文章目录
ELK日志分析系统(一)之ELK原理
ELK日志分析系统(二)之ELK搭建部署
ELFK日志分析系统(三)之Filebeat
ELFK日志分析系统(四)之Kafka
ELFK日志分析系统(五)之Zookeeper
随着业务量的增长,每天业务服务器将会产生上亿条的日志,单个日志文件达几个GB,这时我们发现用Linux自带工具,cat grep awk 分析越来越力不从心了,而且除了服务器日志,还有程序报错日志,分布在不同的服务器,查阅繁琐。
待解决的痛点:
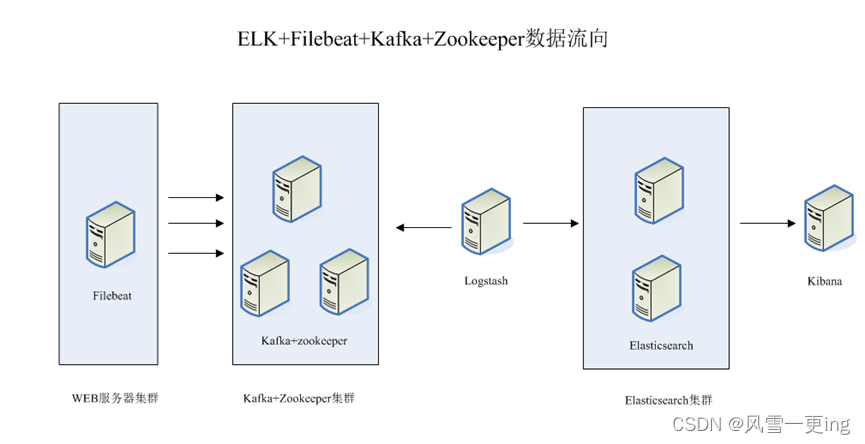
整体的架构如上图所示
这个架构图从左到右,总共分为5层,每层实现的功能和含义分别介绍如下:
第一层、数据采集层
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat做日志收集,然后把采集到的原始日志发送到Kafka+zookeeper集群上。
第二层、消息队列层
原始日志发送到Kafka+zookeeper集群上后,会进行集中存储,此时,filbeat是消息的生产者,存储的消息可以随时被消费。
第三层、数据分析层
Logstash作为消费者,会去Kafka+zookeeper集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch集群。
第四层、数据持久化存储
Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到Elasticsearch集群上。
第五层、数据查询、展示层
Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。
| IP | 角色 | 所属集群 |
|---|---|---|
| 192.168.109.11 | Elasticsearch | Elasticsearch集群 |
| 192.168.109.12 | Elasticsearch | Elasticsearch集群 |
| 192.168.109.13 | Logstash | 数据转发 |
| 192.168.109.14 | Kafka+zookeeper | Kafka+zookeeper群集 |
| 192.168.109.15 | Kafka+zookeeper | Kafka+zookeeper群集 |
| 192.168.109.16 | Kafka+zookeeper | Kafka+zookeeper群集 |
| 192.168.109.17 | filebeat | 配置数据采集层 |
本实验基于ELK已经搭好的情况下
Zookpeer下载地址:apache-zookeeper-3.7.1-bin.tar.gz
tar zxf apache-zookeeper-3.7.1-bin.tar.gz
mv apache-zookeeper-3.7.1-bin /usr/local/zookeeper-3.7.1
cd /usr/local/zookeeper-3.7.1/conf/
cp zoo_sample.cfg zoo.cfg
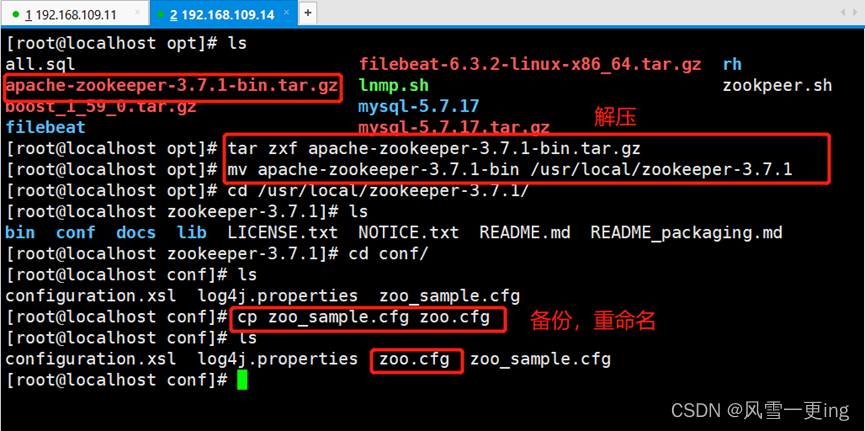
vim zoo.cfg
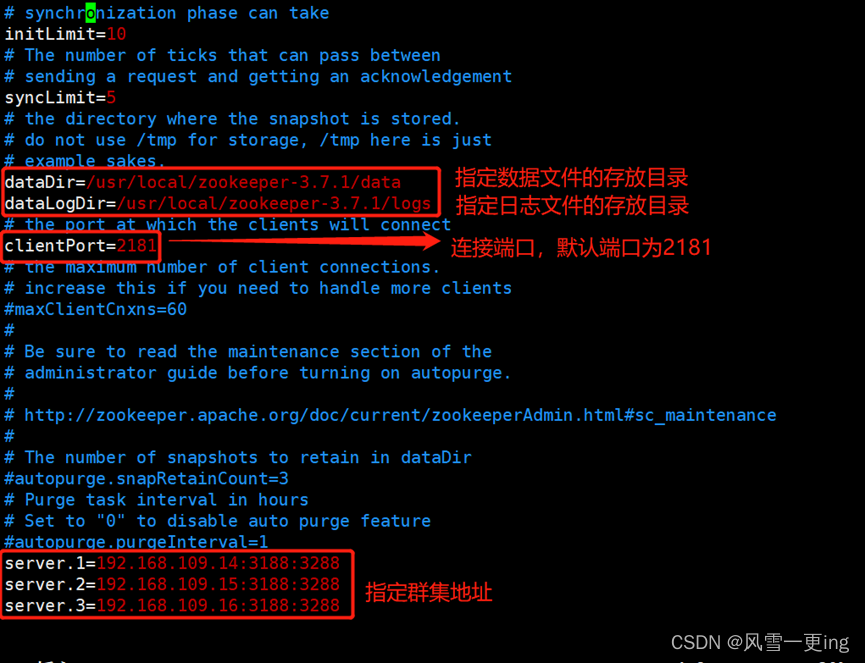
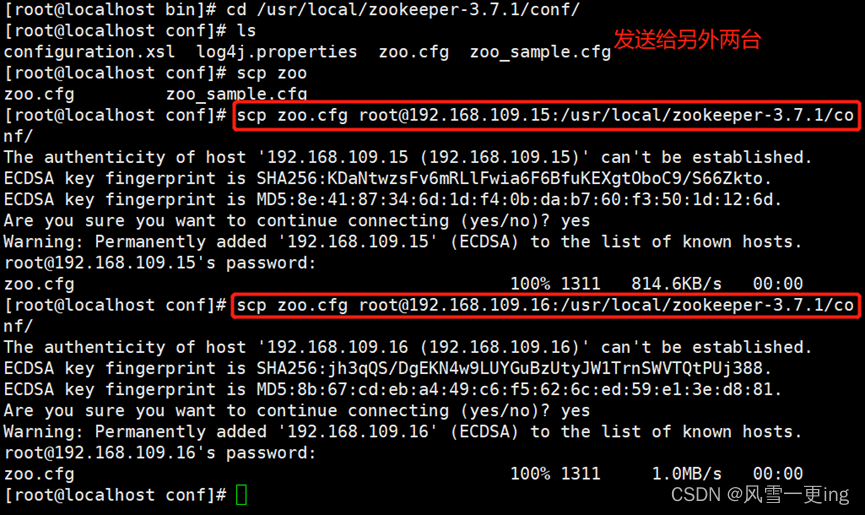
mkdir data logs
echo 1 > data/myid
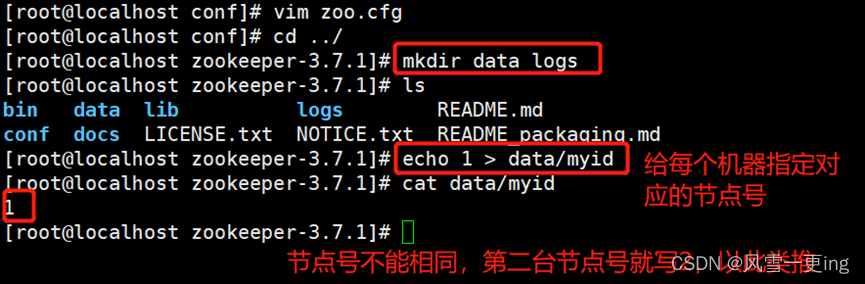

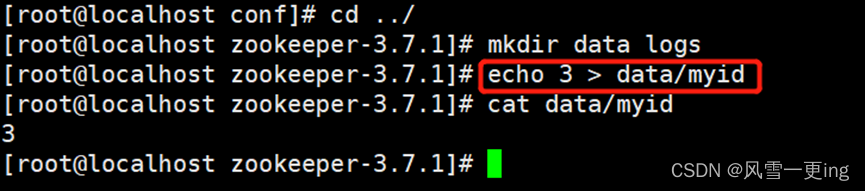
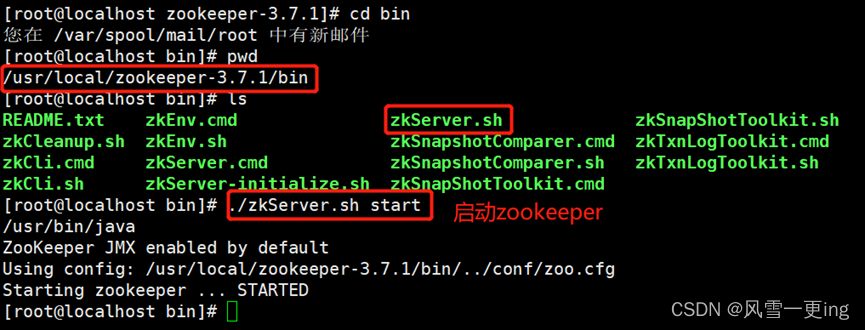
cd /usr/local/zookeeper-3.7.1/bin
./zkServer.sh start

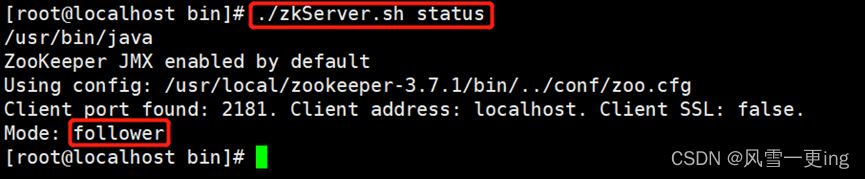

tar zxf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
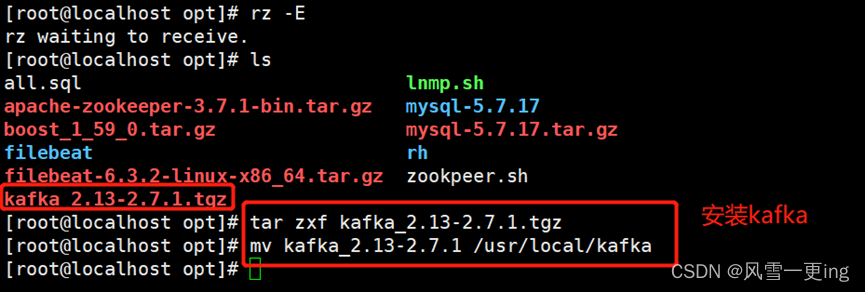
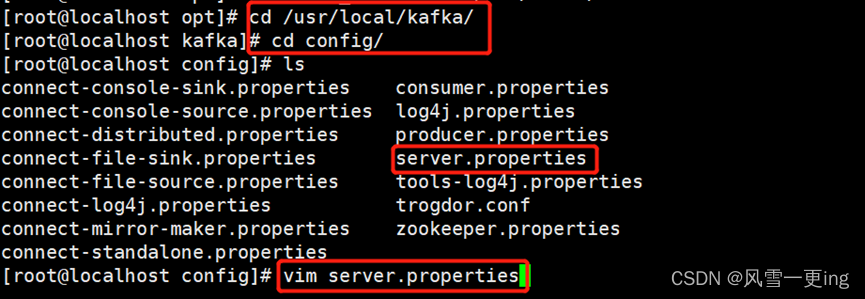
cd /usr/local/kafka/config/
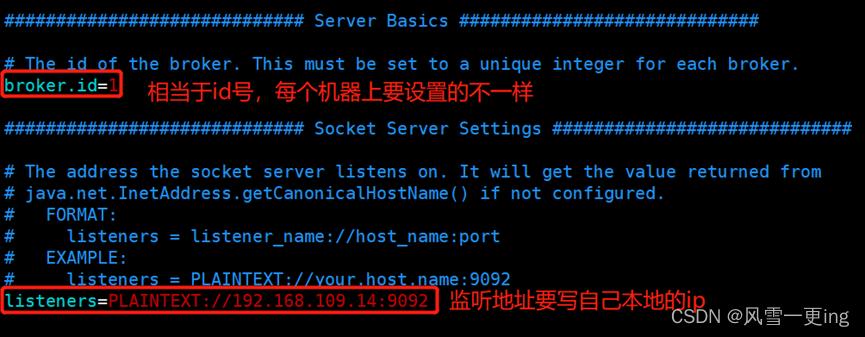
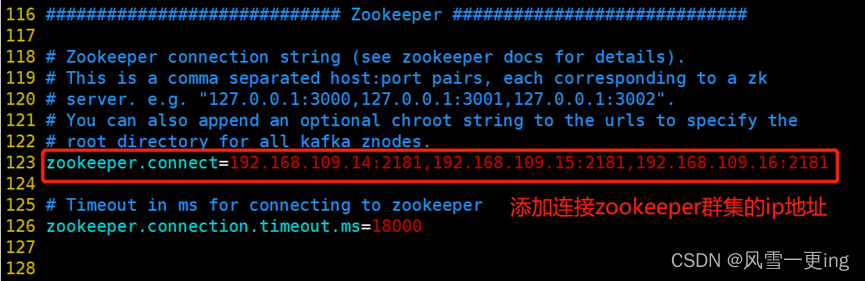
vim server.properties
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile


cd /usr/local/kafka/config/
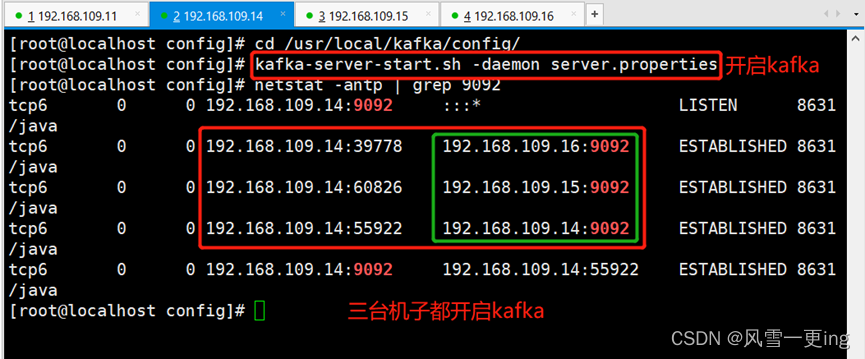
kafka-server-start.sh -daemon server.properties
netstat -antp | grep 9092
创建topic
kafka-topics.sh --create --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181 --replication-factor 2 --partitions 3 --topic test
–zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
–replication-factor:定义分区副本数,1 代表单副本,建议为 2
–partitions:定义分区数
–topic:定义 topic 名称
查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181
查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181
发布消息
kafka-console-producer.sh --broker-list 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test --from-beginning
–from-beginning:会把主题中以往所有的数据都读取出来
修改分区数
kafka-topics.sh
--zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --alter --topic test --partitions 6
删除 topic
kafka-topics.sh
--delete --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --topic test
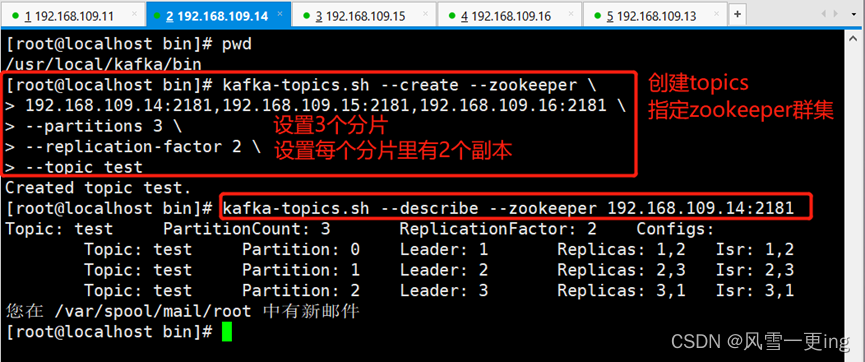
[root@localhost bin]# pwd
/usr/local/kafka/bin
[root@localhost bin]# kafka-topics.sh --create --zookeeper \
> 192.168.109.14:2181,192.168.109.15:2181,192.168.109.16:2181 \
> --partitions 3 \
> --replication-factor 2 \
> --topic test
Created topic test.
[root@localhost bin]# kafka-topics.sh
--describe --zookeeper 192.168.109.14:2181
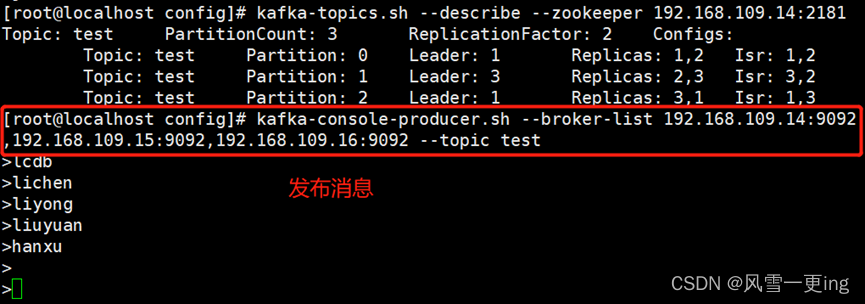
发布消息
kafka-console-producer.sh
--broker-list 192.168.109.14:9092,192.168.109.15:9092,192.168.109.16:9092 --topic test
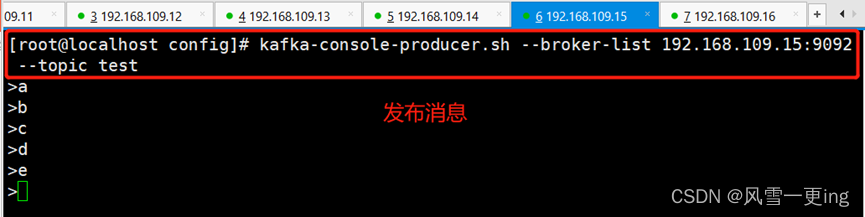
kafka-console-producer.sh --broker-list 192.168.109.15:9092 --topic test
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.109.15.9092 –topic test --from-beginning
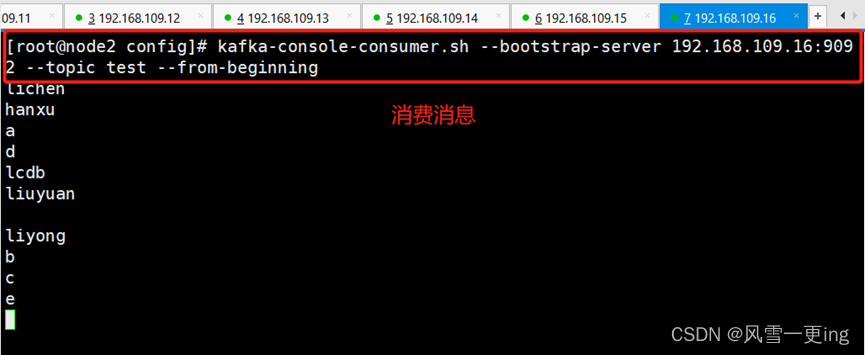
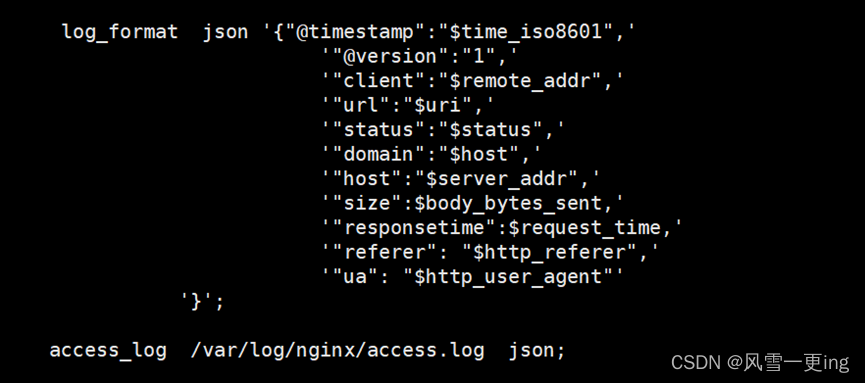
vim /etc/nginx/nginx.conf
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
access_log /var/log/nginx/access.log json;
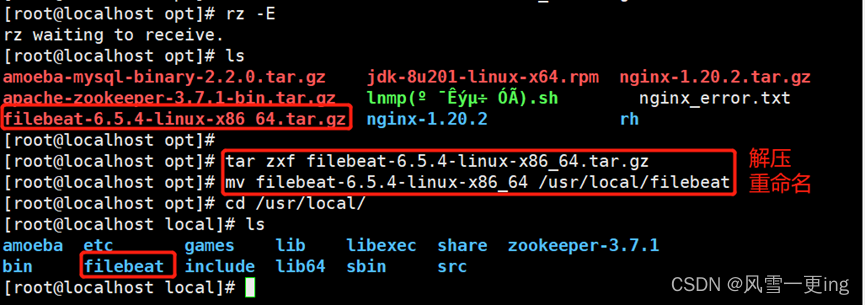
cd /opt
tar zxf filebeat-6.5.4-linux-x86_64.tar.gz
mv filebeat-6.5.4-linux-x86_64 /usr/local/filebeat
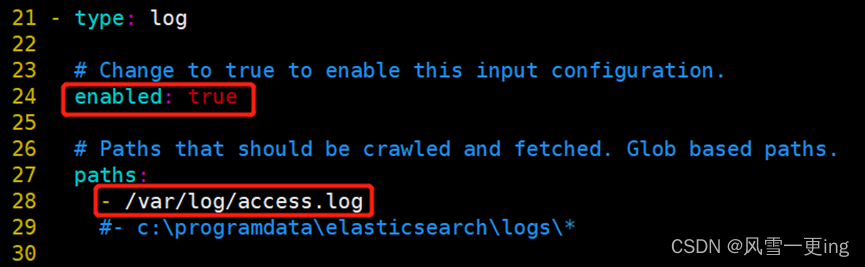
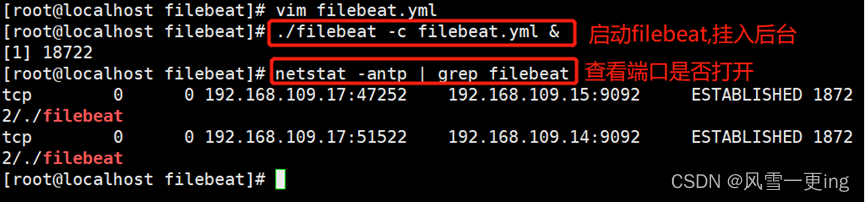
vim filebeat.yml

./filebeat -c filebeat.yml &
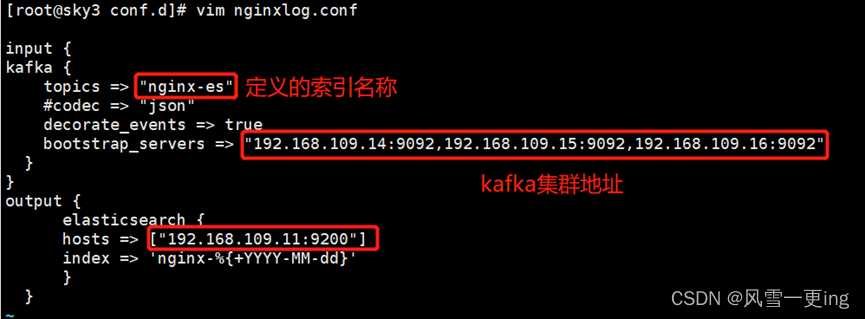
kafka-topics.sh --create --zookeeper
192.168.109.14:2181,192.168.109.15:2181,192.168.109.16:2181
--replication-factor 1 --partitions 1 –topic nginx-es



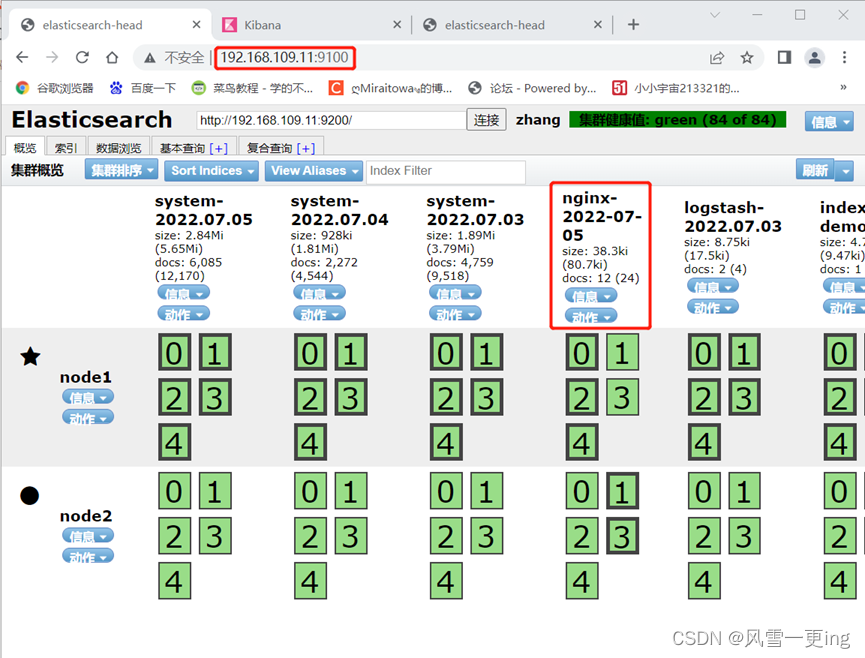
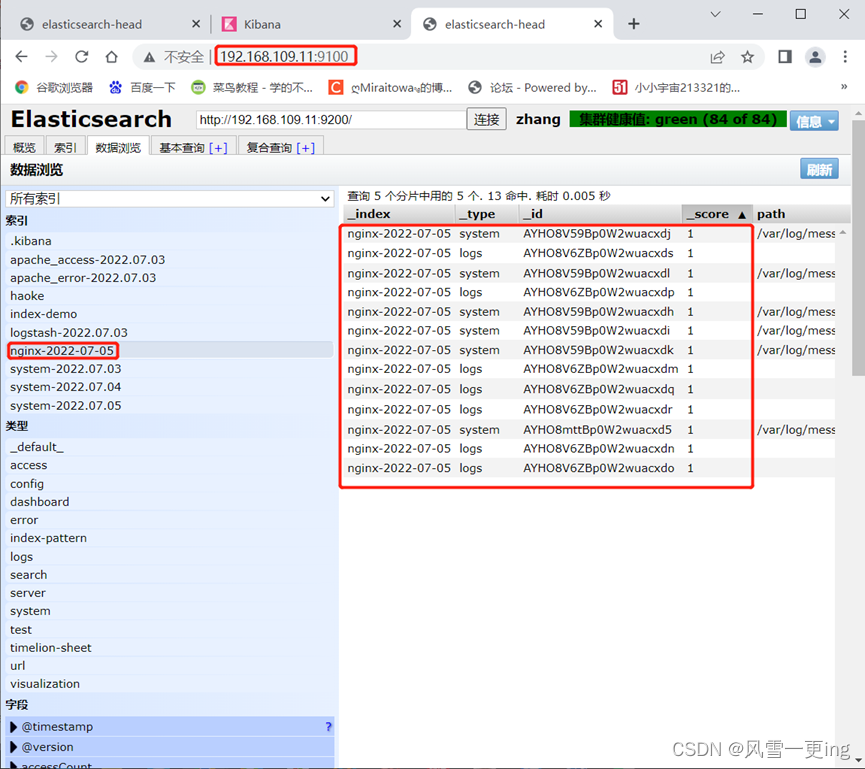
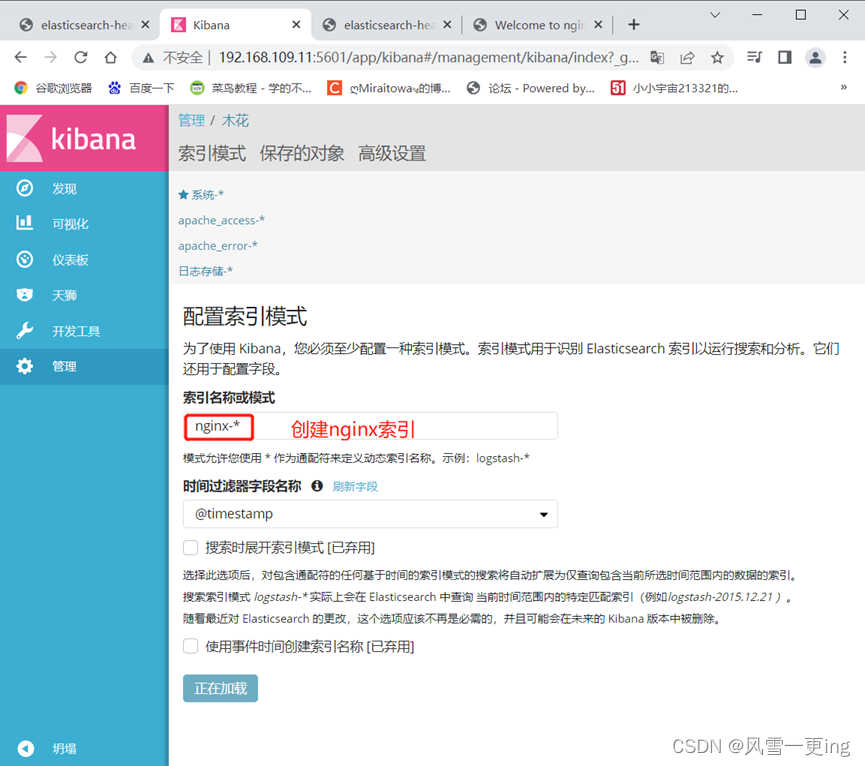
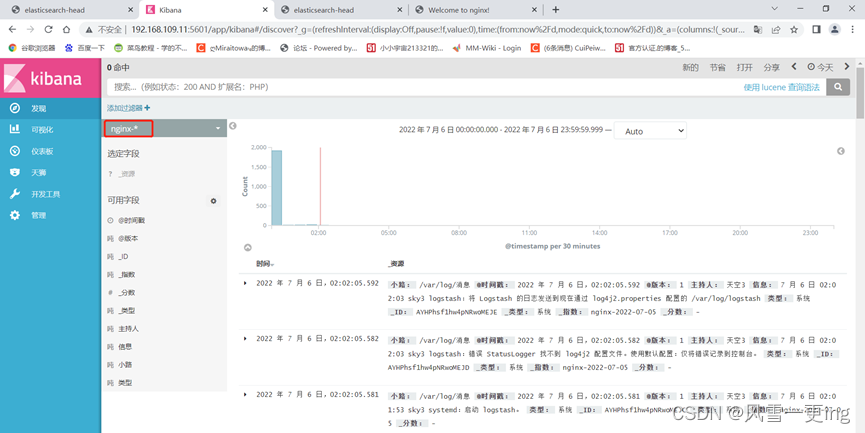
至此,ELFK日志分析系统搭建完成!!!!!
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭8年前。Improvethisquestion我们有以下(以及更多)系统,我们将数据从一个应用推送/拉取到另一个:托管CRM(InsideSales.com)Asterisk电话系统(内部)横幅广告系统(openx,我们托管)潜在客户生成系统(自行开发)电子商务商店(spree,我们托管)工作板(本土)一些工作网站抓取+入站工作提要电子邮件传送系统(如Mailchimp,自主开发)事件管理系统(如eventbrite,自主开发)仪表板系统(大量图表和