摘要:基于深度学习的瓶子检测软件用于自动化瓶子检测与识别,对于各种场景下的塑料瓶、玻璃瓶等进行检测并计数,辅助计算机瓶子生产回收等工序。本文详细介绍深度学习的瓶子检测软件,在介绍算法原理的同时,给出Python的实现代码、训练数据集,以及PyQt的UI界面。基于YOLOv5算法实现对图像中存在的多个目标进行识别分类,在界面中可以选择各种图片、视频进行检测识别;博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。本博文目录如下:
参考博客文章:https://mbd.pub/o/bread/ZJaXlZ1q 参考视频演示:https://www.bilibili.com/video/BV1jM411W7Tz/ 离线依赖库下载:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (提取码:oy4n ) 玻璃瓶、塑料瓶使用后可以回收再产,既有效解决废料垃圾的产生,同时也能够实现产品的循环利用。随着政府对环境友好型、资源节约型社会建设的不断深入,以及消费者本身环保节约意识的增强,玻璃包装逐渐成为政府鼓励类包装材料,消费者的认可程度也不断提升。各种玻璃瓶、塑料瓶的应用已然非常普遍,诸如:酒类、医包、日包等。 为了提高塑料瓶、玻璃瓶的生产线定位检测、回收利用等环节的效率,在当今全自动化生产趋势下,需要配合机床、机器人等识别和定位瓶子位置,传统的人工目测显然不是一个好的解决方案。各企业急需一套全自动化的检测方案,来解决这个难以平衡的矛盾。 本系统基于YOLOv5算法实现,采用登录注册进行用户管理,对于图片、视频和摄像头捕获的实时画面,可检测瓶子,系统支持结果记录、展示和保存,每次检测的结果记录在表格中。对此这里给出博主设计的界面,同款的简约风,功能也可以满足图片、视频和摄像头的识别检测,希望大家可以喜欢,初始界面如下图: 检测类别时的界面截图(点击图片可放大)如下图,可识别画面中存在的多个类别,也可开启摄像头或视频检测: 详细的功能演示效果参见博主的B站视频或下一节的动图演示,觉得不错的朋友敬请点赞、关注加收藏!系统UI界面的设计工作量较大,界面美化更需仔细雕琢,大家有任何建议或意见和可在下方评论交流。
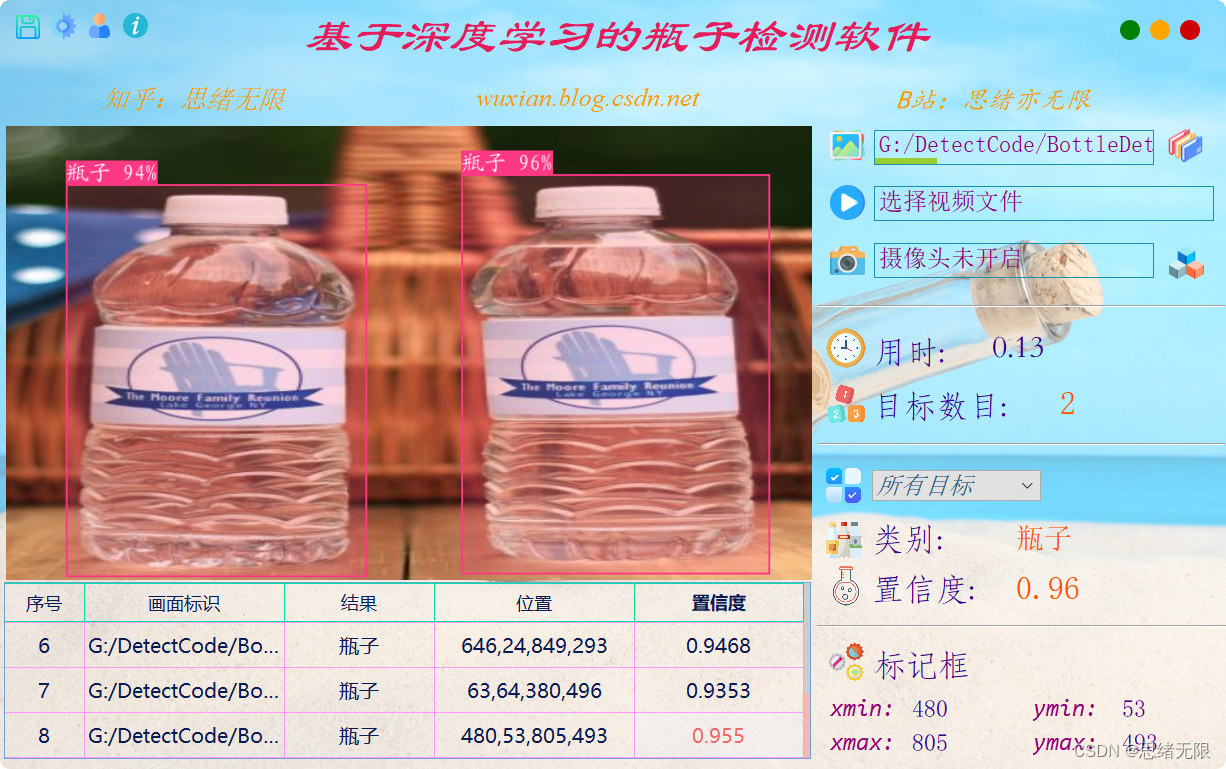
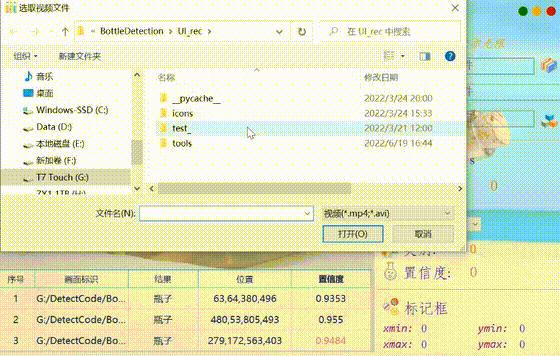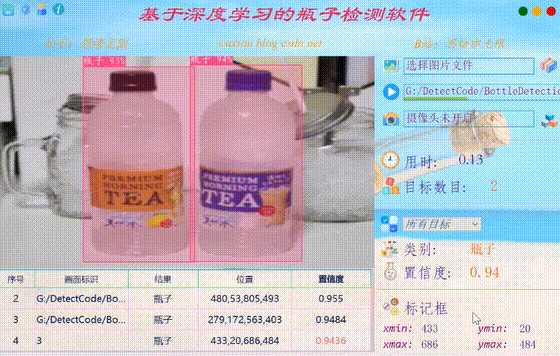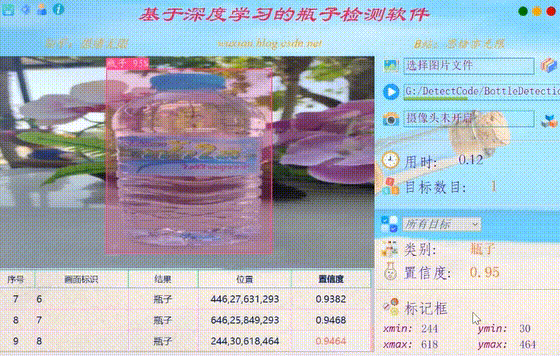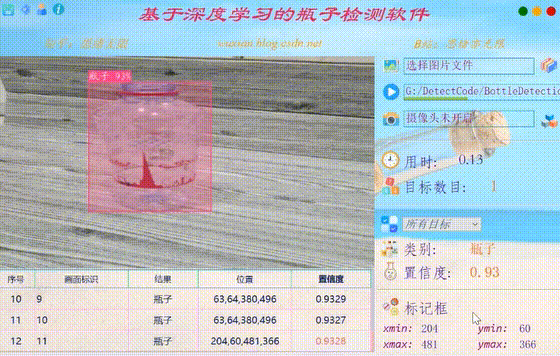
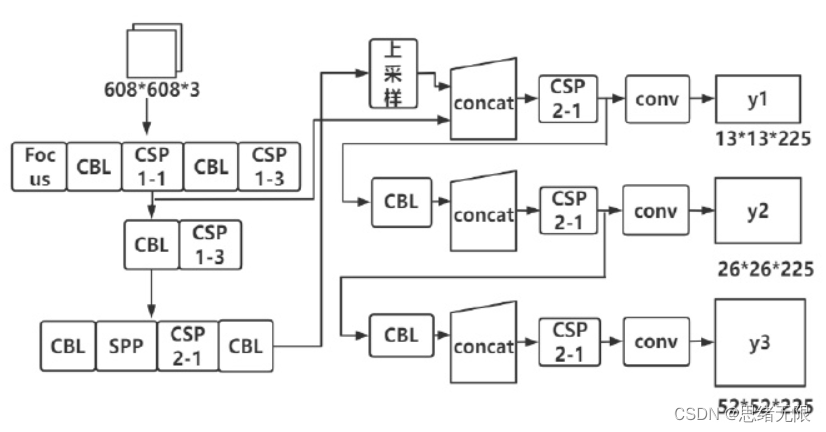
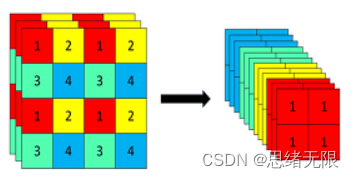
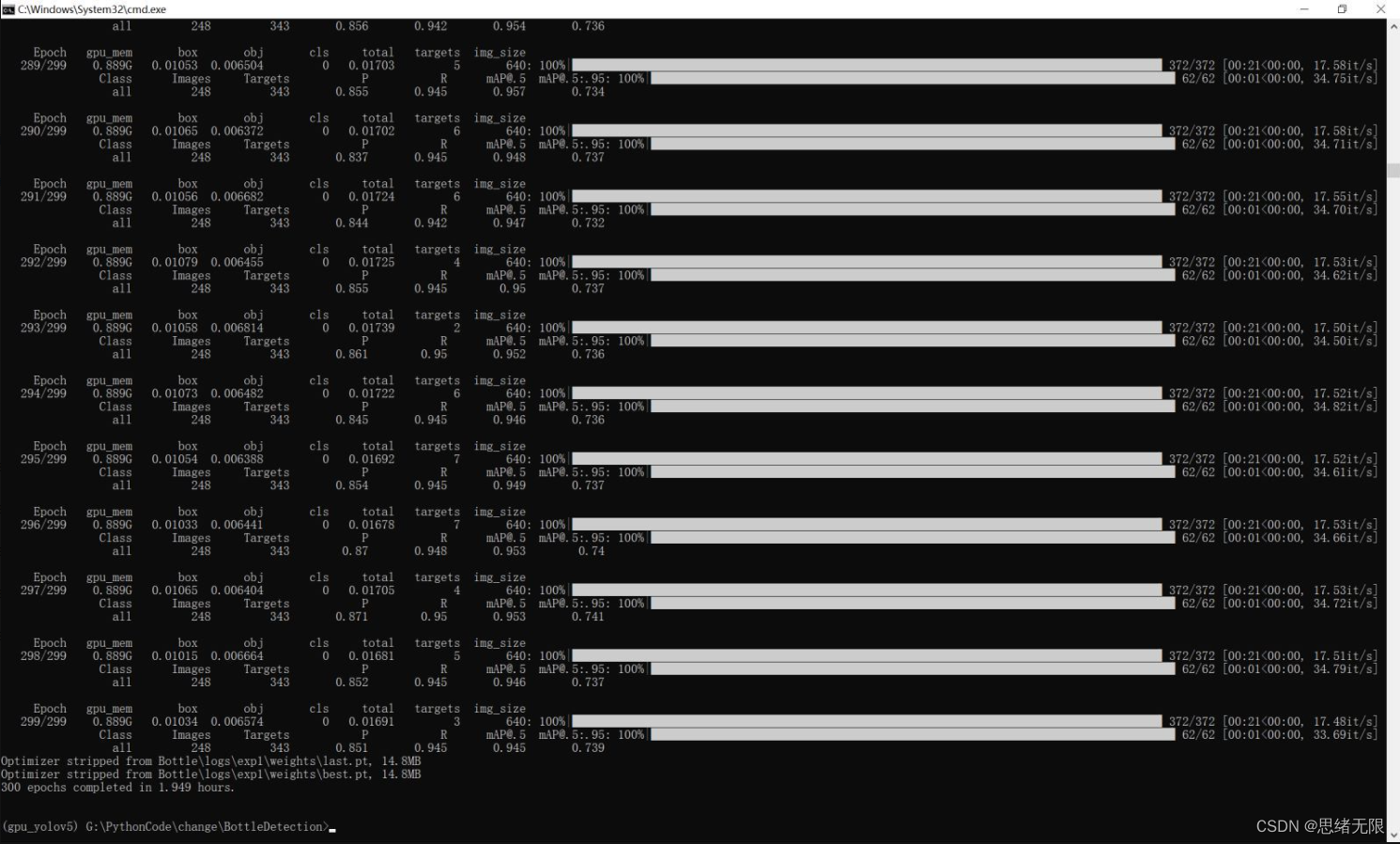
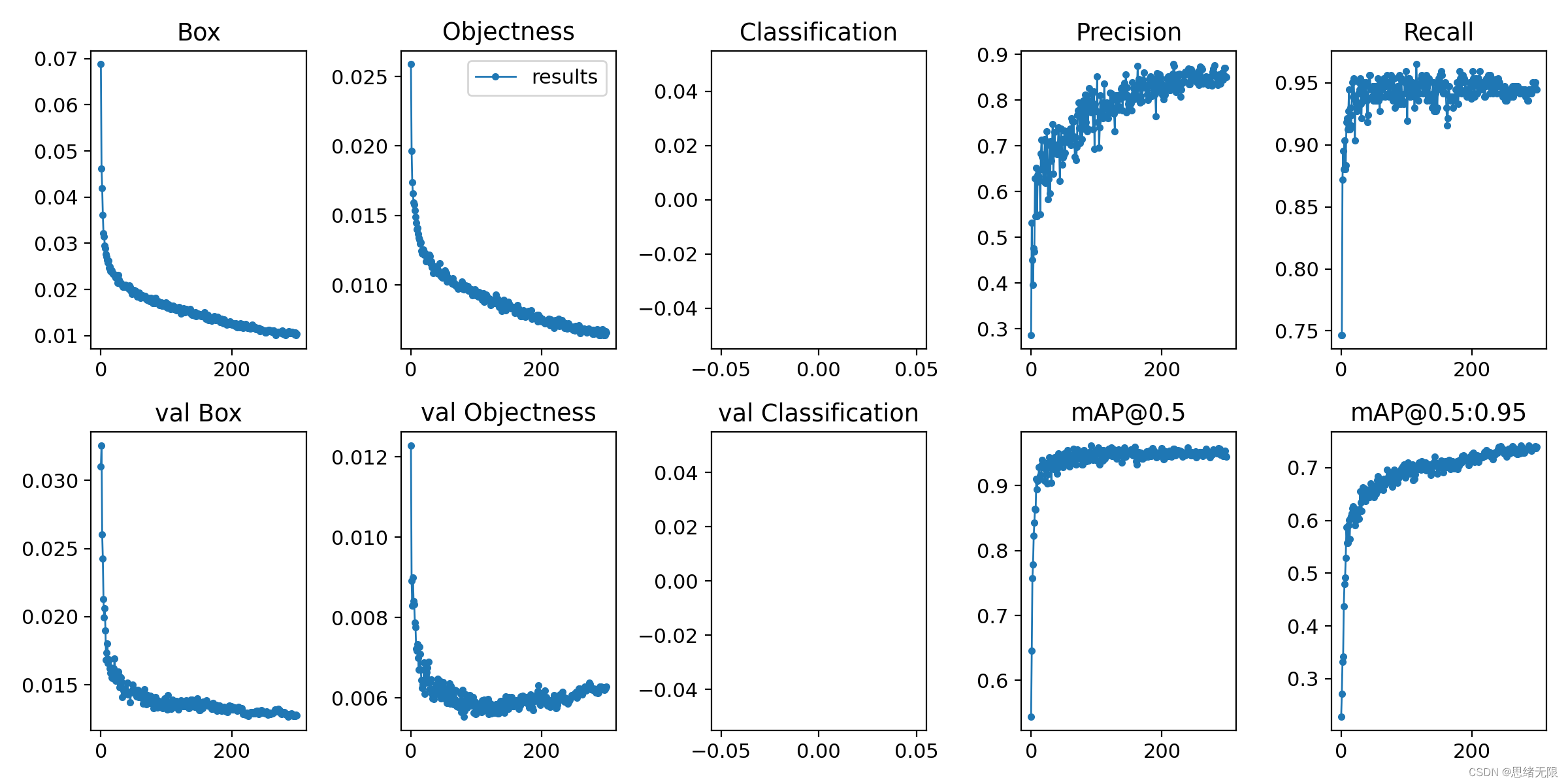
首先我们还是通过动图看一下识别的效果,系统主要实现的功能是对图片、视频和摄像头画面中的瓶子进行识别,识别的结果可视化显示在界面和图像中,另外提供多个目标的显示选择功能,演示效果如下。 (一)系统介绍 基于深度学习的瓶子检测软件主要用于日常塑料瓶、玻璃瓶等瓶子检测,利用深度学习技术检测识别瓶子数目,可视化检测结果;可对图片、视频、摄像设备得到的图像进行分析,自动标记和记录检测结果,辅助计算机进行瓶子生产回收等工序;深度学习模型可方便切换和更新,已针对不同场景进行模型调整;提供用户登录注册功能,方便用户管理和使用;检测结果易于查看、记录和保存。 (二)技术特点 (1)检测算法采用YoloV5实现,模型可切换更新; (三)用户注册登录界面 这里设计了一个登录界面,可以注册账号和密码,然后进行登录。界面还是参考了当前流行的UI设计,左侧是一个动图,右侧输入账号、密码、验证码等等。 (四)选择图片识别 系统允许选择图片文件进行识别,点击图片选择按钮图标选择图片后,显示所有识别的结果,可通过下拉选框查看单个结果,以便具体判断某一特定目标。本功能的界面展示如下图所示: (五)视频识别效果展示 很多时候我们需要识别一段视频中的多个瓶子,这里设计了视频选择功能。点击视频按钮可选择待检测的视频,系统会自动解析视频逐帧识别多个瓶子,并将瓶子的分类和计数结果记录在右下角表格中,效果如下图所示: (六)摄像头检测效果展示 (一)基于YoloV5的瓶子检测 YOLOv5( You Only Look Once ) 是 由 UltralyticsLLC 公司于 2020 年 5 月份提出,其图像推理速度最快达 0.007 s,即每秒可处理 140 帧,满足视频图像实时检测需求,同时结构更为小巧,YOLOv5s 版本的权重数据文件为 YOLOv4的 1/9,大小为 27 MB。YOLOv5处理流程为: (1)先将输入图片缩放到固定大小 640×640,再假想地将图片切分为 7×7个网格; (2)对整张图像做卷积运算,每个小网格负责 2 个回归框的和置信度的预测,同时每个小网格还要预测出来 20 个类别,以及属于这些类别的条件概率。 (3)使用非极大值抑制法,对输出结果—类别和位置进行筛选处理。 YOLO 最大的特长是由于只看一次,所以速度极快,但是准确率跟当下最好的检测器相比有差距。对于出现在同一个网格里,距离很近的两个小目标,经常出现漏检等情况。 Yolov5 按照网络深度大小和特征图宽度大小分为 Yolov5s、 Yolov5m、Yolov5l、Yolov5,本文采用了 yolov5s 作为使用模型。Yolov5 的结构分为 input,backbone,Neck, 预测层。 (1)在输入端使用了 Mosaic 的数据增强方式,随机调用 4 张图片,随机大小和分布,进行堆叠,丰富了数据,增加了很多小目标,提升小物体的识别能力。可以同时计算 4 张图片,相当于增加了 Mini-batch 大小,减少了GPU 内存的消耗。Yolov5 首先也可以通过聚类设定anchor大小,然后还可以在训练过程中,在每次训练时,计算不同训练集中的ahchor值。然后在预测时使用了自适应图片大小的缩放模式,通过减少黑边,提高了预测速度。 (2) 在 Backbone 上 的 主 要 是 采 用 了Focus 结构,CSPnet 结构。Focus 结构不存在与 YOLOv3和 v4 版本中,其关键步骤为切片操作,如下图 所示。例如将原始图像 416* 416* 3 接入 Focus 结构中,通过切片操作,变为 208* 208* 12 的特征图,接下来进行一次 32 个卷积核操作,变为 208* 208* 32 的特征图。 (二)数据集和训练 这里我们使用的瓶子识别数据集,包含训练数据集1486张图片,验证集248张图片,验证集125张图片,共计1859张图片。数据集部分图像及其标注信息如下图所示: 每张图像均提供了图像类标记信息,图像中瓶子的bounding box,瓶子的关键part信息,以及瓶子的属性信息,数据集并解压后得到如下的图片。 在深度学习中,我们通常通过损失函数下降的曲线来观察模型训练的情况。而YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),在训练结束后,我们也可以在logs目录下找到生成对若干训练过程统计图。下图为博主训练瓶子类识别的模型训练和曲线图。 YOLOv5训练时主要包含三个方面的损失:矩形框损失(box_loss)、置信度损失(obj_loss)和分类损失(cls_loss),下图为博主训练交通标志类识别的模型训练曲线图。 一般我们会接触到两个指标,分别是召回率recall和精度precision,两个指标p和r都是简单地从一个角度来判断模型的好坏,均是介于0到1之间的数值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,为了综合评价目标检测的性能,一般采用均值平均密度map来进一步评估模型的好坏。绘制出来可以得到如下图所示的曲线。 以PR-curve为例,可以看到我们的模型在验证集上的均值平均准确率为0.945。 在训练完成后得到最佳模型,接下来我们将帧图像输入到这个网络进行预测,从而得到预测结果,预测方法(predict.py)部分的代码如下所示: 得到预测结果我们便可以将帧图像中的瓶子框出,然后在图片上用opencv绘图操作,输出瓶子的类别及瓶子的预测分数。以下是读取一个瓶子图片并进行检测的脚本,首先将图片数据进行预处理后送predict进行检测,然后计算标记框的位置并在图中标注出来。 执行得到的结果如下图所示,图中瓶子的种类和置信度值都标注出来了,预测速度较快。基于此模型我们可以将其设计成一个带有界面的系统,在界面上选择图片、视频或摄像头然后调用模型进行检测。 博主对整个系统进行了详细测试,最终开发出一版流畅得到清新界面,就是博文演示部分的展示,完整的UI界面、测试图片视频、代码文件,以及Python离线依赖包(方便安装运行,也可自行配置环境),均已打包上传,感兴趣的朋友可以通过下载链接获取。 若您想获得博文中涉及的实现完整全部程序文件(包括测试图片、视频,py, UI文件等,如下图),这里已打包上传至博主的面包多平台,见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下: 在文件夹下的资源显示如下,下面的链接中也给出了Python的离线依赖包,读者可在正确安装Anaconda和Pycharm软件后,复制离线依赖包至项目目录下进行安装,离线依赖的使用详细演示也可见本人B站视频:win11从头安装软件和配置环境运行深度学习项目、Win10中使用pycharm和anaconda进行python环境配置教程。
注意:该代码采用Pycharm+Python3.8开发,经过测试能成功运行,运行界面的主程序为runMain.py和LoginUI.py,测试图片脚本可运行testPicture.py,测试视频脚本可运行testVideo.py。为确保程序顺利运行,请按照requirements.txt配置Python依赖包的版本。Python版本:3.8,请勿使用其他版本,详见requirements.txt文件; 完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件下载请见以下链接处给出:➷➷➷ 参考博客文章:https://mbd.pub/o/bread/ZJaXlZ1q 参考视频演示:https://www.bilibili.com/video/BV1jM411W7Tz/ 离线依赖库下载:https://pan.baidu.com/s/1hW9z9ofV1FRSezTSj59JSg?pwd=oy4n (提取码:oy4n ) 界面中文字、图标和背景图修改方法: 在Qt Designer中可以彻底修改界面的各个控件及设置,然后将ui文件转换为py文件即可调用和显示界面。如果只需要修改界面中的文字、图标和背景图的,可以直接在ConfigUI.config文件中修改,步骤如下: 可修改为自己的名为background2.png图片(位置在UI_rec/icons/文件夹中),可将该项设置如下即可修改背景图: 由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
前言


1. 效果演示
(2)定位图片、视频或摄像头等图像中瓶子位置;
(3)检测结果实时性强,便携展示、记录和保存;
(4)支持用户登录、注册、管理、界面可视化等功能;

在真实场景中,我们往往利用摄像头获取实时画面,同时需要对瓶子进行识别,因此本文考虑到此项功能。如下图所示,点击摄像头按钮后系统进入准备状态,系统显示实时画面并开始检测画面中的瓶子,识别结果展示如下图: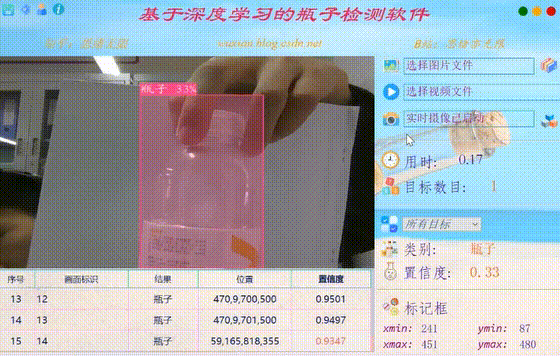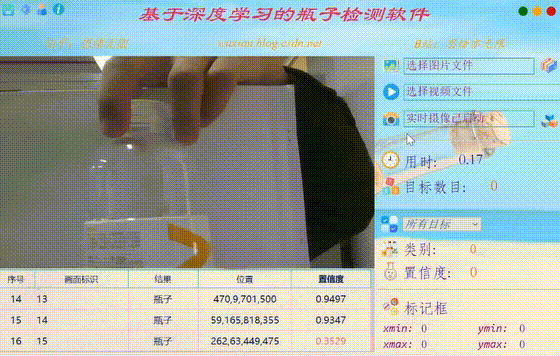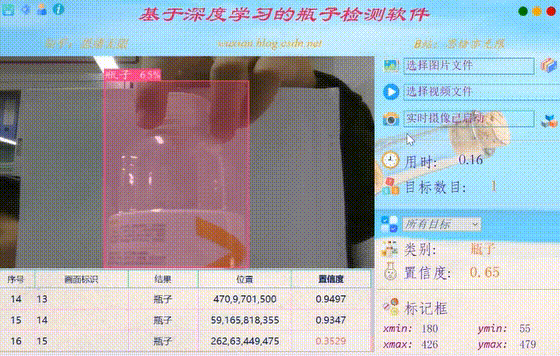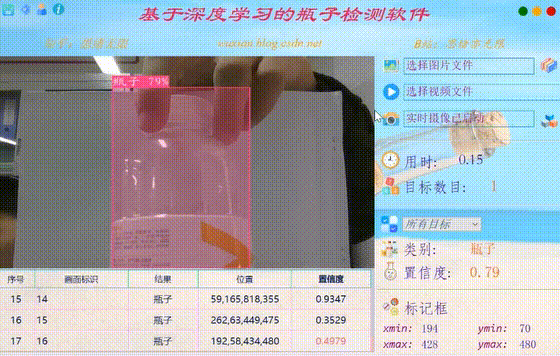
2. 检测原理与训练



3. 瓶子检测识别
def predict(img):
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
t1 = time_synchronized()
pred = model(img, augment=False)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes,
agnostic=opt.agnostic_nms)
t2 = time_synchronized()
InferNms = round((t2 - t1), 2)
return pred, InferNms
if __name__ == '__main__':
# video_path = 0
video_path = "./UI_rec/test_/瓶子检测视频.mp4"
# 初始化视频流
vs = cv2.VideoCapture(video_path)
(W, H) = (None, None)
frameIndex = 0 # 视频帧数
try:
prop = cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
# print("[INFO] 视频总帧数:{}".format(total))
# 若读取失败,报错退出
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1
fourcc = cv2.VideoWriter_fourcc(*'XVID')
ret, frame = vs.read()
vw = frame.shape[1]
vh = frame.shape[0]
print("[INFO] 视频尺寸:{} * {}".format(vw, vh))
output_video = cv2.VideoWriter("./results.avi", fourcc, 20.0, (vw, vh)) # 处理后的视频对象
# 遍历视频帧进行检测
while True:
# 从视频文件中逐帧读取画面
(grabbed, image) = vs.read()
# 若grabbed为空,表示视频到达最后一帧,退出
if not grabbed:
print("[INFO] 运行结束...")
output_video.release()
vs.release()
exit()
# 获取画面长宽
if W is None or H is None:
(H, W) = image.shape[:2]
image = cv2.resize(image, (850, 500))
img0 = image.copy()
img = letterbox(img0, new_shape=imgsz)[0]
img = np.stack(img, 0)
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
pred, useTime = predict(img)
det = pred[0]
p, s, im0 = None, '', img0
if det is not None and len(det): # 如果有检测信息则进入
det[:, :4] = scale_coords(img.shape[1:], det[:, :4], im0.shape).round() # 把图像缩放至im0的尺寸
number_i = 0 # 类别预编号
detInfo = []
for *xyxy, conf, cls in reversed(det): # 遍历检测信息
c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3]))
# 将检测信息添加到字典中
detInfo.append([names[int(cls)], [c1[0], c1[1], c2[0], c2[1]], '%.2f' % conf])
number_i += 1 # 编号数+1
label = '%s %.2f' % (names[int(cls)], conf)
# 画出检测到的目标物
plot_one_box(image, xyxy, label=label, color=colors[int(cls)])
# 实时显示检测画面
cv2.imshow('Stream', image)
image = cv2.resize(image, (vw, vh))
output_video.write(image) # 保存标记后的视频
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# print("FPS:{}".format(int(0.6/(end-start))))
frameIndex += 1


下载链接

(1)打开UI_rec/tools/ConfigUI.config文件,若乱码请选择GBK编码打开。
(2)如需修改界面文字,只要选中要改的字符替换成自己的就好。
(3)如需修改背景、图标等,只需修改图片的路径。例如,原文件中的背景图设置如下:mainWindow = :/images/icons/back-image.png
mainWindow = ./icons/background2.png
结束语
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。问题1)我想知道rubyonrails是否有功能类似于primefaces的gem。我问的原因是如果您使用primefaces(http://www.primefaces.org/showcase-labs/ui/home.jsf),开发人员无需担心javascript或jquery的东西。据我所知,JSF是一个规范,基于规范的各种可用实现,prim
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or