————raft分布式一致性算法。数据存储在分层组织的目录中【类似文件系统,只有叶子结点可以存储数据,相当于文件】
————分布式锁:保持独占【CAS】
————mvcc: revision、keyIndex、treeIndex【B树,每一个结点都是keyIndex】。【boldb key是revision,value是key-value组合】
1. etcd是什么?[]
A highly-available key value store for shared configuration and service discovery.
多个节点之间通过 Raft 一致性算法的完成分布式一致性协同
键值对存储:数据存储在分层组织的目录中,类似于我们日常使用的文件系统。
- 存储方式,采用类似目录结构。
- 只有叶子节点才能真正存储数据,相当于文件。
- 叶子节点的父节点一定是目录,目录不能存储数据。
etcd 的场景默认处理的数据都是系统中的控制数据。所以 etcd 在系统中的角色不是其他 NoSQL 产品的替代品,更不能作为应用的主要数据存储。etcd 中应该尽量只存储系统中服务的配置信息,对于应用数据只推荐把数据量很小,但是更新和访问频次都很高的数据存储在 etcd 中。
2. 动画理解Raft算法
Leader Election.
Log Replication.
First is the election timeout.【The election timeout is randomized to be between 150ms and 300ms.】
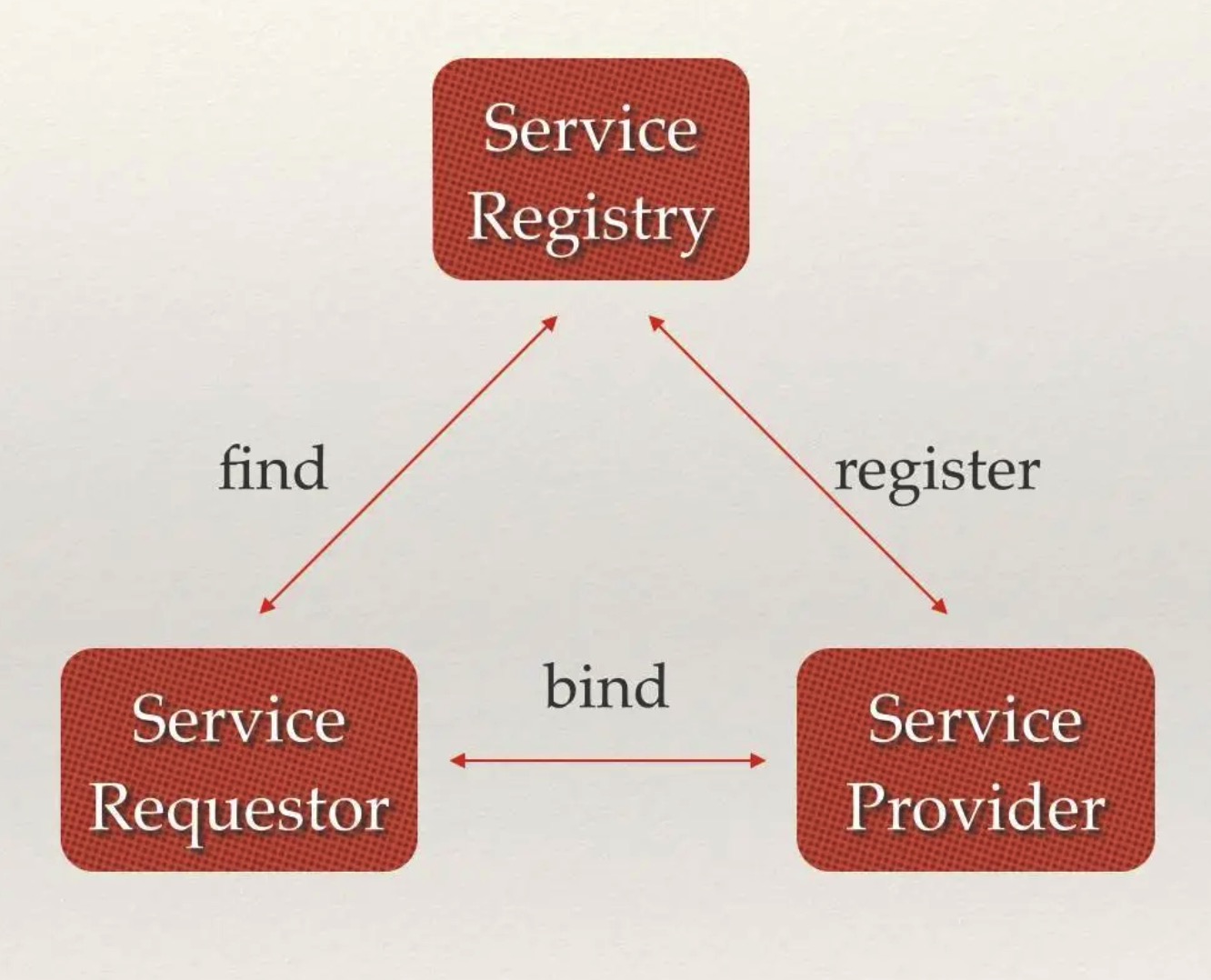
3. 服务发现
服务发现要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
1. 一个强一致性、高可用的服务存储目录。基于 Raft 算法的 etcd 就是一个强一致性高可用的服务存储目录。
2. 一种注册服务和监控服务健康状态的机制。用户可以在 etcd 中注册服务,并且对注册的服务设置 key TTL,定时保持服务的心跳以达到监控健康状态的效果。
3. 一种查找和连接服务的机制。通过在 etcd 指定的主题(由服务名称构成的服务目录)下注册的服务也能在对应的主题下查找到。
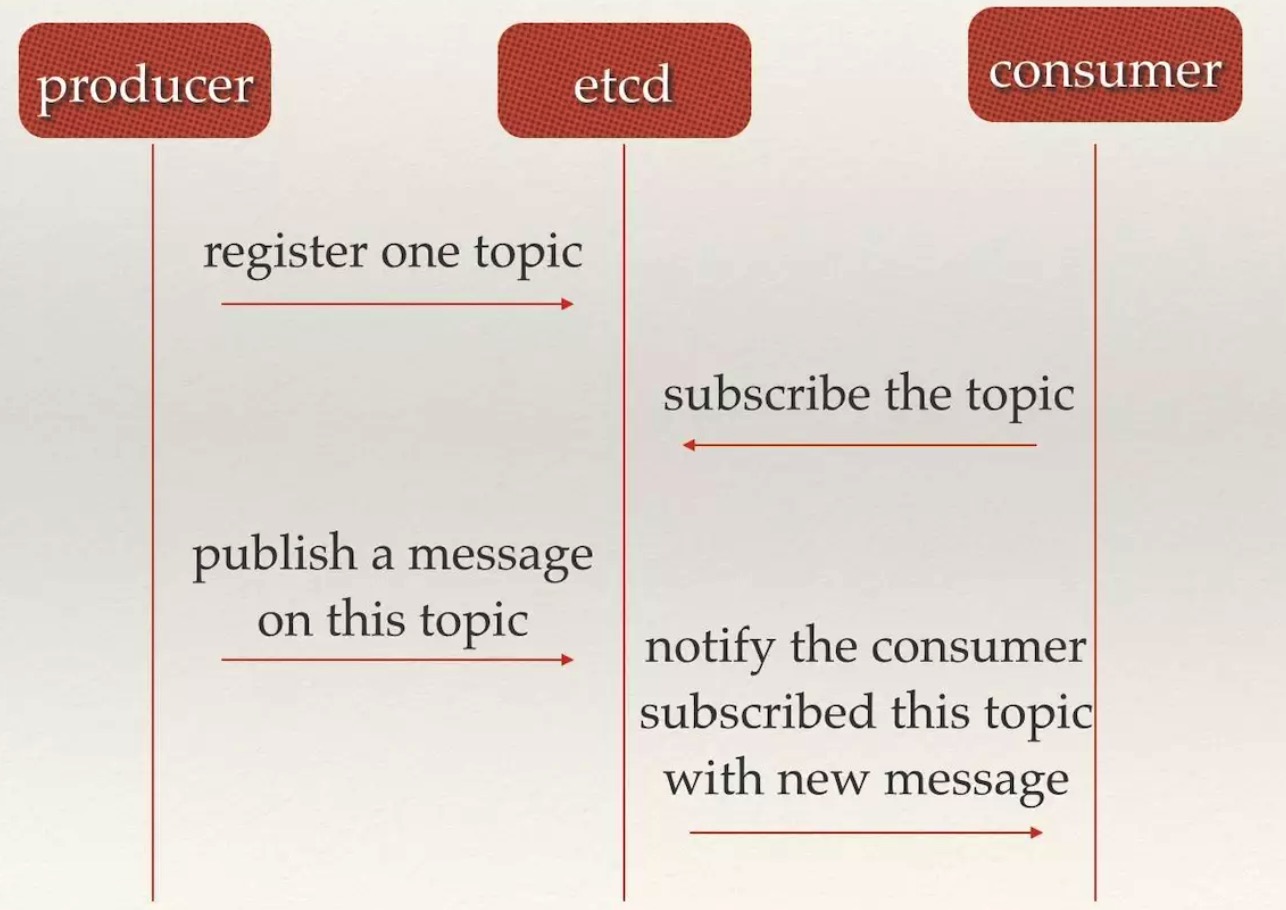
4. 消息发布与订阅
在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅,即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者。
通过消息发布与订阅的方式可以做到分布式系统配置的集中式管理与动态更新。
应用在启动的时候主动从etcd获取一次配置信息,同时,在etcd节点上注册一个 Watcher 并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的
5. 分布式锁
因为etcd使用Raft算法保持了数据的强一致性,某次操作存储到集群中的值必然是全局一致的,所以很容易实现分布式锁。锁服务有两种使用方式,一是保持独占,二是控制时序。
保持独占即所有获取锁的用户最终只有一个可以得到。etcd为此提供了一套实现分布式锁原子操作CAS(CompareAndSwap)的API。通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。
控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序。etcd为此也提供了一套API(自动创建有序键),对一个目录建值时指定为POST动作,这样etcd会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用API按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
6. etcd和redis的对比
etcd 和 redis 都支持键值存储,也支持分布式特性,redis支持的数据格式更加丰富,但是他们两个定位和应用场景不一样,关键差异如下:
- redis在分布式环境下不是强一致性的,可能会丢失数据,或者读取不到最新数据
- redis的数据变化监听机制没有etcd完善
- etcd强一致性保证数据可靠性,导致性能上要低于redis
7. MVCC
MVCC 由于其出色的性能优势,而被越来越多的数据库所采用
它的基本思想是保存一个数据的多个历史版本。
在处理一个写请求时,MVCC 不是简单的用新值覆盖旧值,而是为这一项添加一个新版本的数据。在读取一个数据项时,要先确定一个要读取的版本,然后根据版本找到对应的数据。这种写操作创建新版本,读操作访问旧版本的方式使得读写操作彼此隔离,他们之间就不需要用锁来协调


8. 什么是线性一致性读
所谓线性一致性读,可以简单理解为:当存储系统已将写操作提交成功,那此时读出的数据应是最新的数据(假设这期间没有新的写操作),CAP 理论中的 C(consistency)即是线性一致性。
由于在 Raft 算法中,写操作成功仅仅意味着日志达成了一致(已经落盘),而并不能确保当前状态机也已经 apply 了日志。状态机 apply 日志的行为在大多数 Raft 算法的实现中都是异步的,所以此时读取状态机并不能准确反应数据的状态,很可能会读到过期数据。
基于以上这个原因,要想实现线性一致性读,一个较为简单通用的策略就是:每次读操作的时候记录此时集群的 commited index,当状态机的 apply index 大于或等于 commited index 时才读取数据并返回。由于此时状态机已经把读请求发起时的已提交日志进行了 apply 动作,所以此时状态机的状态就可以反应读请求发起时的状态,符合线性一致性读的要求。这便是 ReadIndex 算法。
如何准确获取集群的 commited index ?
如何确保leader的有效性?
情景:利用 etcd 的客户端发起读请求时,服务端如何响应读请求 ?
客户端读请求的发起过程
服务端的处理过程

linearizableReadLoop()顾名思义是一个 for-loop:func (s *EtcdServer) linearizableReadLoop() { ... for { // 这里的命名有点不好,此处的 ctx 其实是 request id // 为每一个读请求赋予一个唯一的 id ctx := make([]byte, 8) binary.BigEndian.PutUint64(ctx, s.reqIDGen.Next()) // 如果能从 readwaitc 接收到信号则说明有新的读请求到来 // 否则将一直阻塞在 receive 环节 select { case <-s.readwaitc: case <-s.stopping: return } // 创建一个新的 notifier 对象让其下一次读请求使用 nextnr := newNotifier() s.readMu.Lock() // 将当前的通知通道拷贝到 nr 并将其换成 nextnr nr := s.readNotifier s.readNotifier = nextnr s.readMu.Unlock() // 调用 raft 模块来获取当前读请求的 read index cctx, cancel := context.WithTimeout(context.Background(), c.Cfg.ReqTimeout()) // ReadIndex() 对应的是从 raft 模块发出 read index 请求 if err := c.r.ReadIndex(cctx, ctx); err != nil { ... } ... // ReadIndex() 发出了 read index 请求 // 接下来就是处理 read index 请求的返回 // 如果成功返回将可以从对应 channel 接收到信号 var ( timeout bool // read index 请求是否超时 done bool // read index 请求是否完成 ) // 阻塞等待 read index 请求完成 // 请求完成说明当前读请求已经获取到对应准确的 read index for !timeout && !done { select { // 如果接收到消息,说明 read index 请求完成 case rs = <-s.r.readStateC: // 检查 request id 是否正确 done := bytes.Equal(r.RequestCtx, ctx) ... } } // 如果有问题,放弃此次 loop if !done { continue } // 此处就是等待 apply index >= read index if ai := s.getAppliedIndex(); ai < rs.Index { select { // 等待 apply index >= read index case <-s.applyWait.Wait(rs.Index): case <-s.stopping: return } } // 发出可以进行读取状态机的信号 nr.notify(nil) } }
当使用
addRequest()的时候:func (ro *readOnly) addRequest(index uint64, m pb.Message) { // ctx 是 request id ctx := string(m.Entries[0].Data) // 如果已经在待处理请求队列中则直接返回 if _, ok := ro.pendingReadIndex[ctx]; ok { return } // 将请求加到一个 hash 中:key: 第一个 entry 的内容;value: 构建一个 readIndexStatus ro.pendingReadIndex[ctx] = &readIndexStatus{index: index, req: m, acks: make(map[uint64]struct{})} // 将读请求的 request id 添加到 readIndexQueue 中 ro.readIndexQueue = append(ro.readIndexQueue, ctx) }
我们看到当 leader 处理读请求,先是调用
addRequest()添加读请求,接着就向其他节点广播心跳且 payload 是 request id,当 leader 收到心跳的响应时:func stepLeader(r *raft, m pb.Message) { switch m.Type { ... case pb.MsgHeartbeatResp: ... // 积累收到的 ack ackCount := r.readOnly.recvAck(m) // 如果还没收到法定节点数量的 ack 直接返回 if ackCount < r.quorum() { return } // 收到足够多的 ack,清理队列的 map 和 queue 并将此时读状态添加到 readStates 队列中 // 上次会将 readStates 包装成 Ready 数据结构透给应用层 rss := r.readOnly.advance(m) for _, rs := range rss { req := rs.req if req.From == None || req.From == r.id { r.readStates = append(r.readStates, ReadState{Index: rs.index, RequestCtx: req.Entries[0].Data}) } else { r.send(pb.Message{To: req.From, Type: pb.MsgReadIndexResp, Index: rs.index, Entries: req.Entries}) } } ... } }

目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
蓝桥杯第十四届蓝桥杯模拟赛第三期考场应对攻略(C/C++)真题可以去此处寻找https://blog.csdn.net/weixin_46239370/article/details/105464885?spm=1001.2014.3001.5506考前准备考前五分钟,开十个源文件,并把头文件等必须写的部分写出来,写完的程序一定要有顺序地保留万能头可以尝试开一下#include试题1:问题描述请找到一个大于2022的最小数,这个数转换成十六进制之后,所有的数位(不含前导0)都为字母(A到F)。请将这个数的十进制形式作为答案提交。答案提交这是一道结果填空的题,你只需要算出结果后提交即可。本题的结
我不确定这个问题是不是太傻了,但我还没有找到解决办法。通常我会把一个数组放在一个循环中current_humans=[.....]current_humans.eachdo|characteristic|putscharacteristicend但是如果我有这个:classHumanattr_accessor:name,:country,:sex@@current_humans=[]defself.current_humans@@current_humansenddefself.print#@@current_humans.eachdo|characteristic|#putschar
最近收到好多学员的一些提问,零基础没经验,能不能转行到网络工程师?发展前景怎么样?薪资能有多少?应该有不少朋友都有这个疑问,那么,今天我尽量给大家做出一个详细的解答,希望能有所帮助。内容可能比较长,大家可以点赞收藏,再慢慢阅读。零基础没经验,能不能转行到网络工程师?想要快速学习并入门网工行业,最快速也是效率做高的方法就是考取行业的相关证书。就像其他行业一样,也有属于网工的认证。网络工程师这个行业,现在最具有含金量并被行业承认的两个认证:思科和华为。简单说一下两者的区别: 从含金量角度来看。两者的含金量其实差不多,HCIE是华为认证的最高等级证书,CCIE是思科认证的最高等级证书,两者在网
如今eBPF程序的编写,很多都是基于bcc或者bpftrace进行,也有开发者直接基于libbpf库进行,但是不管怎样,编写的xx.bpf.c程序,在加载到内核时,都必须经过内核的verifier校验器进行各种边界和内存检查,经常会碰到各种奇奇怪怪的verifier报错,导致eBPF程序加载失败。有些错误,开发者可能要花费大量的时间去分析并修改程序,并祈祷程序能够加载成功。特别是在低版本的内核运行低版本Clang编译器编译的eBPF程序,错误提示非常糟糕,经常找不到出错点,这就大大增加了开发难度。为此,本文梳理了一些常见的eBPFverifier报错,避免更多的人走弯路,写出能成功加载的eBP
目录步骤安装第二步下载flink第三步安装flink-streaming-patform-web第四步配置flinkweb平台第五步运行demo在Flink学习的入门阶段,非常重要的一个过程就是Flink环境搭建,这是认识FLInk框架的第一步,也是为后续的理论学习和代码练习打下基础。今天加米谷大数据就为大家带来Flink环境搭建的步骤解析,帮助大家一步步来部署好Flink环境。步骤1、使用gitclone到本地后,使用IDEA打开项目2、修改数据库连接flink-streaming-web/src/main/resources/application.properties3、在本地数据库中创
一、生命周期1、定义生命周期(LifeCycle)是指一个对象从创建>运行→>销毁的整个阶段,强调的是一个时间段。2、分类应用生命周期(app.js):特指小程序从启动->运行→销毁的过程App({//小程序初始化完成时,执行此函数,全局只触发一次。可以做一些初始化的工作。onLaunch:function(options){},//小程序启动,或从后台进入前台显示时触发。onShow:function(options){},//小程序从前台进入后台时触发。onHide:function(){}})页面生命周期(页面.js):特指小程序中,每个页面的加载→渲染→销毁的过程Page({onLoa
这里写目录标题专业性问题你系统的整体设计是怎么样?用了什么技术?这些技术应用的好处是什么?框架,SSM,SSH这些有什么优势。前端,前端用了什么;你数据库整体的设计是怎么样的,某个表,某个字段作用是什么?MySQL,为什么用MySQL;有几个表;三范式;主键这些基础。数据库链接方式,数据库设计中的ER图、范式等。你系统核心功能怎么实现?业务,功能模块,老师对某个模块需要详细了解,问你是怎么做的,其实就是你的代码实现逻辑;功能怎么实现的。流程图,讲一下有角色的功能区别。一些软件工程,数据库的基础知识,比如时序图,ER图,范式之类的。前后端交互用什么;ajax等等软件测试Java基础,三大特性,有
报错1:报错:RuntimeError:DataLoaderworker(pid93789)iskilledbysignal:Killed.原因:显存不够报错2:报错:TqdmWarning:IProgressnotfound.Pleaseupdatejupyterandipywidgets.解决:pipinstallipywidgets报错3:报错:RuntimeError:CUDAerror:CUBLAS_STATUS_EXECUTION_FAILEDwhencalling`cublasSgemm(handle,opa,opb,m,n,k,&alpha,a,lda,b,ldb,&beta
我希望在json中有这样的结构:{"a":["b":1,"c":2],"x":["y":3,"z":4]}我可以使用“a”和“x”作为目录并在它们下面有节点来存储数据。我无法在如何完成此操作的文档或示例中找到它。编辑:我刚刚通过为Set调用/a/b、/a/c、/x/y和/x/z将其创建为目录。这创建了必要的结构,但我正在寻找一个简化版本来做同样的事情,而不是4个etcd调用。 最佳答案 创建目录etcdctlmkdir做你想做的,有这个选项:etcdctlsetmyobject'{"a":["b":1,"c":2],"x":["y"