我有一个以 UTF-8 编码的 XSD 文件,我运行它的任何文本编辑器都没有在文件的开头显示任何字符,但是当我在 Visual Studio 的调试器中将它拉出来时,我清楚看到文件前面有一个空框。
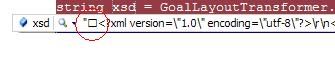
我也得到了错误:
根级别的数据无效。第 1 行,位置 1。
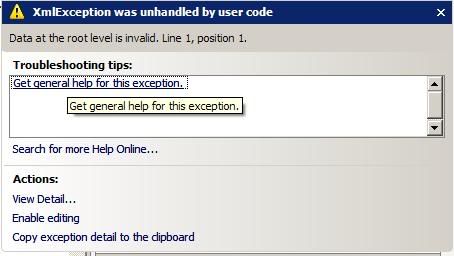
有人知道这是什么吗?
更新:编辑帖子以限定文件类型。它是由 Microsoft 的 XSD 创建者创建的 XSD 文件。
最佳答案
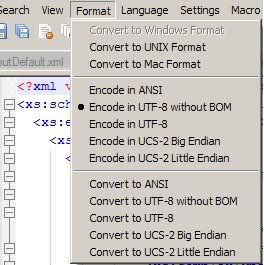
事实证明,答案是我看到的是 Byte Order Mark ,这是一个字符,它告诉加载文档的内容是什么。在我的例子中,它是用 utf-8 编码的,所以相应的 BOM 是 EF BB BF,如下所示。要删除它,我在 Notepad++ 中将其打开然后点击“Encode in UTF-8 without BOM”,如下图:
 .
.
要实际查看 BOM,我必须在 TextPad 中打开它在二进制模式下:,并进行了 Google search for "EF BB BF" .

我花了大约 8 个小时才找出是什么原因造成的,所以我想我应该与大家分享。
更新:如果我读过 Joel Spolsky 的博文:The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) ,那么我可能没有遇到过这个问题。
关于.net - XML - 根级别的数据无效,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/291455/
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD