一,死锁发现
项目中有一个接口包含更新操作1,后面发现更新失败,通过查看应用程序日志,发现发生了死锁
sql 1 如下
1.最初版本根据id为条件,更新(plan_start_time 二级索引)
update tt_task SET org_id = ?, org_name = ?, plan_start_time = ? where id = ?
2.第二版根据order_number唯一索引为条件,更新(这样改当时想法是减少对id的争夺,后面发布后未生效,似乎导致了更严重的死锁(更新1后面还有一个更新2操作,从应用日志中发现更新2的死锁))
update tt_task SET org_id = ?, org_name = ?, plan_start_time = ? where order_number = ?
二,死锁日志
1.最初根据id更新死锁,更新1
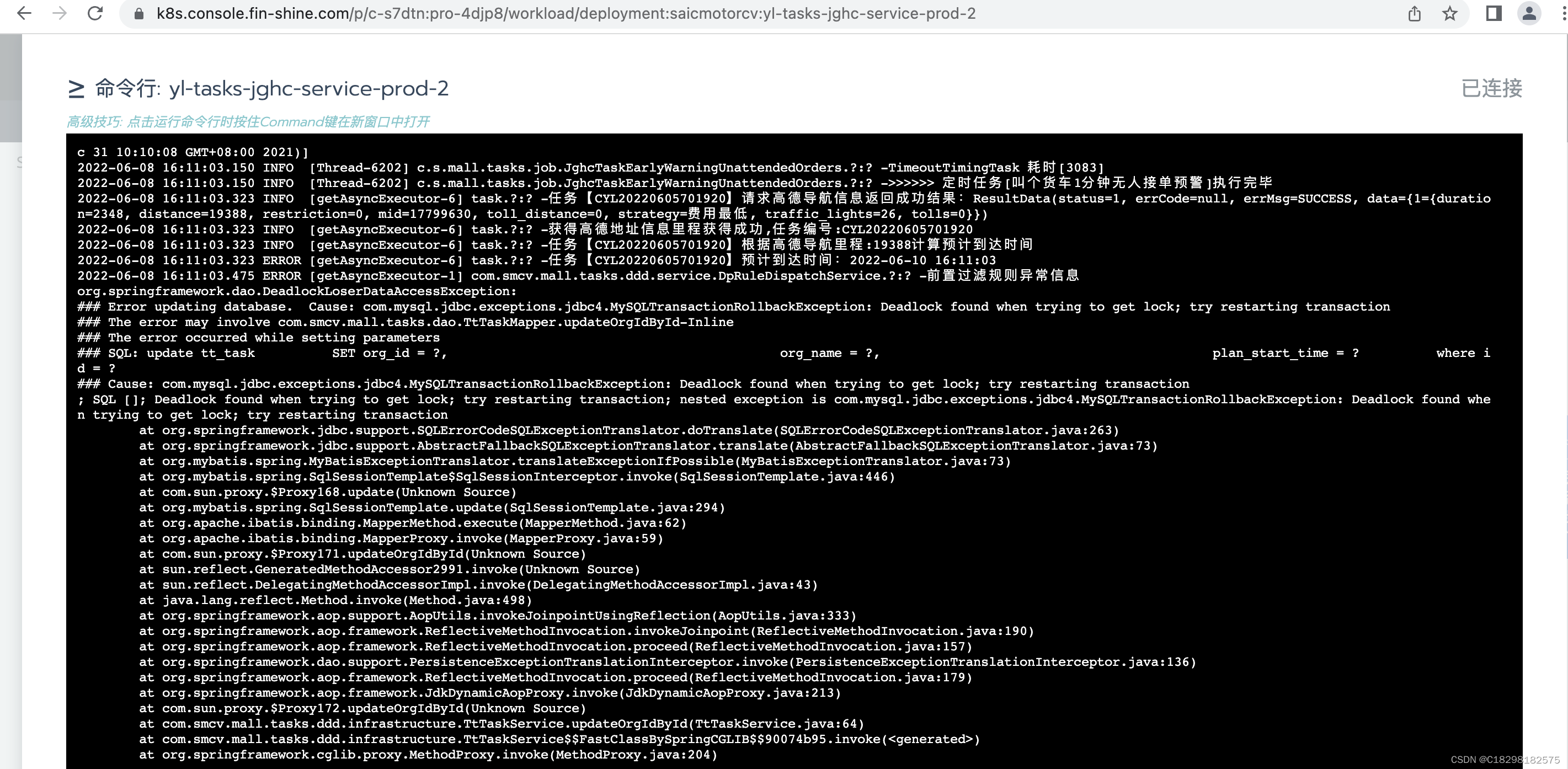
2.改成根据唯一索引order_number更新

3.更新2死锁(更新1后面的一个更新操作)(plan_arrive_time 二级索引)
update tt_task SET navigation_distance = ?, plan_arrive_time = ? where id = ?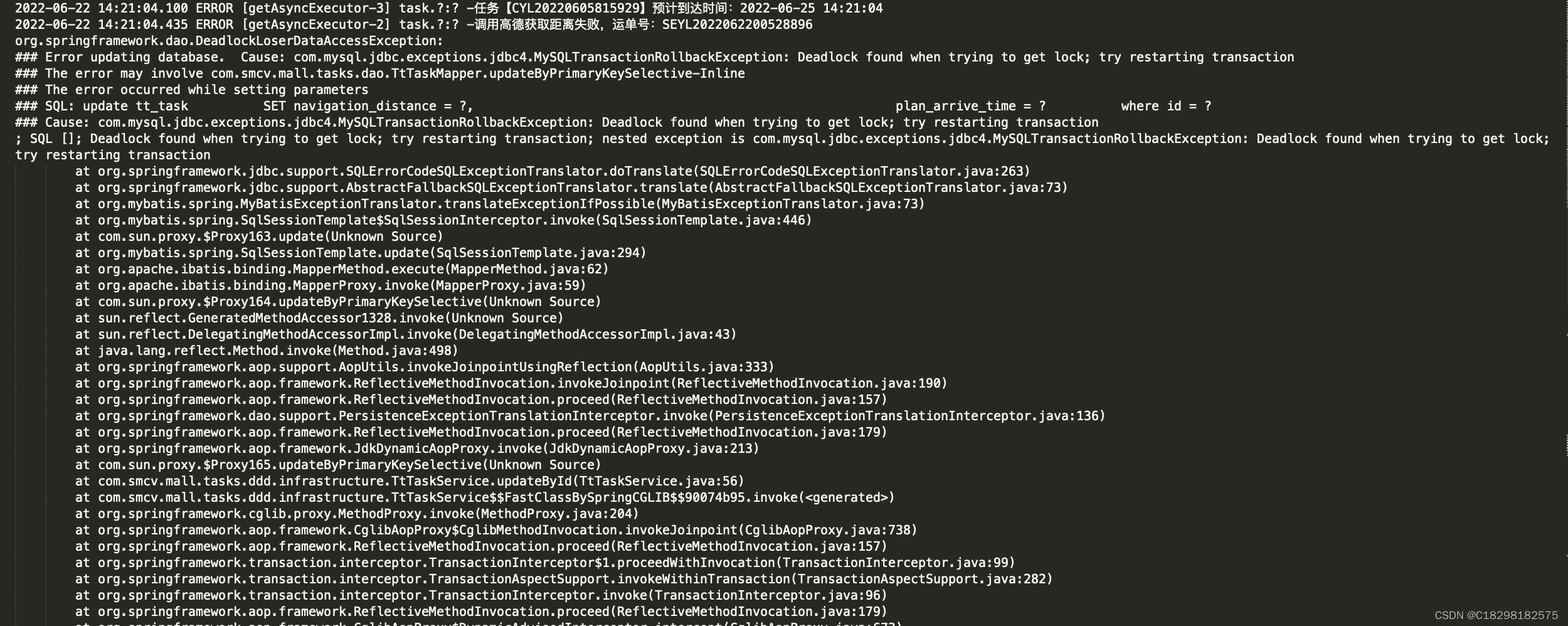
4.死锁日志分析
上面上传的死锁日志是不全的,出现死锁日志有的不是一处错误,有的是连续两个,甚至是三个死锁报错
4.1 连续两个报错日志,且是不同的两条数据,发生报错时间s秒级
4.2 只有一个报错日志,某一条数据发生死锁
4.3 连续出现3处死锁日志,如上图3,1.3处是更新2的死锁,2处是更新1的死锁,且分别是3条不同的数据
三,猜想
一般死锁原因:并发+两个事物+操作同一条数据(具体原因:待补充)
比较疑惑的是
1.更新操作,条件已经是id,最大限度的减少了死锁,为什么还会发生
2.只有一条死锁报错,只涉及到一条数据,怎么产生死锁的(不会并发啊)
3.连续两个死锁日志,是两个不同的数据(不是争夺同一个数据引发死锁吗)
猜想1:
肯定有并发操作
针对发生死锁的这个表,项目中有很多更新操作(确实有,哪些比较模糊)
当前发生死锁的更新,肯定是和哪个更新操作发生了冲突,两个不同事物各自持有锁
方案
1,怎么优化当前发生死锁的sql,但是已经是根据id更新的,死锁概率应该比较低啊,方向是这里,所以有了改成根据唯一索引更新,想减少对主键id的占用。
具体操作
1.1 把代码逻辑中更新报错的sql,单独写一个根据唯一索引更新,独立与其他更新操作
1.2 把更新操作上的,@Transation 事物注解去掉,如下图

结果:但是上线后,未生效
四,继续排查
因为第一次改动未生效,发下可以查询mysql日志,如下
1.查询mysql死锁日志
SHOW ENGINE INNODB STATUS;
2.mysql日志详情
更新2的死锁日志
*** (1) TRANSACTION:
TRANSACTION 1090268215, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1136, 1 row lock(s)
MySQL thread id 1951581, OS thread handle 140039768516352, query id 6856707976 10.129.22.123 service-2eoui9 updating
update tt_task
SET navigation_distance = '28115',
plan_arrive_time = '2022-06-25 17:11:03.08'
where id = 528013
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 1233 page no 40677 n bits 96 index PRIMARY of table `yl-task-jghc`.`tt_task` trx id 1090268215 lock_mode X locks rec but not gap waiting
Record lock, heap no 17 PHYSICAL RECORD: n_fields 111; compact format; info bits 0
之前未发现的死锁日志 (grabbing_status 二级索引),当作更新3
update tt_task
set grabbing_status = '0'
where grabbing_status = '79501010'
and relation_parts_count > 0
*** (2) TRANSACTION:
TRANSACTION 1090267856, ACTIVE 3 sec fetching rows
mysql tables in use 1, locked 1
30328 lock struct(s), heap size 2711760, 557309 row lock(s), undo log entries 35
MySQL thread id 1951474, OS thread handle 140039766386432, query id 6856706017 10.129.22.123 service-2eoui9 updating
update tt_task
set grabbing_status = '0'
where grabbing_status = '79501010'
and relation_parts_count > 0
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 1233 page no 40677 n bits 88 index PRIMARY of table `yl-task-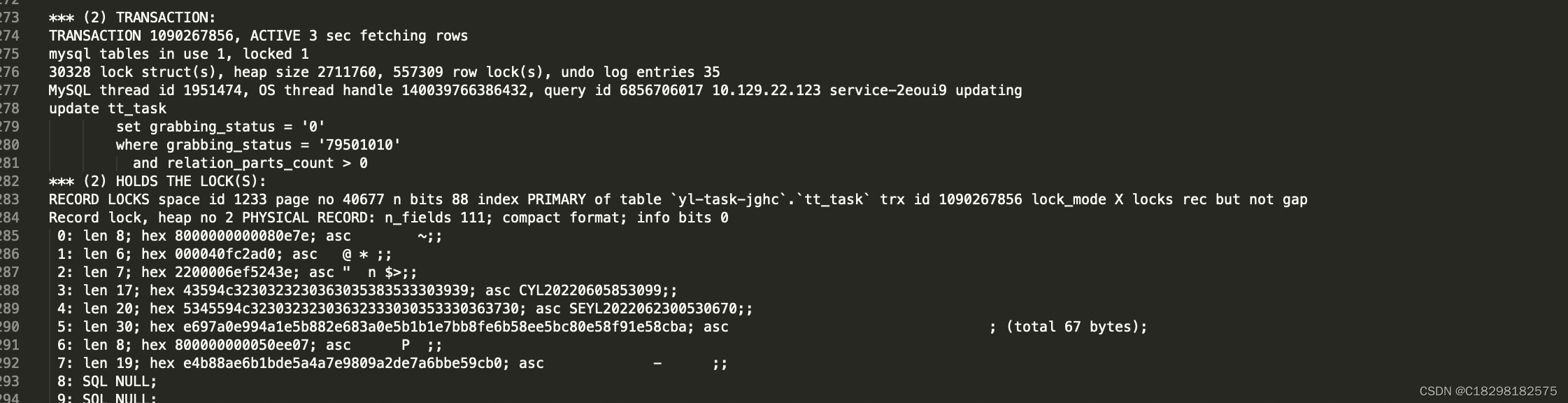
3. 再结合业务日志发现以下问题
3.1.实际上更新2(包含在更新1中,且是异步的)的死锁概率大于更新1
3.2.更新1,更新2,这两个受害者,都与自己无关,也与对方无关,还有一个第三者,是第三者导致了更新1,更新2,甚至更多地方的死锁
至此,发现了导致死锁的根本sql
4.可归类为
更新1(死锁受害者)
更新2(死锁受害者)
更新3(死锁引发者)
再回头看下发生死锁的三个sql,前面已经说了是第三个sql,导致前两个sql死锁,细节怎样的?
update tt_task SET org_id = ?, org_name = ?, plan_start_time = ? where id = ?
update tt_task SET navigation_distance = ?, plan_arrive_time = ? where id = ?
update tt_task set grabbing_status = '0' where grabbing_status = '79501010' and relation_parts_count > 0
再次之前,先想一下之所以死锁,是一条数据导致的,还是多条数据导致的,答案是多条数据
先看一个简单案例
事物1,更新数据1,持有数据1的锁,准备更新数据2,想获取数据2的锁
事物2,更新数据2,持有数据2的锁,准备更新数据1,想获取数据1的锁
先弄明白,锁是什么时候释放的,是事物提交之后释放的,即以上两个事物更新完第一个数据后,仍持有第一个数据锁,从而导致,想获取下一个数据的锁时,获取失败,导致死锁(持有对方需要的锁,不释放)。
再分析,以上三个sql死锁问题
sql3进行了一个范围更新,会持有符合条件的所有数据锁,这些数据同时在sql1,2中,所以死锁,等等,先看下死锁条件,如下,sql1/2,是另外一个事物满足,具体持有了哪些锁,更新的数据?被sql3持有锁,只能说明无法获取锁,无法更新,并未持有锁(更具ID更新,就一条数据?看下代码.....从代码看,就是单条操作)
死锁条件:
1.多个并发事务(2个或者以上)
2.每个事物都持有了锁(或者是已经在等待锁)
3.每个事务都需要再继续持有锁(为了完成事务逻辑,还必须更新更多的行)
4.事物之间产生加锁的循环等待,形成死锁
从上面分析,sql1/2并未持有锁,只是在等待获取锁,具体见下,日志分析
todo
五,死锁知识
归纳如下
【1】基本概念
1.通过聚簇索引更新时,会在聚簇索引上加锁。
2.通过二级索引进行更新时,会先对二级索引加锁,然后对聚簇索引加锁。
3.使用聚簇索引更新二级索引时,会先对聚簇加锁,再对二级索引加锁。此结论的前提条件为结论4
4.更新二级索引时,只有二级索引所在的列产生实际变化的更新,才会对二级索引加锁,否则仅会对聚簇索引加锁。
【2】锁知识
1.mysql的事务支持与存储引擎有关,MyISAM不支持事务,INNODB支持事务,更新时采用的是行级锁
2.行级锁必须建立在索引的基础
3.行级锁并不是直接锁记录,而是锁索引,如果一条SQL语句用到了主键索引,mysql会锁住主键索引;如果一条语句操作了非主键索引,mysql会先锁住非主键索引,再锁定主键索引。
4.在并发高的应用中,批量更新一定要带上记录的主键,优先获取主键上锁,这样开业减少死锁的发生
5.在采用INNODB的MySQL中,更新操作默认会加行级锁,行级锁是基于索引的,在分析死锁之前需要查询一下mysql的执行计划,看看是否用到了索引,用到了哪个索引,对于没有用索引的操作会采用表级锁。如果操作用到了主键索引会先在主键索引上加锁,然后在其他索引上加锁,否则加锁顺序相反。在并发度高的应用中,批量更新一定要带上记录的主键,优先获取主键上的锁,这样可以减少死锁的发生。
