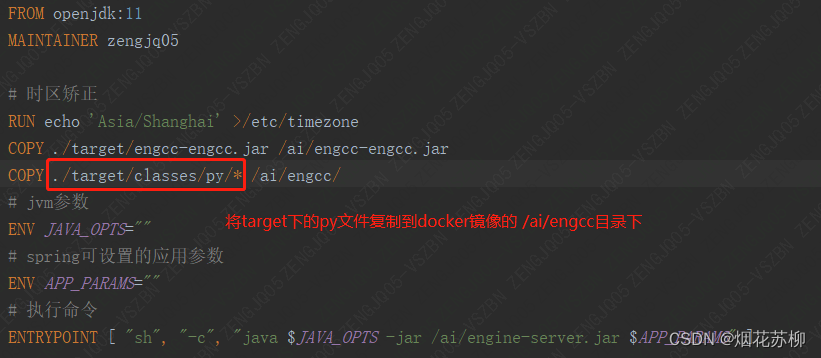
下面代码将兼容windows和linux调用py文件【Linux执行py文件是使用python还是python3根据实际py环境变量配置来选择就好】
/**
* 执行python文件
* @param fileName python文件地址
* @param params 参数 其实可以改成传入多个参数 一个个放入ProcessBuilder中的
* @throws IOException
*/
public static void execPythonFile(String fileName, String params) throws IOException {
// ① 当前系统类型
String os = System.getProperty("os.name");
// ② 获取python文件所在目录地址
String windowsPath = ClassUtils.getDefaultClassLoader().getResource("").getPath().substring(1) + "py/";
String linuxPath = "/ai/egcc/";
logger.info("读取python文件 init fileName={}&path={}", fileName);
Process process;
if (os.startsWith("Windows")){
// windows执行脚本需要使用 cmd.exe /c 才能正确执行脚本
process = new ProcessBuilder("cmd.exe", "/c", "python", windowsPath + fileName, params).start();
}else {
// linux执行脚本一般是使用python3 + 文件所在路径
process = new ProcessBuilder("python3", linuxPath + fileName, params).start();
}
logger.info("读取python文件 开始 fileName={}", fileName);
BufferedReader errorReader = null;
// 脚本执行异常时的输出信息
errorReader = new BufferedReader(new InputStreamReader(process.getErrorStream()));
List<String> errorString = read(fileName, errorReader);
logger.info("读取python文件 异常 fileName={}&errorString={}", fileName, errorString);
// 脚本执行正常时的输出信息
BufferedReader inputReader = null;
inputReader = new BufferedReader(new InputStreamReader(process.getInputStream()));
List<String> returnString = read(fileName, inputReader);
logger.info("读取python文件 fileName={}&returnString={}", fileName, returnString);
try {
logger.info("读取python文件 wait fileName={}", fileName);
process.waitFor();
} catch (InterruptedException e) {
logger.error("读取python文件 fileName="+fileName+" 等待结果返回异常", e);
}
logger.info("读取python文件 fileName={} == 结束 ==", fileName);
}
private static List<String> read(String fileName, BufferedReader reader) {
List<String> resultList = Lists.newArrayList();
String res = "";
while (true) {
try {
if (!((res = reader.readLine()) != null)) break;
} catch (IOException e) {
logger.error("读取python文件 fileName=" + fileName + " 读取结果异常", e);
}
resultList.add(res);
}
return resultList;
}以为这就完了吗,其实还没有呢,process.waitFor()方法其实存在一些问题,如果上线后可能会造成事故,具体参考:java调用exe程序 使用process.waitFor()死锁
那我们就尝试用线程池来解决死锁的问题吧
以下为终极版代码:
private static ExecutorService taskPool = new ThreadPoolExecutor(8, 32
,200L,TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(600)
,new ThreadFactoryBuilder()
.setNameFormat("thread-自定义线程名-runner-%d").build());
/**
* 执行python文件
* @param fileName python文件地址
* @param params 参数 多个直接逗号隔开
* @throws IOException
*/
public static void execPythonFile(String fileName, String params) throws IOException {
// ① 当前系统类型
String os = System.getProperty("os.name");
// ② 获取python文件所在目录地址
String windowsPath = ClassUtils.getDefaultClassLoader().getResource("").getPath().substring(1) + "py/";
String linuxPath = "/ai/egcc/";
logger.info("读取python文件 init fileName={}&path={}", fileName);
Process process;
if (os.startsWith("Windows")){
// windows执行脚本需要使用 cmd.exe /c 才能正确执行脚本
process = new ProcessBuilder("cmd.exe", "/c", "python", windowsPath + fileName, params).start();
}else {
// linux执行脚本一般是使用python3 + 文件所在路径
