linux下有时因为文件过大,传输过程中需要将源文件压缩成zip分卷压缩文件,以下是具体方法
首先看一下版本
zip -r -s 1m log.zip log/
-r 代表递归子目录(如果没有加压缩出来只包含一个空目录)
-s 1m代表分卷大小(这里我进行测试所以设置的比较小,正式使用一般设置为1g)
log.zip为压缩包名
log/为待压缩的目录
执行压缩:


对于一个大的文件,使用分卷压缩得到如下文件:
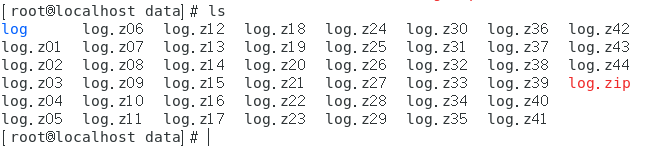
先压缩后分卷
zip -r log.zip log
先压缩成一个压缩文件
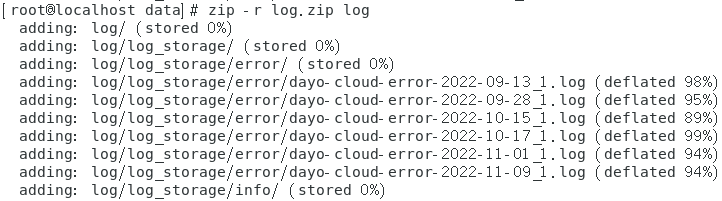


对压缩文件进行分卷处理
zip -s 5m log.zip --out new.zip
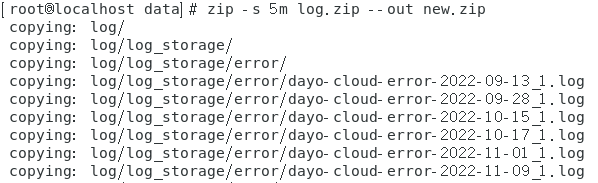

这里生成 new.zip new.z01 new.z02 new.z03 … 表示成功

zip -s 0 log.zip --out LOG.zip
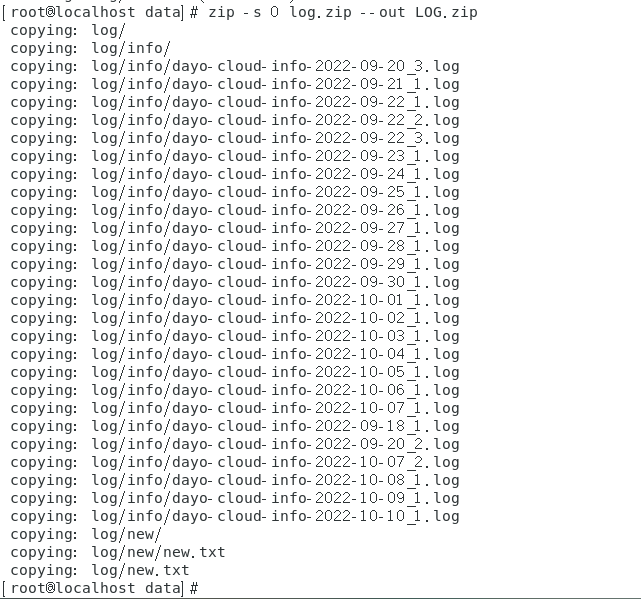
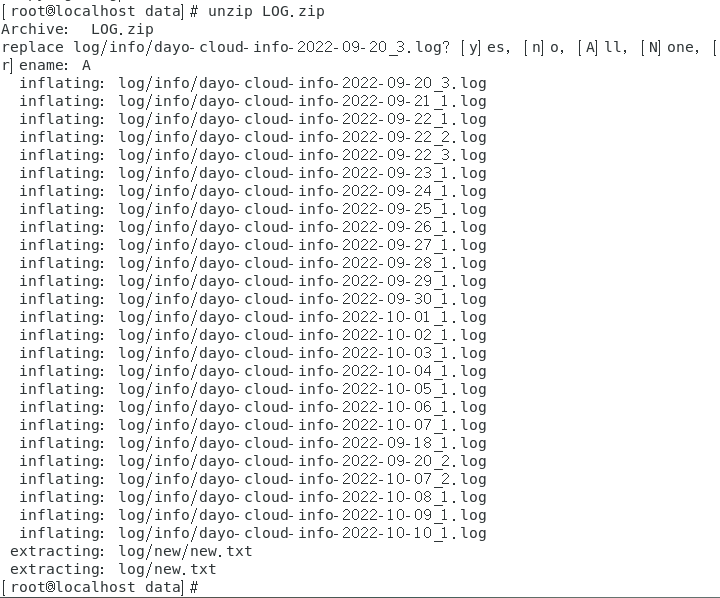
unzip LOG.zip
我这里是刚刚进行压缩了,源文件没有删除这里提示是否进行覆盖我这里输入A进行全部覆盖

1.在Linux目录下,如果要解压出来,可以先使用zip -F命令修复分卷,合成正确的一个压缩文件再进行解压
zip -F log.zip --out LOG.zip
-F 后是要修复的压缩文件
–out 后是修复合并出来的用于解压缩的压缩文件
执行修复压缩文件:
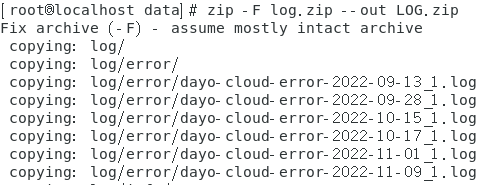

得到 LOG.zip
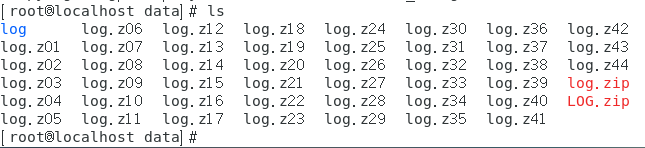
然后解压 LOG.zip 即可
unzip LOG.zip
我这里是刚刚进行压缩了,源文件没有删除这里提示是否进行覆盖我这里输入A进行全部覆盖

解压成功:
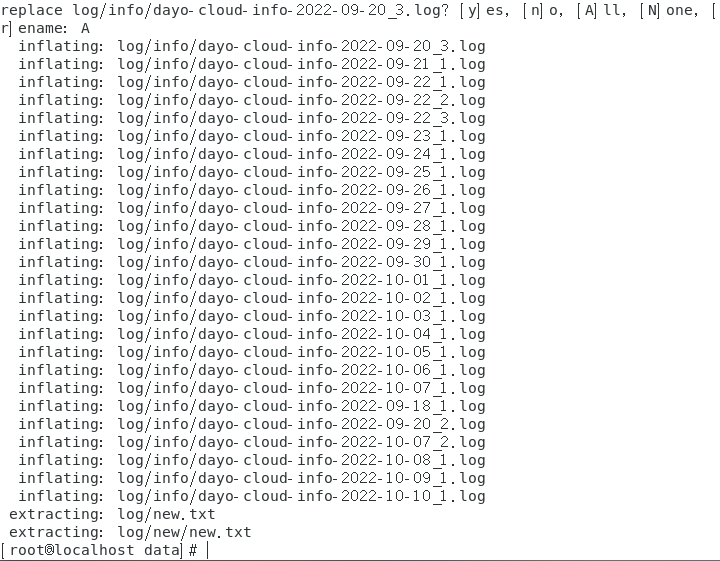
1.先合并文件
cat log.z* > LOG.zip

2.解压
unzip LOG.zip
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
是否有任何可用于Ruby的开源压缩/解压库?有没有人实现过LZW?或者,是否有任何使用压缩组件的开源库可以提取出来独立使用?编辑——感谢您的回答!我应该提到我必须压缩的是只驻留在数据库中的长字符串(我不会压缩文件)。此外,如果可以执行此操作的任何库都具有用于客户端压缩/分解的等效JavaScript实现,那将是理想的,因为这将用于Web应用程序。 最佳答案 您会在rubystdlib下找到所有已交付的ruby库的一个很好的列表.我会使用zlib库,它是开放的,无处不在,您会发现几乎所有语言的库!
我有一个包含100多个zip文件的目录,我需要读取zip文件中的文件以进行一些数据处理,而无需解压缩存档。是否有一个Ruby库可以在不解压缩文件的情况下读取zip存档中的文件内容?使用rubyzip报错:require'zip'Zip::File.open('my_zip.zip')do|zip_file|#Handleentriesonebyonezip_file.eachdo|entry|#Extracttofile/directory/symlinkputs"Extracting#{entry.name}"entry.extract('here')#Readintomemoryc
我有一个正在HerokuCedar堆栈上部署的Rails3.2应用程序。这意味着应用程序本身负责为其静态Assets提供服务。我希望对这些Assets进行gzip压缩,所以我在production.rb的中间件堆栈中插入了Rack::Deflater:middleware.insert_after('Rack::Cache',Rack::Deflater)...curl告诉我这与宣传的一样有效。但是,由于Heroku将全力运行rakeassets:precompile,生成一堆预gzipAssets,我很想使用它们(而不是让Rack::Deflater再次完成所有工作)。我已经看到使用
我想知道与使用native操作系统库执行压缩相比,使用rubyzip压缩数据时的性能差异是什么。我正在从URL获取要压缩的数据,然后使用ZipOutputStream创建zip文件。对于native操作系统实用程序,我正在考虑使用zip工具。很高兴听到这两种方法的优缺点。 最佳答案 事实证明,无论是运算时间还是CPU使用率,都没有太大差异。但是在内存使用方面存在显着差异。与使用ziputil相比,使用rubyzip的过程最终会使用更多的内存。在我们的用例中,内存使用是一个重要问题,因此我们最终使用了zip实用程序。
我知道如何使用rubyzip检索普通zip文件的内容。但是我在解压缩压缩文件夹的内容时遇到了问题,我希望你们中的任何人都能帮助我。这是我用来解压的代码:Zip::ZipFile::open(@file_location)do|zip|zip.eachdo|entry|nextifentry.name=~/__MACOSX/orentry.name=~/\.DS_Store/or!entry.file?logger.debug"#{entry.name}"@data=File.new("#{Rails.root.to_s}/tmp/#{entry.name}")endendentry
我想每周更新一个城市表以反射(reflect)世界各地城市的变化。为此,我正在创建一个Rake任务。如果可能,我希望在不添加其他gem依赖项的情况下执行此操作。压缩文件是在geonames.org/15000cities.zip上公开可用的压缩文件.我的尝试:require'net/http'require'zip'namespace:geocitiesdodesc"RaketasktofetchGeocitiescitylistevery3days"task:fetchdouri=URI('http://download.geonames.org/export/dump/cities
假设我有这个:[{:user_id=>1,:search_id=>a},{:user_id=>1,:search_id=>b},{:user_id=>2,:search_id=>c},{:user_id=>2,:search_id=>d}]我想结束:[{:user_id=>1,:search_id=>[a,b]},{:user_id=>2,:search_id=>[c,d]}]最好的方法是什么? 最佳答案 确实是非常奇怪的要求。无论如何[{:user_id=>1,:search_id=>"a"},{:user_id=>1,:sear
我有一个ruby脚本,它使用rubysopen命令从服务器下载远程ZIP文件。当我查看下载的内容时,它显示如下内容:PK\x03\x04\x14\x00\b\x00\b\x00\x9B\x84PG\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\n\x00\x10\x00foobar.txtUX\f\x00\x86\v!V\x85\v!V\xF6\x01\x14\x00K\xCB\xCFOJ,RH\x03S\\\x00PK\a\b\xC1\xC0\x1F\xE8\f\x00\x00\x00\x0E\x00\x00\x00PK\x0
我已经写了一些csv文件并压缩它,使用这个代码:arr=(0...2**16).to_aFile.open('file.bz2','wb')do|f|writer=Bzip2::Writer.newfCSV(writer)do|csv|(2**16).times{csv我想阅读这个csvbzip2ed文件(用bzip2压缩的csv文件)。这些未压缩的文件如下所示:1,24,125,28,71,3...所以我尝试了这段代码:Bzip2::Reader.open(filename)do|bzip2|CSV.foreach(bzip2)do|row|putsrow.inspectendend