前言:
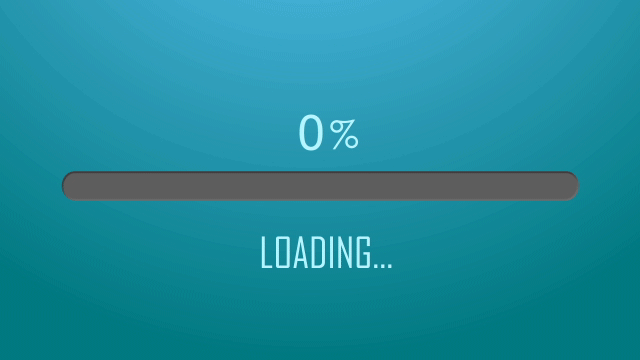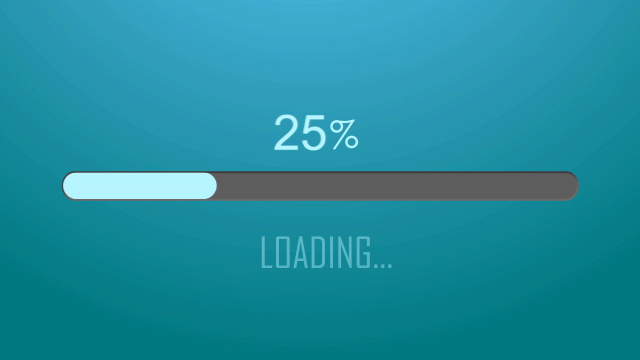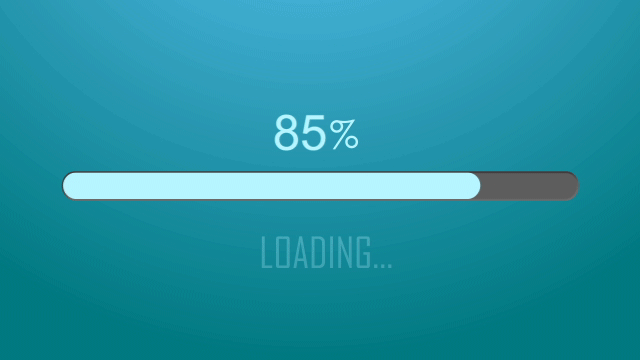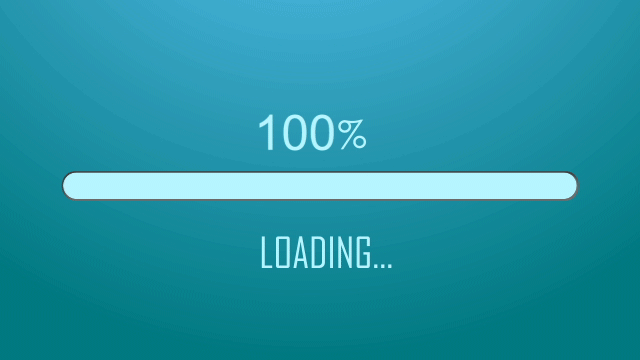
本文目录
在我们正式的写进度条之间,我先给大家理清一下这两个概念,带大家看看到底什么是
\r \n
在我们之前学习的 C语言中,有很多的字符。但是在宏观上大概可以分为两类字符,它们分别是:
不知道大家发现没有,不管是在我们日常敲代码又或者像我此时写文章的时候,当我们写完一行后若是没有 自动换行功能 此时就需要敲下键盘中的【Enter】键以此来达到换行的效果。可是对于这个按键,大家可能都认为就是简单的敲一下键盘上的一个键,但是实际上在计算机内部是做了两件事的,即 —— 【换行】+【回车】。具体如下:
此时可能就有点小伙伴会有疑惑,说不对呀!我之前写 C语言的时候就是 printf打印 \n 之后就可以了呀,你这里怎么说是有两部呢?
现在我们知道了进行“换行操作” 其实是经历过两步的。其实很早之前在我们的老式键盘上就已经体现出来了,不知道各位小伙伴有没有仔细观察过呢?

当我们知道现象后,接下来我们就需要去验证一下,看我所说的是否是真的。接下来,我写几行代码给大家演示一下
a)首先,我们的代码是先写出基础的【Makefile】,我们在创建一个【test.c】文件用来写代码
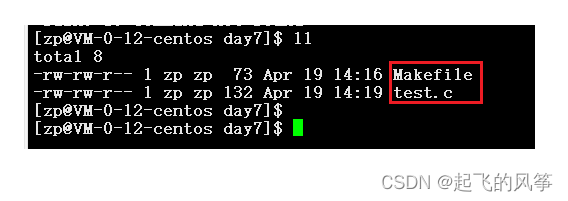
b)紧接着我们先写【Makefile】,同时在【test.c】文件中写入两行代码。具体如下:
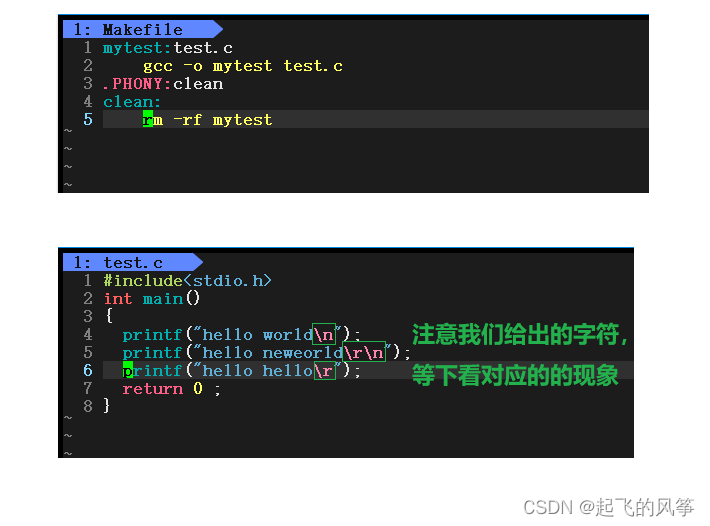
c)最后,我们可以执行这个程序,看最后的结果是如何的
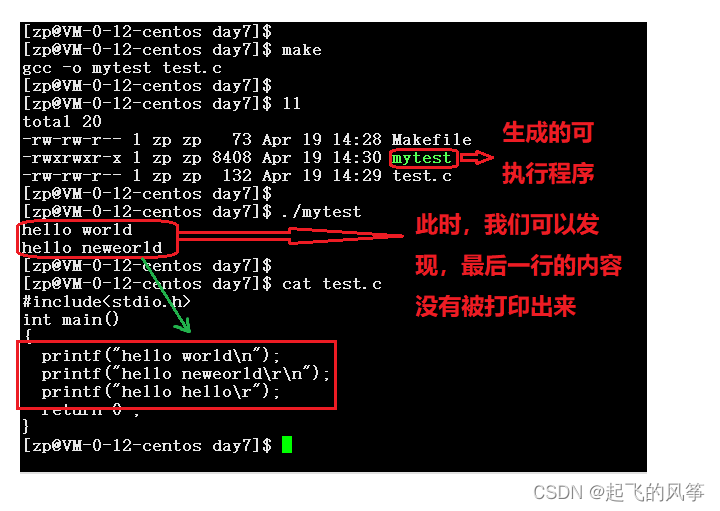
现象解释:
到此,具体的现象我就带大家看到了,原因我也给大家分析了。
因此,接下来我们将要学习的便是关于缓冲区的基本知识了!!!
那么当我们有了关于缓冲区的概念之后,此时我们就会想为什么会引入 “缓冲区” 这个概念呢?
举个简单的例子:
有了上述的基本认识之后,接下来我们通过简单的代码观察其中的现象,让大家有直观的感受,进而我们在深入探讨
sleep() 函数:——>睡眠
<unistd.h>中fflush()函数 ——> 刷新流
int fflush(FILE *stream);
还是以上述验证字符的代码为例,我给几段代码以及输出现象,大家先感受一下
a)代码
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 printf("hello world");
6
7 sleep(2);
8
9 return 0 ;
10 } 运行结果
现象描述:
b)代码
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 printf("hello world\n");
7 sleep(2);
8
9 return 0 ;
10 } 运行结果
现象描述:
sleep()函数,相当于在打印输出完之后让程序 “延迟” 2秒,然后才会显示【命令提示符】
c)代码
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 printf("hello world");
6 fflush(stdout);
7 sleep(2);
8
9 return 0 ;
10 } 运行结果
现象描述:
fflush() 这个函数,将其放在 sleep() 函数之前,也就相当于是优先刷新了一下缓冲流,此时就可以看到【hello world】立马先被打印了出来,等上2秒后才显示的【命令提示符】
d)代码
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 printf("hello world\r");
6
7 sleep(2);
8
9 return 0 ;
10 } 运行结果
现象描述:
\r 时,当开始执行后程序便开始睡眠, 然后在2秒睡眠后便直接打印出了【命令提示符】(注意:问题又来了哟!!!)
e)代码
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 printf("hello world\r");
6 fflush(stdout);
7 sleep(2);
8
9 return 0 ;
10 }
运行结果
现象描述:
fflush()刷新流,我们提前显示了一下需要打印的数据,此时就可以清晰的观察到,其实我们原本要打印的数据是在的,结果被【命令提示符】覆盖掉了
从上述的代码展示以及最后的结果我们提出了以下几个问题,分别是:
\n 时为何是先睡眠再打印?加上 \n 后数据会立刻显示出来,完成睡眠后才显示提示符?\r 后观察不到我们输出的数据。然而刷新一下就有了?
接下来,我会一一为大家解答上述疑惑!!!
缓冲区可以分为三种类型:全缓冲、行缓冲和不带缓冲
1、全缓冲
2、行缓冲
3、不带缓冲
当发生以下情况后,缓冲区将会执行刷新操作:
可见,缓冲区满或关闭文件时都会刷新缓冲区,进行真正的I/O操作。
另外,我们可以使用 fflush 函数来刷新缓冲区(执行I/O操作并清空缓冲区)
接下来,我就来回答一下上述我们提出的几个问题吧!
①不加换行符 \n时为何是先睡眠再打印?
sleep()函数的缘故,导致这个缓冲区没有被刷新而已,所以它并没有丢失
②加上\n后数据会立刻显示出来,完成睡眠后才显示提示符?
\n,数据都会被保存在缓冲区里。
③加上回车 \r后观察不到我们输出的数据。然而刷新一下就有了?
当我们领悟到上述所讲的知识之后,接下来我们先简单的实现一个——倒计时。
sleep(1)代码如下:
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 int i=9;
6 for(;i>=0; i--)
7 {
8 printf("%d\n",i);
9 sleep(1);
10 }
11
12 return 0 ;
13 }
运行结果如下:
上述就是最简单的倒计时实现了。但是这跟我们想象的似乎不一样啊是不是:
接下来我就带大家看看怎么实现:
代码如下:
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 int i=9;
6 for(;i>=0; i--)
7 {
8 printf("%d\r",i); //注意这里变为了\r
9 fflush(stdout);
10 sleep(1);
11 }
12
13 return 0 ;
14 }
此时我们再去查看最终的结果:
不知道大家觉得【0-9】和【0-10】这二者实现倒计时是否一样呢?其实是不一样的哟!!
结论:
00
那么我们要如何修改才会和上述的一样呢?
putc()这个函数将字符一一地打印在显示器上
我们可以像如下一样进行修改,即可实现我们上述的效果。
代码如下:
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 int i=10;
6 for(;i>=0; i--)
7 {
8 printf("%2d\r",i); //改为%2d
9 fflush(stdout);
10 sleep(1);
11 }
12 return 0 ;
13 }
运行结果:
到此,在这里就简单的实现出来了一个倒计时的“小玩具”。
有了以上的知识铺垫,接下来就到了实现 ——>进度条小程序的实现过程了!
首先,就是给大家先说明一下本次进度条我们最终呈现出来的样式是什么样的。
因为,Linux下不是图形化的,因此我们这里实现的进度条就不是大家所熟知的网上看见的那种形状。
首先,我先给出我们的进度条的大概样式,最后呈现出来的就是以下这种现象:
说明:
1.主体部分大概就是用个【】来进行概括,中间用 ## 这样的符号来表示我们的进度条的进度样式;
2.后一个【】则表示相应的进度情况;
3.因为我们是在Linux环境下,无法做到这种图形化界面。最后就是用旋转字符的样式来代替我们在 Windows下的缓冲的样式
在这里我们给出的是多文件这样的实现方案。因此在正式的上手之前,我们需要创建相应的文件来表示相应的代码。
先直接给出程序的大概框架,让大家先见见:
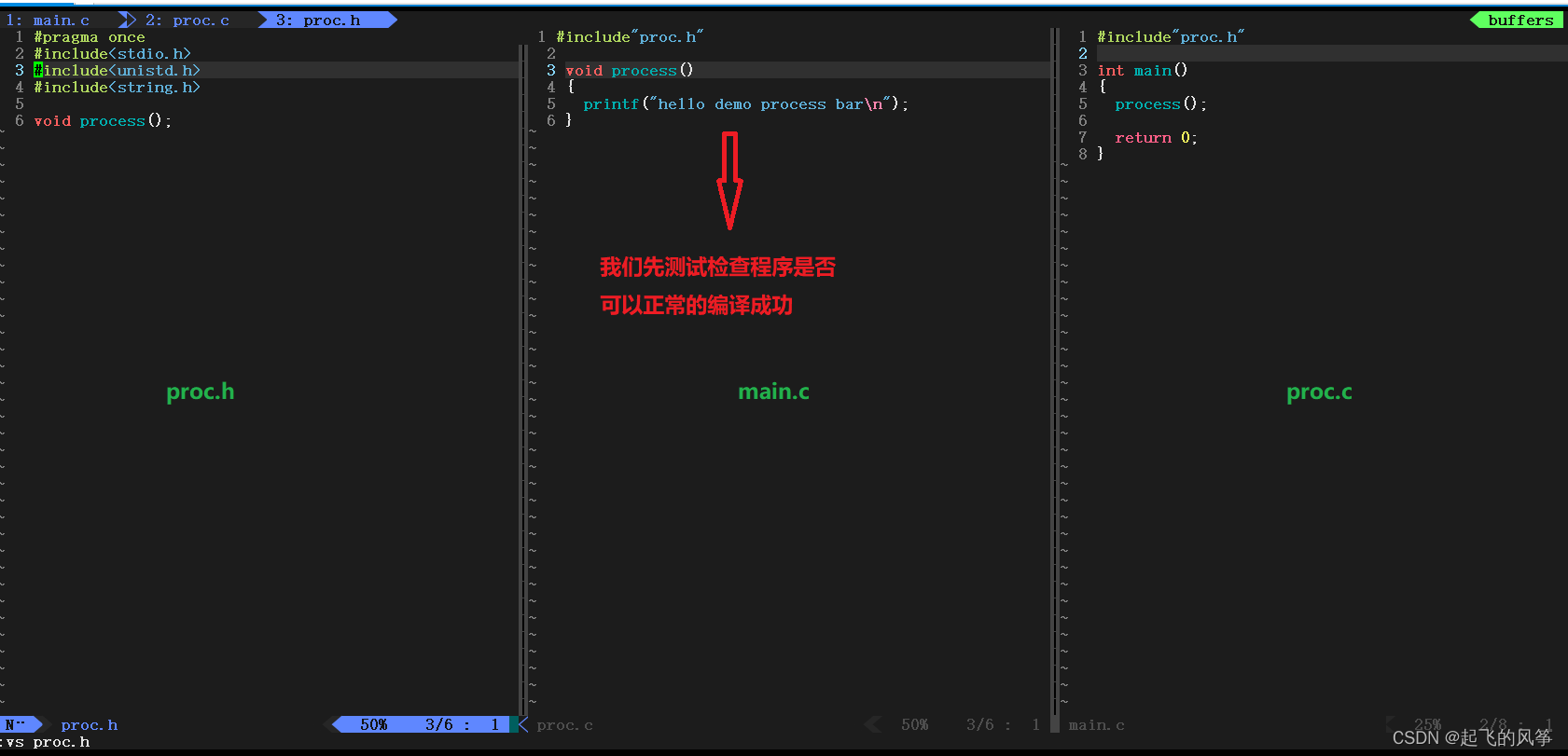
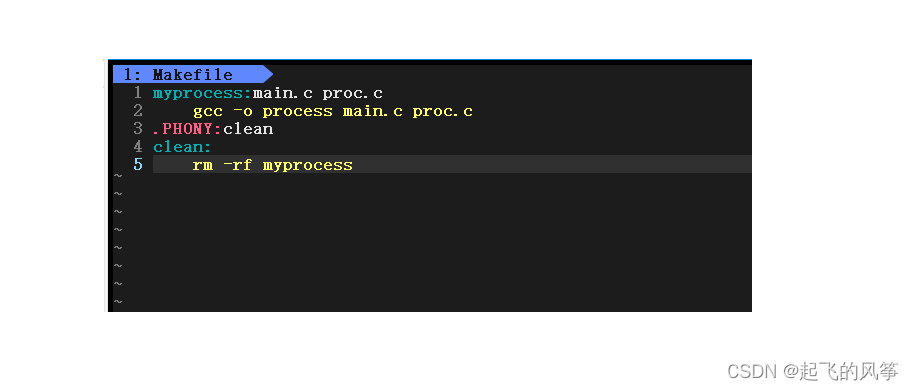
此时,可能好多小伙伴就会有疑惑,在创建的文件列表【Makefile】中只有 main.c和 proc.c 而没有头文件 proc.h 文件
gcc】的时候我大概提到过关于这个知识点。.c源文件中进行展开,因此加不加结果都是一样的。
第一步:
#define SIZE 101
解释说明:
第二步:
memset(bar, '\0', sizeof(bar));解释说明:
代码如下:
1 #include"proc.h"
2
3 #define SIZE 101
4
5 void process()
6 {
7 char bar[SIZE];
8
9 memset(bar,'\0',sizeof(bar));
10
11 int i=0;
12 while(i<+100)
13 {
14 printf("[%s]\n",bar);
15 bar[i++]='#';
16 sleep(1);
17 }
18 }
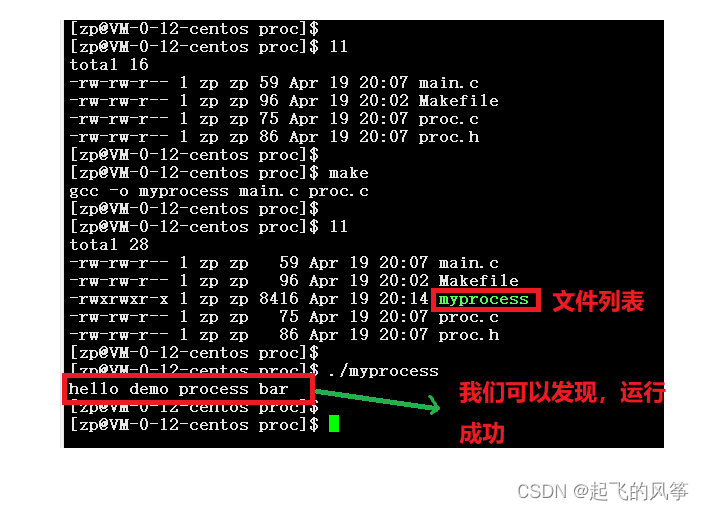
但是此时我们可以发现,这是不断的换行实现的,但是在我们的认知中进度条就是在 “一行 ”上实现的呀。因此,此时显然不符合我们的预期
当我们完成上述要求之后,紧接着来编译代码看最终的结果是不是我们期望的那样,具体如下:
1 #include"proc.h"
2
3 #define SIZE 101
4
5 void process()
6 {
7 char bar[SIZE];
8
9 memset(bar,'\0',sizeof(bar));
10
11 int i=0;
12 while(i<+100)
13 {
14 printf("[%s]\r",bar); //此时变为\r
15 bar[i++]='#';
16 sleep(1);
17 }
18 }
此时,出现了一个 “小坑” ,我们可以发现并没有显示出任何东西大家知道什么吗?
fflush(stdout);
不过此时有点小伙伴就会有这样一个问题,是什么呢?
答案是有的,此时有需要另外一个库函数了,那就是 【usleep】函数。

1 #include"proc.h"
2
3 #define SIZE 101
4 #define ARP '>'
5
6 void process()
7 {
8 char bar[SIZE];
9
10 memset(bar,'\0',sizeof(bar));
11
12 int i=0;
13 while(i<+100)
14 {
15 printf("[%s]\r",bar);
16 fflush(stdout);
17 bar[i++]='#';
18 usleep(100000); //变为usleep
19 }
20 }
主体的进度条预留出了一个100的空间,好呈现进度条从0 ~ 100的推进,就可以上面说到过的格式化占位符
printf("[%100s]\r", bar);
我们可以发现怎么是从反方向走的,这也不是符合我们的需求啊!
printf("[%-100s]\r", bar);
当然我们还可以实现更多的样式,例如假设我们要实现【===>】这样的,我们可以怎么操作呢?
1 #include"proc.h"
2
3 #define SIZE 102 //记住,此时当你加入的符号过多时,空间也应该随之变大
4 #define ARP '>'
5 #define STYLE '=' //我们在这里用宏定义样式,便于我们修改
6
7 void process()
8 {
9 char bar[SIZE];
10
11 memset(bar,'\0',sizeof(bar));
12
13 int i=0;
14 while(i<+100)
15 {
16 printf("[%-100s]\r",bar);
17 fflush(stdout);
18 bar[i++]= STYLE;
19 bar[i]=ARP;
20
21 usleep(100000);
22 }
23 }
实现完主体的框架之后,紧接着我们需要去实现一下百分比递增
1 #include"proc.h"
2
3 #define SIZE 102
4 #define ARP '>'
5 #define STYLE '='
6
7 void process()
8 {
9 char bar[SIZE];
10
11 memset(bar,'\0',sizeof(bar));
12
13 int i=0;
14 while(i<+100)
15 {
16 printf("[%-100s][%d]\r",bar,i); //我们只需在最后加上输出的值即可
17 fflush(stdout);
18 bar[i++]= STYLE;
19 if(i != 100) bar[i]=ARP;
20
21 usleep(100000);
22 }
23 }
但是此时我们可以发现,输出只是数字,并不是百分数啊!
到此,关于进度的实现便完成了。接下来就是关于缓冲功能了!!!
终于到了最后。马上就要揭开我们进度条的了 ”庐山真面目“了。
const】来修饰。
const char* label = "|/-\\";
printf("[%-100s][%d%%][%c]\r", bar, i , label[i % 4]);
运行如下:
到此,我们就实现了一个进度条小程序的设计。最终代码如下:
1 #include"proc.h"
2
3 #define SIZE 102
4 #define ARP '>'
5 #define STYLE '='
6
7 void process()
8 {
9 const char* label = "|/-\\";
10 char bar[SIZE];
11
12 memset(bar,'\0',sizeof(bar));
13
14 int i=0;
15 while(i<+100)
16 {
17 printf("[%-100s][%d%%][%c]\r", bar, i , label[i % 4]);
18 fflush(stdout);
19 bar[i++]= STYLE;
20 if(i != 100 )bar[i]=ARP;
21
22 usleep(100000);
23 }
24 }
到此,关于进度条小程序的所有知识便讲解完毕了!接下来,我们一起回顾一下
\n】与【\r】,知道了这两者的作用及功能;以上就是本文的所有知识,感谢各位的支持!!!

我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象