如何编写从文件名获取标题和年份(如果可用)的正则表达式?请参阅下面的示例。
此解决方案适用于 php,但我在将其转换为 javascript 时遇到问题 Seprate movie name and year from moviefile name
The.Great.Gatsby.2013.BluRay.1080p.DTS.x264-CHD.mkv
The Forbidden Girl 2013 BRRIP Xvid AC3-BHRG.avi
Pain.&.Gain.2013.720p.BluRay.DD5.1.x264-HiDt.mkv
Se7en.avi
Se7en.(1995).avi
How to train your dragon 2.mkv
10,000BC (2010).1080p.avi
最佳答案
下面提供的解决方案适用于您提供的所有测试用例(以及一些额外的标题,请参阅下面的代码)并且可以自定义。
长话短说,试试下面的片段:
// Live Test
var input = document.getElementById('input');
var output = document.getElementById('output');
input.oninput = function() { output.textContent = extractData(input.value); }
// Samples
var tests = ['The.Great.Gatsby.2013.BluRay.1080p.DTS.x264-CHD.mkv', 'The Forbidden Girl 2013 BRRIP Xvid AC3-BHRG.avi', 'Pain.&.Gain.2013.720p.BluRay.DD5.1.x264-HiDt.mkv', 'Se7en.(1995).avi', 'How to train your dragon 2.mkv', '10,000BC (2010).1080p.avi', 'The.Great.Gatsby.BluRay.1080p.DTS.x264-CHD.mkv', 'Se7en.avi', '2001 A Space Odyssey.BluRay.1080p.DTS.x264-CHD.mkv','Sand.Castle.2017.FRENCH.1080.WEBRip.AAC2.0-NEWCiNE-WwW.Zone-Telechargement.Ws.mkv'];
while (t = tests.pop()) {
document.getElementById('list').innerHTML += '<b>INPUT</b>: "' + t + '"<br>';
document.getElementById('list').innerHTML += extractData(t,true) + '<hr>';
}
function titlelize(title) {
return title.replace(/(^|[. ]+)(\S)/g, function(all, pre, c) { return ((pre) ? ' ' : '') + c.toUpperCase(); });
};
function extractData(it, html) {
var regex = /^(.+?)[.( \t]*(?:(19\d{2}|20(?:0\d|1[0-9])).*|(?:(?=bluray|\d+p|brrip|webrip)..*)?[.](mkv|avi|mpe?g|mp4)$)/i;
var out = '↳ ';
if ( m = regex.exec(it) ) {
title = titlelize(m[1]) || '-'; year = m[2] || '-';
out += '<font color="green"><b>Title</b>: "' + title +
'"  <b>Year</b>: "' + year + '"</font>';
} else {
out += '<font color="red">No match</font>';
}
//the replace is an hack to remove html in live input text
return (html) ? out : out.replace(/<[^>]+>|&[^;]+;/g,'');
}<mark><b>Paste and Try!</b></mark> ⇒ <input id="input" type="text" size="70" />
<br>↳ <span id="output" style="line-height:40px;">No Match</span>
<hr>
<div id="list"></div>
描述
假设标题的结构大致如下:
Title* || [ Year* ] || [ Codec ] Extension
The fields enclosed in square brackets are optional (e.g [field1])
* : field saved
关键是将所有内容匹配为 title 直到找到最后一个有效的 year(有效年份:1900-2016)或直到文件 extension(结构为一个点加 3 个字母,如果需要可以轻松更改)。
异常(exception):如果电影的所有部分都不包含有效年份(不区分大小写)bluray 或 [0-9 ]+p(例如 720p、1080p)或 brrip 从 title 部分中删除。
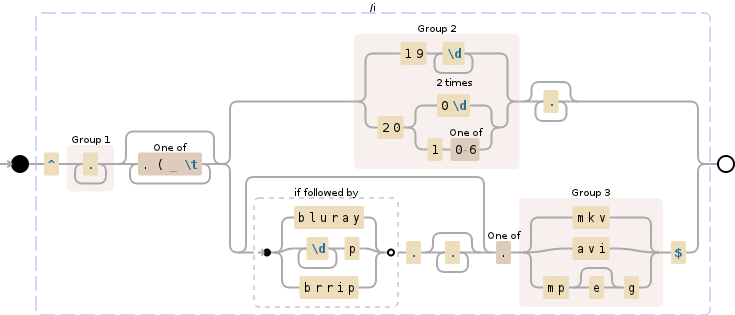
正则表达式突破 Regex101 Demo
/^
(.+?) # Save title into group $1
[.( \t]* # Remove some separators
(?: # Non capturing group
(19\d{2}|20(?:0\d|1[0-6])).* # Save years (1900-2016) in $2
| # OR
(?:(?=bluray|\d+p|brrip)..*)? # Match string starting with bluray,brrip,720p...
[.](mkv|avi|mpe?g)$) # Match extension (.mkv,.avi.,mpeg) add your own
/i # make the regex case insensitive
正则表达式自定义
异常 和扩展 的列表可以在测试期间/如果需要时轻松地一点一点地填充新值(作为文件扩展名,例如添加 .wmv 和 .flv 将它们添加到正则表达式的 (mkv|avi|mpe?g|wmv|flv) 部分)或制作该部分通用将其替换为 [.]\w{3,4}$。
关于javascript - 使用正则表达式从文件名中获取标题和年份,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/34712335/
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题