6. innodb 读不加锁。但是写加了锁,在什么时候加锁呢? 在我们执行一条 update 语句的时候。 在什么时候释放锁呢? 在事务提交的时候。
上面说过 锁会在事务提交的时候释放,所以 两个事务就锁死了。
7.where条件 与表锁/行锁
在 update 语句的 where 条件没有使用索引,就会全表扫描;
where条件里面,不加索引时,update会使用“表锁”进行更新,影响所有行的查询更新;
加了索引后,使用“行锁”进行udpate,只锁当前行。不影响其他行的查询更新。
mysql的行锁是通过索引加载的,即是行锁是加在索引响应的行上的,要是对应的SQL语句没有走索引,则会全表扫描
【3】死锁必要条件
1.产生死锁的必要条件
多个并发事务(2个或者以上)
每个事物都持有了锁(或者是已经在等待锁)
每个事务都需要再继续持有锁(为了完成事务逻辑,还必须更新更多的行)
事物之间产生加锁的循环等待,形成死锁
【4】加锁流程
4.1
对同一条数据,T1通过二级索引更新,T2通过聚簇索引更新T1作为更新条件二级索引,如果T1先拿到二级索引,T2先拿到聚簇索引。此时就会出现T1等T2的聚簇索引,T2等T1的二级索引的死锁
4.2
事物1: 根据二级索引作为条件,更新二级索引;先锁二级索引(相关记录),再锁主键索引(相关记录)
事物2: 根据主键更新数据,更新的字段中包含;先锁主键索引(相关记录),再锁二级索引(相关记录)
形成了(针对单个的一条记录(很多这样记录))
事物1锁定二级索引记录,持有二级索引锁,待获取主键索引锁
事物2锁定主键索引记录,持有主键索引锁,待获取二级索引锁
六,死锁原因,深度分析
七,方案
针对更新3,引发死锁的sql
更新条件为二级索引的sql进行优化,改为先查询id,再根据id更新
mysql死锁的例子_MySQL数据库的一次死锁实例分析_C18298182575的博客-CSDN博客
MySQL造成更新死锁及插入死锁的几种常见原因_yue_hu的博客-CSDN博客_mysql update 死锁
mysql死锁的例子_MySQL数据库的一次死锁实例分析_weixin_39947314的博客-CSDN博客
MySQL InnoDB update锁表问题Record Locks_&夜半钟声到客船&的博客-CSDN博客
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr