目录
蚁群算法(Ant Colony Optimization,ACO)由Dorigo 等人于1991年在第一届欧洲人工生命会议(European Conference on Artificial Intelligence,ECAL)上提出,是模拟自然界真实蚂蚁觅食过程的一种随机搜索算法。蚁群算法与遗传算法(GeneticAlgorithm,GA)、粒子群优化算法(Particle Swarm Optimization,PSO)、免疫算法(Immune Algorithm,IA)等同属于仿生优化算法,具有鲁棒性强、全局搜索、并行分布式计算、易与其他方法结合等优点,在典型组合优化问题如旅行商问题(Traveling SalesmanProblem,TSP)、车辆路径问题(Vehicle Routing Problem,VRP),车间作业调度问题(Job-shop Scheduling Problem,JSP)和动态组合规划问题如通信领域的路由问题中均得到了成功的应用。
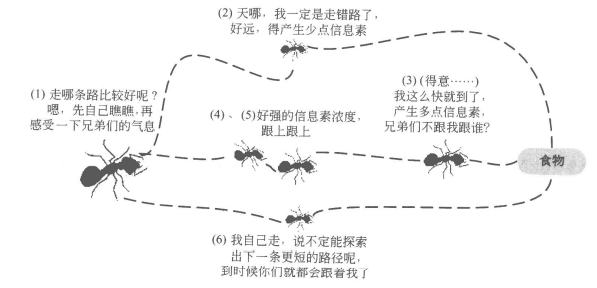
在自然界中,蚂蚁群体在寻找食物的过程中,无论是蚂蚁与蚂蚁之间的协作还是蚂蚁与环境之间的交互均依赖于一种被称为信息素(Pheromone)的物质实现蚁群的间接通信,从而通过合作发现从蚁穴到食物源的最短路径。
蚂蚁在寻找食物的过程中往往是随机选择路径的,但它们能感知当前地面上的信息素浓度,并倾向于往信息素浓度高的方向行进。信息素由蚂蚁自身释放,是实现蚁群内间接通信的物质。由于较短路径上蚂蚁的往返时间比较短,单位时间内经过该路径的蚂蚁多,所以信息素的积累速度比较长路径快。因此,当后续蚂蚁在路口时,就能感知先前蚂蚁留下的信息,并倾向于选择一条较短的路径前行。这种正反馈机制使得越来越多的蚂蚁在巢穴与食物之间的最短路径上行进。由于其他路径上的信息素会随着时间蒸发,最终所有的蚂蚁都在最优路径上行进。
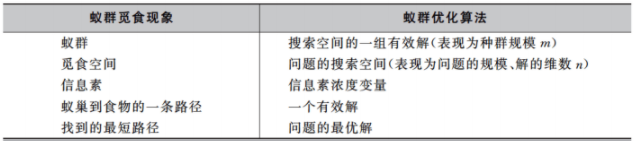
通过对自然界蚁群觅食过程进行抽象建模,我们可以对蚁群觅食现象和蚁群优化算法中的各个要素建立一 一 对应关系:
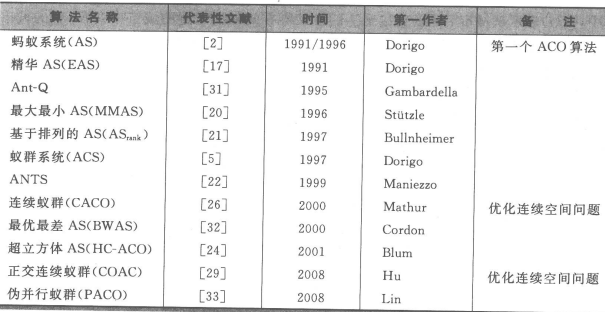
蚂蚁系统(Ant System,AS)是最基本的ACO算法,是以TSP作为应用实例提出的。
AS对于TSP的求解流程大致可分为两步:路径构建和信息素更新。
伪随机比例选择规则(random proportional)。
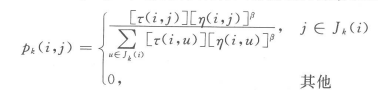
对于每只蚂蚁k,路径记忆向量按照访问顺序记录了所有k已经经过的城市序号。设蚂蚁k当前所在城市为i,则其选择城市j作为下一个访问对象的概率如上式。
表示从城市i可以直接到达的、且又不在蚂蚁访问过的城市序列
中的城市集合。η(i, j)是一个启发式信息,通常由
直接计算。
表示边(i, j)上的信息素量。
长度越短、信息素浓度越大的路径被蚂蚁选择的概率越大。a和b是两个预先设置的参数,用来控制启发式信息与信息素浓度作用的权重关系。当a=0时,算法演变成传统的随机贪心算法,最邻近城市被选中的概率最大。当b=0时,蚂蚁完全只根据信息素浓度确定路径,算法将快速收敛,这样构建出的最优路径往往与实际目标有着较大的差异,算法的性能比较糟糕。
可以结合下面公式来看哦:

m是蚂蚁个数;r是信息素的蒸发率,规定。
是第k只蚂蚁在它经过的边上释放的信息素量,它等于蚂蚁k本轮构建路径长度的倒数。
表示路径长度,它是
中所有边的长度和。

接着,我们结合一个实例来做进一步介绍


步骤2.2中有提到轮盘赌法。是的,和我们遗传算法用的是一样的(当然后面新的方法会有不一样)。
轮盘赌法具体怎么操作,在这里稍微解释一下:
比方说,现在A占比为0.2,B占比为0.5,C占比为0.3。
则当你随机值大小位于为0-0.2时,选A,大小位于0.2-0.7时,选B,大小位于0.7-1.0时,选C。
精华蚂蚁系统(Elitist Ant System,EAS)是对基础AS的第一次改进,它在原AS信息素更新原则的基础上增加了一个对至今最优路径的强化手段。

引入这种额外的信息素强化手段有助于更好地引导蚂蚁搜索的偏向,使算法更快收敛。
基于排列的蚂蚁系统(rank-based Ant System,)在AS的基础上给蚂蚁要释放的信息素大小加上一个权值,进一步加大各边信息素量的差异,以指导搜索。在每一轮所有蚂蚁构建完路径后,它们将按照所得路径的长短进行排名,只有生成了至今最优路径的蚂蚁和排名在前(ω-1)的蚂蚁才被允许释放信息素,蚂蚁在边(i, j)上释放的信息素 的权值由蚂蚁的排名决定。

权值(ω−k)对不同路径的信息素浓度差异起到了一个放大的作用,能更有力度地指导蚂蚁搜索。
最大最小蚂蚁系统(MAX-MIN Ant System,MMAS)在基本AS算法的基础上进行了四项改进:
1997年,蚁群算法的创始人Dorigo在“Ant colony system: a cooperative learning approach to the traveling salesman problem”一文中提出了一种具有全新机制的ACO算法——蚁群系统(Ant Colony System,ACS),进一步提高了ACO算法的性能。
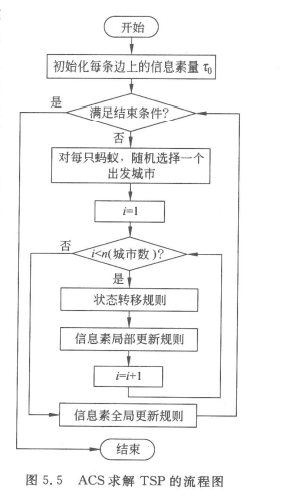
(1)使用一种伪随机比例规则(pseudorandom proportional)选择下城市节点,建立开发当前路径与探索新路径之间的平衡。

是一个[0, 1]区间内的参数,当产生的随机数q≤
时,蚂蚁直接选择使启发式信息与信息素量的指数乘积最大的下城市节点,我们通常称之为开发(exploitation);反之,当产生的随机数q>
时ACS将和各种AS算法一样使用轮盘赌选择策略,我们称之为偏向探索(bias exploration)。
通过调整,我们能有效调节“开发”与“探索”之间的平衡,以决定算法是集中开发最优路径附近的区域,还是探索其它的区域。
(2)使用信息素全局更新规则,每轮迭代中所有蚂蚁都已构建完路径后,在属于至今最优路径的边上蒸发和释放信息素。

其中,不论是信息素的蒸发还是释放,都只在属于至今最优路径的边上进行,这里与AS有很大的区别。因为AS算法将信息素的更新应用到了系统的所有边上,信息素更新的计算复杂度为
,而ACS算法的信息素更新计算复杂度降低为O(n)。参数ρ代表信息素蒸发的速率,新增加的信息素 被乘上系数ρ后,更新后的信息素浓度被控制在旧信息素量与新释放的信息素量之间,用一种隐含的又更简单的方式实现了MMAS算法中对信息素量取值范围的限制。
(3)引入信息素局部更新规则,在路径构建过程中,对每一只蚂蚁,每当其经过一条边(i, j)时,它将立刻对这条边进行信息素的更新。


信息素局部更新规则作用于某条边上会使得这条边被其他蚂蚁选中的概率减少。这种机制大大增加了算法的探索能力,后续蚂蚁倾向于探索未被使用过的边,有效地避免了算法进入停滞状态。
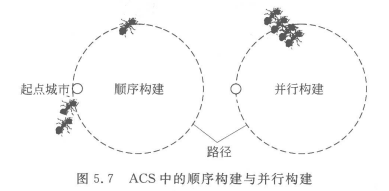
顺序构建和并行构建。顺序构建是指当一只蚂蚁完成一轮完整的构建并返回到初始城市之后,下一只蚂蚁才开始构建;并行构建是指所有蚂蚁同时开始构建,每次所有蚂蚁各走一步(从当前城市移动到下一个城市)。对于ACS,要注意到两种路径构建方式会造成算法行为的区别。
在ACS中通常我们选择让所有蚂蚁并行地工作。
6.5 连续正交蚁群系统
连续正交蚁群算法(Continuous Orthogonal Ant Colony, COAC):近年来,将应用领域扩展到连续空间的蚁群算法也在发展,连续正交蚁群就是其中比较优秀的一种。COAC通过在问题空间内自适应地选择和调整一定数量的区域,并利用蚂蚁在这些区域内进行正交搜索、在区域间进行状态转移、并更新各个区域的信息素来搜索问题空间中的最优解。
COAC的基本思想是利用正交试验的方法将连续空间离散化。



洋洋就介绍到这里了,我也是初次学,请大家指教,有问题之间评论或私聊即可,看到就会回复哦,先说好,我不知我什么时候会上线哦,有时候一个星期也不来一次的。哈哈哈!
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva