语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification[,create_specification]...]
create_specification:
[DEFAULT]CHARACTER SET charset_name
[DEFAULT]COLLATE collation_name
练习:
创建一个名为hsp_db01的数据库[图形和指令演示]
创建一个utf8字符集的hsp_db02的数据库
创建一个使用utf8字符集,并带校对队则的hsp_db03数据库
指令创建:
#演示数据库的操作
#1. 创建一个名为hsp_db01的数据库
CREATE DATABASE hsp_db01;
#删除数据库指令
DROP DATABASE hsp_db01;
#2. 创建一个utf8字符集的hsp_db02的数据库
CREATE DATABASE hsp_db02 CHARACTER SET utf8
#3. 创建一个使用utf8字符集,并带校对队则的hsp_db03数据库
CREATE DATABASE hsp_db03 CHARACTER SET utf8 COLLATE utf8_bin
#校对规则 utf8_bin 区分大小写 默认utf8_general_ci 不区分大小写
可以看见在不指定采用字符集和校验规则的情况下,字符集默认为utf8,校验规则默认为utf8_general_ci
关于字符集和校验规则:
如果在创建表的时候没有指定字符集和校验规则,则遵循和数据库一样的规则
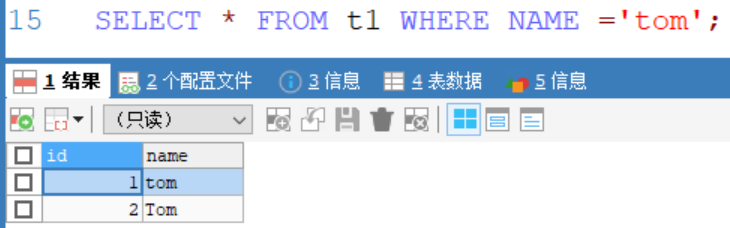
如下:在数据库hsp_db02中创建表t1,t1设为默认字符集和校验规则。
在表t1中用select查询可以得到不区分大小写的两条数据:
在数据库hsp_03中创建同样的表t1并插入同样的数据,查询后只得到一条数据:
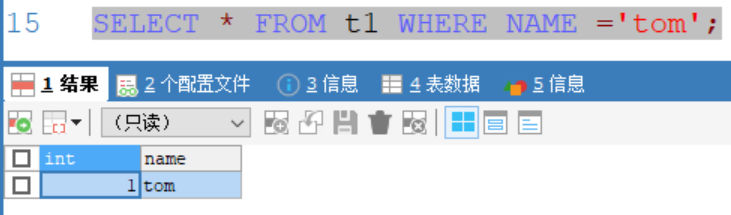
因为数据库hsp_03在创建时指定校验规则为utf8_bin,区分大小写,查询返回的数据也区分了大小写
数据库hsp_02没有指定大小写,返回的查询没有区分大小写
因此可知当表设置默认的字符集和校验规则时,其则遵循数据库的字符集和校验规则
#显示数据库语句
#显示数据库创建时的语句
#数据库删除语句[一定要慎用]
练习
查看当前服务器中的所有数据库
SHOW DATABASES
查看前面创建的hsp_02数据库的定义信息
SHOW CREATE DATABASE hsp_db02

删除前面创建的数据库
关键字作名字创建数据库:
例如:创建一个名为create的数据库,不使用反引号就会报错
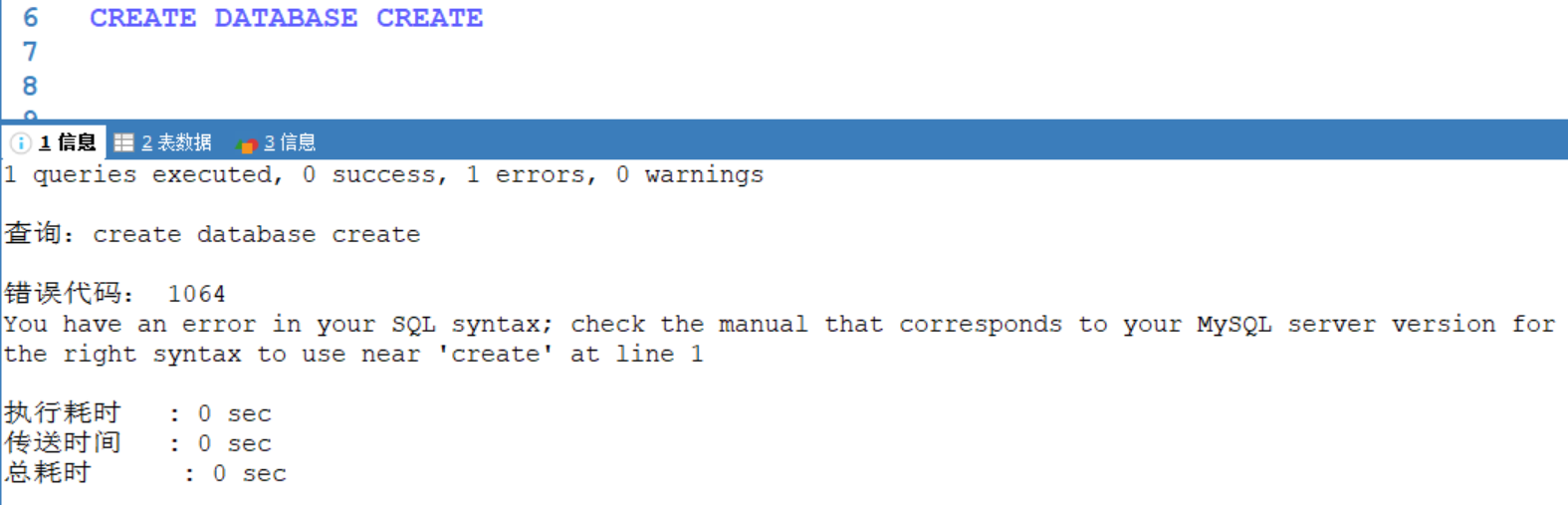
使用了反引号之后,就可以成功创建数据库

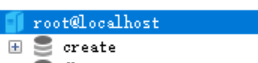
使用关键字创建,在删除的时候也要在名字旁边反引号
备份数据库 (注意:在DOS执行)
mysqldump -u 用户名 -p -B 数据库1 数据库2 数据库n > 文件名.sql
恢复数据库(注意:进入MySQL命令行再执行)
Source 文件名.sql
练习:备份恢复数据库
备份hsp_db02和hsp_db03库中的数据,并恢复
备份:
如下,在Dos窗口下输入指令,指明备份的数据库和保存的文件名
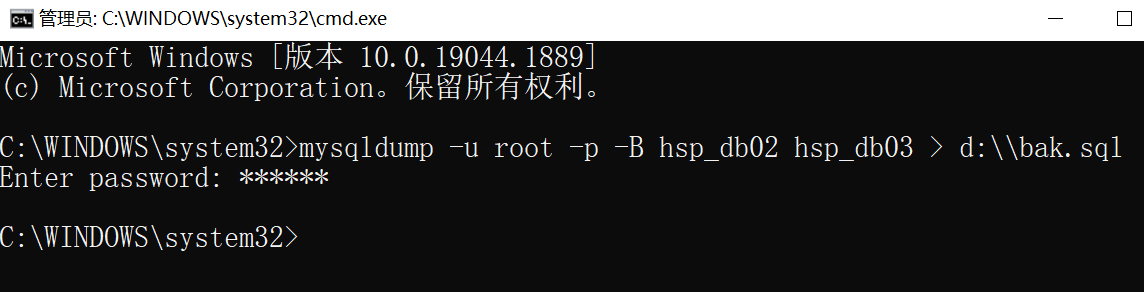
在指定的路径下生成了对应的sql文件

这个备份的文件就是对应的sql语句:
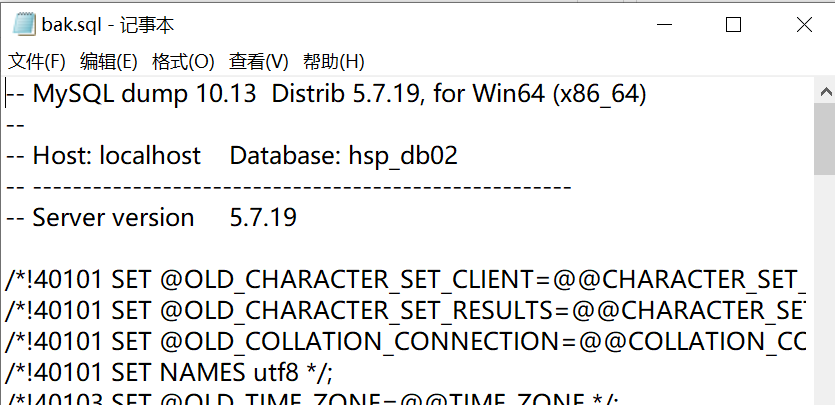
首先删除掉数据库hsp_db02和hsp_db03
登录账号,进入mysql命令行,输入指令 Source d:\\\bak.sql

可以看到数据库及里面的信息成功恢复:
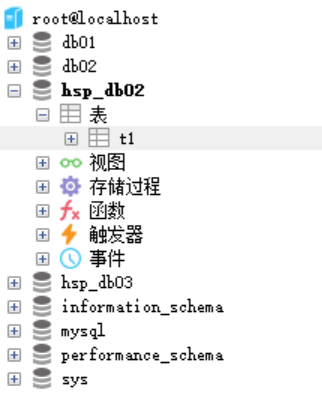
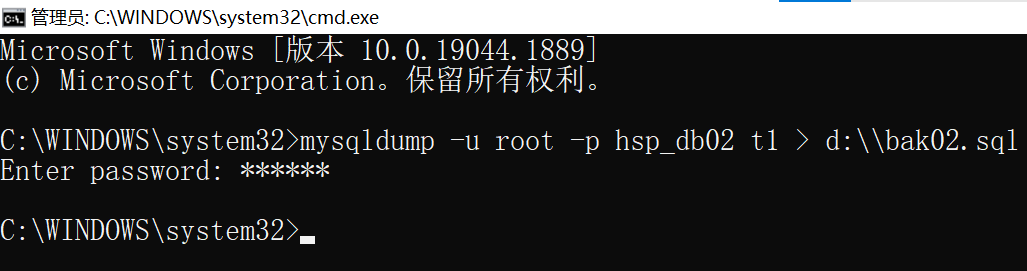
备份数据库的表
mysqldump -u 用户名 -p 数据库 表1 表2 表n > 文件名.sql
(注意:在DOS执行)
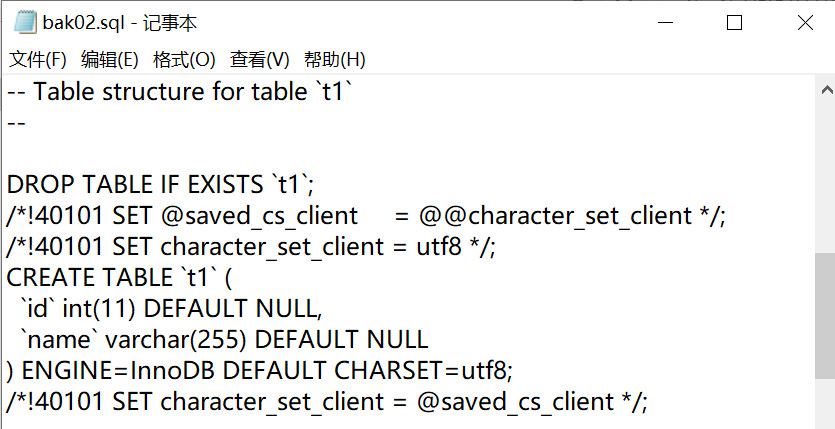
恢复和数据库同理(注意进入mysql命令行执行)
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字符集 collate 校对规则 engine 存储引擎
# field:指定列名 datatype:指定列类型(字段类型)
# character set:如不指定则为所在的数据库字符集
# collate:如不指定则为所在的数据库的校验规则
# engine:引擎(这个涉及较多,后面单独讲解)
练习1
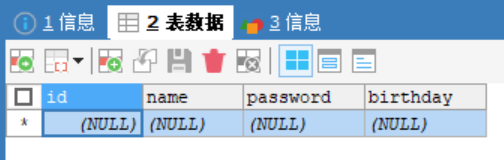
在数据库hsp_db02创建一张表,根据需求的数据创建相应的列,并根据数据的类型定义相应的列类型
user表:
id 整形
name 字符串
passwoed 字符串
birthday 日期
#id 整形
#name 字符串
#passwoed 字符串
#birthday 日期
CREATE TABLE `user`(
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255),
`birthday` DATE)
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
练习2
创建一个员工表,选用适当的数据类型
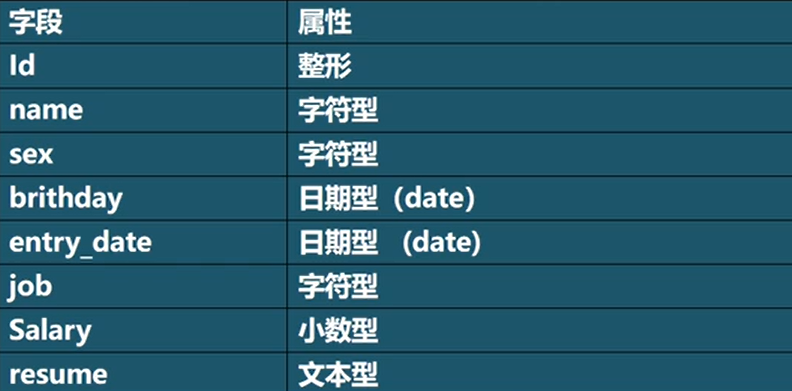
#创建表的课堂练习
CREATE TABLE emplyee(
id INT,
`name` VARCHAR(32),
sex CHAR(1),
birthday DATE,
entry_date DATE,
job VARCHAR(32),
Salary FLOAT,
`resume` TEXT ) CHARSET utf8 COLLATE utf8_bin ENGINE INNODB;
-- 添加一条数据
INSERT INTO emplyee VALUES (
100,'小妖怪','男','2000-11-11',
'2010-11-10','巡山的',3000,'大王叫我来巡山');
SELECT * FROM emplyee ;

使用ALTER TABLE 语句追加,修改,或删除列的语法
添加列:
ALTER TABLE tablename
ADD (column datatype [DEFAULT expr][,column datatype]...);
修改列:
ALTER TABLE tablename
MODIFY (column datatype [DEFAULT expr][,column datatype]...);
删除列:
ALTER TABLE tablename
DROP (column);
查看表的结构:desc 表名; -- 可以查看表的列
修改表名:
Rename table 表名 to 新表名;
修改表的字符集:
alter table 表名 character set 字符集;
应用案例
# 修改表的操作练习
-- 1. 在员工表上增加一个image列,为vachar类型(要求在resume后面)
ALTER TABLE emplyee
ADD image VARCHAR(32) NOT NULL DEFAULT ''
AFTER RESUME;
-- 2. 修改job列,使其长度为60
ALTER TABLE emplyee
MODIFY job VARCHAR(60) NOT NULL DEFAULT ''
-- 3. 删除sex列
ALTER TABLE emplyee
DROP sex;
-- 4. 表名修改为emp
RENAME TABLE emplyee TO emp;
-- 5. 修改表的字符集为utf8
ALTER TABLE emp CHARACTER SET utf8;
-- 6. 列名name修改为user_name
ALTER TABLE emp
CHANGE `name` user_name VARCHAR(64) NOT NULL DEFAULT ''
DESC emp -- 显示表结构,可以查看表的所有列
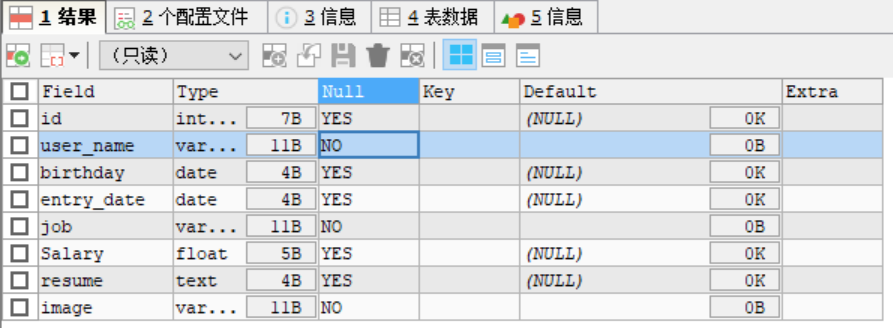
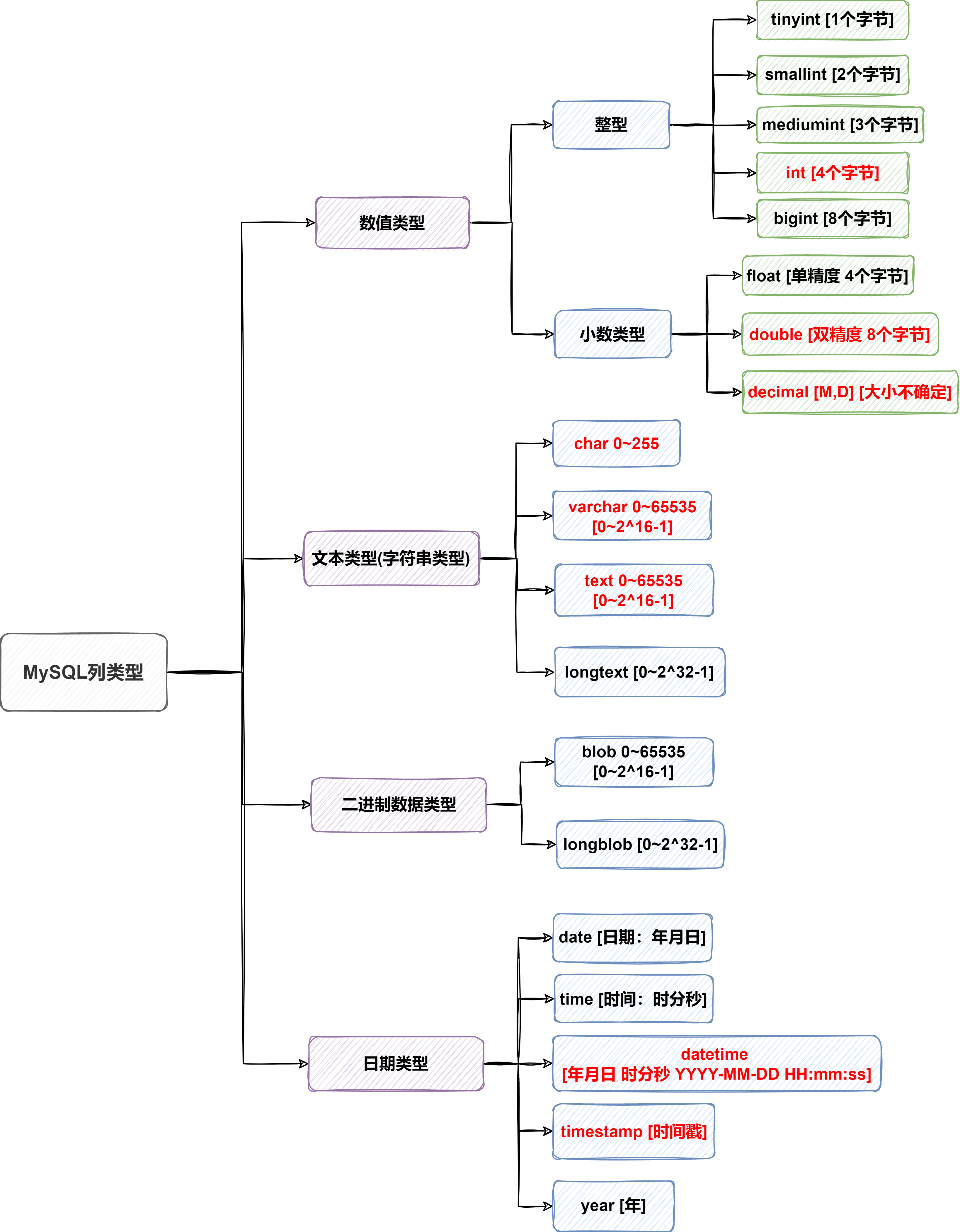

Mysql列类型即mysql的数据类型
详见MySQL的参考手册
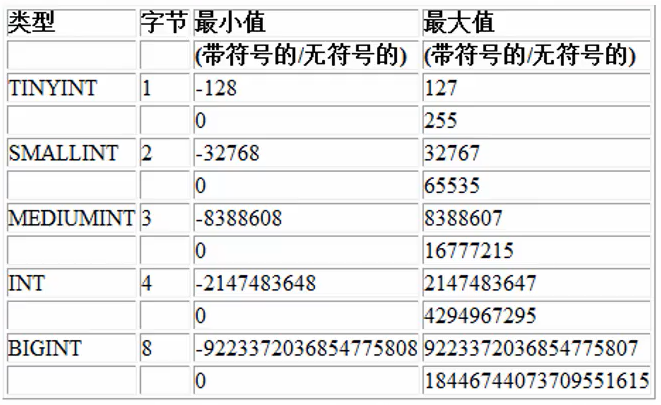
数值型(整型)的基本使用
说明:使用规范:在能够满足需求的情况下尽量选择空间小的类型
应用实例
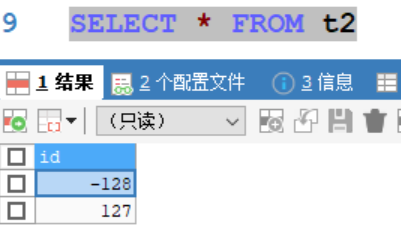
CREATE TABLE t2(
id TINYINT);
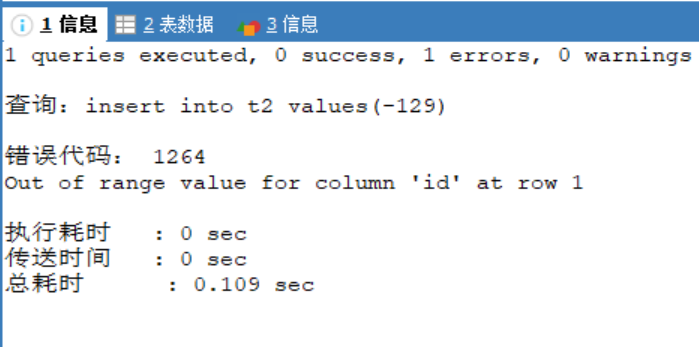

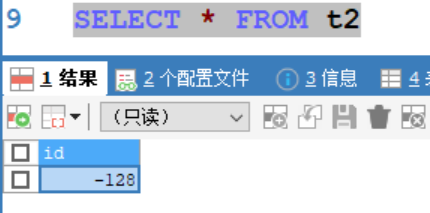
同理,分别往表中插入数据128、127,只有127插入成功
说明在有符号情况下,tinyint的范围为-128~127
在列类型后面指定无符号
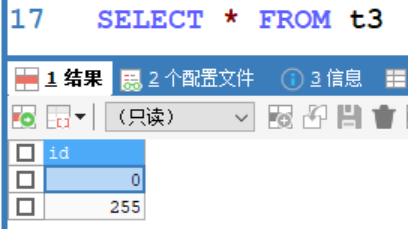
CREATE TABLE t3(
id TINYINT UNSIGNED);
INSERT INTO t3 VALUES(-1);#错误,超出范围
INSERT INTO t3 VALUES(0);
INSERT INTO t3 VALUES(256);#错误,超出范围
INSERT INTO t3 VALUES(255);
练习
#演示bit类型使用
#说明
#1.bit(M) M在1-64位
#2.添加数据 的范围是按照你给定的M的位数来确定,例如M=8 表示一个字节(8bit) 0~255
create table t5 (num bit(8));
INSERT INTO t5 VALUES(5);
insert into t5 values(3);
select * from t5;
#3.查询时仍然可以按照十进制数来查询
select * from t5 where num = 5;
FLOAT/DOUBLE[UNSIDNED]
float 单精度,double 双精度
DECIMAL[M,D] [UNSIGNED]
可以支持更加精确的小数位。M是小数位数(精度)的总数,D是小数点(标度)后面的位数。
如果D是0,则值没有小数点或分数部分。M最大65,D最大是30。如果D被省略,默认D是0;如果M被省略,默认M是10.
