 想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com首先感谢大家参与我们Arctic开源发布会。我是马进,网易数帆实时计算和湖仓一体团队负责人。我们在2020年开始关注数据湖新的技术,并用它来构建流批一体、湖仓一体的架构。最早我们使用Flink+Iceberg,但是实践过程中发现这个架构距离生产场景还有很大的gap,所以有了Arctic项目(github.com/NetEase/arctic)。
想了解更多关于开源的内容,请访问:51CTO 开源基础软件社区https://ost.51cto.com首先感谢大家参与我们Arctic开源发布会。我是马进,网易数帆实时计算和湖仓一体团队负责人。我们在2020年开始关注数据湖新的技术,并用它来构建流批一体、湖仓一体的架构。最早我们使用Flink+Iceberg,但是实践过程中发现这个架构距离生产场景还有很大的gap,所以有了Arctic项目(github.com/NetEase/arctic)。
 拿目前主流的数据湖Table format和Hive进行对比,Hive简单定义了表和HDFS上静态目录的映射关系,它本身是没有ACID的保障的,我们在真实的生产场景中只能单读单写。目前我们上层的数据中台或者是DataOps平台能够通过工作流的方式保障我们能正确使用Hive,当然只能用于离线场景。
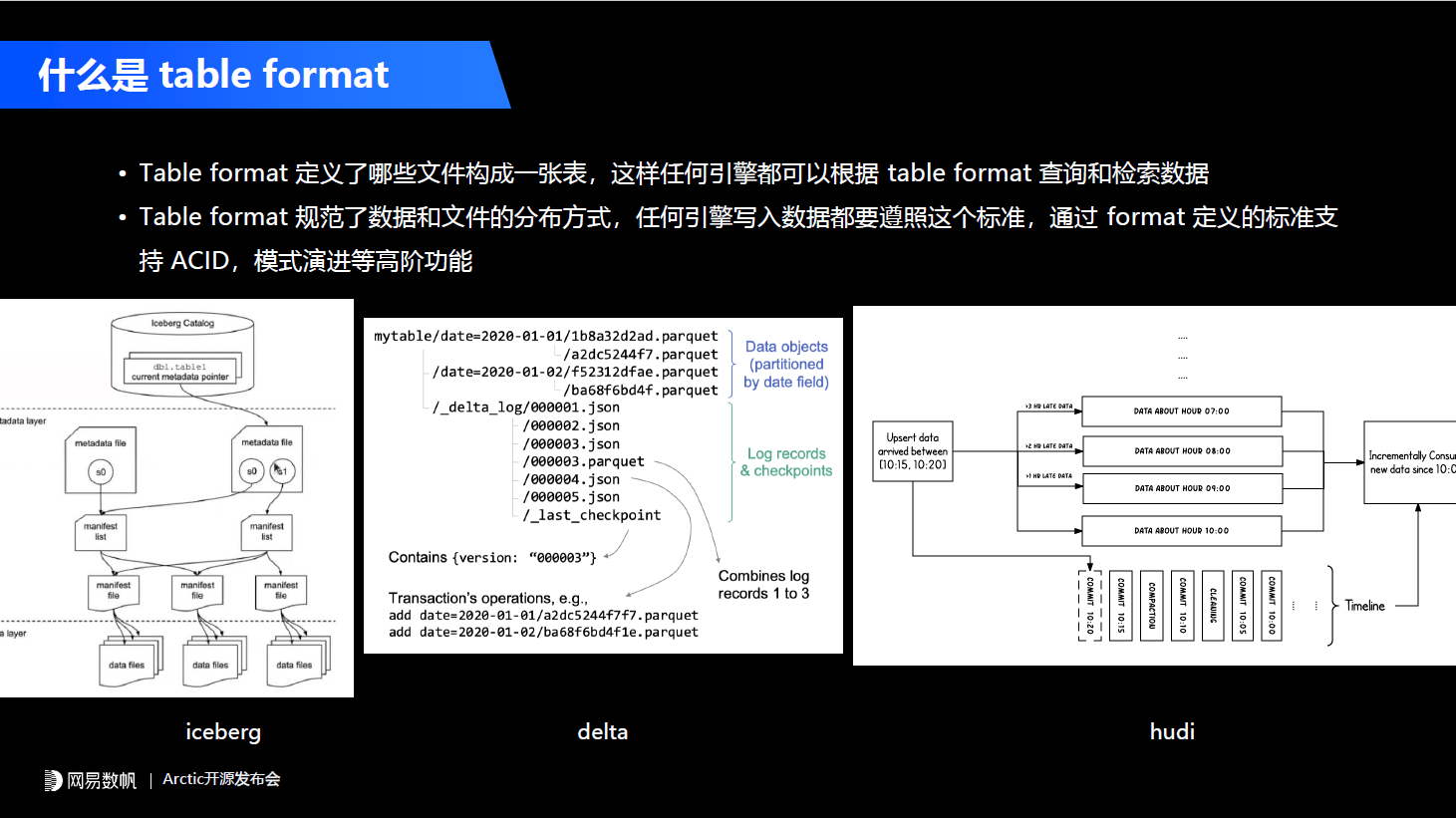
拿目前主流的数据湖Table format和Hive进行对比,Hive简单定义了表和HDFS上静态目录的映射关系,它本身是没有ACID的保障的,我们在真实的生产场景中只能单读单写。目前我们上层的数据中台或者是DataOps平台能够通过工作流的方式保障我们能正确使用Hive,当然只能用于离线场景。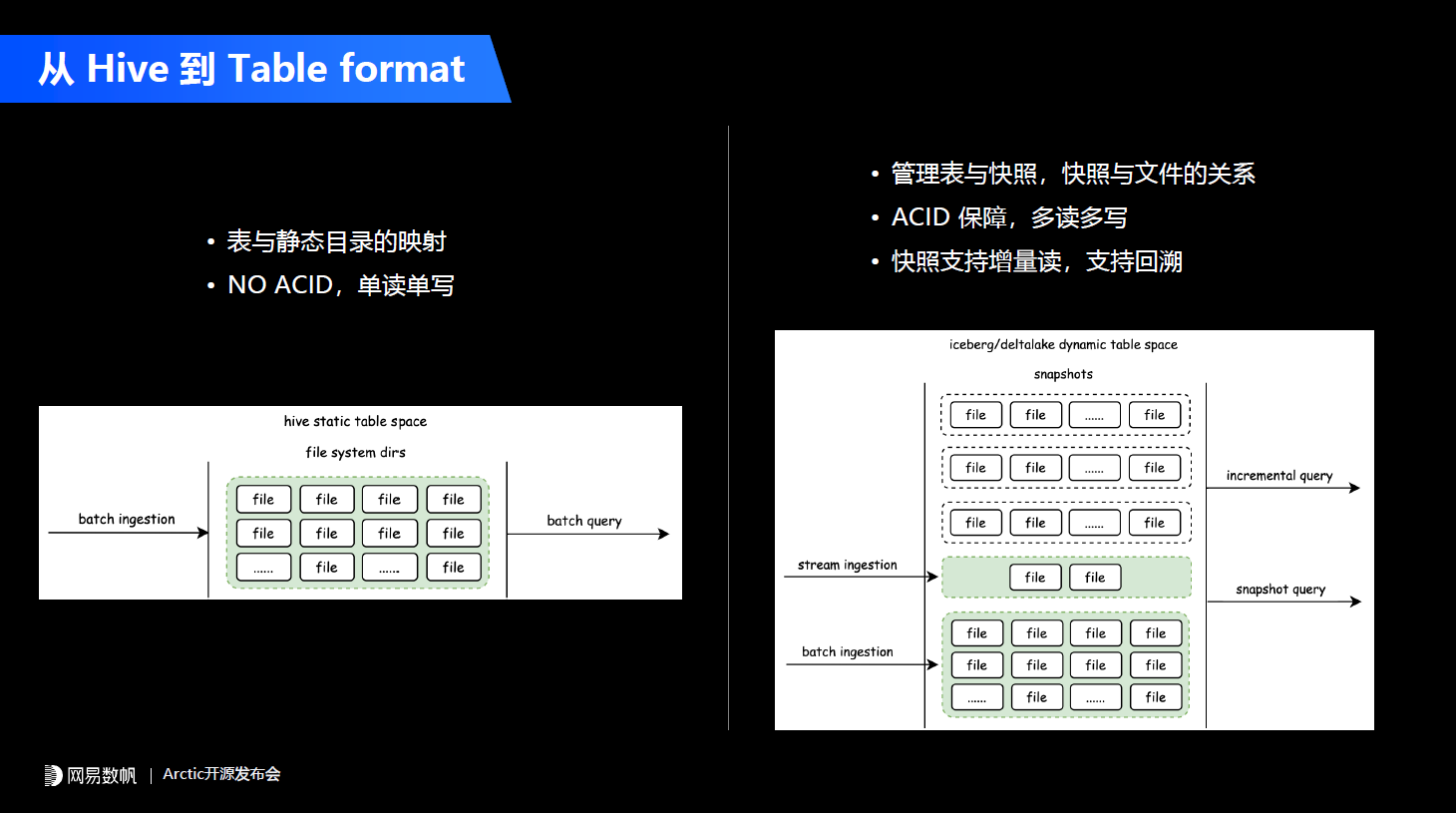 新的Iceberg、Delta、Hudi所主导的Table format能力中,增加了一个快照的概念,表的元数据不再是一个简单的表和文件的关系,变成了表和快照以及快照和文件的关系,数据的每次写入会产生新的快照,而这个快照和文件产生一个动态的映射关系,这样它能实现每次写入ACID的保障,也能通过快照的隔离实现用户的多读多写。而且基于快照也能给上层提供一些比较有意思的功能,比如说可以基于快照的增量写入实现增量读,也就是CDC的功能,可以通过快照去支持回溯,例如我们在time travel或者数据的rollback。总结下来Table format有四点核心特性。第一,结构自由。 像之前的Hive只能支持简单的加列操作,而在Delta、Iceberg这样的Table format之上用户可以自由地更改表的结构,可以加列、减列、改列,而且对数据的迁移和变更不会有要求。第二,读写自由。 因为它通过快照能够保证数据的ACID,任何实时、离线以及AI的需求都可以自由地往这个表里面写数据或者读数据。第三,流批同源。 因为Table format核心的一个功能是可以很好地支持流场景,我们的批和流都可以往新的Table format去写和读。第四,引擎平权。 这点非常重要,它不能只是绑定某一个引擎,比如说像Delta在1.0时代是Spark生态中的一个组件,在一个月之前Delta2.0的发布再次向我们证明了去适配多个引擎的重要性。在Table format这些项目的官网中,他们会主推一些功能主要包含CDC、SQL扩展,数据的Rollback,以及time travel,模式演进(Schema evolution)以及我们经常说的流式更新(Upsert)、读时合并(merge-on-read)的功能。CDC一定程度上能起到平替消息队列的作用,比如说在生产场景中,实时计算主要会用Kafka或者Pulsar做流表的选型。有了Table format之后,我们可以基于数据湖来实现类似于消息队列的功能,当然它的数据延迟会从毫秒或者秒级降级为分钟级别。像Upsert、读时合并和行业内或者说很多公司去推广数据湖的主要场景,就是拿这个实时更新以及读时合并去平替Apache Kudu、Doris、Greenplum这些实时更新的数仓系统。
新的Iceberg、Delta、Hudi所主导的Table format能力中,增加了一个快照的概念,表的元数据不再是一个简单的表和文件的关系,变成了表和快照以及快照和文件的关系,数据的每次写入会产生新的快照,而这个快照和文件产生一个动态的映射关系,这样它能实现每次写入ACID的保障,也能通过快照的隔离实现用户的多读多写。而且基于快照也能给上层提供一些比较有意思的功能,比如说可以基于快照的增量写入实现增量读,也就是CDC的功能,可以通过快照去支持回溯,例如我们在time travel或者数据的rollback。总结下来Table format有四点核心特性。第一,结构自由。 像之前的Hive只能支持简单的加列操作,而在Delta、Iceberg这样的Table format之上用户可以自由地更改表的结构,可以加列、减列、改列,而且对数据的迁移和变更不会有要求。第二,读写自由。 因为它通过快照能够保证数据的ACID,任何实时、离线以及AI的需求都可以自由地往这个表里面写数据或者读数据。第三,流批同源。 因为Table format核心的一个功能是可以很好地支持流场景,我们的批和流都可以往新的Table format去写和读。第四,引擎平权。 这点非常重要,它不能只是绑定某一个引擎,比如说像Delta在1.0时代是Spark生态中的一个组件,在一个月之前Delta2.0的发布再次向我们证明了去适配多个引擎的重要性。在Table format这些项目的官网中,他们会主推一些功能主要包含CDC、SQL扩展,数据的Rollback,以及time travel,模式演进(Schema evolution)以及我们经常说的流式更新(Upsert)、读时合并(merge-on-read)的功能。CDC一定程度上能起到平替消息队列的作用,比如说在生产场景中,实时计算主要会用Kafka或者Pulsar做流表的选型。有了Table format之后,我们可以基于数据湖来实现类似于消息队列的功能,当然它的数据延迟会从毫秒或者秒级降级为分钟级别。像Upsert、读时合并和行业内或者说很多公司去推广数据湖的主要场景,就是拿这个实时更新以及读时合并去平替Apache Kudu、Doris、Greenplum这些实时更新的数仓系统。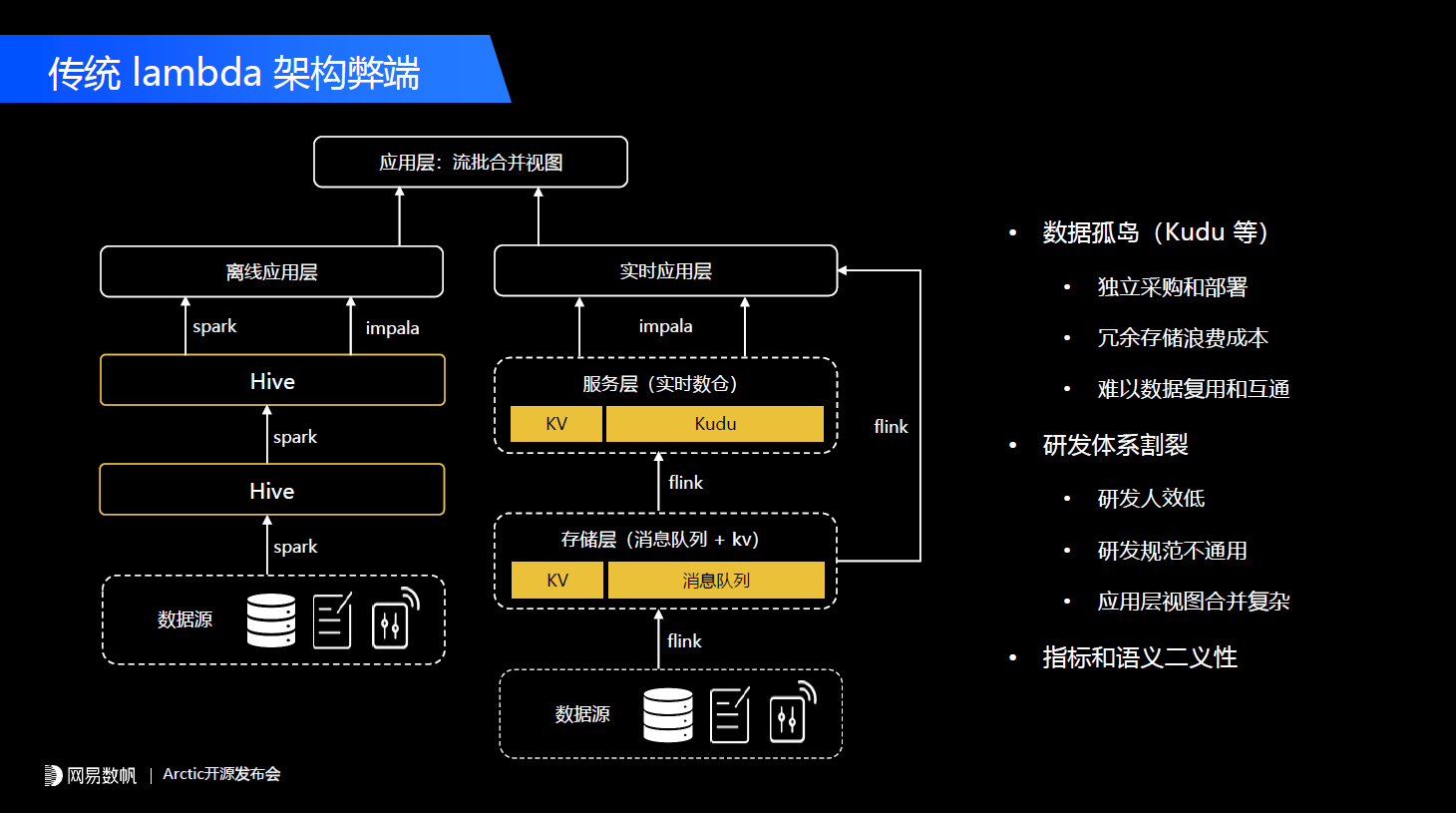 尤其是AI的一些业务,他们要做数据生产,其实更加关注数据训练、样本这些跟AI相关的流程本身,对HBase、KV这些他们是一概不了解的,所以他们会把需求提到另外一个团队,而另外一个团队只能点对点地去响应。总结一下传统Lambda架构给我们带来哪些弊端。第一是数据孤岛的问题。 如果我们使用Kudu或者其他跟数据湖割裂的一套数仓方案,会带来独立的采购和部署成本,会因为容易存储而浪费成本。因为数据之间难以复用和互通,如果我们在相同的业务场景下需要一个实时的数仓,可能需要从源头重新拉一份数据出来,导致成本和人效的浪费。第二是研发人效低,研发体系割裂,研发规范不通用。 这在AI特征、推荐的场景比较典型,需要用户自己去搞定什么时候调用实时的东西,什么时候调用离线的东西,会导致整个业务层非常复杂。最后是指标和语义的二义性问题。 比如过去几年我们主要是使用Kudu作为实时数仓方案,用户需要自己在Kudu里面建一个数仓表,会有Kudu的一套Schema,在Hive这边有一套通过数据模型创建的表,而这两套东西都需要用户自己去维护。当业务逻辑发生变更的时候,用户可能改了Hive但是没有改Kudu的,长久下来就会导致指标和语义的二义性问题。而且随着时间的推移,维护的成本会越来越高。所以业务期望的是什么呢?其实是我们在平台层,在整个数据中台层或者在整套数据的方法论这一层,能够用一套规范、一套流程把实时和离线,以及AI等更多的场景统一。所以我们回过头来看Lakehouse这个概念创造出来的意义,就是拓展产品的边界,让数据湖能更多地服务于流的场景、AI的场景。在我们的生产场景中,Lakehouse给业务最终带来的应当也是一个体系上的收益,而不在于说某一个功能上用了它。比如说我在CDC或者在分析的场景下用了,但是如果用户只是单纯地去比较Kudu和Hudi或者Iceberg之间的差异,他可能很难说到底带来什么样的收益;但是如果我们告诉用户说整套平台可以即插即用地把离线和实时全部统一掉,这个收益就很大了。基于这样一个目标,我们开发了流式湖仓服务Arctic这样一套系统。
尤其是AI的一些业务,他们要做数据生产,其实更加关注数据训练、样本这些跟AI相关的流程本身,对HBase、KV这些他们是一概不了解的,所以他们会把需求提到另外一个团队,而另外一个团队只能点对点地去响应。总结一下传统Lambda架构给我们带来哪些弊端。第一是数据孤岛的问题。 如果我们使用Kudu或者其他跟数据湖割裂的一套数仓方案,会带来独立的采购和部署成本,会因为容易存储而浪费成本。因为数据之间难以复用和互通,如果我们在相同的业务场景下需要一个实时的数仓,可能需要从源头重新拉一份数据出来,导致成本和人效的浪费。第二是研发人效低,研发体系割裂,研发规范不通用。 这在AI特征、推荐的场景比较典型,需要用户自己去搞定什么时候调用实时的东西,什么时候调用离线的东西,会导致整个业务层非常复杂。最后是指标和语义的二义性问题。 比如过去几年我们主要是使用Kudu作为实时数仓方案,用户需要自己在Kudu里面建一个数仓表,会有Kudu的一套Schema,在Hive这边有一套通过数据模型创建的表,而这两套东西都需要用户自己去维护。当业务逻辑发生变更的时候,用户可能改了Hive但是没有改Kudu的,长久下来就会导致指标和语义的二义性问题。而且随着时间的推移,维护的成本会越来越高。所以业务期望的是什么呢?其实是我们在平台层,在整个数据中台层或者在整套数据的方法论这一层,能够用一套规范、一套流程把实时和离线,以及AI等更多的场景统一。所以我们回过头来看Lakehouse这个概念创造出来的意义,就是拓展产品的边界,让数据湖能更多地服务于流的场景、AI的场景。在我们的生产场景中,Lakehouse给业务最终带来的应当也是一个体系上的收益,而不在于说某一个功能上用了它。比如说我在CDC或者在分析的场景下用了,但是如果用户只是单纯地去比较Kudu和Hudi或者Iceberg之间的差异,他可能很难说到底带来什么样的收益;但是如果我们告诉用户说整套平台可以即插即用地把离线和实时全部统一掉,这个收益就很大了。基于这样一个目标,我们开发了流式湖仓服务Arctic这样一套系统。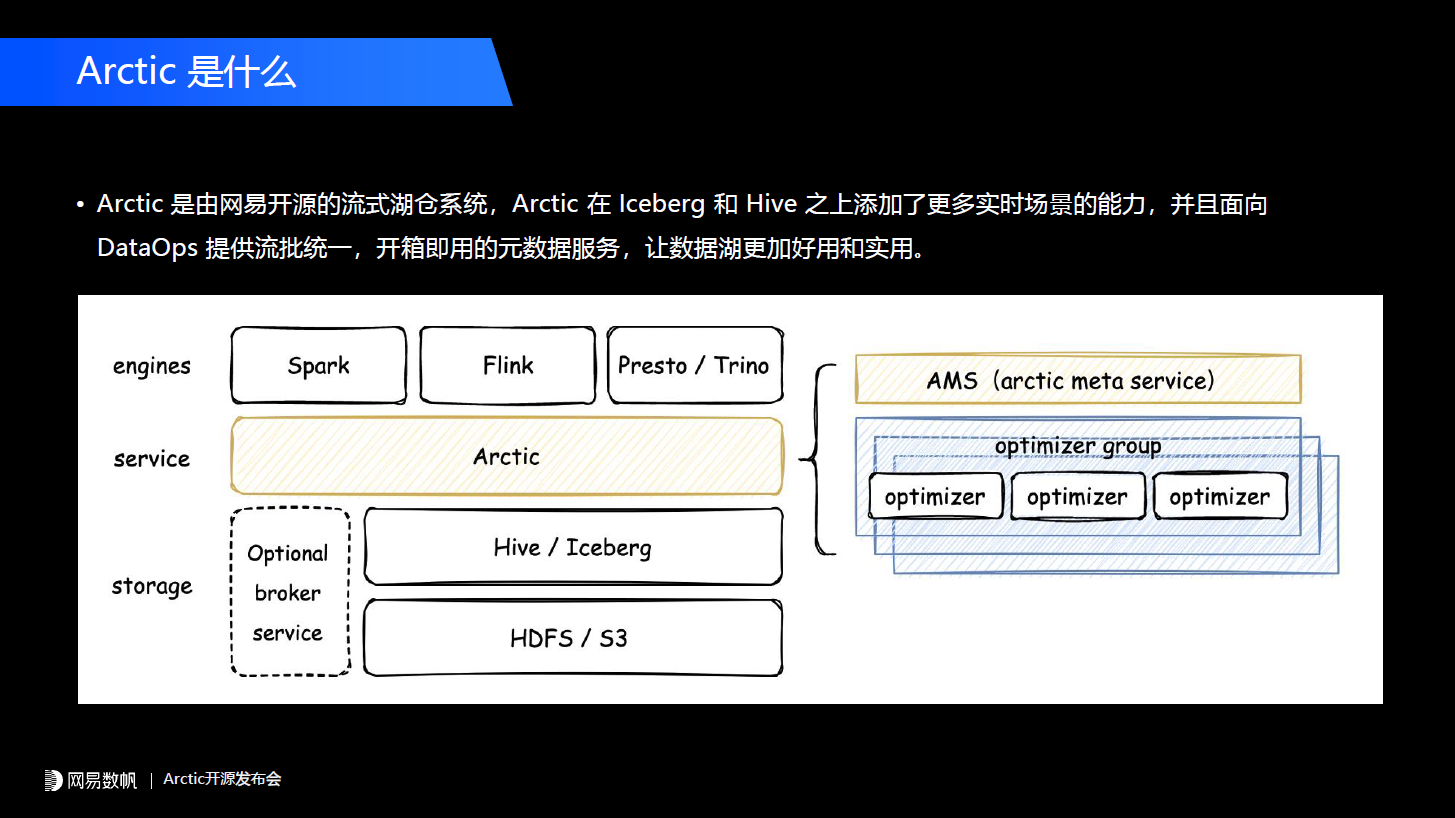 另外一点,我们在Table format之上,主要考虑跟开源的Table format做兼容,所以Arctic的一个核心目标是帮助企业用好数据湖的Table format,以及解决或者拉平在Table format以及用户,或者说产品真实的需求之间的gap。Arctic本身包含两个核心组件,第一个是元数据服务AMS,它在我们系统中定位是下一代HMS的角色。第二个,我们持续自优化的功能,会有整套optimizer组件和机制,来实现后台数据优化。
另外一点,我们在Table format之上,主要考虑跟开源的Table format做兼容,所以Arctic的一个核心目标是帮助企业用好数据湖的Table format,以及解决或者拉平在Table format以及用户,或者说产品真实的需求之间的gap。Arctic本身包含两个核心组件,第一个是元数据服务AMS,它在我们系统中定位是下一代HMS的角色。第二个,我们持续自优化的功能,会有整套optimizer组件和机制,来实现后台数据优化。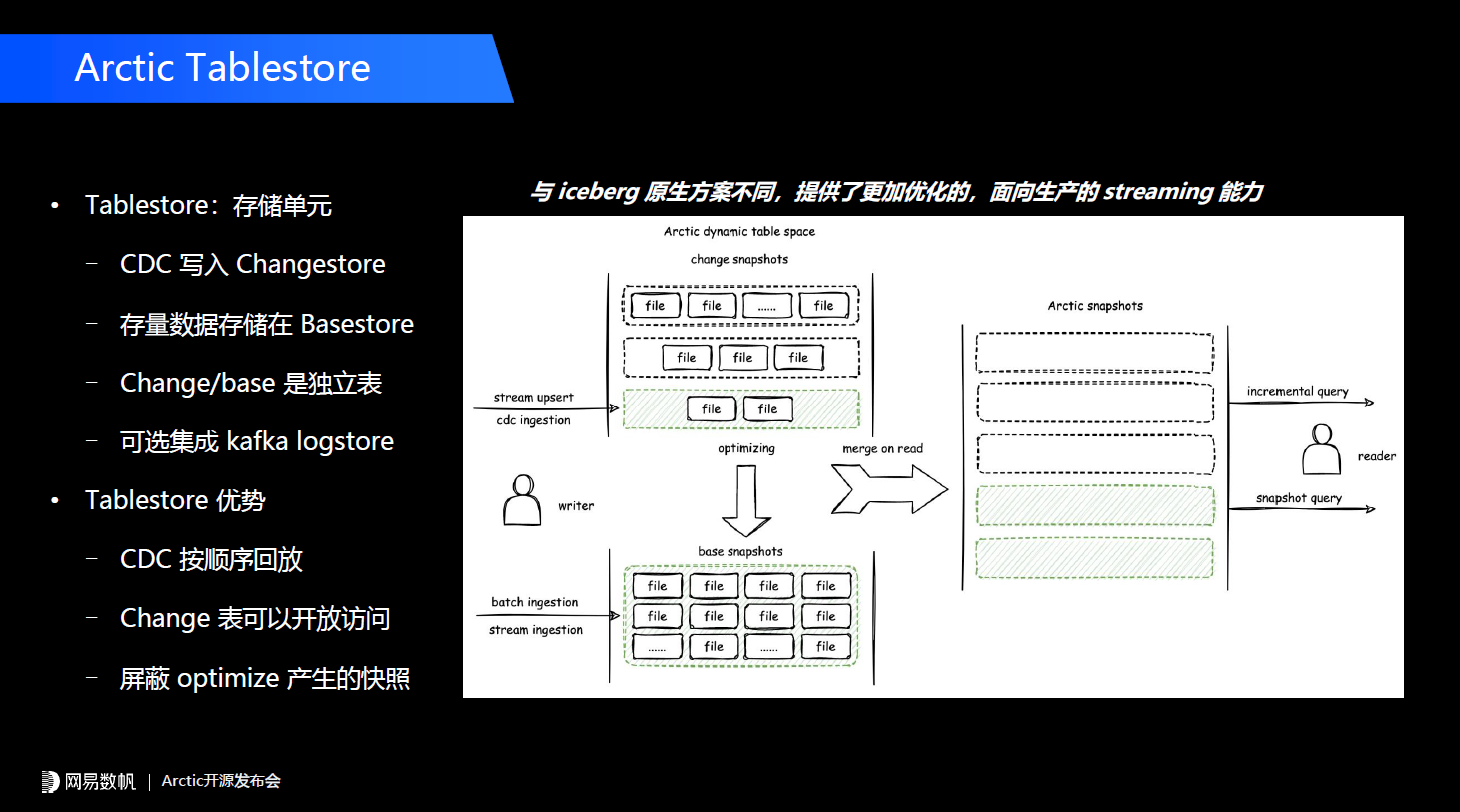 Hudi、Iceberg也有upsert的功能,但2020年我们开始做这个事情的时候Iceberg还没有这个功能,社区出于对 manifest 这层设计的严谨考量在实现上会有一些妥协,所以最终我们决定了在上层去做这个事,并且会体现我们的一些优势。Change表主要存储的是CDC的change数据,另外还有一套Basestore会存储我们的存量数据,两个Tablestore其实是两张独立的Iceberg表。另外我们还可选的集成Kafka的logstore,也就是说我们的数据可以双写,一部分先写到Kafka里面,再写进数据湖里,这样实现了流表和批表的统一。这样设计有什么样的优势?首先change表里的CDC数据可以按顺序回放,会解决Iceberg原生的V2 CDC不太好回放的问题。第二个是change表可以开放访问。在很多电商、物流的场景里change数据不光是作为一个表内置的数据用,很多时候订单表、物流表的变更数据也会作为独立的数仓表来用,我们通过这样的设计允许把change表单独拎出来用,当然会添加一些写入保护。如果未来业务有一些定制化需求,比如说在change表中额外添加一些字段,添加一些业务自己的UDF的计算逻辑,这个设计也具备这样的可能。第三点我们这套设计理念change和base之间的转化,这个过程是optimize。这个概念在Delta、Iceberg和Hudi中都有介绍过,它的核心是做一些小文件合并,我们把change数据到base数据的转换也纳入optimize的范畴,并且这些过程对用户来说是透明的,如果用户直接用Iceberg或者Delta,所有的optimize操作在底层都会有一个快照,这样对用户是不友好的,我们在上层把这套东西封装起来了。当用户读一个高新鲜度的数据做分析时,我们的引擎端会做一个change和base的merge-on-read。
Hudi、Iceberg也有upsert的功能,但2020年我们开始做这个事情的时候Iceberg还没有这个功能,社区出于对 manifest 这层设计的严谨考量在实现上会有一些妥协,所以最终我们决定了在上层去做这个事,并且会体现我们的一些优势。Change表主要存储的是CDC的change数据,另外还有一套Basestore会存储我们的存量数据,两个Tablestore其实是两张独立的Iceberg表。另外我们还可选的集成Kafka的logstore,也就是说我们的数据可以双写,一部分先写到Kafka里面,再写进数据湖里,这样实现了流表和批表的统一。这样设计有什么样的优势?首先change表里的CDC数据可以按顺序回放,会解决Iceberg原生的V2 CDC不太好回放的问题。第二个是change表可以开放访问。在很多电商、物流的场景里change数据不光是作为一个表内置的数据用,很多时候订单表、物流表的变更数据也会作为独立的数仓表来用,我们通过这样的设计允许把change表单独拎出来用,当然会添加一些写入保护。如果未来业务有一些定制化需求,比如说在change表中额外添加一些字段,添加一些业务自己的UDF的计算逻辑,这个设计也具备这样的可能。第三点我们这套设计理念change和base之间的转化,这个过程是optimize。这个概念在Delta、Iceberg和Hudi中都有介绍过,它的核心是做一些小文件合并,我们把change数据到base数据的转换也纳入optimize的范畴,并且这些过程对用户来说是透明的,如果用户直接用Iceberg或者Delta,所有的optimize操作在底层都会有一个快照,这样对用户是不友好的,我们在上层把这套东西封装起来了。当用户读一个高新鲜度的数据做分析时,我们的引擎端会做一个change和base的merge-on-read。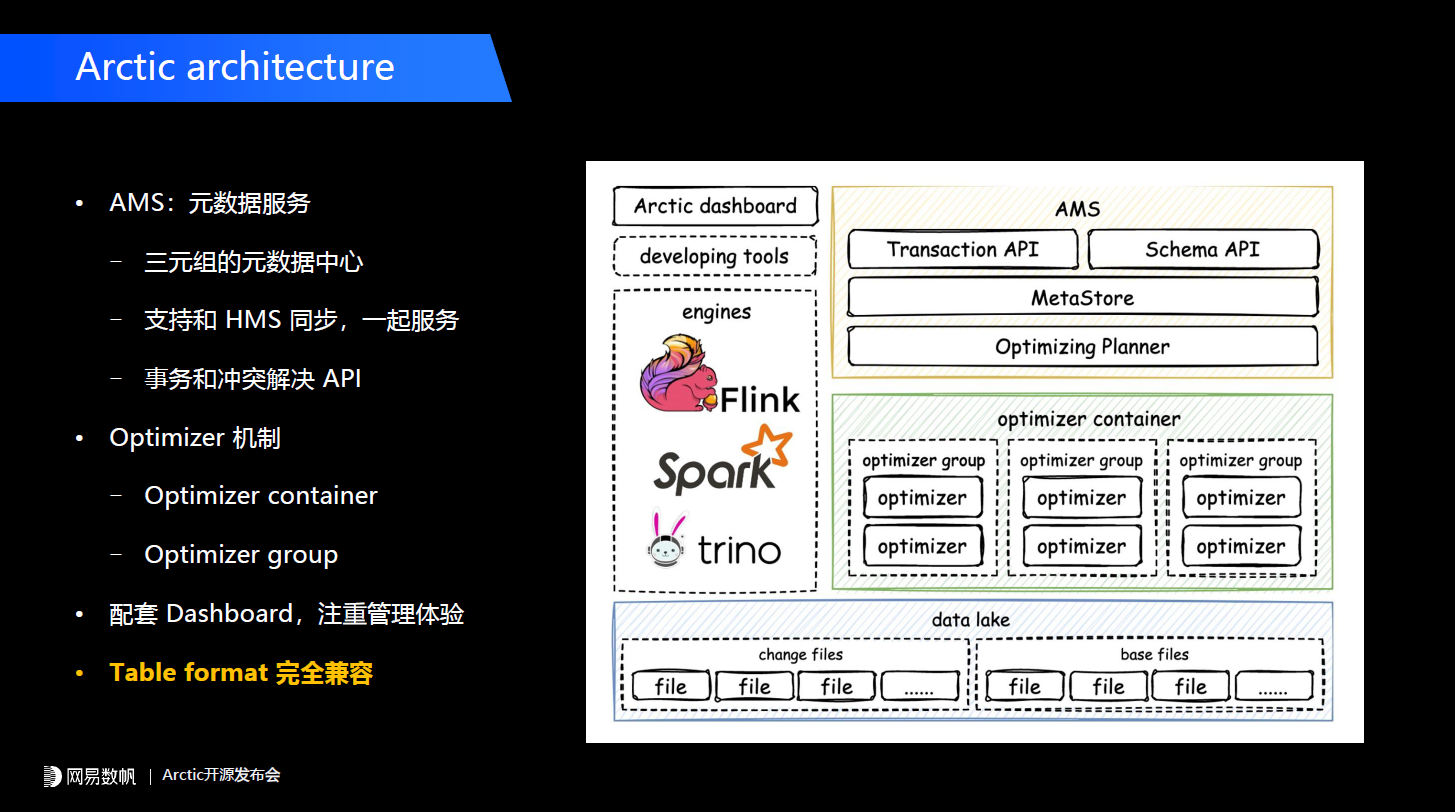 在上层我们有一个前面介绍过的AMS(Arctic Meta Service),AMS是Arctic流式湖仓服务中“服务”这一层所重点强调的组件,是面向三元组的元数据中心。三元组是什么呢?就是catalog.table.db这样的三元组,大家知道在Spark 3.0和Flink 1.2之后,主推的是multi catalog这样的功能,它可以适配不同的数据源。目前我们在主流的大数据实践中更多的是把HMS当作元数据中心来使用,HMS是二元组的结构,如果我们想扩展,把HMS里面根据更多的数据源,需要做很多定制性的工作。比如说网易数帆有数平台其实是在HMS之外单独做了一个元数据中心,来管理三元组和数据源的关系,AMS本身就是面向三元组设计的元数据服务。第二个我们的AMS可以和HMS做同步,就是我们的Schema可以存在HMS里面,除了Hive所能够存储的一些字段信息外,一些额外的组件信息,一些额外的properties会存在AMS中,这样AMS可以和HMS一起提供服务,所以业务不用担心在使用Arctic的时候一定要做一个替换,这其实是一个很灰度的过程。第三个是AMS会提供事务和冲突解决的API。在optimizer这儿,我们有一整套完整的扩展机制和管理机制。首先我们有一个optimizer container****的概念,本质上是平台调度任务的组件,我们整个后台的optimize过程对业务来说是透明的,后台需要有一套调度服务,能够把optimize的进程调度到一个平台中(比如YARN上、K8s),这种不同的模式就是optimizer container的概念,未来用户也可以通过container接口去扩展它的调度框架。optimizer group****是在container内部做资源隔离,比如说用户觉得有一些表的optimize需要高优先级运行,可以给他抽出一个独立的optimizer group执行他的优化任务。第三点在我们架构中有单独的Dashboard,也是我们的一个管理界面,我们非常注重湖仓本身的管理体验。最后一点也是非常重要的,刚才提过我们有Table format完全兼容的特性。目前提供两种,一个是Iceberg,因为我们是基于Iceberg来做的,basestore、changestore都是独立的Iceberg表,并且我们的兼容是随着Iceberg的迭代持续推进的,目前已经兼容Iceberg V2。另外我们也有Hive兼容的模式,能让业务在不用改代码的前提下,直接使用Arctic的一些主要功能,如果用户使用的是Hive format兼容,它的change数据还是存在Iceberg里面的。
在上层我们有一个前面介绍过的AMS(Arctic Meta Service),AMS是Arctic流式湖仓服务中“服务”这一层所重点强调的组件,是面向三元组的元数据中心。三元组是什么呢?就是catalog.table.db这样的三元组,大家知道在Spark 3.0和Flink 1.2之后,主推的是multi catalog这样的功能,它可以适配不同的数据源。目前我们在主流的大数据实践中更多的是把HMS当作元数据中心来使用,HMS是二元组的结构,如果我们想扩展,把HMS里面根据更多的数据源,需要做很多定制性的工作。比如说网易数帆有数平台其实是在HMS之外单独做了一个元数据中心,来管理三元组和数据源的关系,AMS本身就是面向三元组设计的元数据服务。第二个我们的AMS可以和HMS做同步,就是我们的Schema可以存在HMS里面,除了Hive所能够存储的一些字段信息外,一些额外的组件信息,一些额外的properties会存在AMS中,这样AMS可以和HMS一起提供服务,所以业务不用担心在使用Arctic的时候一定要做一个替换,这其实是一个很灰度的过程。第三个是AMS会提供事务和冲突解决的API。在optimizer这儿,我们有一整套完整的扩展机制和管理机制。首先我们有一个optimizer container****的概念,本质上是平台调度任务的组件,我们整个后台的optimize过程对业务来说是透明的,后台需要有一套调度服务,能够把optimize的进程调度到一个平台中(比如YARN上、K8s),这种不同的模式就是optimizer container的概念,未来用户也可以通过container接口去扩展它的调度框架。optimizer group****是在container内部做资源隔离,比如说用户觉得有一些表的optimize需要高优先级运行,可以给他抽出一个独立的optimizer group执行他的优化任务。第三点在我们架构中有单独的Dashboard,也是我们的一个管理界面,我们非常注重湖仓本身的管理体验。最后一点也是非常重要的,刚才提过我们有Table format完全兼容的特性。目前提供两种,一个是Iceberg,因为我们是基于Iceberg来做的,basestore、changestore都是独立的Iceberg表,并且我们的兼容是随着Iceberg的迭代持续推进的,目前已经兼容Iceberg V2。另外我们也有Hive兼容的模式,能让业务在不用改代码的前提下,直接使用Arctic的一些主要功能,如果用户使用的是Hive format兼容,它的change数据还是存在Iceberg里面的。 我们的table service的功能,对于表有很多元数据的信息,包括每张表动态的变更,一些DDL的历史信息,事务的信息,都会在表服务中体现。
我们的table service的功能,对于表有很多元数据的信息,包括每张表动态的变更,一些DDL的历史信息,事务的信息,都会在表服务中体现。
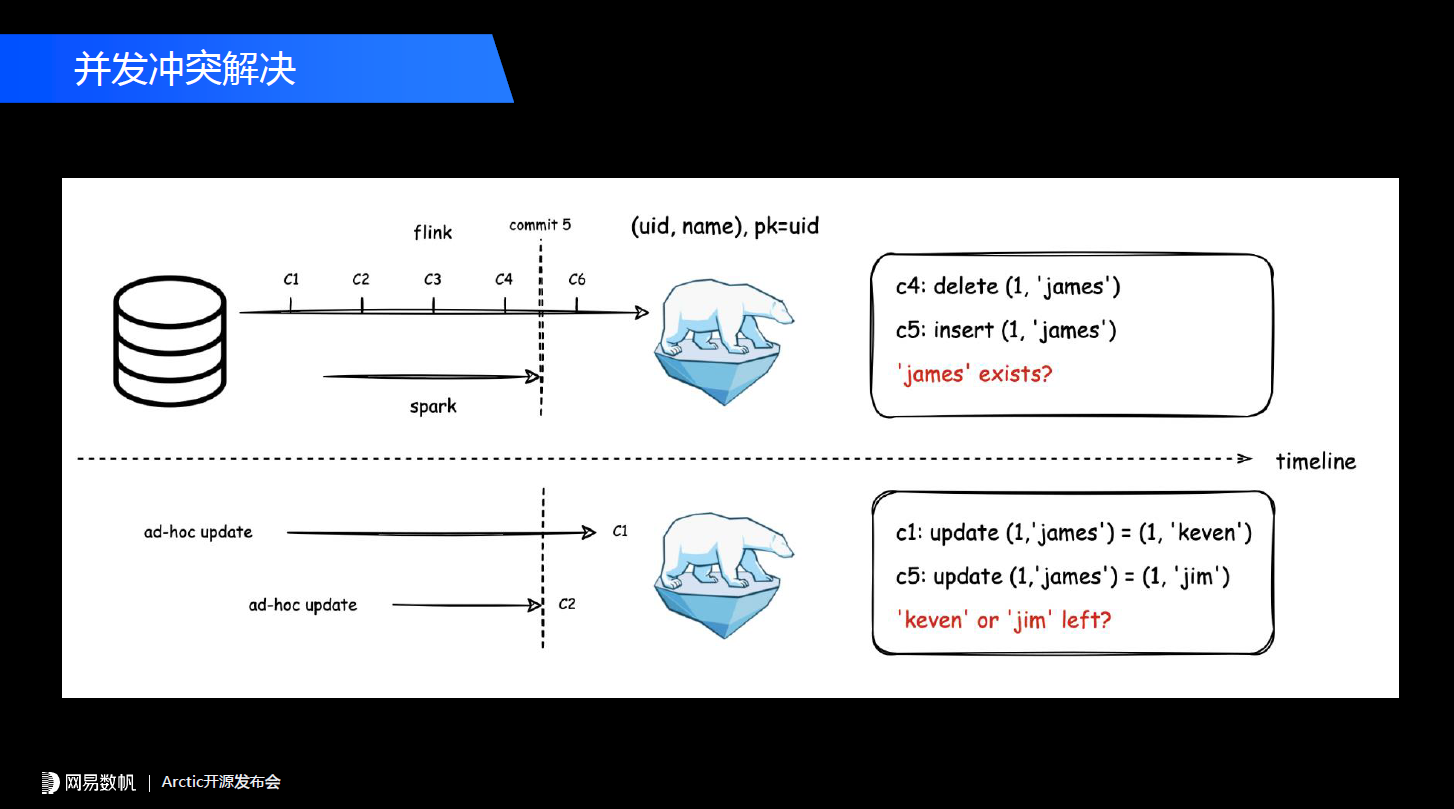 现在在Table format这一层普遍提供的是乐观并发控制的语义,当我们出现冲突的时候首先想到的是让某一个提交失败,换句话说,乐观并发控制的语义核心的一点是不允许并发出现,那么在我们这个场景里Spark任务可能永远提交不成功的,因为我们对它的期待是做全部的数据重写,这样它的数据范畴是一定会和我们的实时数据冲突的。但业务肯定希望他的数据能够提交成功,所以我们提供了并发冲突解决的机制,让这个数据能够提交成功,并且同时保障它依然具有事务一致性的语义。下半部分也是类似的,我们对一个数仓表、湖仓表进行了ad-hoc并发的更新c1和c2,c1在c2之后提交,但是c1在c2之前开始,当它们出现冲突之后是c1覆盖c2,还是c2覆盖c1?从目前数据湖方案来说,一般是谁后提交以谁为准,但是在更多的生产场景中我们需要谁先开始以谁为准。这一块时间关系就不展开,有任何疑问可以在用户群里与我们深入交流。
现在在Table format这一层普遍提供的是乐观并发控制的语义,当我们出现冲突的时候首先想到的是让某一个提交失败,换句话说,乐观并发控制的语义核心的一点是不允许并发出现,那么在我们这个场景里Spark任务可能永远提交不成功的,因为我们对它的期待是做全部的数据重写,这样它的数据范畴是一定会和我们的实时数据冲突的。但业务肯定希望他的数据能够提交成功,所以我们提供了并发冲突解决的机制,让这个数据能够提交成功,并且同时保障它依然具有事务一致性的语义。下半部分也是类似的,我们对一个数仓表、湖仓表进行了ad-hoc并发的更新c1和c2,c1在c2之后提交,但是c1在c2之前开始,当它们出现冲突之后是c1覆盖c2,还是c2覆盖c1?从目前数据湖方案来说,一般是谁后提交以谁为准,但是在更多的生产场景中我们需要谁先开始以谁为准。这一块时间关系就不展开,有任何疑问可以在用户群里与我们深入交流。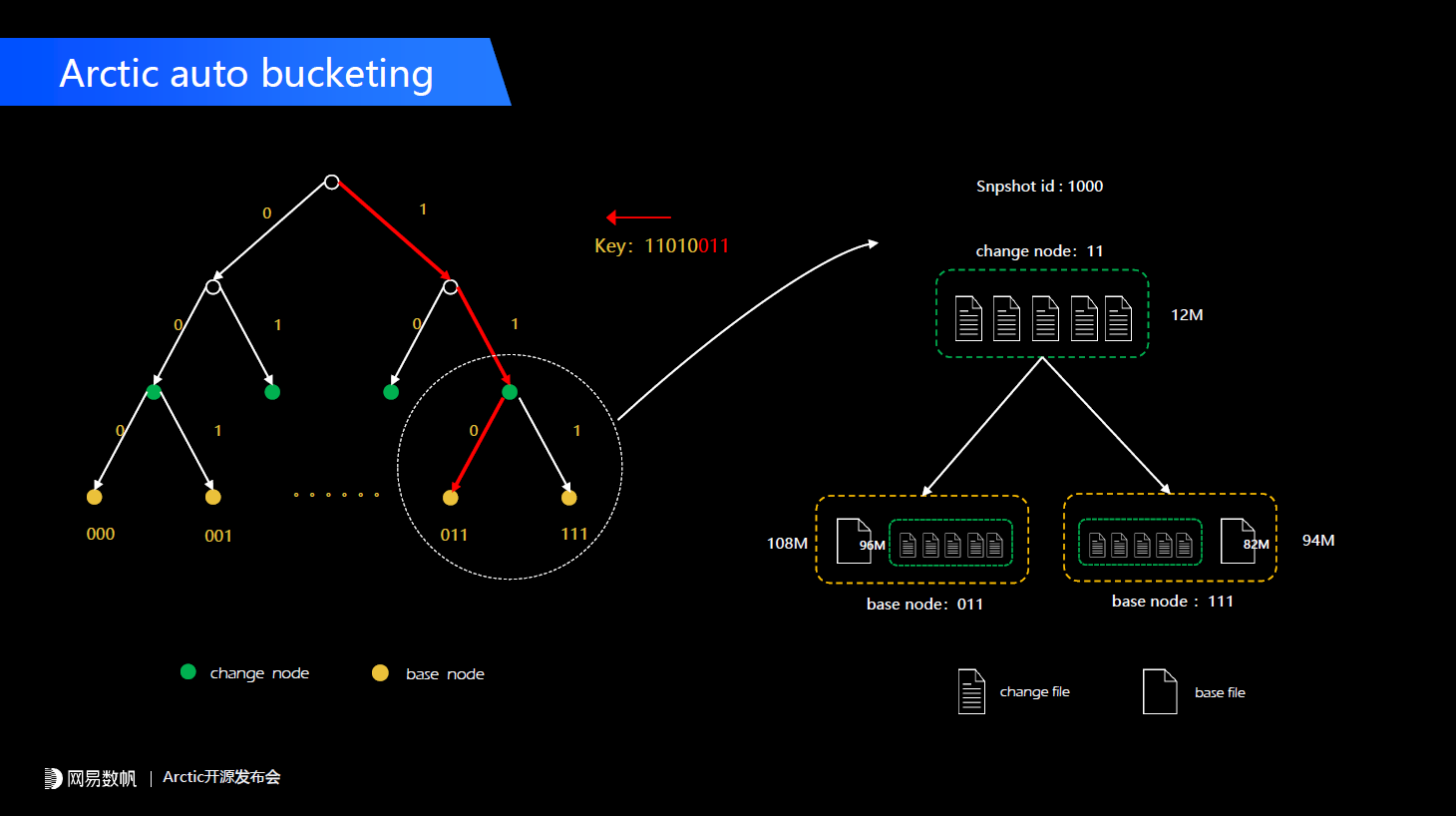 当一个node数据超过这个范畴之后,我们会尝试把它分裂,之前也提到我们分了changestore和basestore,它们都是按照同样的方式管理,这样在每一个节点之上可以对应到change数据和base的数据,就能实现更精细的数据映射,数据分析的性能会有一个非常好的提升。可以看到在merge-on-read的过程也可以用到整套机制。2000年左右伯克利有一篇论文专门描述这种方案,感兴趣的同学也可以自己去了解。
当一个node数据超过这个范畴之后,我们会尝试把它分裂,之前也提到我们分了changestore和basestore,它们都是按照同样的方式管理,这样在每一个节点之上可以对应到change数据和base的数据,就能实现更精细的数据映射,数据分析的性能会有一个非常好的提升。可以看到在merge-on-read的过程也可以用到整套机制。2000年左右伯克利有一篇论文专门描述这种方案,感兴趣的同学也可以自己去了解。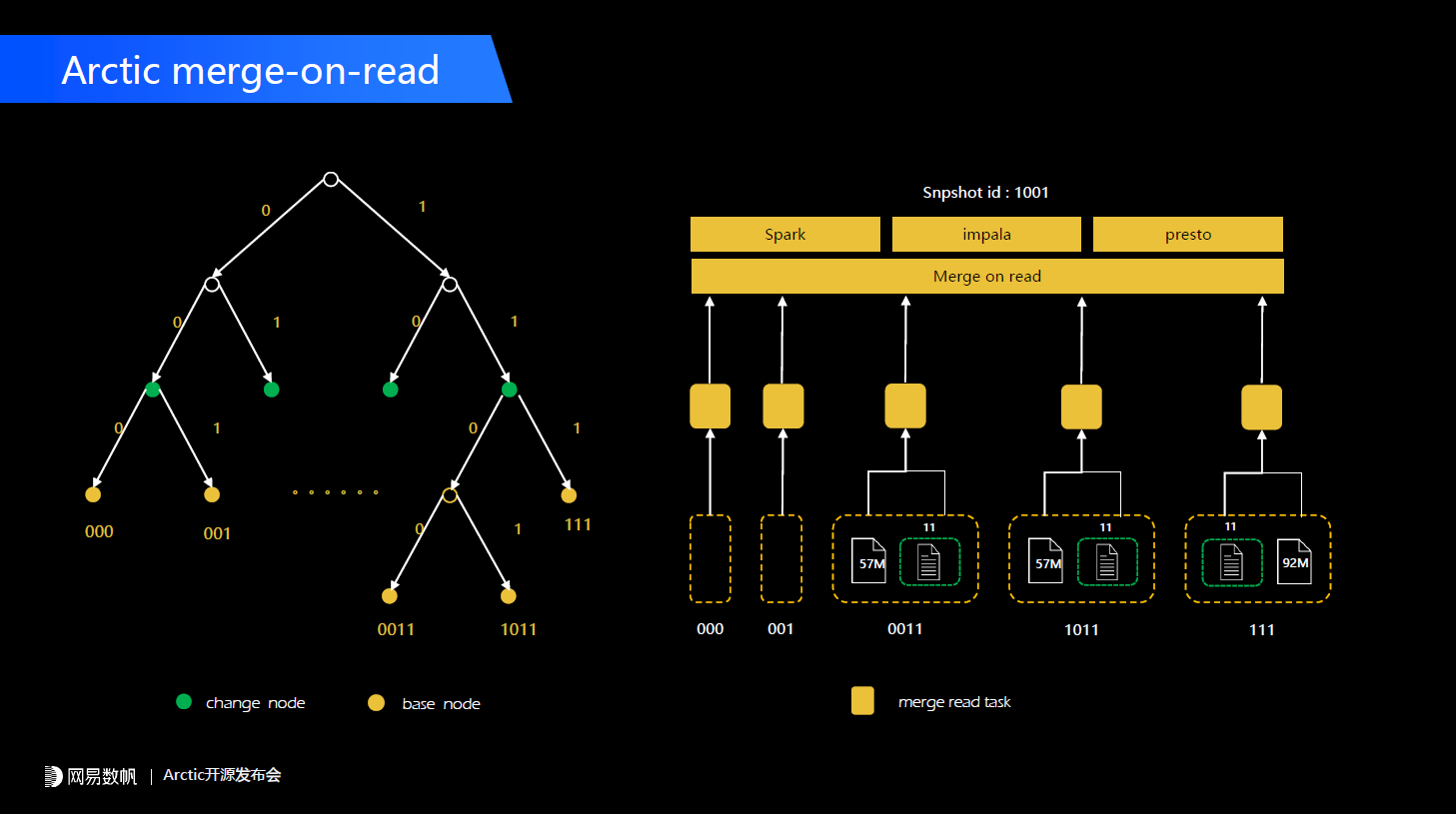
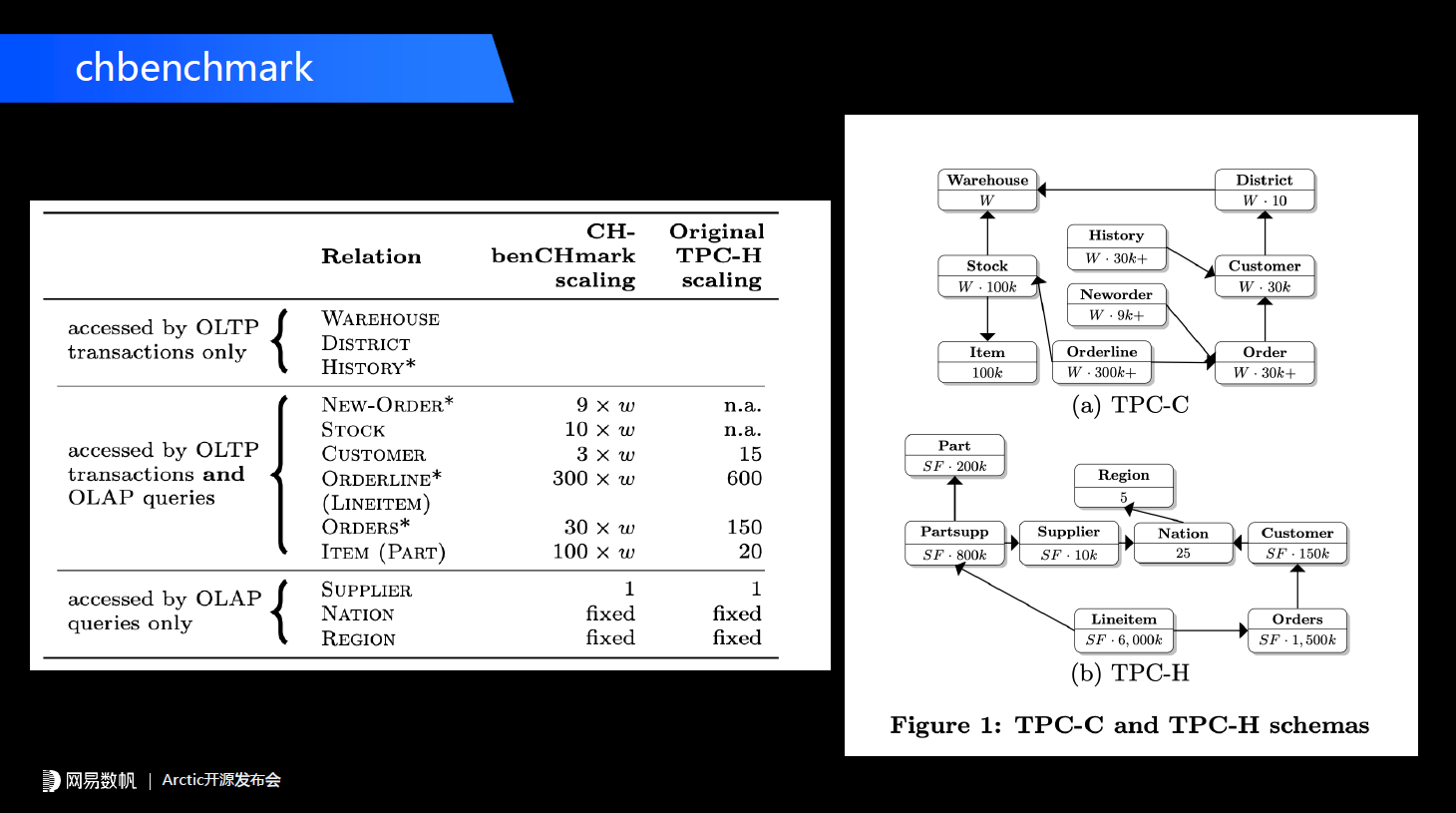 基于这套方案我们做了一个改造,首先用TPC-C跑数据库,在下面我们再跑一个Flink CDC任务,把数据库实时流式地同步到Arctic数据湖中,用Arctic数据湖构建一个分钟级别数据新鲜度的流式湖仓,在这之上我们再跑CHbenchmark中TPC-H的部分,这样能得到比较标准的流式湖仓的数据分析的性能。针对optimize前后的Arctic、Iceberg和Hudi测试的结果(Trino下测试),我们按阶段做了一个简单的对比,分为0-30分钟、30-60、60-90分钟和90-120分钟四组。下图蓝色的部分是没有optimize的数据分析的性能,从0-30分钟,到最后的90-120分钟,延迟从20秒降低到了40多秒,降低了一半多。而黄色部分有持续合并的Arctic,性能稳定在20秒左右。
基于这套方案我们做了一个改造,首先用TPC-C跑数据库,在下面我们再跑一个Flink CDC任务,把数据库实时流式地同步到Arctic数据湖中,用Arctic数据湖构建一个分钟级别数据新鲜度的流式湖仓,在这之上我们再跑CHbenchmark中TPC-H的部分,这样能得到比较标准的流式湖仓的数据分析的性能。针对optimize前后的Arctic、Iceberg和Hudi测试的结果(Trino下测试),我们按阶段做了一个简单的对比,分为0-30分钟、30-60、60-90分钟和90-120分钟四组。下图蓝色的部分是没有optimize的数据分析的性能,从0-30分钟,到最后的90-120分钟,延迟从20秒降低到了40多秒,降低了一半多。而黄色部分有持续合并的Arctic,性能稳定在20秒左右。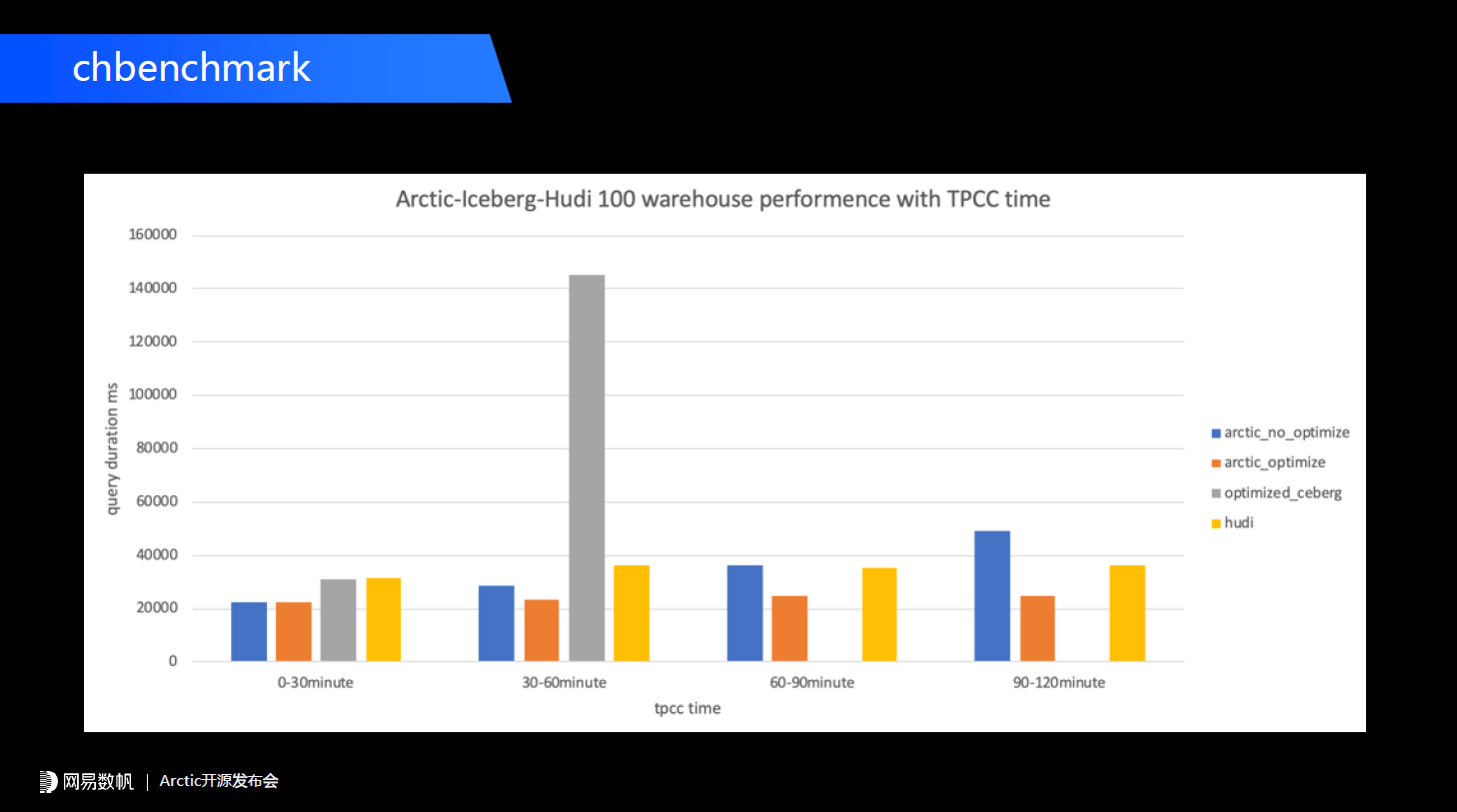 灰色的是原生的Iceberg upsert方案,0-30分钟是在30秒左右,从30-60分钟性能是急剧下降的。为什么Iceberg出现了这么大的性能滑坡呢?因为原生Iceberg确实没有insert数据和delete数据的精细化的映射,所以当我们持续写入流式文件之后,每一个insert file都会跟delete file产生非常多的关联,从而导致我们在Trino中做merge-on-read的性能急剧下降。后面测60-90分钟、90-120分钟就直接OOM,跑不出来了。黄色部分是Hudi。目前来看Arctic和Hudi一样,通过后台优化能够保证数据分析的性能,维持在一个比较平稳的数字。目前来看我们通过上层的优化,比Hudi要好一些。后续我们也会在官网中把我们整个测试流程和相关配置向大家公开。Arctic 目前看 mor 性能相比 Hudi 有一定优势,这里我们先不强调Arctic 做得有多好我们也研究了Hudi,它有RO和RT两种模式,前者是只会读合并数据,RT模式是merge-on-read的一种模式。它的RO模式和RT模式性能差距非常大,所以未来可能会有很大的优化空间。
灰色的是原生的Iceberg upsert方案,0-30分钟是在30秒左右,从30-60分钟性能是急剧下降的。为什么Iceberg出现了这么大的性能滑坡呢?因为原生Iceberg确实没有insert数据和delete数据的精细化的映射,所以当我们持续写入流式文件之后,每一个insert file都会跟delete file产生非常多的关联,从而导致我们在Trino中做merge-on-read的性能急剧下降。后面测60-90分钟、90-120分钟就直接OOM,跑不出来了。黄色部分是Hudi。目前来看Arctic和Hudi一样,通过后台优化能够保证数据分析的性能,维持在一个比较平稳的数字。目前来看我们通过上层的优化,比Hudi要好一些。后续我们也会在官网中把我们整个测试流程和相关配置向大家公开。Arctic 目前看 mor 性能相比 Hudi 有一定优势,这里我们先不强调Arctic 做得有多好我们也研究了Hudi,它有RO和RT两种模式,前者是只会读合并数据,RT模式是merge-on-read的一种模式。它的RO模式和RT模式性能差距非常大,所以未来可能会有很大的优化空间。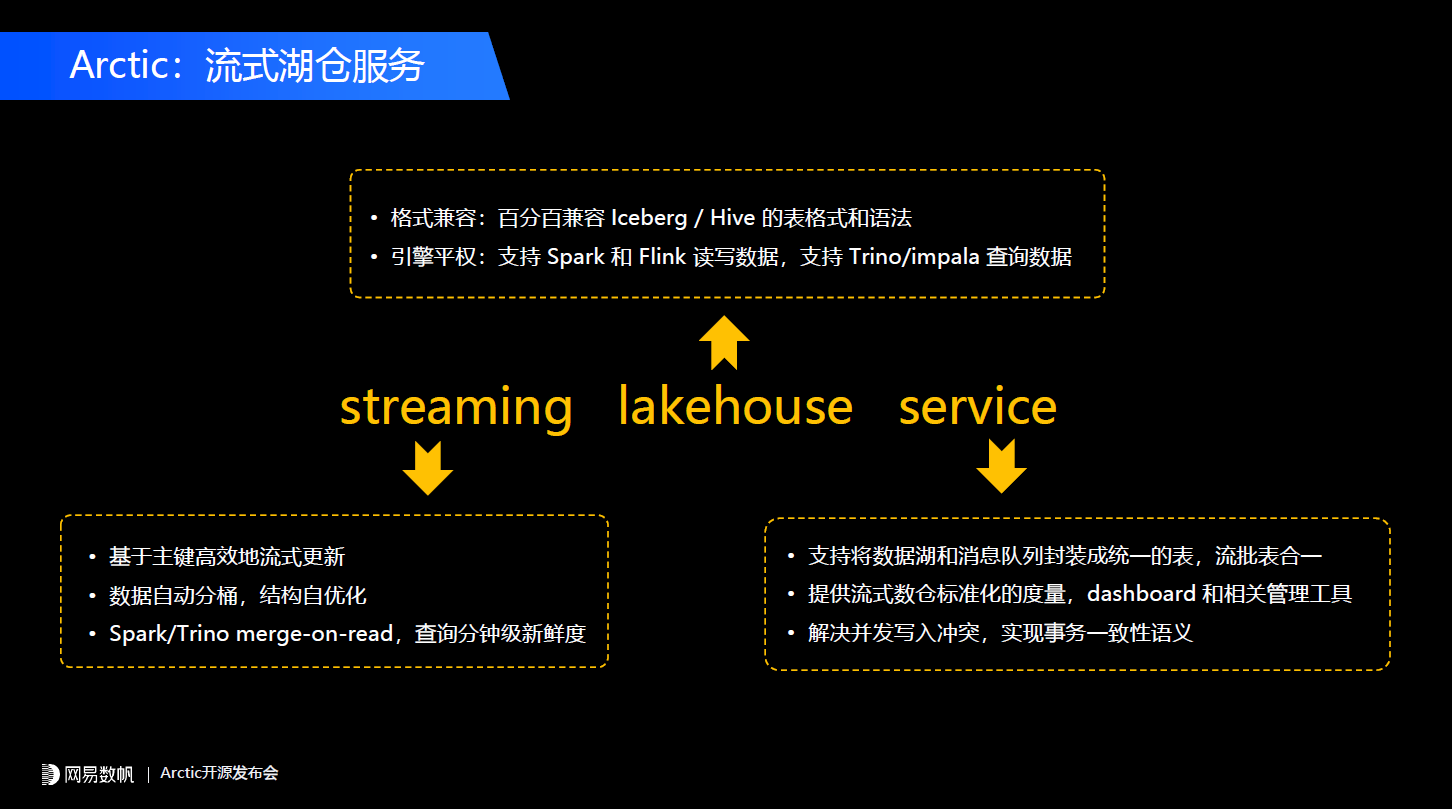 在service这一块主要强调管理上的功能:第一个是支持将数据湖和消息队列封装成统一的表,实现流批表的统一,这样用户使用Arctic表不用担心从秒级或者毫秒级降低到分钟级别,他依然可以使用数据湖提供毫秒或者秒级的数据延迟的能力。第二点提供流式湖仓标准化度量,dashboard和相关的管理工具。第三点是解决并发写入冲突,实现事务一致性语义。在管理层面我们聚焦回答下面这几个问题,这些工作还有很长的路要走。第一个是表的实时性怎么量化,比如说我们搭建一个流式的湖仓表之后,当前的新鲜度是一分钟、两分钟还是多少,是否达到了用户的预期。第二个怎样在时效性、成本、性能之间给用户提供trade off方案。第三个查询性能有多少优化空间,需要投入多大的资源做这样的事情。第四点数据优化的资源该怎样量化,怎样最大化利用这些资源。如果用户深入了解Arctic,会发现我们optimizing跟目前Hudi其他的有很大不同,首先我们optimizing是在平台层面调度的,不是在每一个写入的任务里做的,这样我们可以集中化管理这些数据优化的资源,并且可以提供最快的迭代。比如我们发现通过一些优化能够让合并效率有很大的提升,就可以很快迭代。最后一点是怎样灵活分配资源,为高优先级来调度资源。在未来Core feature维度的工作,首先我们关注的是不依赖外部KV实现Flink lookup join功能。我们之前看到的一个架构里,如果在实时场景下做一个维表join,可能需要一个外部的KV做同步,目前我们在做这样的方案,就是不需要做外部的同步了,可以直接基于Arctic表来做维表join。第二个是流式更新部分列,现在我们主要是通过CDC来做streaming upsert,很多场景,比如特征、大宽表,我们可能需要能够更新部分列。后面是更多的optimizer container支持,比如说K8s;更多SQL语法的支持,比如说merge into——目前我们在Arctic层面还没有这样的语法,用户可以把Arctic的表当成Iceberg表来用,来支持merge into。未来如果在Arctic层面支持了merge into,它会和Iceberg有所不同,因为我们的变更数据首先会进入到change空间。