🌻算法,不如说它是一种思考方式🍀
算法专栏: 👉🏻123
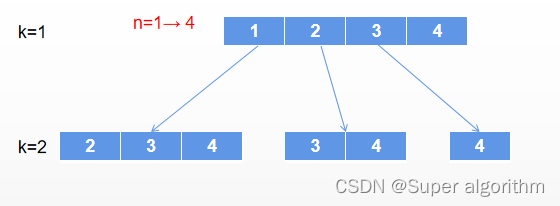
输入:n = 4, k = 2
就是遍历这样的一个树,选取组合。
class Solution {
public List<List<Integer>> combine(int n, int k) {
List<List<Integer>> ans= new ArrayList<>();
List<Integer> nk=new ArrayList<>();
getnk(n,k,ans,nk,1);
return ans;
}
private static void getnk(int n, int k,List<List<Integer>> ans, List<Integer> nk,int index) {
if(nk.size()==k){
ans.add(new ArrayList<>(nk));
return;
}
for (int i = index; i <= n; i++) {
nk.add(i);
getnk(n,k,ans,nk,i+1);
nk.remove((Object) i);
}
}
}
回溯算法是一种基于 DFS 搜索的算法思想,回溯算法可枚举出所有可能的情况,并通过剪枝等优化技巧减少搜索时间,从而求出问题的解。
在回溯算法中,我们通常需要定义以下几个概念:
状态:问题或问题的解可以表示为不同状态的组合。例如,在 8 皇后问题中,状态是一个长度为 8 的数组,在数组中,每个元素存储一个整数,表示皇后的位置。因此,所有可能的状态组成了问题的解空间。
决策:对于一个给定的状态,我们可以通过一种操作,生成不同的下一个状态。例如,在 8 皇后问题中,决策是指从当前状态中选择一个位置,将下一个皇后放在该位置。
可行性条件:在生成新状态之后,需要检查该状态是否满足问题的要求。如果新状态不满足要求,则需要回溯到前一个状态,进行其他的决策。
回溯算法是通过枚举所有可能的情况,逐个考虑每个决策,生成新的可能状态,检验状态是否满足问题要求。如果满足要求,继续生成下一个状态,否则回溯到上一个状态,选择其他的决策进行尝试。由于需要考虑所有可能的情况,因此回溯算法,具有非常高的时间复杂度,因此,需要合理地设置搜索条件、剪枝等技巧,以提高回溯算法的效率。
回溯算法通常需要进行以下几个操作:
初始化状态:根据问题要求,生成最初的状态。
生成新状态:对于当前的状态,尝试不同的决策,生成一个新状态。
检验状态:对于生成的新状态,进行问题要求的检验,是否满足要求。
回溯处理:如果新状态不满足要求,需要回溯到前一个状态,进行其他决策。
回溯算法的优点是,基本上不需要额外的存储空间,即空间复杂度很低。并且适用于求解大部分 NP 问题,可以解决许多其它算法无法处理的问题。通过逐个尝试所有可能的情况,检验状态是否满足要求,从而求出问题的解。虽然回溯算法的效率比较低,但是对于许多 NP 问题,回溯算法仍然是一种有效的解决方案。
☕物有本末,事有终始,知所先后。🍭
🍎☝☝☝☝☝我的CSDN☝☝☝☝☝☝🍓
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
给定一个数组a,什么是实现其组合直到第n的最佳方法?例如:a=%i[abc]n=2#Expected=>[[],[:a],[:b],[:c],[:a,b],[:b,:c],[:c,:a]] 最佳答案 做如下:a=%w[abc]n=30.upto(n).flat_map{|i|a.combination(i).to_a}#=>[[],["a"],["b"],["c"],["a","b"],#["a","c"],["b","c"],["a","b","c"]] 关于ruby-最多n的组合,我
我想合并多个事件记录关系例如,apple_companies=Company.where("namelike?","%apple%")banana_companies=Company.where("namelike?","%banana%")我想结合这两个关系。不是合并,合并是apple_companies.merge(banana_companies)=>Company.where("namelike?andnamelike?","%apple%","%banana%")我要Company.where("名字像?还是名字像?","%apple%","%banana%")之后,我会写代
我有一个熟悉的问题,看起来像是数学世界的排列/组合。如何通过ruby实现以下目标?badges="1-2-3"badge_cascade=[]badges.split("-").eachdo|b|badge_cascade["1","2","3"]ButIwantittobeis:=>["1","2","3","1-2","2-3","3-1","2-1","3-2","1-3","1-2-3","2-3-1","3-1-2"] 最佳答案 函数式方法:bs="1-2-3".split("-")strings=1.upto(bs.
在尝试解决“网格上的路径”问题时,我编写了代码defpaths(n,k)p=(1..n+k).to_ap.combination(n).to_a.sizeend代码工作正常,例如ifn==8andk==2代码返回45,这是正确的路径数。但是,当使用较大的数字时,代码非常慢,我正在努力想出如何加快这个过程。 最佳答案 与其构建组合数组只是为了计算它,不如编写function定义组合的数量。我敢肯定还有包含此功能和许多其他组合函数的gem。请注意,我使用的是gemDistribution对于Math.factorial方法,但这是另一种
对于一个电子商务应用程序,我试图将选项的散列(每个选项都有一系列选择)转换为代表这些选择组合的散列数组。例如:#Input:{:color=>["blue","grey"],:size=>["s","m","l"]}#Output:[{:color=>"blue",:size=>"s"},{:color=>"blue",:size=>"m"},{:color=>"blue",:size=>"m"},{:color=>"grey",:size=>"s"},{:color=>"grey",:size=>"m"},{:color=>"grey",:size=>"m"}]Input内部可能有额
前言我们习惯用idea编写、调试代码,在LeetCode上刷题时,如果能够在IDEA编写代码,并且做好代码管理,是一件事半功倍的事情。对于后续复习题目,做笔记也会非常便利。本文目的在于介绍LeetCodeEditor的使用,以及配置工具类,最终目录结构如下:note:放置笔记src:放置代码leetcode.editor.cn:插件LeetCodeEditor自动生成utils:自定义的工具包,可用于自动化输入测试用例,定义题目需要的类(结构体)out:运行测试时自动生成LeetCodeEditorGitHub:https://github.com/shuzijun/leetcode-edit
我大胆猜测将一个数组拼成另一个数组比将两个数组加在一起更快,但经过快速基准测试后我发现我错了。我假设解释器只会将splat转换为数组文字,而不必每次都对其调用+方法。那么,为什么+比splat更快?我使用了这个基准代码:deftest(trials=1000)head=[1,2,3]tail=100.times.to_at=Time.now.to_ftrials.timesdo|i|a=[head,*tail]endputs"splatdonein#{Time.now.to_f-t}"t=Time.now.to_ftrials.timesdo|i|a=head+tailendputs"
这里是初级程序员,只是想了解Ruby背后的过程sort使用飞船操作符时的方法.希望有人能帮忙。在以下内容中:array=[1,2,3]array.sort{|a,b|ab}...我明白sort一次比较一对数字,然后返回-1如果a属于b之前,0如果它们相等,或者1如果a应该遵循b.但是在降序排序的情况下,像这样:array.sort{|a,b|ba}...到底发生了什么?是否sort还是比较ab然后翻转结果?或者它是在解释return的-1,0和1具有相反的行为?换句话说,为什么要像这样将变量放在block中:array.sort{|b,a|ba}...结果与第一个示例中的排序模式相同?
link有两个组件:componenta_id和componentb_id。为此,在Link模型文件中我有:belongs_to:componenta,class_name:"Component"belongs_to:componentb,class_name:"Component"validates:componenta_id,presence:truevalidates:componentb_id,presence:truevalidates:componenta_id,uniqueness:{scope::componentb_id}validates:componentb_id
