摘要:SPL实现了更优算法,性能远远超过存储过程,能显著提高单机计算效率,非常适合跑批计算。
本文分享自华为云社区《Java开源专业计算引擎:跑批真的这么难吗?》,作者: Java李杨勇。
业务系统产生的明细数据通常要经过加工处理,按照一定逻辑计算成需要的结果,用以支持企业的经营活动。这类数据加工任务一般会有很多个,需要批量完成计算,在银行和保险行业常常被称为跑批,其它像石油、电力等行业也经常会有跑批的需求。
大部分业务统计都会要求以某日作为截止点,而且为了不影响生产系统的运行,跑批任务一般会在夜间进行,这时候才能将生产系统当天产生的新明细数据导出来,送到专门的数据库或数据仓库完成跑批计算。第二天早上,跑批结果就可以提供给业务人员使用了。
和在线查询不同,跑批计算是定时自动执行的离线任务,不会出现多人同时访问一个任务的情况,所以没有并发问题,也不必实时返回结果。但是,跑批必须在规定的窗口时间内完成。比如某银行的跑批窗口时间是晚上8:00到第二天早上7:00,如果到了早上7:00跑批任务还没有完成,就会造成业务人员无法正常工作的严重后果。
跑批任务涉及的数据量非常大,很可能用到所有的历史数据,而且计算逻辑复杂、步骤众多,所以跑批时间经常是以小时计的,一个任务两三小时是家常便饭,跑到十个小时也不足为奇。随着业务的发展,数据量还在不断增加。跑批数据库的负担快速增长,就会发生整晚都跑不完的情况,严重影响用户的业务,这是无法接受的。
要解决跑批时间过长的问题,必须仔细分析现有的系统架构中的问题。
跑批系统比较典型的架构大致如下图:
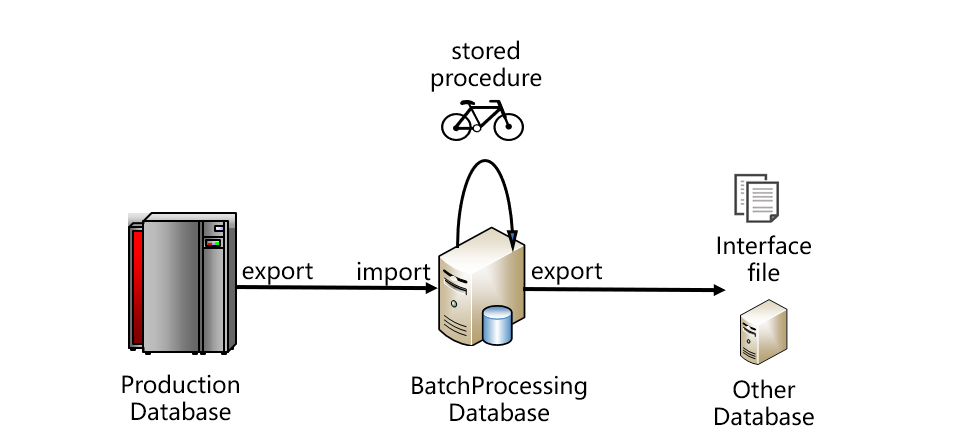
从图上看,数据要从生产数据库取出,存入跑批数据库。跑批数据库通常是关系型的,编写存储过程代码完成跑批计算。跑批的结果一般不会直接使用,而是再从跑批数据库中导出,采用接口文件的方式提供给其他系统,或者再导入其他系统数据库。这是比较典型的架构,图中的生产数据库也可能是某个中央数据仓库或者Hadoop等。一般情况下,生产库和跑批库不会是同一种数据库,它们之间往往通过文件的方式传递数据,这样也比较有利于降低耦合度。跑批计算完成后,结果要给多个应用系统使用,一般也都是以文件方式传递。
跑批很慢的第一个原因,是用来完成跑批任务的关系数据库入库、出库太慢。由于关系数据库的存储和计算能力具有封闭性,数据的进出要做过多的约束检查和安全处理,当数据量较大时,写入读出的效率非常低,耗时会非常长。所以,跑批数据库导入文件数据的过程,以及跑批计算结果再导出文件的过程都会很慢。
跑批很慢的第二个原因,是存储过程性能差。由于SQL的语法体系过于陈旧,存在诸多限制,很多高效的算法无法实施,所以存储过程中的SQL语句计算性能很不理想。而且,业务逻辑比较复杂的时候很难用一个SQL实现,经常要分成多个步骤,用十几甚至几十个SQL语句才能完成。每个SQL的中间结果,都要存入临时表给后续步骤的SQL使用。临时表数据量较大时就必须落地,会造成大量的数据写出。而数据库的写出要比读入性能差很多,会严重拖慢整个存储过程。
对于更复杂的计算,甚至很难用SQL语句直接实现,需要用数据库游标遍历取出数据,循环计算。但数据库游标遍历计算性能又要比SQL语句差很多,一般也都不直接支持多线程并行计算,很难利用多CPU核的计算能力,会让计算性能更加糟糕。
那么,是否可以考虑用分布式数据库来代替传统关系数据库,通过增加节点数量的办法,来提高跑批任务的速度呢?
答案仍然是不可行。主要原因是跑批计算的逻辑相当复杂,即使是用传统数据库的存储过程,也常常要写几千甚至上万行代码,而分布式数据库的存储过程计算能力还比较弱,很难实现这么复杂的跑批计算。
而且,当复杂计算任务不得不分成多个步骤时,分布式数据库也面临中间结果落地的问题。由于数据可能在不同的节点上,所以前序步骤将中间结果落地,后续步骤再读取的时候,都会造成大量跨网络的读写操作,性能很不可控。
这时,也不能采用分布式数据库依靠数据冗余来提升查询速度的办法。这是因为,查询之前可以预先准备好多份冗余数据,但是,跑批的中间结果是临时生成的,如果冗余的话就要临时生成多份,整体的性能只会变得更慢。
所以,现实的跑批业务通常仍然是使用大型单体数据库进行,计算强度太大时会采用类似ExaData这样的一体机(ExaData是多数据库,但被Oracle专门优化过,可以看成是个超大型单体数据库)。虽然很慢,但是暂时找不到更好的选择,只有这类大型数据库有足够的计算能力,所以只能用它来完成跑批任务了。
开源的专业计算引擎SPL提供了不依赖数据库的计算能力,直接利用文件系统计算,可以解决关系数据库出库入库太慢的问题。而且SPL实现了更优算法,性能远远超过存储过程,能显著提高单机计算效率,非常适合跑批计算。
利用SPL实现的跑批系统新架构是下面这样的:
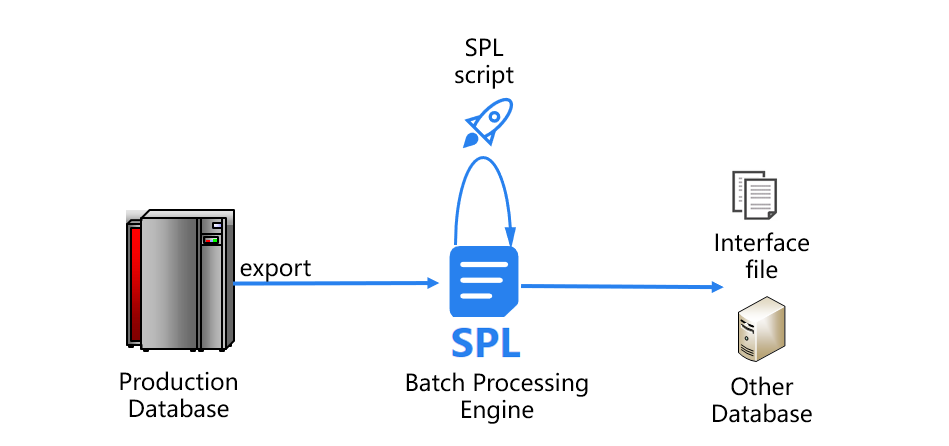
在新架构中,SPL解决了造成跑批慢的两大瓶颈问题。
首先来看数据的入库、出库问题。SPL可以直接基于生产库导出的文件计算,不必再将数据导入到关系数据库中。完成跑批计算后,SPL还能将最终结果直接存储成文本文件等通用格式,传递给其他应用系统,避免了原有跑批数据库的出库操作。这样一来,SPL就省去了关系数据库缓慢的入库、出库过程。
下面再来看计算的过程。SPL提供了更优的算法(有许多是业界首创),计算性能远远超过存储过程和SQL语句。这些高性能算法包括:

这些高性能算法可以应用于跑批任务中的常见JOIN计算、遍历、分组汇总等,能有效提升计算速度。例如,跑批任务常常要遍历整个历史表。有些情况下,对一个历史表还要遍历好多次,来完成多种业务逻辑的计算。历史表数据量一般都很大,每次遍历都要消耗很多的时间。此时我们可以应用SPL的遍历复用机制,仅对大表遍历一次,就可以同时完成多种计算,可以节省大量时间。
SPL的多路游标能做到数据的并行读取和计算,即使是很复杂的跑批逻辑,也可以利用多CPU核实现多线程并行运算。而数据库游标是很难并行的,这样一来,SPL的计算速度常常可以达到存储过程的数倍。
SPL的延迟游标机制,可以在一个游标上定义多个计算步骤,之后让数据流按顺序依次完成这些步骤,实现链式计算,能够有效减少中间结果落地的次数。在数据必须落地的情况下,SPL也可以将中间结果存成内置的高性能数据格式,供下一个步骤使用。SPL高性能存储基于文件,采用有序压缩存储、自由列式存储、倍增分段、自有压缩编码等技术,减少了硬盘占用,读写速度要远远好于数据库。
SPL在技术架构上打破了关系型跑批数据库存在的两大瓶颈,在实际应用中也取得了非常好的效果。
L 银行跑批任务采用传统架构,以关系数据库作为跑批数据库,用存储过程编程实现跑批逻辑。其中,贷款协议存储过程需要执行 2 个小时,而且是很多其他跑批任务的前序任务,耗时这么久,对整个跑批任务造成了严重影响。
采用SPL后,使用高性能列存、文件游标、多线程并行、小结果内存分组、游标复用等高性能算法和存储机制,将原来2个小时的计算时间缩短为10分钟,性能提高12倍。
而且,SPL代码更简洁。原存储过程3300多行,改为SPL后,仅有500格语句,代码量减少了6倍多,大大提高了开发效率。
P保险公司的车险业务中,需要用往年历史保单来关联新的保单,在跑批中称为历史保单关联任务。原来也采用关系数据库完成跑批,存储过程计算10天的新增保单关联历史保单,运行时间47分钟;30天则需要112分钟,接近2小时;如果日期跨度更大,运行时间就会长的无法忍受,基本就变成不可能完成的任务了。
采用SPL后,应用了高性能文件存储、文件游标、有序归并分段取出、内存关联和遍历复用等技术,计算10天新增保单仅需13分钟;30天新增保单只需要17分钟,速度提高了近7倍。而且,新算法执行的时间随着保单天数的增长并不是很大,并没有像存储过程那样成正比的增长。
从代码总量来看,原来存储过程有2000行代码,去掉注释后还有1800多行,而SPL的全部代码只有不到500格,不到原来的1/3。
T银行通过互联网渠道发放贷款的明细数据,需要每天执行跑批任务,统计汇总指定日期之前的所有历史数据。跑批任务采用关系数据库的SQL语句实现,运行总时间7.8小时,占用了过多的跑批时间,甚至影响了其他的跑批任务,必须优化。
采用SPL后,应用了高性能文件、文件游标、有序分组、有序关联、延迟游标、二分法等技术,原来需要7.8小时的跑批任务,单线程仅需180秒,2线程仅需137秒,速度提高了204倍。
我注意到array.min看起来很慢,所以我针对我自己的简单实现做了这个测试:require'benchmark'array=(1..100000).to_a.shuffleBenchmark.bmbm(5)do|x|x.report("lib:"){99.times{min=array.min}}x.report("own:"){99.times{min=array[0];array.each{|n|min=nifn结果:Rehearsal-----------------------------------------lib:1.5310000.0000001.531000(1.5
据我所知,Ruby中基本上有三种不同的闭包;方法、过程和lambdas。我知道它们之间存在差异,但是我们不能只是拥有一种可以容纳所有可能用例的类型吗?通过调用self.method(method_name)已经可以像procs和lambdas一样传递方法。,我所知道的procs和lambdas之间的唯一显着区别是当您尝试使用return时,lambdas检查arity和procs会做一些疯狂的事情。.那么我们不能将它们全部合并为一个并完成它吗? 最佳答案 AsfarasIcantell,thereareessentiallythre
我正在开发我的第一个名为t_time_tracker的gem(哇哦!)。一切进展顺利;我尽可能地对其进行了优化,以尽可能减少执行时间:t_time_tracker[master*]%timeruby-Ilib./bin/t_time_trackerYou'renotworkingonanything0.07suser0.03ssystem67%cpu0.141total(这是我的应用程序的“helloworld”——不带参数调用它只会打印出“你没有做任何事情”)大约十分之一秒,使用了我67%的CPU-太棒了,我可以接受。感觉相当瞬间。让我们构建它:$gembuildt_time_tra
目录一种简单上手的暴力论文分析方法——以区块链为例【含项目源码】太长不看版本:最终成果:情况说明论文推荐方面论文投稿方面以下是具体的实现,有其他研究方向想自行确定的请仔细阅读,授人以鱼不如授人以渔第一章、确定对象——研究热点的中国计算机研究生第二章、思路——基于爬虫结合关键字过滤暴力获取所需论文信息第一步:从CCF推荐目录中获取网址01、背景介绍02、数据预处理03、数据写入表格第二步:从中科院分区中获取期刊对应分区第三步:从期刊/会议对应网址中爬取到子网页并进入,获取到其中的标题、年份等信息第四步:针对获取到的表格数据进行分析和整理实际爬取数据量【其实就论文的标题+对应年份】
每当我为我的Rails应用程序运行rspec测试时,在它真正开始运行测试之前需要很长时间和一天的开销。为什么rspec这么慢?有没有一种方法可以加快Rails的初始加载速度,或者挑出我需要的Rails应用程序部分(例如,仅ActiveRecord内容),这样它就不会完全加载所有内容来运行一些测试? 最佳答案 我绝对建议检查一下spork。http://spork.rubyforge.org/railstutorial专门解决了这个问题,并提供了一种解决方法,让spork在rails3.0中正常运行(截至目前,rails3还没有开箱即
学妹问我的终端为什么这么好看———windows命令行美化指南(从cmd到oh-my-posh)前言一个美观的开发界面,对于调试程序、管理代码版本、提升编程体验等有着至关重要的作用。本文介绍了windows平台下命令行界面的美化方法,以期让读者拥有更好的编程体验。在图形化用户界面(GUI)大规模普及之前,命令行界面(CLI)一直是电脑界的主流。CLI开销小、运行快速,但是非专业用户使用不方便。如今,不从事开发的电脑用户接触到命令行的机会已经很少了(非计算机系学习C,可能只会在“命令行参数”一节接触到命令行),但如果从事软件开发,使用git、gcc等工具,熟练掌握命令行的使用还是有必要的。了解更
我正在使用D3.js来操作一些SVG元素。我了解到(艰难的方式)较新版本的FireFox并不能很好地处理D3的强制布局。所以我切换到一个简单的旋转,它仍然在Firefox中运行糟糕。在以下代码中,group1是一个包含200个的数组我动态创建的svg元素:functionorbit(target,first){/*Othereasingoptionshere:https://github.com/mbostock/d3/wiki/Transitions#wiki-d3_ease*/varease=(first)?'sin-in':'linear';target.transition()
当我读到GuidovanRossum的文章AnOptimizationAnecdote时,它开始了。.决定在JavaScript中尝试同样的事情,我计时如下:numbers.map(function(x){returnString.fromCharCode(x);});这已经相当快了,但为什么不完全消除匿名函数并将String.fromCharCode直接传递给map():numbers.map(String.fromCharCode);我对它计时并且......这比以前的版本慢了~100倍。怎么会?不知何故,将此native函数直接传递给Array.map()比将其包装在另一个函数中
文章目录前言使用过ChatGPT的人都知道,提示占据非常重要的位置。而Word,Excel、PPT这办公三大件中,当属Excel最难搞,想要熟练掌握它,需要记住很多公式。但是使用提示就简单多了,和ChatGPT聊聊天就能解决问题。一、使用ChatGPT完成Excel公式二、使用步骤1.引入库2.读入数据3.提取数据4.计算唯一值5.使用ChatGPT创建宏变量总结前言ChatGPT自去年11月30日OpenAI重磅推出以来,这款AI聊天机器人迅速成为AI界的「当红炸子鸡」。一经发布,不少网友更是痴迷到通宵熬夜和它对话聊天,就为了探究ChatGPT的应用天花板在哪里,经过试探不少人发现,Chat
我正在阅读this文章和Chrome似乎遥遥领先。但是为什么这么好呢?它只推出了大约一年,但比其他任何一个都要好得多。谁能从技术上阐明这一点? 最佳答案 “我们经常被问到是什么让GoogleChrome浏览器如此之快——从其快速的启动时间和快速的页面加载,到快速运行复杂的网络应用程序的能力。来回顾一些思考过程和关于使GoogleChrome成为快速浏览器所涉及的技术决策,我们汇总了三个关于DNS预解析、V8JavaScript引擎和DOM绑定(bind)的技术访谈。在以后的文章中,我们还将涵盖其他重要领域,例如WebKit和用户界面