process = new ProcessBuilder("python3", linuxPath + fileName, params).start();
}
taskPool.submit(() -> {
logger.info("读取python文件 开始 fileName={}", fileName);
BufferedReader errorReader = null;
// 脚本执行异常时的输出信息
errorReader = new BufferedReader(new InputStreamReader(process.getErrorStream()));
List<String> errorString = read(fileName, errorReader);
logger.info("读取python文件 异常 fileName={}&errorString={}", fileName, errorString);
});
taskPool.submit(() -> {
// 脚本执行正常时的输出信息
BufferedReader inputReader = null;
inputReader = new BufferedReader(new InputStreamReader(process.getInputStream()));
List<String> returnString = read(fileName, inputReader);
logger.info("读取python文件 fileName={}&returnString={}", fileName, returnString);
});
try {
logger.info("读取python文件 wait fileName={}", fileName);
process.waitFor();
} catch (InterruptedException e) {
logger.error("读取python文件 fileName="+fileName+" 等待结果返回异常", e);
}
logger.info("读取python文件 fileName={} == 结束 ==", fileName);
}
private static List<String> read(String fileName, BufferedReader reader) {
List<String> resultList = Lists.newArrayList();
String res = "";
while (true) {
try {
if (!((res = reader.readLine()) != null)) break;
} catch (IOException e) {
logger.error("读取python文件 fileName=" + fileName + " 读取结果异常", e);
}
resultList.add(res);
}
return resultList;
}好了 上述代码已经可以正确的调用python脚本了,但博主目前仍然有些问题还没解决:比如如何调用java的jar包内部的py文件?在windows上的jar包内的py文件是可以调用成功的【我在windows本地启动jar包做过测试】,但是docker容器里面的jar却无法调用成功的原因是什么?
如果有朋友遇到问题欢迎在评论区留言和讨论
import com.google.common.collect.Lists;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import org.springframework.util.ClassUtils;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* java调用python的执行器
*/
@Component
public class PythonExecutor {
private static final Logger logger = LoggerFactory.getLogger(PythonExecutor.class);
private static final String OS = System.getProperty("os.name");
private static final String WINDOWS_PATH = ClassUtils.getDefaultClassLoader().getResource("").getPath().substring(1) + "py/automl/"; // windows为获取项目根路径即可
private static final String LINUX_PATH = "/ai/xx";// linux为python文件所在目录
private static ExecutorService taskPool = new ThreadPoolExecutor(8, 16
, 200L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(600)
, new ThreadFactoryBuilder()
.setNameFormat("thread-自定义线程名-runner-%d").build());
/**
* 执行python文件【异步 无需等待py文件执行完毕】
*
* @param fileName python文件地址
* @param params 参数
* @throws IOException
*/
public static void execPythonFile(String fileName, String params) {
taskPool.submit(() -> {
try {
exec(fileName, params);
} catch (IOException e) {
logger.error("读取python文件 fileName=" + fileName + " 异常", e);
}
});
}
/**
* 执行python文件 【同步 会等待py执行完毕】
*
* @param fileName python文件地址
* @param params 参数
* @throws IOException
*/
public static void execPythonFileSync(String fileName, String params) {
try {
execSync(fileName, params);
} catch (IOException e) {
logger.error("读取python文件 fileName=" + fileName + " 异常", e);
}
}
private static void exec(String fileName, String params) throws IOException {
logger.info("读取python文件 init fileName={}&path={}", fileName, WINDOWS_PATH);
Process process;
if (OS.startsWith("Windows")) {
// windows执行脚本需要使用 cmd.exe /c 才能正确执行脚本
process = new ProcessBuilder("cmd.exe", "/c", "python", WINDOWS_PATH + fileName, params).start();
} else {
// linux执行脚本一般是使用python3 + 文件所在路径
process = new ProcessBuilder("python3", LINUX_PATH + fileName, params).start();
}
new Thread(() -> {
logger.info("读取python文件 开始 fileName={}", fileName);
BufferedReader errorReader = null;
// 脚本执行异常时的输出信息
errorReader = new BufferedReader(new InputStreamReader(process.getErrorStream()));
List<String> errorString = read(fileName, errorReader);
logger.info("读取python文件 异常 fileName={}&errorString={}", fileName, errorString);
}).start();
new Thread(() -> {
// 脚本执行正常时的输出信息
BufferedReader inputReader = null;
inputReader = new BufferedReader(new InputStreamReader(process.getInputStream()));
List<String> returnString = read(fileName, inputReader);
logger.info("读取python文件 fileName={}&returnString={}", fileName, returnString);
}).start();
try {
logger.info("读取python文件 wait fileName={}", fileName);
process.waitFor();
} catch (InterruptedException e) {
logger.error("读取python文件 fileName=" + fileName + " 等待结果返回异常", e);
}
logger.info("读取python文件 fileName={} == 结束 ==", fileName);
}
private static void execSync(String fileName, String params) throws IOException {
logger.info("同步读取python文件 init fileName={}&path={}", fileName, WINDOWS_PATH);
Process process;
if (OS.startsWith("Windows")) {
// windows执行脚本需要使用 cmd.exe /c 才能正确执行脚本
process = new ProcessBuilder("cmd.exe", "/c", "python", WINDOWS_PATH + fileName, params).start();
} else {
// linux执行脚本一般是使用python3 + 文件所在路径
process = new ProcessBuilder("python3", LINUX_PATH + fileName, params).start();
}
taskPool.submit(() -> {
logger.info("读取python文件 开始 fileName={}", fileName);
BufferedReader errorReader = null;
// 脚本执行异常时的输出信息
errorReader = new BufferedReader(new InputStreamReader(process.getErrorStream()));
List<String> errorString = read(fileName, errorReader);
logger.info("读取python文件 异常 fileName={}&errorString={}", fileName, errorString);
});
taskPool.submit(() -> {
// 脚本执行正常时的输出信息
BufferedReader inputReader = null;
inputReader = new BufferedReader(new InputStreamReader(process.getInputStream()));
List<String> returnString = read(fileName, inputReader);
logger.info("读取python文件 fileName={}&returnString={}", fileName, returnString);
});
try {
logger.info("同步读取python文件 wait fileName={}", fileName);
process.waitFor();
} catch (InterruptedException e) {
logger.error("同步读取python文件 fileName=" + fileName + " 等待结果返回异常", e);
}
logger.info("同步读取python文件 fileName={} == 结束 ==", fileName);
}
private static List<String> read(String fileName, BufferedReader reader) {
List<String> resultList = Lists.newArrayList();
String res = "";
while (true) {
try {
if (!((res = reader.readLine()) != null)) break;
} catch (IOException e) {
logger.error("读取python文件 fileName=" + fileName + " 读取结果异常", e);
}
resultList.add(res);
}
return resultList;
}
}
===== 补充 =====
有小伙伴可能在别的博文上找到下面的java调用脚本方式
Runtime.getRuntime().exec()其实上面的脚本底层用的也是ProcessBuilder对象,所以是一样的。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta