需要源码和数据集请点赞关注收藏后评论区留言私信~~~
利用计算机自动识别字符的技术,是模式识别应用的一个重要领域。人们在生产和生活中,要处理大量的文字、报表和文本。为了减轻人们的劳动,提高处理效率,从上世纪50年代起就开始探讨文字识别方法,并研制出光学字符识别器。
OCR(Optical Character Recognition)图像文字识别是人工智能的重要分支,赋予计算机人眼的功能,使其可以看图识字,图像文字识别系统流程一般分为图像采集、文字检测、文字识别以及结果输出四部分。
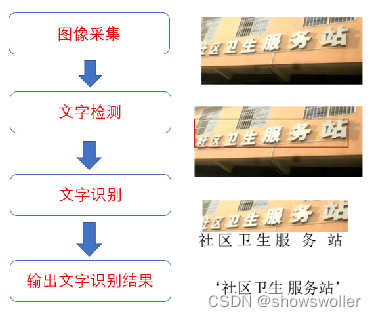
MSRA-TD500该数据集共包含500 张自然场景图像,其分辨率在1296 ´ 864至920 ´ 1280 之间,涵盖了室内商场、标识牌、室外街道、广告牌等大多数场,文本包含中文和英文,有着不同的字体、大小和倾斜方向,部分数据集图像如下图所示。

数据集项目结构如下 分为训练集和测试集
整体项目结构如下 上面是一些算法和模型比如CRAFT CRNN的定义,下面是测试代码
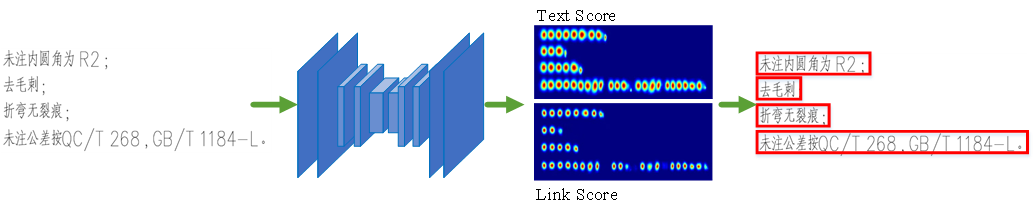
CRAFT算法实现文本行的检测如图下图所示。首先将完整的文字区域输入CRAFT文字检测网络,得到字符级的文字得分结果热图(Text Score)和字符级文本连接得分热图(Link Score),最后根据连通域得到每个文本行的位置
开始运行代码

输出运行结果 可以放入不同图片进行测试
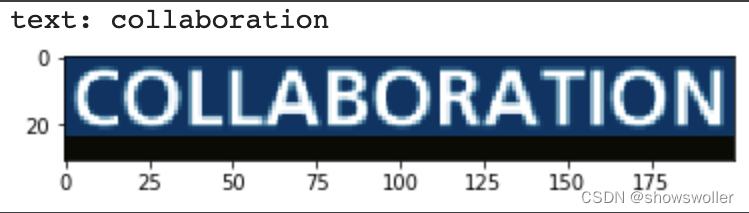



部分代码如下 需要全部代码和数据集请点赞关注收藏后评论区留言私信~~~
"""This script demonstrates how to train the model
on the SynthText90 using multiple GPUs."""
# pylint: disable=invalid-name
import datetime
import argparse
import math
import random
import string
import functools
import itertools
import os
import tarfile
import urllib.request
import numpy as np
import cv2
import imgaug
import tqdm
import tensorflow as tf
import keras_ocr
# pylint: disable=redefined-outer-name
def get_filepaths(data_path, split):
"""Get the list of filepaths for a given split (train, val, or test)."""
with open(os.path.join(data_path, f'mnt/ramdisk/max/90kDICT32px/annotation_{split}.txt'),
'r') as text_file:
filepaths = [
os.path.join(data_path, 'mnt/ramdisk/max/90kDICT32px',
line.split(' ')[0][2:]) for line in text_file.readlines()
]
return filepaths
# pylint: disable=redefined-outer-name
def download_extract_and_process_dataset(data_path):
"""Download and extract the synthtext90 dataset."""
archive_filepath = os.path.join(data_path, 'mjsynth.tar.gz')
extraction_directory = os.path.join(data_path, 'mnt')
if not os.path.isfile(archive_filepath) and not os.path.isdir(extraction_directory):
print('Downloading the dataset.')
urllib.request.urlretrieve("https://www.robots.ox.ac.uk/~vgg/data/text/mjsynth.tar.gz",
archive_filepath)
if not os.path.isdir(extraction_directory):
print('Extracting files.')
with tarfile.open(os.path.join(data_path, 'mjsynth.tar.gz')) as tfile:
tfile.extractall(data_path)
def get_image_generator(filepaths, augmenter, width, height):
"""Get an image generator for a list of SynthText90 filepaths."""
filepaths = filepaths.copy()
for filepath in itertools.cycle(filepaths):
text = filepath.split(os.sep)[-1].split('_')[1].lower()
image = cv2.imread(filepath)
if image is None:
print(f'An error occurred reading: {filepath}')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = keras_ocr.tools.fit(image,
width=width,
height=height,
cval=np.random.randint(low=0, high=255, size=3).astype('uint8'))
if augmenter is not None:
image = augmenter.augment_image(image)
if filepath == filepaths[-1]:
random.shuffle(filepaths)
yield image, text
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Process some integers.')
parser.add_argument('--model_id',
default='recognizer',
help='The name to use for saving model checkpoints.')
parser.add_argument(
'--data_path',
default='.',
help='The path to the directory containing the dataset and where we will put our logs.')
parser.add_argument(
'--logs_path',
default='./logs',
help=(
'The path to where logs and checkpoints should be stored. '
'If a checkpoint matching "model_id" is found, training will resume from that point.'))
parser.add_argument('--batch_size', default=16, help='The training batch size to use.')
parser.add_argument('--no-file-verification', dest='verify_files', action='store_false')
parser.set_defaults(verify_files=True)
args = parser.parse_args()
weights_path = os.path.join(args.logs_path, args.model_id + '.h5')
csv_path = os.path.join(args.logs_path, args.model_id + '.csv')
download_extract_and_process_dataset(args.data_path)
with tf.distribute.MirroredStrategy().scope():
recognizer = keras_ocr.recognition.Recognizer(alphabet=string.digits +
string.ascii_lowercase,
height=31,
width=200,
stn=False,
optimizer=tf.keras.optimizers.RMSprop(),
weights=None)
if os.path.isfile(weights_path):
print('Loading saved weights and creating new version.')
dt_string = datetime.datetime.now().isoformat()
weights_path = os.path.join(args.logs_path, args.model_id + '_' + dt_string + '.h5')
csv_path = os.path.join(args.logs_path, args.model_id + '_' + dt_string + '.csv')
recognizer.model.load_weights(weights_path)
augmenter = imgaug.augmenters.Sequential([
imgaug.augmenters.Multiply((0.9, 1.1)),
imgaug.augmenters.GammaContrast(gamma=(0.5, 3.0)),
imgaug.augmenters.Invert(0.25, per_channel=0.5)
])
os.makedirs(args.logs_path, exist_ok=True)
training_filepaths, validation_filepaths = [
get_filepaths(data_path=args.data_path, split=split) for split in ['train', 'val']
]
if args.verify_files:
assert all(
os.path.isfile(filepath) for
filepath in tqdm.tqdm(training_filepaths + validation_filepaths,
desc='Checking filepaths.')), 'Some files appear to be missing.'
(training_image_generator, training_steps), (validation_image_generator, validation_steps) = [
(get_image_generator(
filepaths=filepaths,
augmenter=augmenter,
width=recognizer.model.input_shape[2],
height=recognizer.model.input_shape[1],
), math.ceil(len(filepaths) / args.batch_size))
for filepaths, augmenter in [(training_filepaths, augmenter), (validation_filepaths, None)]
]
training_generator, validation_generator = [
tf.data.Dataset.from_generator(
functools.partial(recognizer.get_batch_generator,
image_generator=image_generator,
batch_size=args.batch_size),
output_types=((tf.float32, tf.int64, tf.float64, tf.int64), tf.float64),
output_shapes=((tf.TensorShape([None, 31, 200, 1]), tf.TensorShape([None, recognizer.training_model.input_shape[1][1]]),
tf.TensorShape([None,
1]), tf.TensorShape([None,
1])), tf.TensorShape([None, 1])))
for image_generator in [training_image_generator, validation_image_generator]
]
callbacks = [
tf.keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0,
patience=10,
restore_best_weights=False),
tf.keras.callbacks.ModelCheckpoint(weights_path, monitor='val_loss', save_best_only=True),
tf.keras.callbacks.CSVLogger(csv_path)
]
recognizer.training_model.fit(
x=training_generator,
steps_per_epoch=training_steps,
validation_steps=validation_steps,
validation_data=validation_generator,
callbacks=callbacks,
epochs=1000,
)
"""This script is what was used to generate the
backgrounds.zip and fonts.zip files.
"""
# pylint: disable=invalid-name,redefined-outer-name
import json
import urllib.request
import urllib.parse
import concurrent
import shutil
import zipfile
import glob
import os
import numpy as np
import tqdm
import cv2
import keras_ocr
if __name__ == '__main__':
fonts_commit = 'a0726002eab4639ee96056a38cd35f6188011a81'
fonts_sha256 = 'e447d23d24a5bbe8488200a058cd5b75b2acde525421c2e74dbfb90ceafce7bf'
fonts_source_zip_filepath = keras_ocr.tools.download_and_verify(
url=f'https://github.com/google/fonts/archive/{fonts_commit}.zip',
cache_dir='.',
sha256=fonts_sha256)
shutil.rmtree('fonts-raw', ignore_errors=True)
with zipfile.ZipFile(fonts_source_zip_filepath) as zfile:
zfile.extractall(path='fonts-raw')
retained_fonts = []
sha256s = []
basenames = []
# The blacklist includes fonts that, at least for the English alphabet, were found
# to be illegible (e.g., thin fonts) or render in unexpected ways (e.g., mathematics
# fonts).
blacklist = [
'AlmendraDisplay-Regular.ttf', 'RedactedScript-Bold.ttf', 'RedactedScript-Regular.ttf',
'Sevillana-Regular.ttf', 'Mplus1p-Thin.ttf', 'Stalemate-Regular.ttf', 'jsMath-cmsy10.ttf',
'Codystar-Regular.ttf', 'AdventPro-Thin.ttf', 'RoundedMplus1c-Thin.ttf',
'EncodeSans-Thin.ttf', 'AlegreyaSans-ThinItalic.ttf', 'AlegreyaSans-Thin.ttf',
'FiraSans-Thin.ttf', 'FiraSans-ThinItalic.ttf', 'WorkSans-Thin.ttf',
'Tomorrow-ThinItalic.ttf', 'Tomorrow-Thin.ttf', 'Italianno-Regular.ttf',
'IBMPlexSansCondensed-Thin.ttf', 'IBMPlexSansCondensed-ThinItalic.ttf',
'Lato-ExtraLightItalic.ttf', 'LibreBarcode128Text-Regular.ttf',
'LibreBarcode39-Regular.ttf', 'LibreBarcode39ExtendedText-Regular.ttf',
'EncodeSansExpanded-ExtraLight.ttf', 'Exo-Thin.ttf', 'Exo-ThinItalic.ttf',
'DrSugiyama-Regular.ttf', 'Taviraj-ThinItalic.ttf', 'SixCaps.ttf', 'IBMPlexSans-Thin.ttf',
'IBMPlexSans-ThinItalic.ttf', 'AdobeBlank-Regular.ttf',
'FiraSansExtraCondensed-ThinItalic.ttf', 'HeptaSlab[wght].ttf', 'Karla-Italic[wght].ttf',
'Karla[wght].ttf', 'RalewayDots-Regular.ttf', 'FiraSansCondensed-ThinItalic.ttf',
'jsMath-cmex10.ttf', 'LibreBarcode39Text-Regular.ttf', 'LibreBarcode39Extended-Regular.ttf',
'EricaOne-Regular.ttf', 'ArimaMadurai-Thin.ttf', 'IBMPlexSerif-ExtraLight.ttf',
'IBMPlexSerif-ExtraLightItalic.ttf', 'IBMPlexSerif-ThinItalic.ttf', 'IBMPlexSerif-Thin.ttf',
'Exo2-Thin.ttf', 'Exo2-ThinItalic.ttf', 'BungeeOutline-Regular.ttf', 'Redacted-Regular.ttf',
'JosefinSlab-ThinItalic.ttf', 'GothicA1-Thin.ttf', 'Kanit-ThinItalic.ttf', 'Kanit-Thin.ttf',
'AlegreyaSansSC-ThinItalic.ttf', 'AlegreyaSansSC-Thin.ttf', 'Chathura-Thin.ttf',
'Blinker-Thin.ttf', 'Italiana-Regular.ttf', 'Miama-Regular.ttf', 'Grenze-ThinItalic.ttf',
'LeagueScript-Regular.ttf', 'BigShouldersDisplay-Thin.ttf', 'YanoneKaffeesatz[wght].ttf',
'BungeeHairline-Regular.ttf', 'JosefinSans-Thin.ttf', 'JosefinSans-ThinItalic.ttf',
'Monofett.ttf', 'Raleway-ThinItalic.ttf', 'Raleway-Thin.ttf', 'JosefinSansStd-Light.ttf',
'LibreBarcode128-Regular.ttf'
]
for filepath in tqdm.tqdm(sorted(glob.glob('fonts-raw/**/**/**/*.ttf')),
desc='Filtering fonts.'):
sha256 = keras_ocr.tools.sha256sum(filepath)
basename = os.path.basename(filepath)
# We check the sha256 and filenames because some of the fonts
# in the repository are duplicated (see TRIVIA.md).
if sha256 in sha256s or basename in basenames or basename in blacklist:
continue
sha256s.append(sha256)
basenames.append(basename)
retained_fonts.append(filepath)
retained_font_families = set([filepath.split(os.sep)[-2] for filepath in retained_fonts])
added = []
with zipfile.ZipFile(file='fonts.zip', mode='w') as zfile:
for font_family in tqdm.tqdm(retained_font_families, desc='Saving ZIP file.'):
# We want to keep all the metadata files plus
# the retained font files. And we don't want
# to add the same file twice.
files = [
input_filepath for input_filepath in glob.glob(f'fonts-raw/**/**/{font_family}/*')
if input_filepath not in added and
(input_filepath in retained_fonts or os.path.splitext(input_filepath)[1] != '.ttf')
]
added.extend(files)
for input_filepath in files:
zfile.write(filename=input_filepath,
arcname=os.path.join(*input_filepath.split(os.sep)[-2:]))
print('Finished saving fonts file.')
# pylint: disable=line-too-long
url = (
'https://commons.wikimedia.org/w/api.php?action=query&generator=categorymembers&gcmtype=file&format=json'
'&gcmtitle=Category:Featured_pictures_on_Wikimedia_Commons&prop=imageinfo&gcmlimit=50&iiprop=url&iiurlwidth=1024'
)
gcmcontinue = None
max_responses = 300
responses = []
for responseCount in tqdm.tqdm(range(max_responses)):
current_url = url
if gcmcontinue is not None:
current_url += f'&continue=gcmcontinue||&gcmcontinue={gcmcontinue}'
with urllib.request.urlopen(url=current_url) as response:
current = json.loads(response.read())
responses.append(current)
gcmcontinue = None if 'continue' not in current else current['continue']['gcmcontinue']
if gcmcontinue is None:
break
print('Finished getting list of images.')
# We want to avoid animated images as well as icon files.
image_urls = []
for response in responses:
image_urls.extend(
[page['imageinfo'][0]['thumburl'] for page in response['query']['pages'].values()])
image_urls = [url for url in image_urls if url.lower().endswith('.jpg')]
shutil.rmtree('backgrounds', ignore_errors=True)
os.makedirs('backgrounds')
assert len(image_urls) == len(set(image_urls)), 'Duplicates found!'
with concurrent.futures.ThreadPoolExecutor(max_workers=2) as executor:
futures = [
executor.submit(keras_ocr.tools.download_and_verify,
url=url,
cache_dir='./backgrounds',
verbose=False) for url in image_urls
]
for _ in tqdm.tqdm(concurrent.futures.as_completed(futures), total=len(futures)):
pass
for filepath in glob.glob('backgrounds/*.JPG'):
os.rename(filepath, filepath.lower())
print('Filtering images by aspect ratio and maximum contiguous contour.')
image_paths = np.array(sorted(glob.glob('backgrounds/*.jpg')))
def compute_metrics(filepath):
image = keras_ocr.tools.read(filepath)
aspect_ratio = image.shape[0] / image.shape[1]
contour, _ = keras_ocr.tools.get_maximum_uniform_contour(image, fontsize=40)
area = cv2.contourArea(contour) if contour is not None else 0
return aspect_ratio, area
metrics = np.array([compute_metrics(filepath) for filepath in tqdm.tqdm(image_paths)])
filtered_paths = image_paths[(metrics[:, 0] < 3 / 2) & (metrics[:, 0] > 2 / 3) &
(metrics[:, 1] > 1e6)]
detector = keras_ocr.detection.Detector()
paths_with_text = [
filepath for filepath in tqdm.tqdm(filtered_paths) if len(
detector.detect(
images=[keras_ocr.tools.read_and_fit(filepath, width=640, height=640)])[0]) > 0
]
filtered_paths = np.array([path for path in filtered_paths if path not in paths_with_text])
filtered_basenames = list(map(os.path.basename, filtered_paths))
basename_to_url = {
os.path.basename(urllib.parse.urlparse(url).path).lower(): url
for url in image_urls
}
filtered_urls = [basename_to_url[basename.lower()] for basename in filtered_basenames]
assert len(filtered_urls) == len(filtered_paths)
removed_paths = [filepath for filepath in image_paths if filepath not in filtered_paths]
for filepath in removed_paths:
os.remove(filepath)
with open('backgrounds/urls.txt', 'w') as f:
f.write('\n'.join(filtered_urls))
with zipfile.ZipFile(file='backgrounds.zip', mode='w') as zfile:
for filepath in tqdm.tqdm(filtered_paths.tolist() + ['backgrounds/urls.txt'],
desc='Saving ZIP file.'):
zfile.write(filename=filepath, arcname=os.path.basename(filepath.lower()))
创作不易 觉得有帮助请点赞关注收藏~~~
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
这段代码似乎创建了一个范围从a到z的数组,但我不明白*的作用。有人可以解释一下吗?[*"a".."z"] 最佳答案 它叫做splatoperator.SplattinganLvalueAmaximumofonelvaluemaybesplattedinwhichcaseitisassignedanArrayconsistingoftheremainingrvaluesthatlackcorrespondinglvalues.Iftherightmostlvalueissplattedthenitconsumesallrvaluesw
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包