最后一点因为我们的生态位是在数据湖Table format之上,所以未来我们会做架构的解耦,去扩展到更多的Table format,比如Delta、Hudi。最后谈谈我们开源的初衷。过去我们做开源可能没有一个非常统一的步调,去年我们领导层下了一个决心,会按照一种更加专注的方式做开源,以Arctic这个项目为例,我们不会做任何的商业隐藏。而且从组织架构而言我们团队推进开源也是非常独立的过程,如果可能有商业化会由其他的团队推进。我们会致力于为开发者、用户、成员构建一个公开、自由的数据湖技术交流社区。当然目前我们主要面向的是国内用户,官网也是以中文为主。希望更多的开发者参与到我们这个项目中来。这是我今天要分享的全部内容,谢谢大家!
在service这一块主要强调管理上的功能:第一个是支持将数据湖和消息队列封装成统一的表,实现流批表的统一,这样用户使用Arctic表不用担心从秒级或者毫秒级降低到分钟级别,他依然可以使用数据湖提供毫秒或者秒级的数据延迟的能力。第二点提供流式湖仓标准化度量,dashboard和相关的管理工具。第三点是解决并发写入冲突,实现事务一致性语义。在管理层面我们聚焦回答下面这几个问题,这些工作还有很长的路要走。第一个是表的实时性怎么量化,比如说我们搭建一个流式的湖仓表之后,当前的新鲜度是一分钟、两分钟还是多少,是否达到了用户的预期。第二个怎样在时效性、成本、性能之间给用户提供trade off方案。第三个查询性能有多少优化空间,需要投入多大的资源做这样的事情。第四点数据优化的资源该怎样量化,怎样最大化利用这些资源。如果用户深入了解Arctic,会发现我们optimizing跟目前Hudi其他的有很大不同,首先我们optimizing是在平台层面调度的,不是在每一个写入的任务里做的,这样我们可以集中化管理这些数据优化的资源,并且可以提供最快的迭代。比如我们发现通过一些优化能够让合并效率有很大的提升,就可以很快迭代。最后一点是怎样灵活分配资源,为高优先级来调度资源。在未来Core feature维度的工作,首先我们关注的是不依赖外部KV实现Flink lookup join功能。我们之前看到的一个架构里,如果在实时场景下做一个维表join,可能需要一个外部的KV做同步,目前我们在做这样的方案,就是不需要做外部的同步了,可以直接基于Arctic表来做维表join。第二个是流式更新部分列,现在我们主要是通过CDC来做streaming upsert,很多场景,比如特征、大宽表,我们可能需要能够更新部分列。后面是更多的optimizer container支持,比如说K8s;更多SQL语法的支持,比如说merge into——目前我们在Arctic层面还没有这样的语法,用户可以把Arctic的表当成Iceberg表来用,来支持merge into。未来如果在Arctic层面支持了merge into,它会和Iceberg有所不同,因为我们的变更数据首先会进入到change空间。最后一点因为我们的生态位是在数据湖Table format之上,所以未来我们会做架构的解耦,去扩展到更多的Table format,比如Delta、Hudi。最后谈谈我们开源的初衷。过去我们做开源可能没有一个非常统一的步调,去年我们领导层下了一个决心,会按照一种更加专注的方式做开源,以Arctic这个项目为例,我们不会做任何的商业隐藏。而且从组织架构而言我们团队推进开源也是非常独立的过程,如果可能有商业化会由其他的团队推进。我们会致力于为开发者、用户、成员构建一个公开、自由的数据湖技术交流社区。当然目前我们主要面向的是国内用户,官网也是以中文为主。希望更多的开发者参与到我们这个项目中来。这是我今天要分享的全部内容,谢谢大家!我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
我在一个静态网站上工作(因此没有真正的服务器支持),我想在另一个网站中包含一个小的细长片段,可能会向它传递一个变量。这可能吗?在rails中很容易,虽然是render方法,但我不知道如何在slim上做(显然load方法不适用于slim)。 最佳答案 Slim包含Include插件,允许在编译时直接在模板文件中包含其他文件:require'slim/include'includepartial_name文档可在此处获得:https://github.com/slim-template/slim/blob/master/doc/incl