ELK是三个开源软件的缩写,分别表示:Elasticsearch,Logstash,Kibana。新增了一个FlieBeat,它是一个轻量级的日志收集处理工具,FlieBeat占用资源少,适用于在各个服务器上搜集日之后,传输给Logstash。
Elasticsearch:开源分布式搜索引擎,提供搜集,分析,缓存数据三大功能,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负 载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构, client 端安装在需要收集日志的主机上, server 端负责将收到的各节点日志进行过
滤、修改等操作在一并发往 elasticsearch 上去。
Kibana 也是一个开源和免费的工具, Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友
好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
日志流量的增长导致了平台部署规模巨大,用户需求也发生了显著变化。两者都给基于 ELK 的平台带来了许多挑战,而这些挑战在较小的规模下是看不到的:
由于 logstash 内存占用较大,灵活性相对没那么好, ELK 正在被 EFK 逐步替代 . 其中本文所讲的 EFK 是 Elasticsearch+Fluentd+Kfka。
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch 、 Fluentd 和 Kibana ( EFK) 技术栈,也是官方现在比较推荐的一种方案。
Fluentd 是一个收集日志文件的开源软件,目前提供数百个插件可用于存储大数据用于日志搜索,数据分析和存储。
Fluentd适用于以下场景。
收集多台服务器的访问日志进行可视化
在AWS 等云端使用 AutoScaling 时把日志文件收集至 S3( 需要安装插件 )
收集客户端的信息并输出至Message Queue ,供其他应用处理
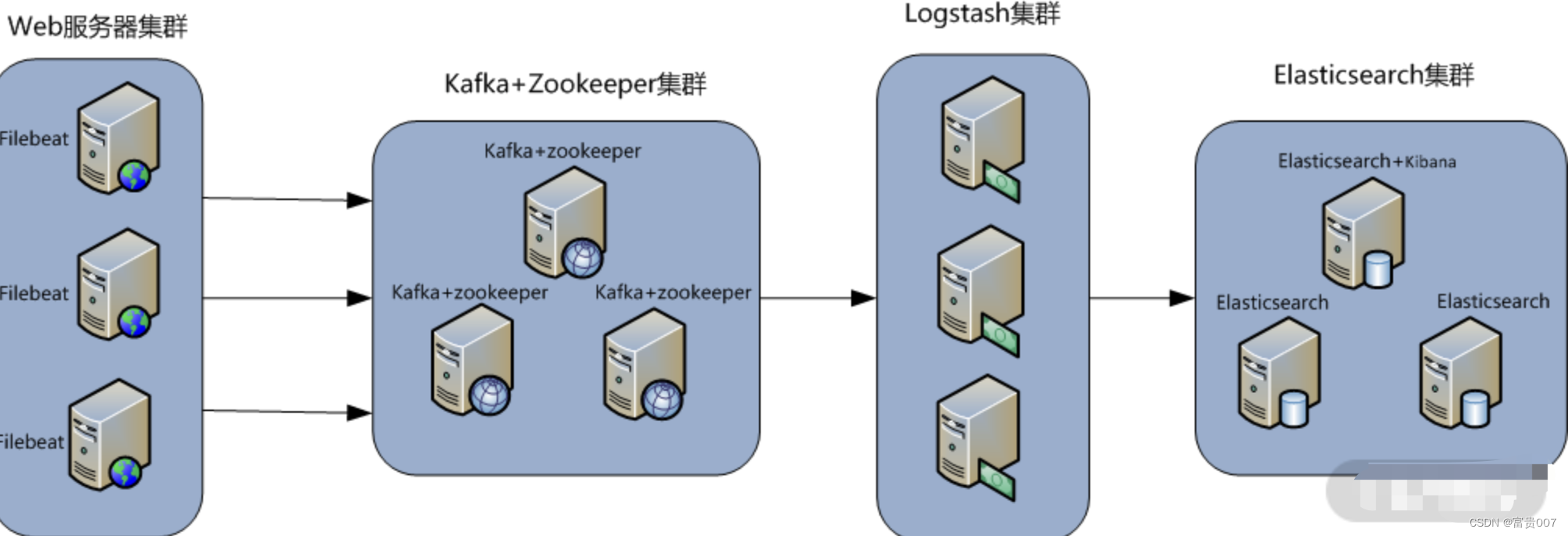
第一层,数据采集层:数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了 Filebeat 做日志收集,然后把采集到的原始日志发送到 Kafka+ZooKeeper 集群上。
第二层,消息队列层:原始日志发送到 Kafka+ZooKeeper 集群上后,会进行集中存储,此时,Filbeat 是消息的生产者,存储的消息可以随时被消费。
第三层,数据分析层:Logstash 作为消费者,会去 Kafka+ZooKeeper 集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至 Elasticsearch 集群中。
第四层,数据持久化存储:Elasticsearch 集群在接收到 Logstash 发送过来的数据后,执行写磁盘、建索引库等操作,最后将结构化的数据存储到 Elasticsearch 集群上。
第五层,数据查询、展示层:Kibana 是一个可视化的数据展示平台,当有数据检索请求时,它从 Elasticsearch 集群上读取数据,然后进行可视化出图和多维度分析。

ClickHouse 是一款常用于大数据分析的 DBMS,因为其压缩存储,高性能,丰富的函数等特性,近期有很多尝试 ClickHouse 做日志系统的案例。本文将分享如何用 ClickHouse 做出通用日志系统。
可以解决的问题:
大数据量。对开发者来说日志最方便的观测手段,而且很多情况下会直接打印 HTTP、RPC 的请求响应日志,这基本上就是把网络流量复制了一份。
非固定检索模式。用户有可能使用日志中的任意关键字任意字段来查询。
成本要低。日志系统不宜在 IT 成本中占比过高。
即席查询。日志对时效性要求普遍较高。
数据量大,检索模式不固定,既要快,还得便宜。所以日志是一道难解的题,它的需求几乎违反了计算机的基本原则,不过幸好它还留了一扇窗,就是对并发要求不高。大部分查询是人为即兴的,即使做一些定时查询,所检索的范围也一定有限。
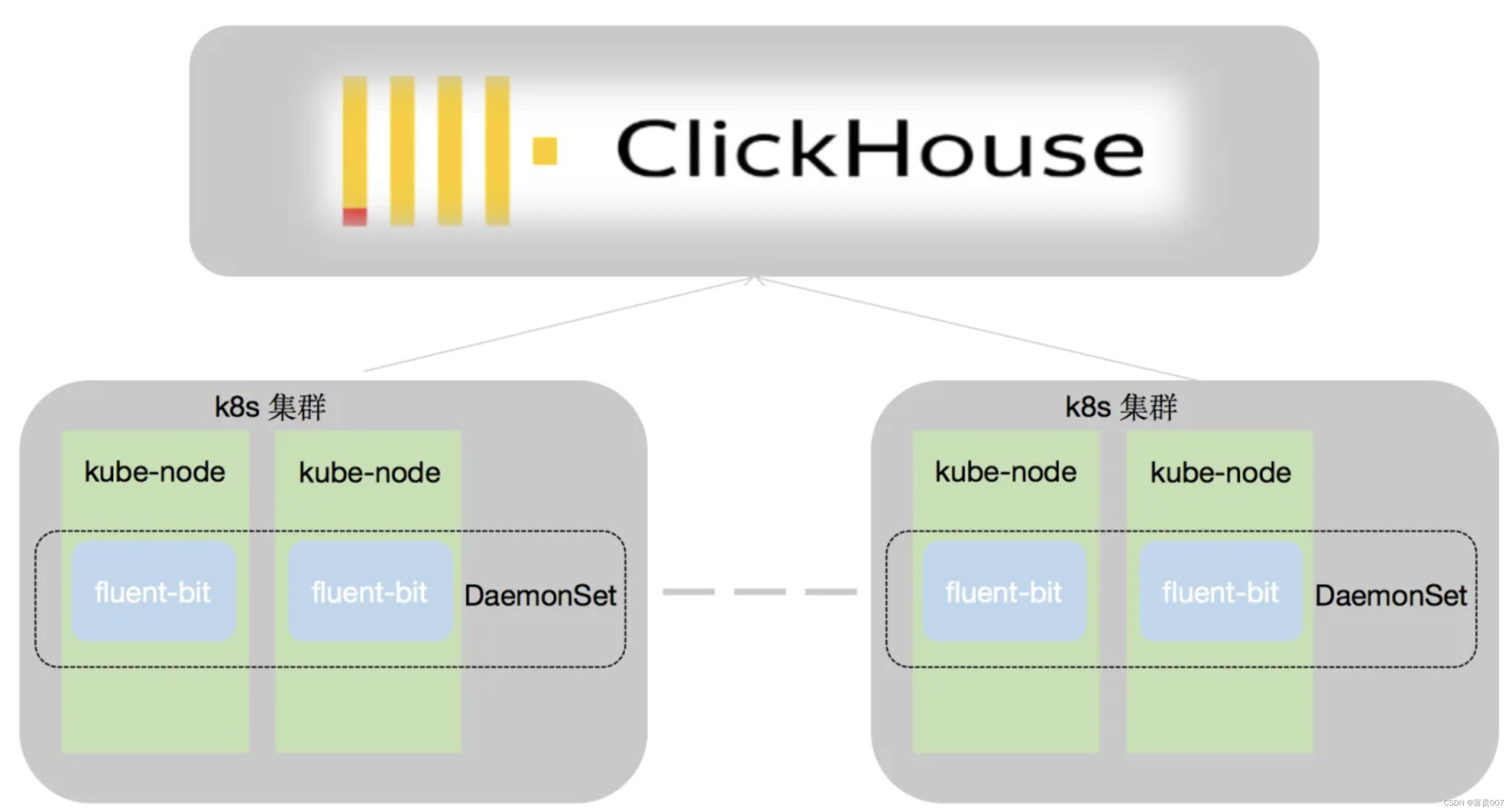
Fluent bit:目前社区日志采集和处理的组件不少,之前elk方案中的logstash,cncf社区中的fluentd,efk方案中的filebeat,以及大数据用到比较多的flume。而Fluent Bit是一款用c语言编写的高性能的日志收集组件,整个架构源于fluentd。官方比较数据如下:
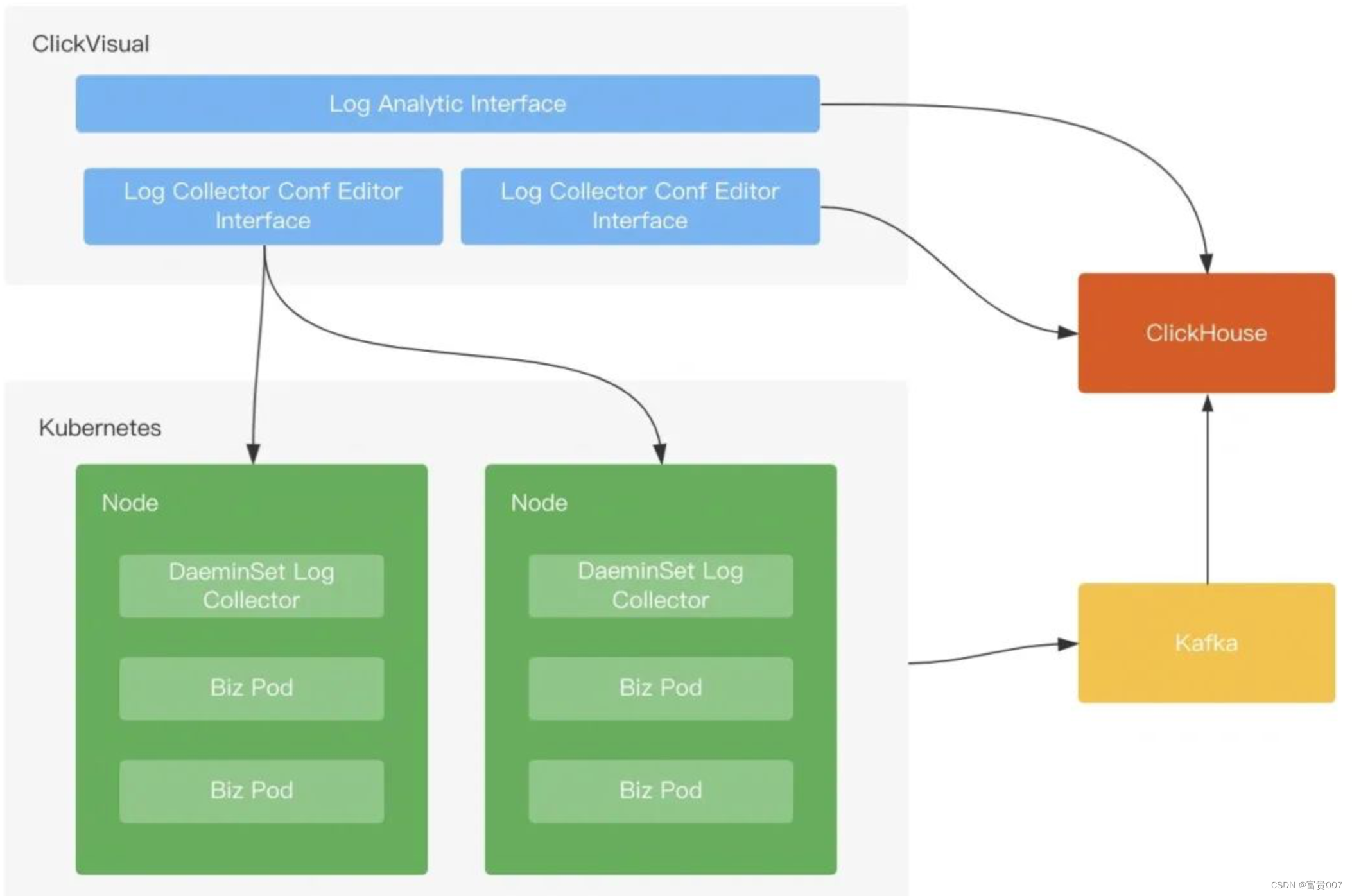
日志系统主要分为四个部分:日志采集、日志传输、日志存储、日志管理。
● 日志采集:LogCollector 采用 Daemonset 方式部署,将宿主机日志目录挂载到 LogCollector 的容器内,LogCollector 通过挂载的目录能够采集到应用日志、系统日志、K8S 审计日志等
● 日志传输:通过不同 Logstore 映射到 Kafka 中不同的 Topic,将不同数据结构的日志做了分离
● 日志存储:使用 Clickhouse 中的两种引擎数据表和物化视图
● 日志管理:开源的 ClickVisual 系统,能够查询日志,设置日志索引,设置 LogCollector 配置,设置 Clickhouse 表,设置报警等
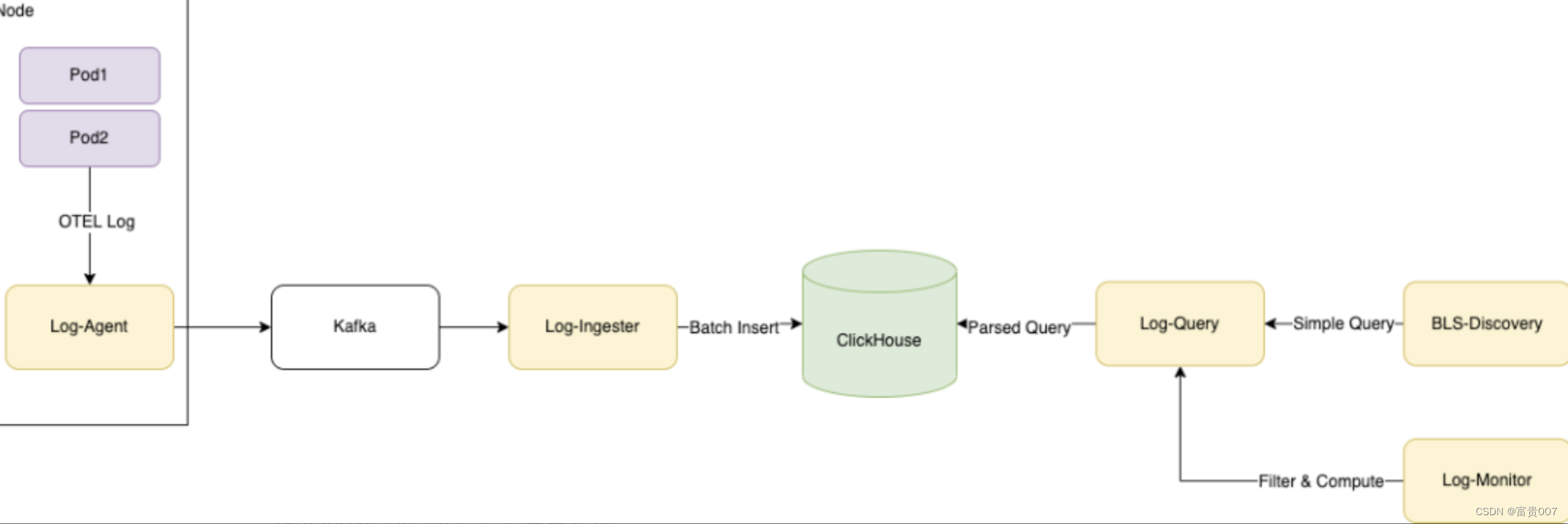
如图所示为日志实时上报和使用的全链路。使用ClickHouse作为存储,实现了自研的日志可视化分析平台,并使用OpenTelemetry作为统一日志上报协议。日志从产生到消费会经过采集→摄入 →存储 →分析四个步骤,分别对应我们在链路上的各个组件,先做个简单的介绍:
● OTEL Logging SDK完整实现OTEL Logging日志模型规范和协议的结构化日志高性能SDK,提供了Golang和Java两个主要语言实现。
● Log-Agent
日志采集器,以Agent部署方式部署在物理机上,通过Domain Socket接收OTEL协议日志,同时进行低延迟文件日志采集,包括容器环境下的采集。支持多种Format和一定的加工能力,如解析和切分等。
● Log-Ingester
负责从日志 kafka 订阅日志数据, 然后将日志数据按时间维度和元数据维度(如AppID) 拆分,并进行多队列聚合, 分别攒批写入ClickHouse中.
● ClickHouse
我们使用的日志存储方案,在ClickHouse高压缩率列式存储的基础上,配合隐式列实现了动态Schema以获得更强大的查询性能,在结构化日志场景如猛虎添翼。
● Log-Query
日志查询模块,负责对日志查询进行路由、负载均衡、缓存和限流,以及提供查询语法简化。
● BLS-Discovery
新一代日志的可视化分析平台,提供一站式的日志检索、查询和分析,追求日志场景的高易用性,让每个研发0学习成本无障碍使用。
在湖仓一体日益成熟的背景下,日志入湖会带来以下收益:
● 部分日志有着三年以上的存储时间要求,比如合规要求的审计日志,关键业务日志等,数据湖的低成本存储特性是这个场景的不二之选。
● 现在日志除了用来进行研发排障外,也有大量的业务价值蕴含其中。日志入湖后可以结合湖上的生态体系,快速结合如机器学习、BI分析、报表等功能,将日志的价值发挥到最大。
此外,我们长远期探索减少日志上报的中间环节,如从agent直接到ClickHouse,去掉中间的Kafka,以及更深度的结合ClickHouse和湖仓一体,打通ClickHouse和iceberg。
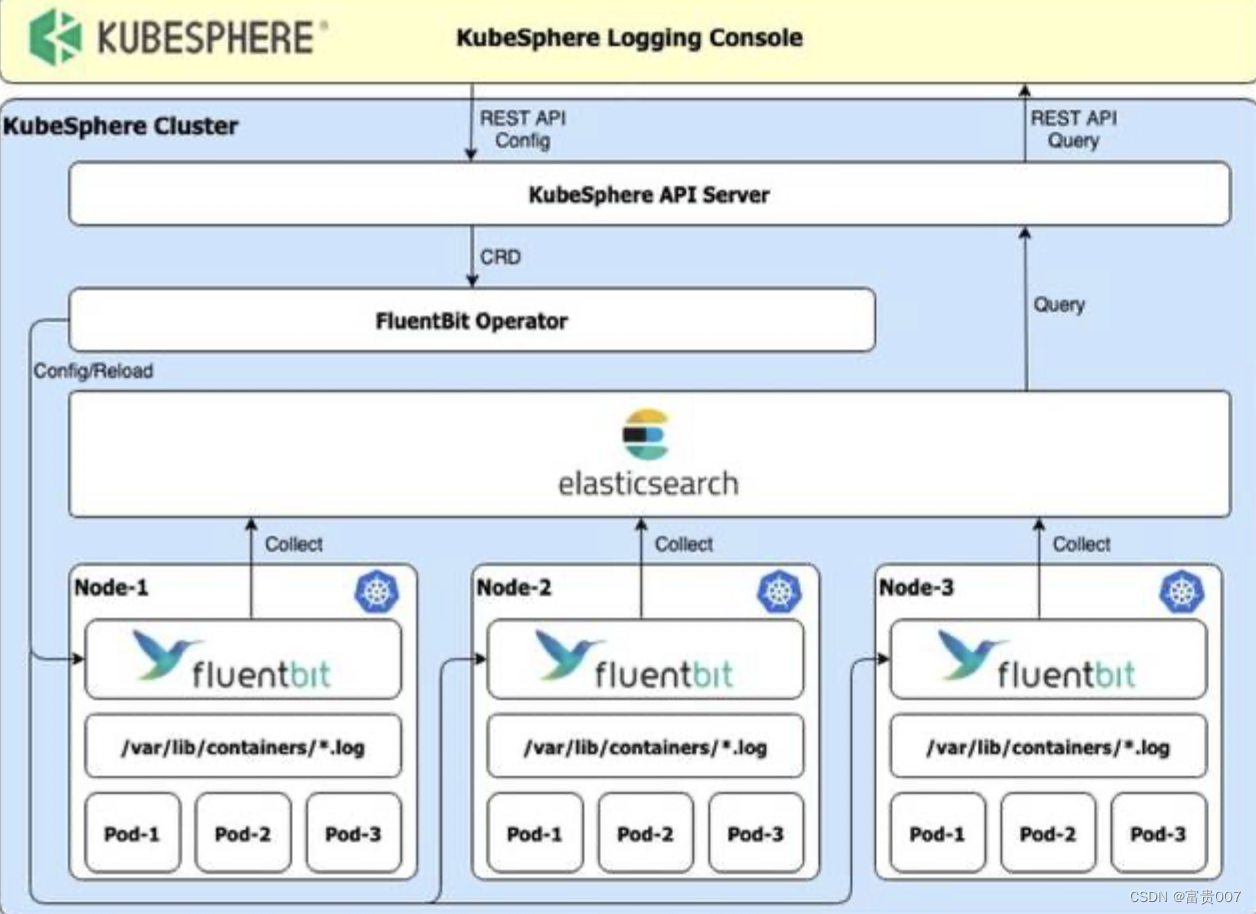
在 KubeSphere 中,选择 Elasticsearch 作为日志后端服务,使用 Fluent Bit 作为日志采集器,KubeSphere 日志控制台通过 FluentBit Operator 控制 FluentBit CRD 中的 Fluent Bit 配置。(用户也可以通过 kubectl edit fluentbit fluent-bit 以 kubernetes 原生的方式来更改 FluentBit 的配置)
通过 FluentBit Operator,KubeSphere 实现了通过控制台灵活的添加/删除/暂停/配置日志接收者。
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我即将开始一个将录制和编辑音频文件的项目,我正在寻找一个好的库(最好是Ruby,但会考虑Java或.NET以外的任何库)以进行实时可视化波形。有人知道我应该从哪里开始搜索吗? 最佳答案 要流入浏览器的数据量很大。Flash或Flex图表可能是唯一能提高内存效率的解决方案。Javascript图表往往会因大型数据集而崩溃。 关于ruby-Ruby中的波形可视化,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
我正在使用此代码在我的Sinatra应用程序中启用日志记录:log_file=File.new('my_log_file.log',"a")$stdout.reopen(log_file)$stderr.reopen(log_file)$stdout.sync=true$stderr.sync=true实际的日志记录是使用:logger.debug("Startingcall.Params=#{params.inspect}")事实证明,只有INFO或更高级别的日志消息被记录,而DEBUG消息没有被记录。我正在寻找一种将日志级别设置为DEBUG的方法。 最佳
我有这段代码来跟踪远程日志文件:defdo_tail(session,file)session.open_channeldo|channel|channel.on_datado|ch,data|puts"[#{file}]->#{data}"endchannel.exec"tail-f#{file}"endNet::SSH.start("host","user",:password=>"passwd")do|session|do_tailsession,"/path_to_log/file.log"session.loop我只想在file.log中检索带有ERROR字符串的行,我正在尝