 转转平台主要对业务运营数据(埋点)进行分析,埋点数据包含在售商品的曝光、点击、展现等事件,覆盖场景数据量很大,且在部分分析场景需要支持精确去重。大数据量加上去重、数据分组等计算使得指标在统计过程中运算量较大。除此之外,在一些数据分析场景中需要计算留存率、漏斗转化等复杂的数据模型。虽然在离线数仓的数仓分层和汇总层对通用指标做了预计算处理,但由于这些模型的分析维度通常是不确定的,因此预计算无法满足产品或者运营提出的个性化报表的需求,需分析师或数仓工程师进行sql开发,使得数据开发链路长交付慢,数据价值也随着时间的推移而减少。作为分析平台,既需要保证数据时效性、架构的高可用,也要做到任意维度、任意指标的秒级响应。基于以上情况,需要一个即席查询的引擎来实现。
转转平台主要对业务运营数据(埋点)进行分析,埋点数据包含在售商品的曝光、点击、展现等事件,覆盖场景数据量很大,且在部分分析场景需要支持精确去重。大数据量加上去重、数据分组等计算使得指标在统计过程中运算量较大。除此之外,在一些数据分析场景中需要计算留存率、漏斗转化等复杂的数据模型。虽然在离线数仓的数仓分层和汇总层对通用指标做了预计算处理,但由于这些模型的分析维度通常是不确定的,因此预计算无法满足产品或者运营提出的个性化报表的需求,需分析师或数仓工程师进行sql开发,使得数据开发链路长交付慢,数据价值也随着时间的推移而减少。作为分析平台,既需要保证数据时效性、架构的高可用,也要做到任意维度、任意指标的秒级响应。基于以上情况,需要一个即席查询的引擎来实现。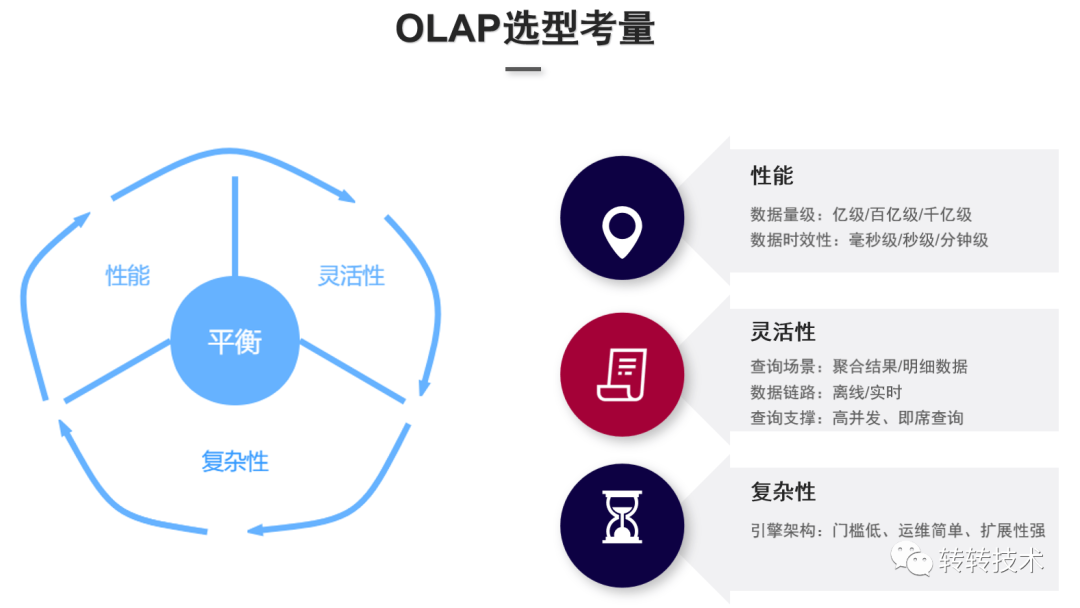 转转对OLAP引擎选型考量有三个方面:性能,灵活性,复杂性。
转转对OLAP引擎选型考量有三个方面:性能,灵活性,复杂性。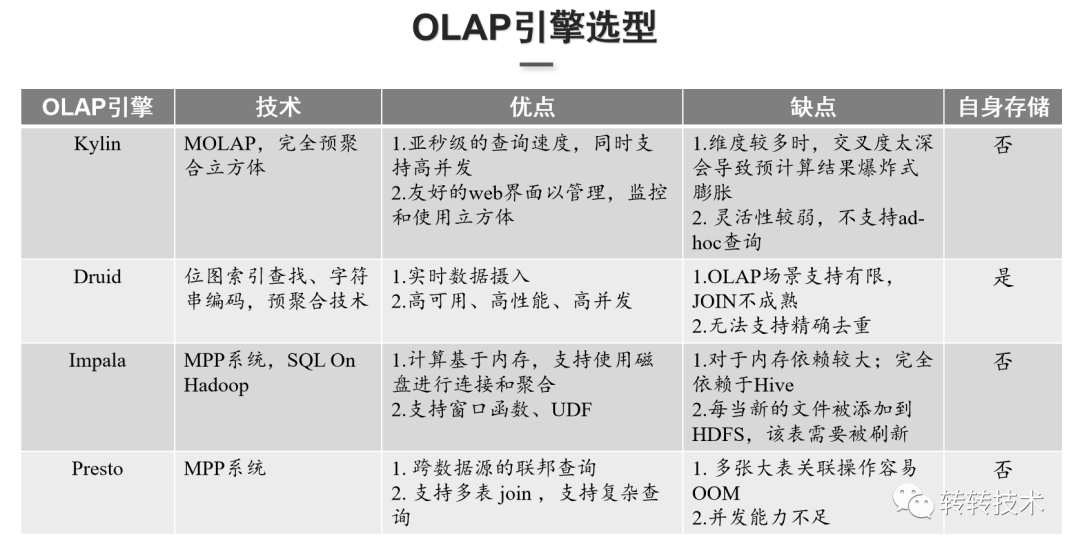 OLAP引擎主要分为两大类:
OLAP引擎主要分为两大类: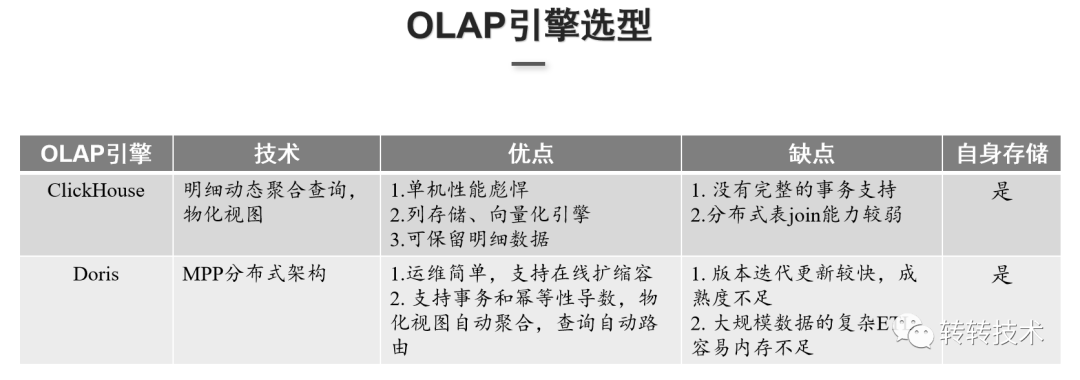 ClickHouse单机性能很强,基于列式存储,能利用向量化引擎做到并行化计算,查询基本上是毫秒级或秒级的反馈,但ClickHouse没有完整的事务支持,对分布式表的join能力较弱。Doris运维简单,扩缩容容易且支持事务,但Doris版本更新迭代较快且成熟度不够,也没有像ClickHouse自带的一些函数如漏斗、留存,不足以支撑转转的业务场景。基于以上考量,最终选择了ClickHouse作为分析引擎。
ClickHouse单机性能很强,基于列式存储,能利用向量化引擎做到并行化计算,查询基本上是毫秒级或秒级的反馈,但ClickHouse没有完整的事务支持,对分布式表的join能力较弱。Doris运维简单,扩缩容容易且支持事务,但Doris版本更新迭代较快且成熟度不够,也没有像ClickHouse自带的一些函数如漏斗、留存,不足以支撑转转的业务场景。基于以上考量,最终选择了ClickHouse作为分析引擎。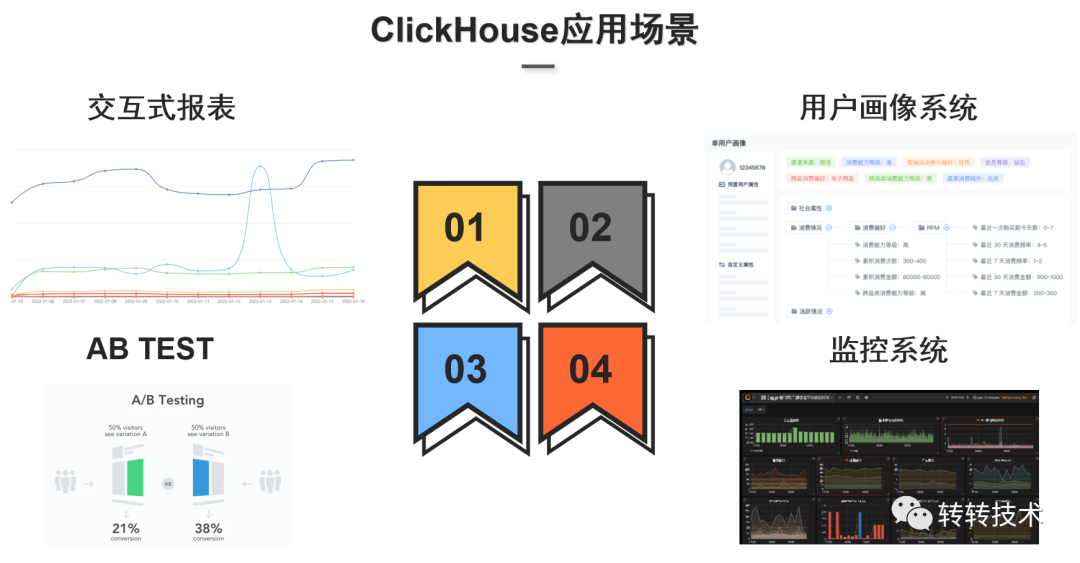 ClickHouse的查询场景主要分为四大类:
ClickHouse的查询场景主要分为四大类: 转转高斯平台的核心功能主要包含两个部分:
转转高斯平台的核心功能主要包含两个部分: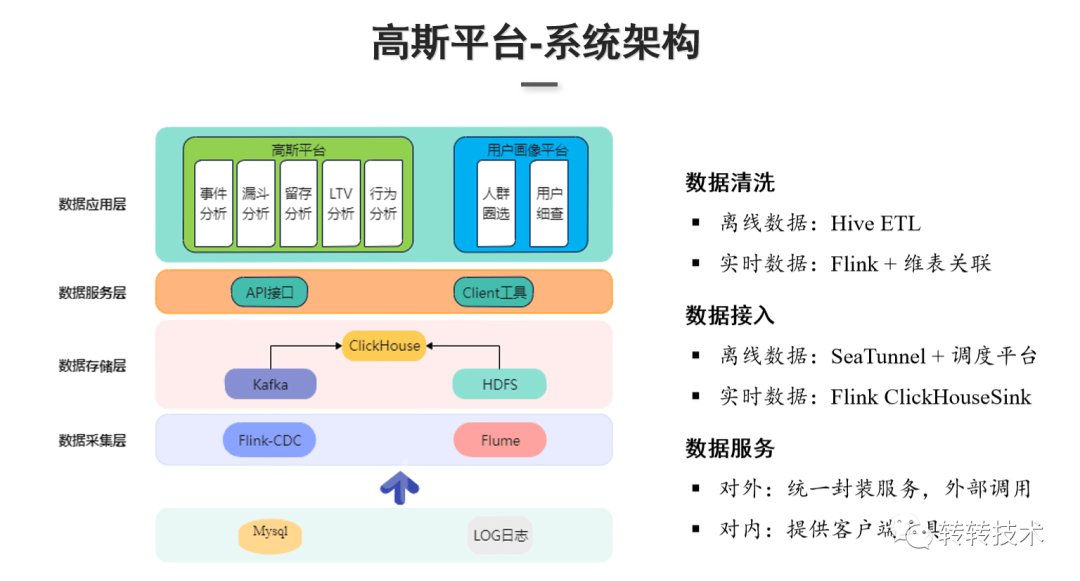 数据采集层:数据来源主要是业务库和埋点数据。业务库数据存储在MySQL里,埋点数据通常是LOG日志。MySQL业务库的数据通过Flink-CDC实时抽取到Kafka;LOG日志由Flume Agent采集并分发到实时和离线两条通道,实时埋点日志会sink写入Kafka,离线的日志sink到HDFS。数据存储层:主要是对数据采集层过来的数据进行存储,存储采用的是Kafka和HDFS,ClickHouse基于底层数据清洗和数据接入,实现宽表存储。数据服务层:对外统一封装的HTTP服务,由外部系统调用,对内提供了SQL化的客户端工具。数据应用层:主要是基于ClickHouse的高斯自助分析平台和用户画像平台两大产品。高斯分析平台可以对于用户去做事件分析,计算PV、UV等指标以及留存、LTV、漏斗分析、行为分析等,用户画像平台提供了人群的圈选、用户细查等功能。
数据采集层:数据来源主要是业务库和埋点数据。业务库数据存储在MySQL里,埋点数据通常是LOG日志。MySQL业务库的数据通过Flink-CDC实时抽取到Kafka;LOG日志由Flume Agent采集并分发到实时和离线两条通道,实时埋点日志会sink写入Kafka,离线的日志sink到HDFS。数据存储层:主要是对数据采集层过来的数据进行存储,存储采用的是Kafka和HDFS,ClickHouse基于底层数据清洗和数据接入,实现宽表存储。数据服务层:对外统一封装的HTTP服务,由外部系统调用,对内提供了SQL化的客户端工具。数据应用层:主要是基于ClickHouse的高斯自助分析平台和用户画像平台两大产品。高斯分析平台可以对于用户去做事件分析,计算PV、UV等指标以及留存、LTV、漏斗分析、行为分析等,用户画像平台提供了人群的圈选、用户细查等功能。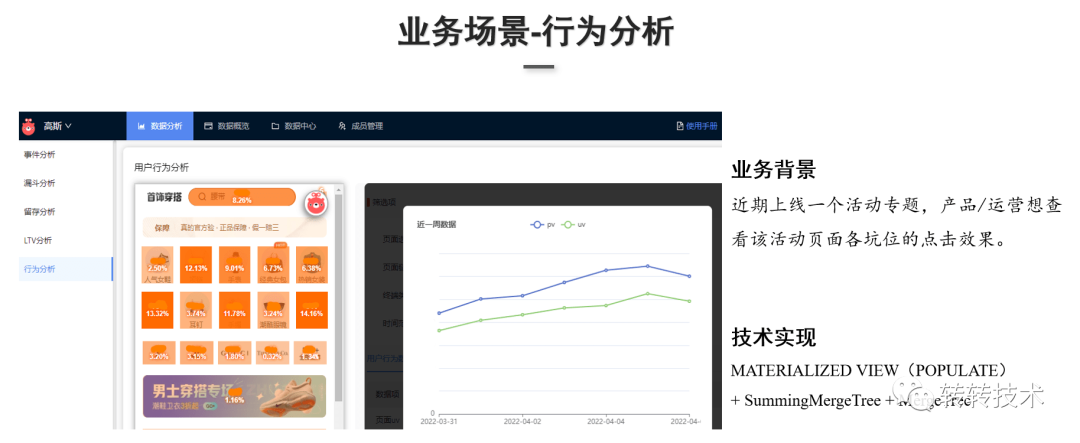 业务背景:App上线活动专题页,业务方想查看活动页面上线后各个坑位的点击的效果。技术实现:采用ClickHouse的物化视图、聚合表引擎,以及明细表引擎。ClickHouse的物化视图可以做实时的数据累加计算,POPULATE关键词决定物化视图的更新策略。在创建物化视图时使用POPULATE关键词会对底层表的历史数据做物化视图的计算。技术实现:采用ClickHouse的物化视图、聚合表引擎,以及明细表引擎。ClickHouse的物化视图可以做实时的数据累加计算,POPULATE关键词决定物化视图的更新策略。在创建物化视图时使用POPULATE关键词会对底层表的历史数据做物化视图的计算。(2)AB-TEST分析
业务背景:App上线活动专题页,业务方想查看活动页面上线后各个坑位的点击的效果。技术实现:采用ClickHouse的物化视图、聚合表引擎,以及明细表引擎。ClickHouse的物化视图可以做实时的数据累加计算,POPULATE关键词决定物化视图的更新策略。在创建物化视图时使用POPULATE关键词会对底层表的历史数据做物化视图的计算。技术实现:采用ClickHouse的物化视图、聚合表引擎,以及明细表引擎。ClickHouse的物化视图可以做实时的数据累加计算,POPULATE关键词决定物化视图的更新策略。在创建物化视图时使用POPULATE关键词会对底层表的历史数据做物化视图的计算。(2)AB-TEST分析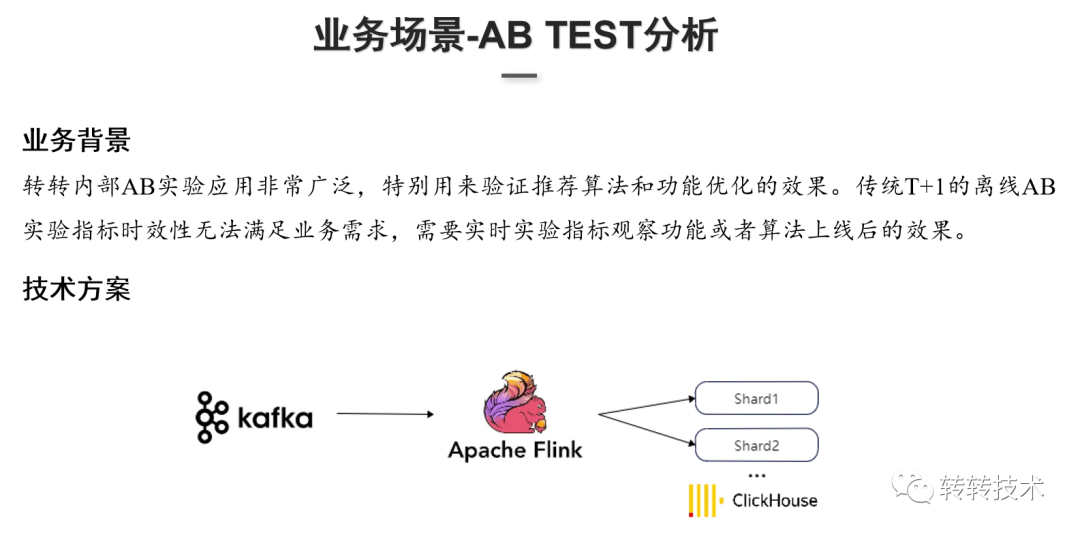 业务背景:转转早期AB-TEST采用传统的T+1日数据,但T+1日数据已无法满足业务需求。技术方案:Flink实时消费Kafka,自定义Sink(支持配置自定义Flush批次大小、时间)到ClickHouse,利用ClickHouse做实时指标的计算。
业务背景:转转早期AB-TEST采用传统的T+1日数据,但T+1日数据已无法满足业务需求。技术方案:Flink实时消费Kafka,自定义Sink(支持配置自定义Flush批次大小、时间)到ClickHouse,利用ClickHouse做实时指标的计算。 在数据分析过程中常见的问题大都是和内存相关的。如上图所示,当内存使用量大于了单台服务器的内存上限,就会抛出该异常。针对这个问题,需要对SQL语句和SQL查询的场景进行分析:
在数据分析过程中常见的问题大都是和内存相关的。如上图所示,当内存使用量大于了单台服务器的内存上限,就会抛出该异常。针对这个问题,需要对SQL语句和SQL查询的场景进行分析: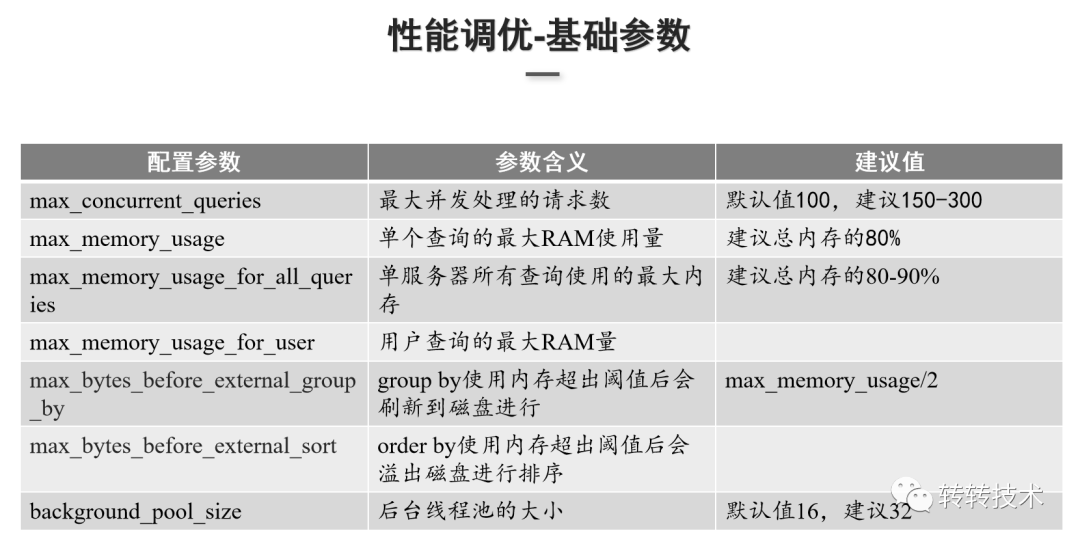 上图是实践的一些优化参数,主要是限制并发处理的请求数和限制内存相关的参数。
上图是实践的一些优化参数,主要是限制并发处理的请求数和限制内存相关的参数。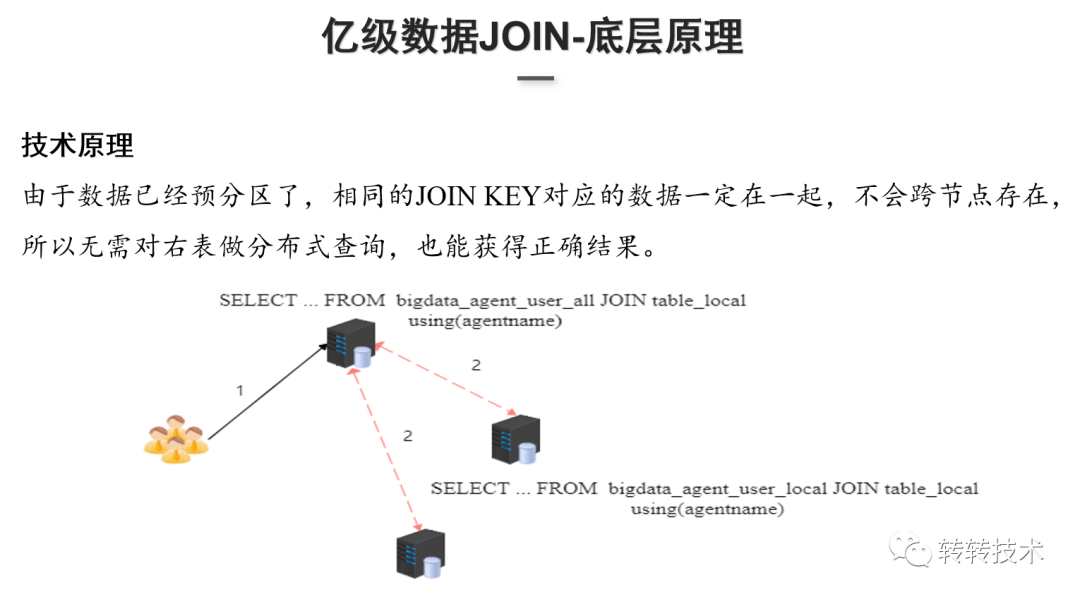 技术原理:在做用户画像数据和行为数据导入的时候,数据已经按照Join Key预分区了,相同的Join Key其实是在同一节点上,因此不需要去做两个分布式表跨节点的Join,只需要去Join本地表就行,执行过程中会把具体的查询逻辑改为本地表,Join本地表之后再汇总最后的计算结果,这样就能得到正确的结果。
技术原理:在做用户画像数据和行为数据导入的时候,数据已经按照Join Key预分区了,相同的Join Key其实是在同一节点上,因此不需要去做两个分布式表跨节点的Join,只需要去Join本地表就行,执行过程中会把具体的查询逻辑改为本地表,Join本地表之后再汇总最后的计算结果,这样就能得到正确的结果。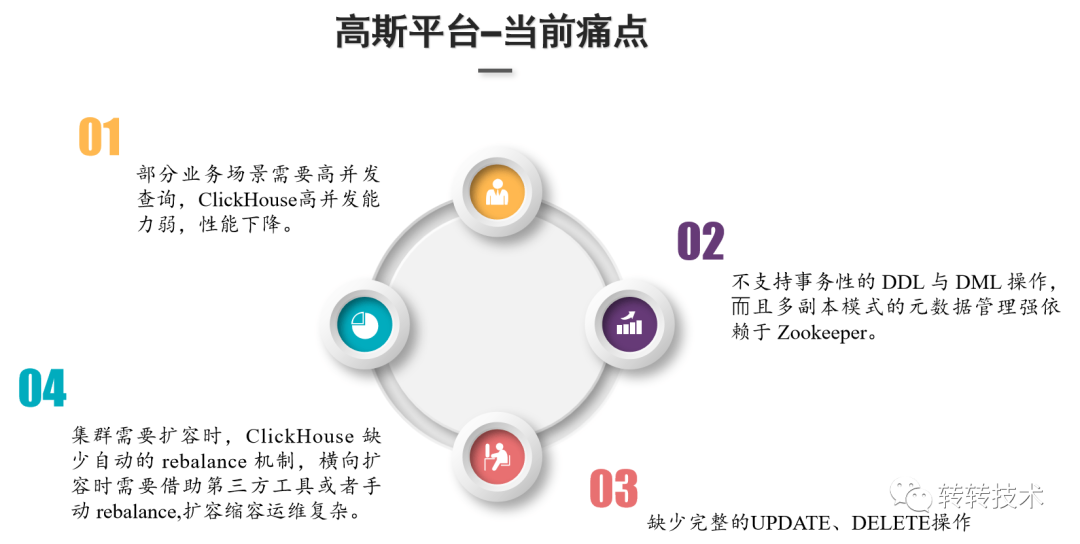

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