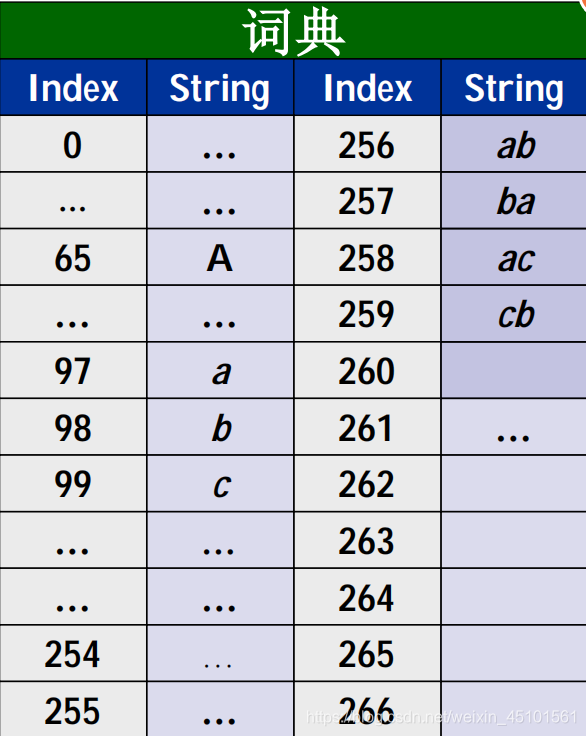
首先我们有一个0到255的ASCII码表,然后得到若干字符串对其进行编码,再对编码后的码流进行解码以验证。
编码:
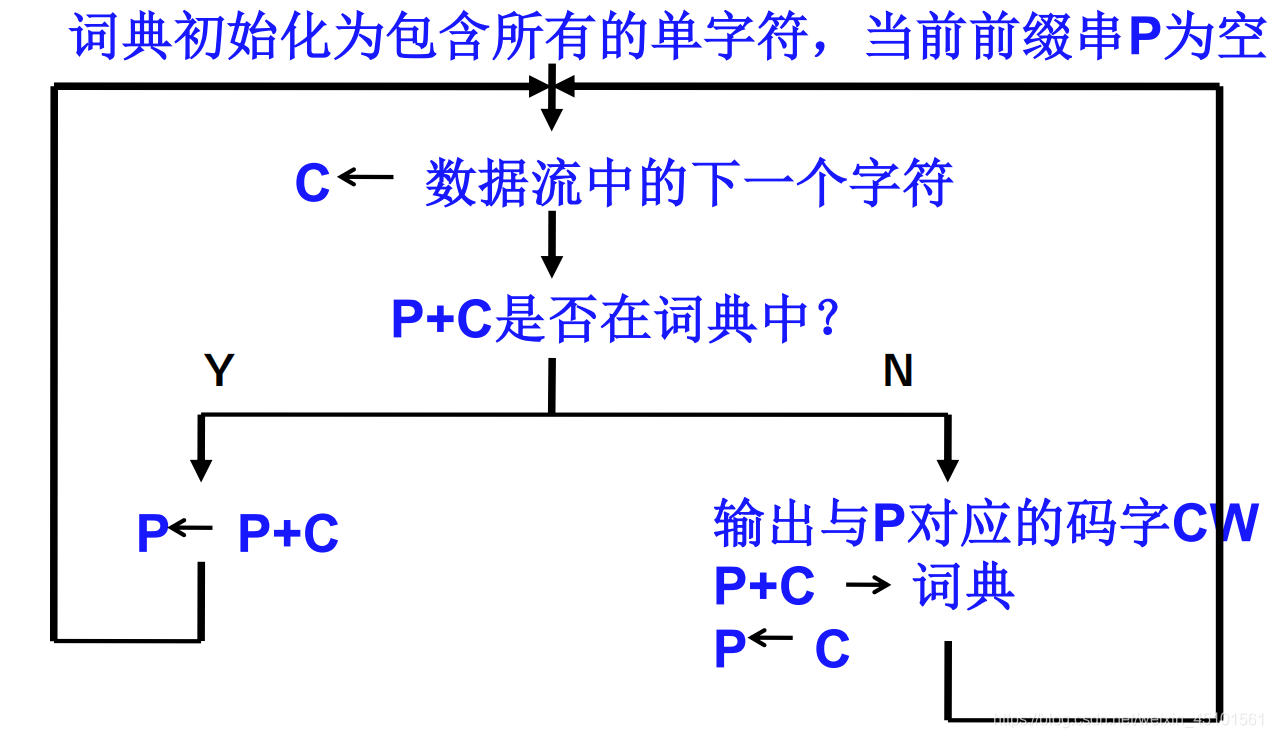 初始化:前缀P为空,第一个字符进入后缀C
初始化:前缀P为空,第一个字符进入后缀C
判断:P+C(P为a,C为b时,P+C为ab)是否在字典中?
是的话将P+C赋给前缀,下一个字符进入后缀,回到判断
否的话将P码字输出,P+C写入词典,C赋给前缀,下一个字符进入后缀,回到判断
解码:
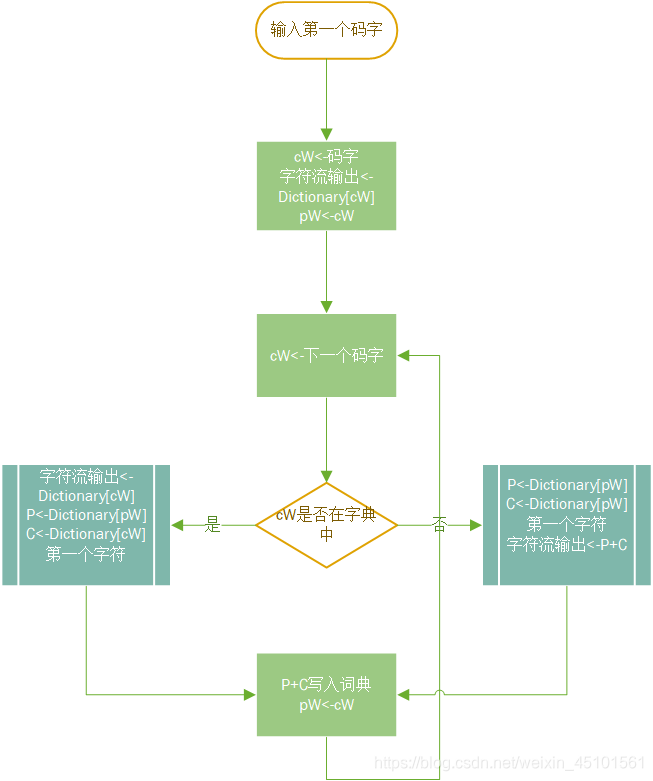 初始化:第一个码字赋值给cW,并在字典中查找到对应的字符并输出,cW再赋值给pW
初始化:第一个码字赋值给cW,并在字典中查找到对应的字符并输出,cW再赋值给pW
依次进入码字
判断:该码字是否在字典中有记录
是的话先将cW在字典中对应的字符输出,再将pW对应的字符和cW对应的字符串中第一个字符连接起来,得到P+C写入词典,cW再赋值给pW,进入下一个码字并判断。
否的话将pW对应的字符串和其字符串中第一个字符连接起来,得到P+C写入词典并输出,cW再赋值给pW,进入下一个码字并判断。
要理解代码主要是要理解这几个变量或者函数
1.对结构体的理解
struct {
int suffix;// suffix 指的是P,parent指的是C
int parent, firstchild, nextsibling;
} dictionary[MAX_CODE + 1];
int next_code;// 指向词典中最大的码字下一个码字,例如词典中最大编码为255,next_code指向256
int d_stack[MAX_CODE]; // 一个码字对应一个字符串,主要用来依次输出字符串中的字符,为倒序排列
因为一个码字经常作为其他码字的前缀,所以通过子节点可以很快地找到一个码字的前缀对应的码字,从而逐渐一个字符一个字符输出后缀。
要注意d_stack是用来遍历输出一个码字对应的字符串的,d_stack经常被覆盖,且为倒序排列。
2.对DecodeString的理解
int DecodeString(int start, int code) {
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix; // 后缀写入d_stack中
code = dictionary[code].parent; // code依次去找前缀
count++; // 计数
}
return count;
}
这个输入参数:start,指的是从输出字符串d_stack中哪个位置开始存入字符,这个主要是以后解码时,cW不在字典中的情况要涉及到一个小小的细节,后面代码会给出注释。
这个函数主要是用来输出当前码字对应的字符串以及返回该字符串的长度。
其他的代码部分理解都比较简单了。
lzw_E.c(核心主程序)
/*
* Definition for LZW coding
*
* vim: ts=4 sw=4 cindent nowrap
*/
#include <stdlib.h>
#include <stdio.h>
#include "bitio.h"
#define MAX_CODE 65535
struct {
int suffix;// suffix 指的是P,parent指的是C
int parent, firstchild, nextsibling; // 后面两个变量是用来一个一个输出字符用的
} dictionary[MAX_CODE + 1];
int next_code;// 指向词典中最大的码字下一个码字,例如词典中最大编码为255,next_code指向256
int d_stack[MAX_CODE]; // 一个码字对应一个字符串,主要用来依次输出字符串中的字符,为倒序排列
#define input(f) ((int)BitsInput( f, 16))
#define output(f, x) BitsOutput( f, (unsigned long)(x), 16)
int DecodeString(int start, int code);
void InitDictionary(void);
// 打印从256开始,由LZW算法编码得到的码表。
void PrintDictionary(void) {
int n;
int count;
for (n = 256; n < next_code; n++) {
count = DecodeString(0, n);
printf("%4d->", n);
while (0 < count--) printf("%c", (char)(d_stack[count]));
printf("\n");
}
}
// 将码字对应的字符串中的字符一个一个存入数组d_stack当中,便于字符串输出
// 当start=0,code=258时,
// 假设码字258对应aba,P=ab,C=a,先将suffix即C中的a存入d_stack[0],然后P=a,C=b,将b存入d_stack[1],最后再将a存入d_stack[2],便于输出aba
// 返回的是这个码字对应的字符串的长度
int DecodeString(int start, int code) {
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix; // 后缀写入d_stack中
code = dictionary[code].parent; // code依次去找前缀
count++; // 计数
}
return count;
}
// 初始化码表为ASCII码表
void InitDictionary(void) {
int i;
for (i = 0; i < 256; i++) {
dictionary[i].suffix = i;
dictionary[i].parent = -1;
dictionary[i].firstchild = -1;
dictionary[i].nextsibling = i + 1;
}
dictionary[255].nextsibling = -1;
next_code = 256;
}
/*
* Input: string represented by string_code in dictionary,
* Output: the index of character+string in the dictionary
* index = -1 if not found
*/
int InDictionary(int character, int string_code) {
int sibling;
if (0 > string_code) return character;
sibling = dictionary[string_code].firstchild;
while (-1 < sibling) {
if (character == dictionary[sibling].suffix) return sibling;
sibling = dictionary[sibling].nextsibling;
}
return -1;
}
void AddToDictionary(int character, int string_code) {
int firstsibling, nextsibling;
if (0 > string_code) return;
dictionary[next_code].suffix = character;
dictionary[next_code].parent = string_code;
dictionary[next_code].nextsibling = -1;
dictionary[next_code].firstchild = -1;
firstsibling = dictionary[string_code].firstchild;
if (-1 < firstsibling) { // the parent has child
nextsibling = firstsibling;
while (-1 < dictionary[nextsibling].nextsibling)
nextsibling = dictionary[nextsibling].nextsibling;
dictionary[nextsibling].nextsibling = next_code;
}
else {// no child before, modify it to be the first
dictionary[string_code].firstchild = next_code;
}
next_code++;
}
void LZWEncode(FILE* fp, BITFILE* bf) {
int character;
int string_code;
int index;
unsigned long file_length;
fseek(fp, 0, SEEK_END);
file_length = ftell(fp);
fseek(fp, 0, SEEK_SET);
BitsOutput(bf, file_length, 4 * 8);
InitDictionary();// 初始化词典
string_code = -1;// P
while (EOF != (character = fgetc(fp))) {
index = InDictionary(character, string_code); // 找到P+C在词典中的编码,如果找到则返回码字给index,否则返回-1给Index
if (0 <= index) { // string_code指的是P,character指的是C ,P+C 在字典里面的话
string_code = index; // P <- P+C
}
else { // P+C不在字典里面的话
output(bf, string_code); // 以字符流输出P
if (MAX_CODE > next_code) { // free space in dictionary
// add string+character to dictionary
AddToDictionary(character, string_code); // 将P+C写入字典
}
string_code = character; // P <- C
}
}
output(bf, string_code);
}
void LZWDecode(BITFILE* bf, FILE* fp) {
int character;
int new_code, last_code;
int phrase_length;
unsigned long file_length;
file_length = BitsInput(bf, 4 * 8);
if (-1 == file_length) file_length = 0;
/*需填充*/
InitDictionary(); // 初始化词典
last_code = -1; // last_code指的是pW
while (0 < file_length) {
new_code = input(bf); // 输入二进制文件,new_code指的是cW
if (new_code >= next_code) { // 如果cW不在字典里面,将pW的第一个字符写入C,pW写入P,输出P+C
d_stack[0] = character; // pW的第一个字符character存入输出字符串d_stack最后一个字符中(d_stack倒着输出)
phrase_length = DecodeString(1, last_code); // 将pW从位置1开始倒着存入d_stack,因为位置0写入了pW的第一个字符
}
else { // 如果cW在字典里面的话,直接将cW存入d_stack输出
phrase_length = DecodeString(0, new_code);
}
character = d_stack[phrase_length - 1]; // 当前cW的第一个字符存入character中,因为d_stack是倒着来的,作为下一次循环的pW的第一个字符
while (0 < phrase_length) {
phrase_length--;
fputc(d_stack[phrase_length], fp);// 输出当前码字对应的字符串
file_length--;
}
if (MAX_CODE > next_code) {// P+C写入词典
AddToDictionary(character, last_code);
}
last_code = new_code;// pW <- cW
}
}
int main(int argc, char** argv) {
FILE* fp;
BITFILE* bf;
if (4 > argc) {
fprintf(stdout, "usage: \n%s <o> <ifile> <ofile>\n", argv[0]);
fprintf(stdout, "\t<o>: E or D reffers encode or decode\n");
fprintf(stdout, "\t<ifile>: input file name\n");
fprintf(stdout, "\t<ofile>: output file name\n");
return -1;
}
if ('E' == argv[1][0]) { // do encoding
fp = fopen(argv[2], "rb");
bf = OpenBitFileOutput(argv[3]);
if (NULL != fp && NULL != bf) {
LZWEncode(fp, bf);
fclose(fp);
CloseBitFileOutput(bf);
fprintf(stdout, "encoding done\n");
}
}
else if ('D' == argv[1][0]) { // do decoding
bf = OpenBitFileInput(argv[2]);
fp = fopen(argv[3], "wb");
if (NULL != fp && NULL != bf) {
LZWDecode(bf, fp);
fclose(fp);
CloseBitFileInput(bf);
fprintf(stdout, "decoding done\n");
}
}
else { // otherwise
fprintf(stderr, "not supported operation\n");
}
PrintDictionary();
return 0;
}
bitio.c (主要涉及文件的读取和写入,没有详细研究)
/*
* Definitions for bitwise IO
*
* vim: ts=4 sw=4 cindent
*/
#include <stdlib.h>
#include <stdio.h>
#include "bitio.h"
BITFILE* OpenBitFileInput(char* filename) {
BITFILE* bf;
bf = (BITFILE*)malloc(sizeof(BITFILE));
if (NULL == bf) return NULL;
if (NULL == filename) bf->fp = stdin;
else bf->fp = fopen(filename, "rb");
if (NULL == bf->fp) return NULL;
bf->mask = 0x80;
bf->rack = 0;
return bf;
}
BITFILE* OpenBitFileOutput(char* filename) {
BITFILE* bf;
bf = (BITFILE*)malloc(sizeof(BITFILE));
if (NULL == bf) return NULL;
if (NULL == filename) bf->fp = stdout;
else bf->fp = fopen(filename, "wb");
if (NULL == bf->fp) return NULL;
bf->mask = 0x80;
bf->rack = 0;
return bf;
}
void CloseBitFileInput(BITFILE* bf) {
fclose(bf->fp);
free(bf);
}
void CloseBitFileOutput(BITFILE* bf) {
// Output the remaining bits
if (0x80 != bf->mask) fputc(bf->rack, bf->fp);
fclose(bf->fp);
free(bf);
}
int BitInput(BITFILE* bf) {
int value;
if (0x80 == bf->mask) {
bf->rack = fgetc(bf->fp);
if (EOF == bf->rack) {
fprintf(stderr, "Read after the end of file reached\n");
exit(-1);
}
}
value = bf->mask & bf->rack;
bf->mask >>= 1;
if (0 == bf->mask) bf->mask = 0x80;
return((0 == value) ? 0 : 1);
}
unsigned long BitsInput(BITFILE* bf, int count) {
unsigned long mask;
unsigned long value;
mask = 1L << (count - 1);
value = 0L;
while (0 != mask) {
if (1 == BitInput(bf))
value |= mask;
mask >>= 1;
}
return value;
}
void BitOutput(BITFILE* bf, int bit) {
if (0 != bit) bf->rack |= bf->mask;
bf->mask >>= 1;
if (0 == bf->mask) { // eight bits in rack
fputc(bf->rack, bf->fp);
bf->rack = 0;
bf->mask = 0x80;
}
}
void BitsOutput(BITFILE* bf, unsigned long code, int count) {
unsigned long mask;
mask = 1L << (count - 1);
while (0 != mask) {
BitOutput(bf, (int)(0 == (code & mask) ? 0 : 1));
mask >>= 1;
}
}
#if 0
int main(int argc, char** argv) {
BITFILE* bfi = NULL, * bfo = NULL;
int bit;
int count = 0;
if (1 < argc) {
if (NULL == OpenBitFileInput(bfi, argv[1])) {
fprintf(stderr, "fail open the file\n");
return -1;
}
}
else {
if (NULL == OpenBitFileInput(bfi, NULL)) {
fprintf(stderr, "fail open stdin\n");
return -2;
}
}
if (2 < argc) {
if (NULL == OpenBitFileOutput(bfo, argv[2])) {
fprintf(stderr, "fail open file for output\n");
return -3;
}
}
else {
if (NULL == OpenBitFileOutput(bfo, NULL)) {
fprintf(stderr, "fail open stdout\n");
return -4;
}
}
while (1) {
bit = BitInput(bfi);
fprintf(stderr, "%d", bit);
count++;
if (0 == (count & 7))fprintf(stderr, " ");
BitOutput(bfo, bit);
}
return 0;
}
#endif
bitio.h
#pragma once
/*
* Declaration for bitwise IO
*
* vim: ts=4 sw=4 cindent
*/
#ifndef __BITIO__
#define __BITIO__
#include <stdio.h>
typedef struct {
FILE* fp;
unsigned char mask;
int rack;
}BITFILE;
BITFILE* OpenBitFileInput(char* filename);
BITFILE* OpenBitFileOutput(char* filename);
void CloseBitFileInput(BITFILE* bf);
void CloseBitFileOutput(BITFILE* bf);
int BitInput(BITFILE* bf);
unsigned long BitsInput(BITFILE* bf, int count);
void BitOutput(BITFILE* bf, int bit);
void BitsOutput(BITFILE* bf, unsigned long code, int count);
#endif // __BITIO__
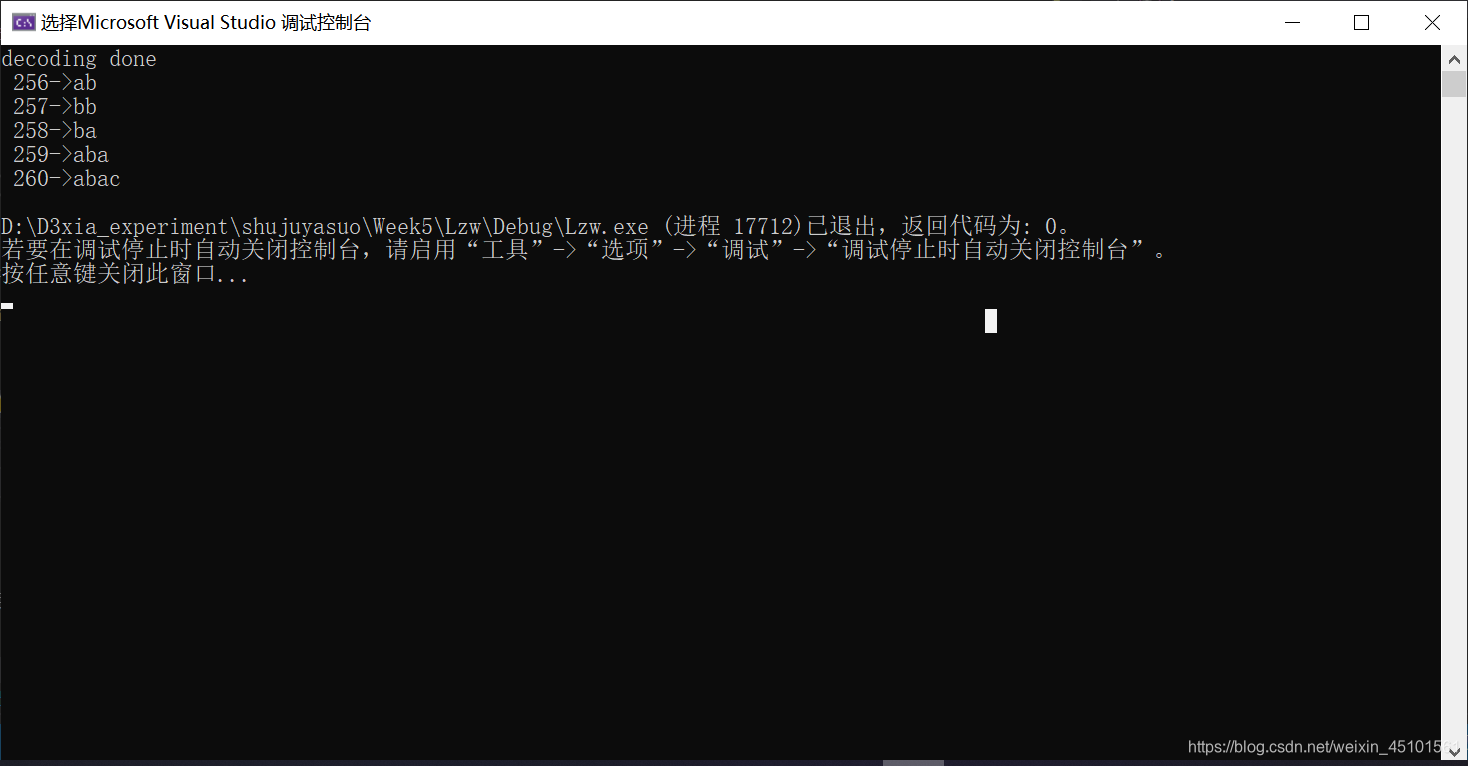
对ppt上字符串abbababac编解码的复现

各种类型文件压缩率比较
对于大多数类型文件压缩后反而变大了,是因为这些文件本身就是经过一定压缩后得到的,进行LZW编码反而会增加不必要的冗余,而比较古老的yuv文件和tga文件和rgb文件本身没有经过处理,通过LZW编码后大大减小了,特别是rgb文件,通过解码还可以恢复为原来的192KB大小的rgb文件。
通过多个txt文件的对比,可以发现影响压缩率的因素主要还有文本重复率,词汇重复率越高,LZW的编码效率越好,如果没有重复或者重复率太低反而会增大文件内存。像上面测试的txt文档中包含着LZW代码,代码中有着变量的重复调用,通过LZW编码有着良好的压缩率,而课本中的字符串编码后文件内存反而从9字节变大为16字节。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.