建议:如果希望小数点的精度高,推荐使用decimal
练习
#案例演示 float、double、decimal的使用
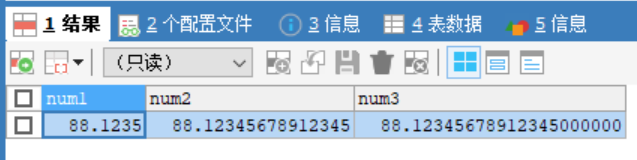
CREATE TABLE t6(
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20));
#添加数据
INSERT INTO t6 VALUES(88.12345678912345,88.12345678912345,88.12345678912345);
#查询
SELECT * FROM t6;
#decimal可以存放很大的数
说明
字符串的基本使用:
CHAR(size)
固定长度字符串 最大255字符
VARCHAR(size)
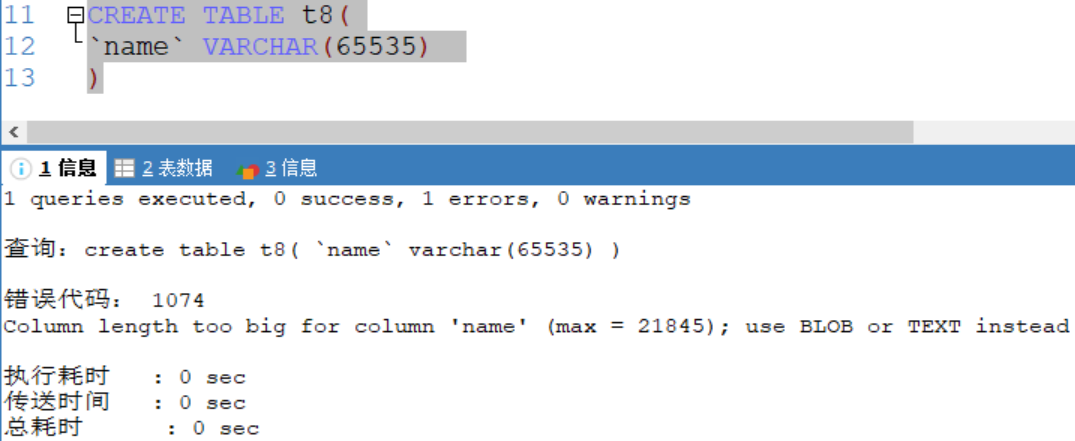
可变长度字符串 最大65532字节
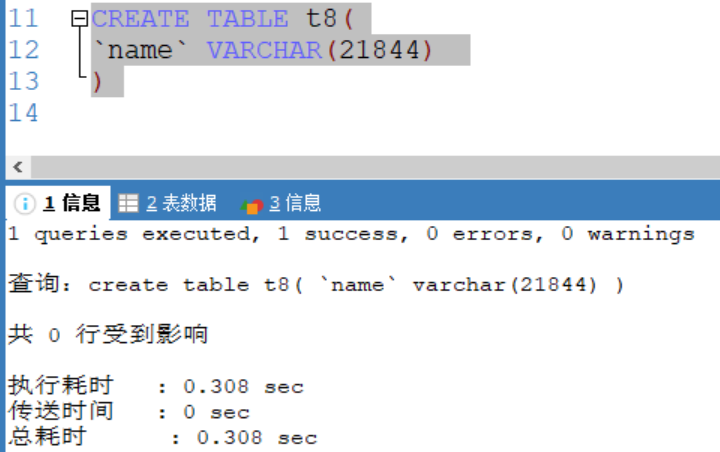
[ utf8编码最大字符为21844字符,1-3个字节用于记录大小,uft8编码每个字符占用三个字节 ]
如果编码是uft8 则varchar(size) size = (65535-3) / 3 = 21844
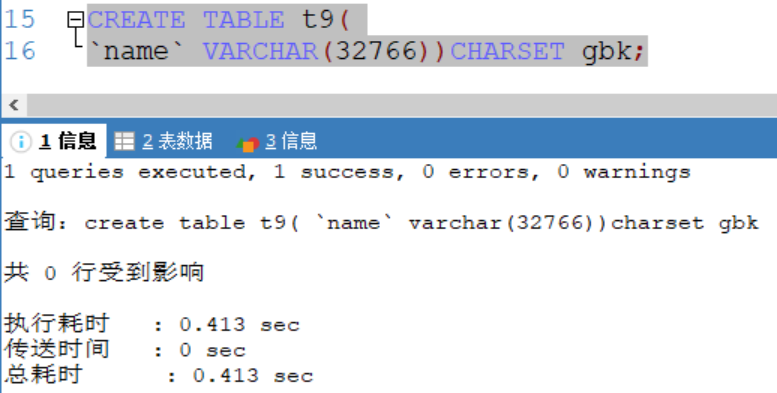
如果编码是gbk 则varchar(size) size = (65535-3) / 2 = 32766
错误使用:(uft8)
成功插入:(uft8)
gbk字符集下:
字符串使用细节
细节1:
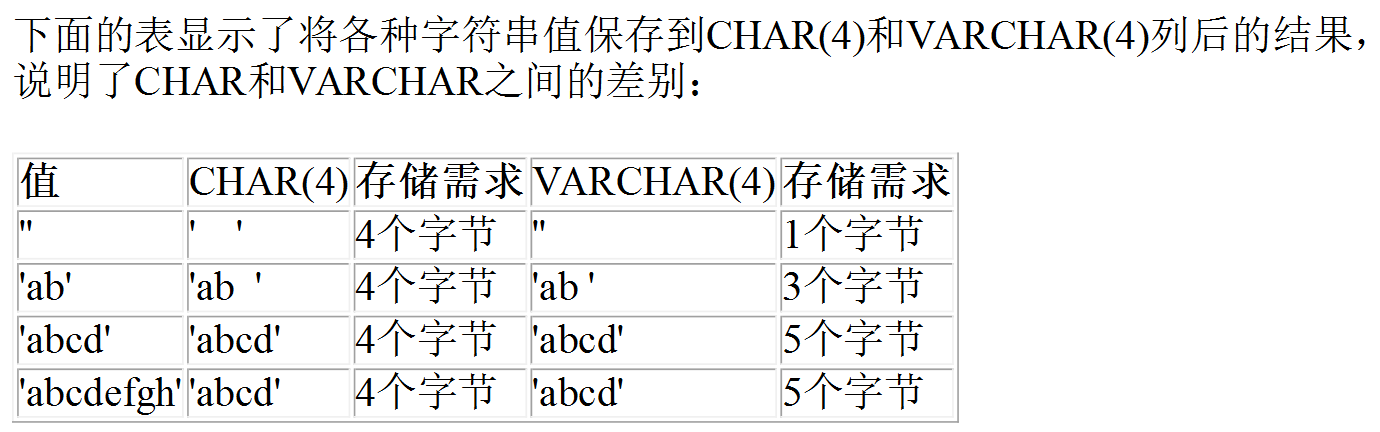
如 char(4) //这个4表示字符数(最大255),不是字节数,不管是中文还是字母都是放四个,按字符计算
varchar(4) //这个4表示字符数,(这四个字符占用多少个字节取决于你定义的编码) 不管是字母还是中文都以定义好的表的编码来存放数据
上面的例子不管是中文还是字母都是最多存放4个,是按照字符来存放的
细节2:
细节3:使用的的时机
细节4:
例子:
在下图中,不管插入的是中文还是字母,每一个都按一个字符来算,因此'abcde'相当5个字符长度,插入失败;varchar同理。
失败:
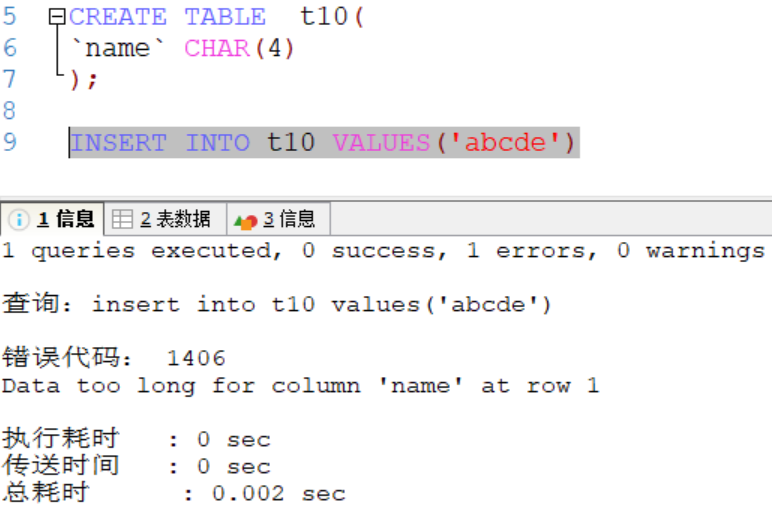
成功:
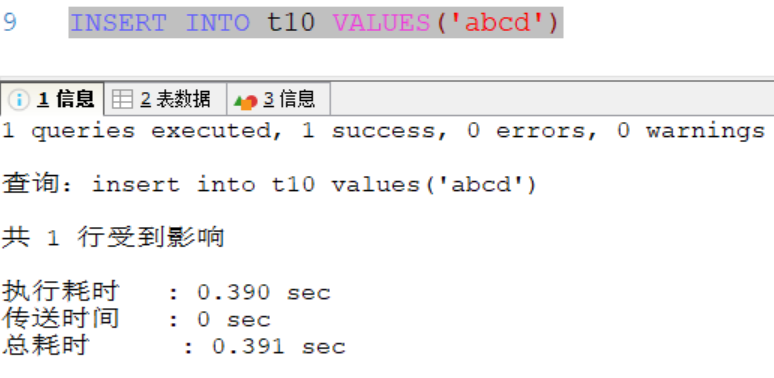
例子2:关于text,mediumtext 和 longtext的使用
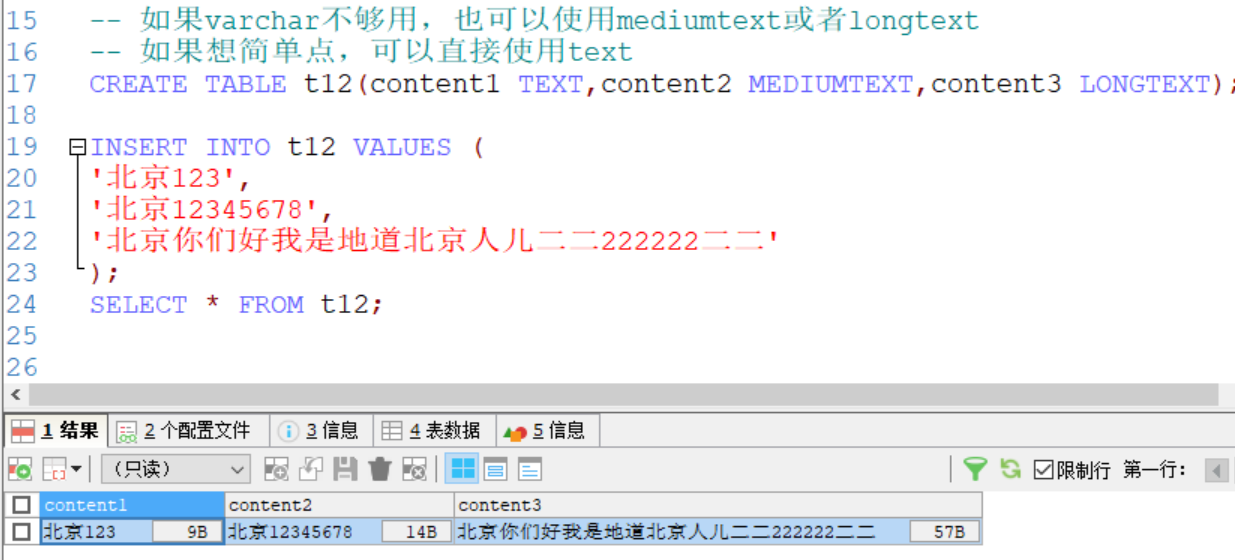
如上图所示:在插入的数据后面显示了实际使用的数值大小
content1有两个中文=2*3=6bit,每个数字占用一个字节,共计9bit
content2也有两个中文=2*3=6bit,有八个数字,共计14bit
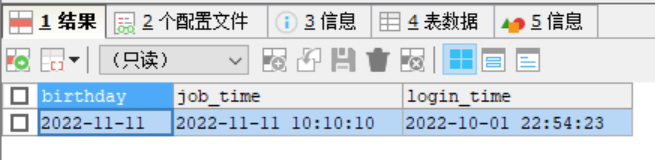
日期类型的细节说明
TimeStamp在Insert和Update时,会自动更新
例子:
#演示时间相关的案例
#创建一张表,data ,datatime,timestamp
CREATE TABLE t13(
birthday DATE,-- 生日
job_time DATETIME,-- 记录年月日 时分秒
login_time TIMESTAMP
NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP);-- 登录时间,如果希望login_time列自动更新,需要配置
INSERT INTO t13(birthday,job_time)
VALUES('2022-11-11','2022-11-11 10:10:10');
#如果我们更新了t13的某条记录,login_time会自动地以当前时间来进行更新
SELECT * FROM t13;
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
1.在Python3中,下列关于数学运算结果正确的是:(B)a=10b=3print(a//b)print(a%b)print(a/b)A.3,3,3.3333...B.3,1,3.3333...C.3.3333...,3.3333...,3D.3.3333...,1,3.3333...解析: 在Python中,//表示地板除(向下取整),%表示取余,/表示除(Python2向下取整返回3)2.如下程序Python2会打印多少个数:(D)k=1000whilek>1: print(k)k=k/2A.1000 B.10C.11D.9解析: 按照题意每次循环K/2,直到K值小于等
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
我有一个任务列表(名称、starts_at),我试图在每日View中显示它们(就像iCal)。deftodays_tasks(day)Task.find(:all,:conditions=>["starts_atbetween?and?",day.beginning,day.ending]end我不知道如何将Time.now(例如“2009-04-1210:00:00”)动态转换为一天的开始(和结束),以便进行比较。 最佳答案 deftodays_tasks(now=Time.now)Task.find(:all,:conditio
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?