上篇说到RK3588编译OpenCV, 这篇记录一下跑通YOLO v5+DeepSORT的愉(chi)快(shi)历程.
如果本身缺少ffmpeg而编译了没有ffmpeg版本的OpenCV, 则视频无法读取.
解决方案参照CSDN, 首先安装ffmpeg:
sudo apt install -y ffmpeg
之后安装一堆dev:
libavcodec-dev 、libavformat-dev、libavutil-dev 、libavfilter-dev、 libavresample-dev、 libswresample-dev、 libswscale-dev
这个时候再去编译OpenCV, 可以看到ffmpeg的选项可以检测出版本了. (我没有做原博客将头文件加入/usr/include, 也是可以的).
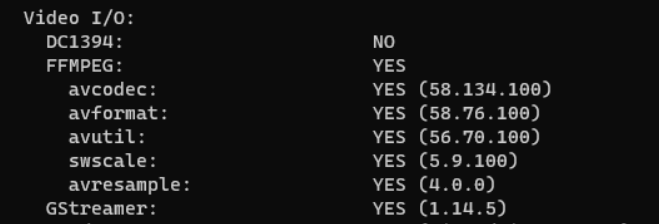
采用的代码是Zhou-sx大神的https://github.com/Zhou-sx/yolov5_Deepsort_rknn, 代码到手后, 要跑通自己的视频, 做如下改动:
在./CMakeLists.txt和./deepsort/CMakeLists.txt中, 更改
set(OpenCV_DIR /home/wjp/opencv-4.6.0/install/lib/cmake/opencv4) # 填入OpenCVConfig.cmake
后面的路径是OpenCV的OpenCVCondif.cmake的路径
在./include/common.h中修改IMG_WIDTH, IMG_HEIGHT, IMG_PAD, OBJ_CLASS_NUM, 例如:
#define BYTE unsigned char
#define IMG_WIDTH 1024
#define IMG_HEIGHT 540
#define IMG_CHANNEL 3
#define IMG_PAD 640
#define OBJ_CLASS_NUM 1
在./yolov5/src/decode.cpp中修改LABEL_NALE_TXT_PATH, 该txt储存的是视频中类别名称, 必须与 OBJ_CLASS_NUM对应:
#define LABEL_NALE_TXT_PATH "../model/hongwai_2_labels_list.txt"
例如只有一类car, 则txt的内容就是
car
在./yolov5_deepsort.cpp中, 更改模型, 读取视频与写入视频的路径. 模型必须是对应的rknn格式, 如何产生的以后补充.
string PROJECT_DIR = "/home/codes/yolov5_Deepsort_12_28";
string YOLO_MODEL_PATH = PROJECT_DIR + "/model/best.rknn";
string SORT_MODEL_PATH = PROJECT_DIR + "/model/osnet_x0_25_market.rknn";
string VIDEO_PATH = PROJECT_DIR + "/data/M1401.mp4";
string VIDEO_SAVEPATH = PROJECT_DIR + "/data/M1401_results.mp4";
cd build
cmake ..
make
./yolov5_deepsort
原来的代码有输出跟踪框漂移和没有处理检测框异常的功能, 我fork并完善了一下, 改善了这些问题, 减少了报错的可能. 并增加了如下功能, 欢迎star:
在
./yolov5/include/detect.h中 将
const int det_interval = 1;改成期望的数值, 例如3, 表示每隔3帧检测一次, 这样可以显著提升速度.
同时, 也需要更改./deepsort/include/deepsort.h中line 39的const int track_interval = 1;, 数值要和检测的保持一致.
如果您不希望使用多线程, 则在
./deepsort/src/deepsort.cpp中line 144的if (numOfDetections < 2)
改成if (true)
自己使用时, 除了更改OpenCV的路径外, 要在./include/common.h中修改IMG_WIDTH, IMG_HEIGHT, IMG_PAD, OBJ_CLASS_NUM
在./yolov5/src/decode.cpp中修改LABEL_NALE_TXT_PATH.
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
在许多ruby类之间共享记录器实例的最佳(正确)方法是什么?现在我只是将记录器创建为全局$logger=Logger.new变量,但我觉得有更好的方法可以在不使用全局变量的情况下执行此操作。如果我有以下内容:moduleFooclassAclassBclassC...classZend在所有类之间共享记录器实例的最佳方式是什么?我是以某种方式在Foo模块中声明/创建记录器还是只是使用全局$logger没问题? 最佳答案 在模块中添加常量:moduleFooLogger=Logger.newclassAclassBclassC..
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
在我的Rails项目中,我有三个模型:classRecipe:recipe_categorizationsaccepts_nested_attributes_for:recipe_categories,allow_destroy::trueendclassCategory:recipe_categorizationsendclassRecipeCategorization通过这个简单的has_many:through设置,我怎样才能像这样获取给定的食谱:@recipe=Recipe.first并根据现有类别向此食谱添加类别,并在相应类别上对其进行更新。所以:@category=#Exi
我有一个帖子属于城市的关系,城市又属于一个州,例如:classPost现在我想找到所有帖子及其所属的城市和州。我编写了以下查询来获取带有城市的帖子,但不知道如何在同一查找器中获取带有城市的相应州:@post=Post.find:all,:include=>[:city]感谢任何帮助。谢谢。 最佳答案 Post.all(:include=>{:city=>:state}) 关于ruby-on-rails-使用Rails事件记录获取二级模型,我们在StackOverflow上找到一个类似的问