
📫作者简介:小明java问道之路,2022年度博客之星全国TOP3,专注于后端、中间件、计算机底层、架构设计演进与稳定性建工设优化。文章内容兼具广度深度、大厂技术方案,对待技术喜欢推理加验证,就职于知名金融公司后端高级工程师。
📫 热衷分享,喜欢原创~ 关注我会给你带来一些不一样的认知和成长。
🏆 2022博客之星TOP3 | CSDN博客专家 | 后端领域优质创作者 | CSDN内容合伙人
🏆 InfoQ(极客邦)签约作者、阿里云专家 | 签约博主、51CTO专家 | TOP红人、华为云享专家
🔥如果此文还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主~
🍅 文末获取联系 🍅 👇🏻 精彩专栏推荐订阅收藏 👇🏻
专栏系列(点击解锁)
学习路线(点击解锁)
知识定位
全面讲解MySQL知识与企业级MySQL实战 🔥计算机底层原理🔥
本文是继,Redis高可用之Cluster主从模式详解、Redis高可用之Sentinel哨兵模式详解 ,的Redis高可用与系列第三篇。
本文主要讲解什么是集群模式,集群模式的必要性、基本概念和拓扑结构,集群中数据Hash Solt分区的原理,节点故障处理方式与集群的伸缩。
Sentinel 模式的最大缺点是所有数据都放在一台服务器上,无法横向扩展,为了解决哨兵模式的问题,集群模式应运而生。
主从模式:Redis高可用之Cluster主从模式详解,哨兵模式:Redis高可用之Sentinel哨兵模式详解
如前所述,主从系统有高可用性和分布性问题,哨兵模式只解决了高可用性问题,集群模式可以解决高可用性和分布问题的终极解决方案。 哨兵模式基于主从模式,实现读写分离,它还可以自动切换,系统可用性更高,但是它每个节点存储的数据是一样的,浪费内存,在Redis3.0后开始支持集群模式。
分片集群模式是将一部分数据存储到每个Redis服务器,所有Redis服务器的数据相加形成一个完整的数据(分片集群或者分布式)。它实现了Redis的分布式存储,对数据进行分片,也就是说每台Redis节点上存储不同的内容,来解决在线扩容的问题。所以要形成分片集群,需要路由不同的密钥。一般使用两种通用的路由方案客户端路由(SDK)和服务器路由(Proxy),客户端路由的代表(Redis Cluster),服务器端路由的代表(Codis)。
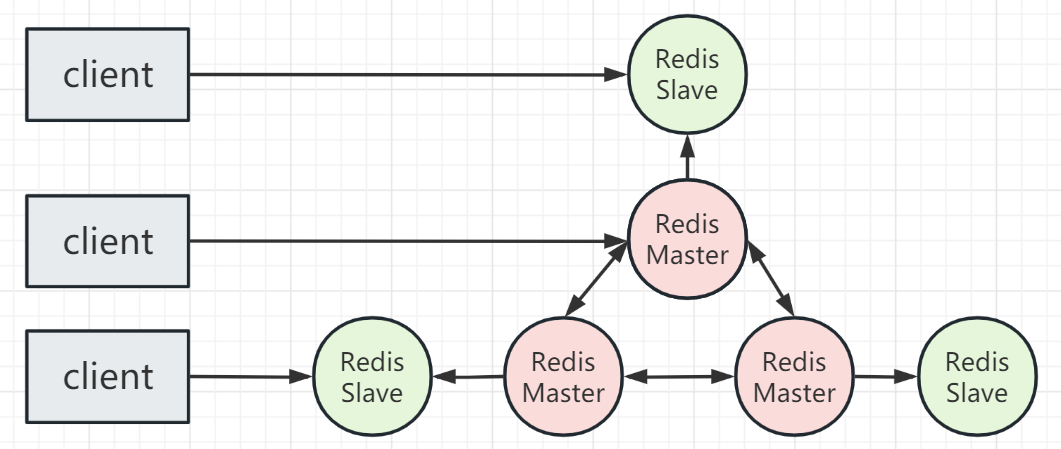
Redis集群由多个Redis节点组成,节点组中是主节点(Master)和从节点(Slave),两者之间的数据是准实时一致的,这是由异步主备复制机制保证的。
如上图所示,一个节点组只有一个主节点,同时可以有0到多个从节点,在这个节点组中,只有主节点为用户提供一些服务,读服务可以由主节点或从节点提供。上图包含三个主节点和对应于主节点的三个从节点。
通常,一组集群至少需要六个节点才能确保完全的高可用性。三个主节点将被分配不同的 slot 插槽(表示数据分区间隔)。当主节点发生故障时,从节点将自动选择出新的主节点继续提供服务。
Redis集群模式使用 slots 插槽,一个集群有 16384 个哈希槽将分配给不同的Redis实例。此外,Redis集群模式没有中心节点,每个主节点将保持与其他主节点的连接,节点通过 gossip协议 相互交换信息,同时,每个主节点都具有一个或多个从节点。
当客户端连接到集群时,它直接连接到Redis集群的每个主节点,并根据哈希算法将密钥存储在不同的哈希槽中。例如上图,Redis集群按数据碎片划分的16384个哈希槽,分别存储在三个主节点中:Master1负责哈希槽0~5460、Master2负责哈希槽5461~10922、Master3负责哈希槽10922~16383。
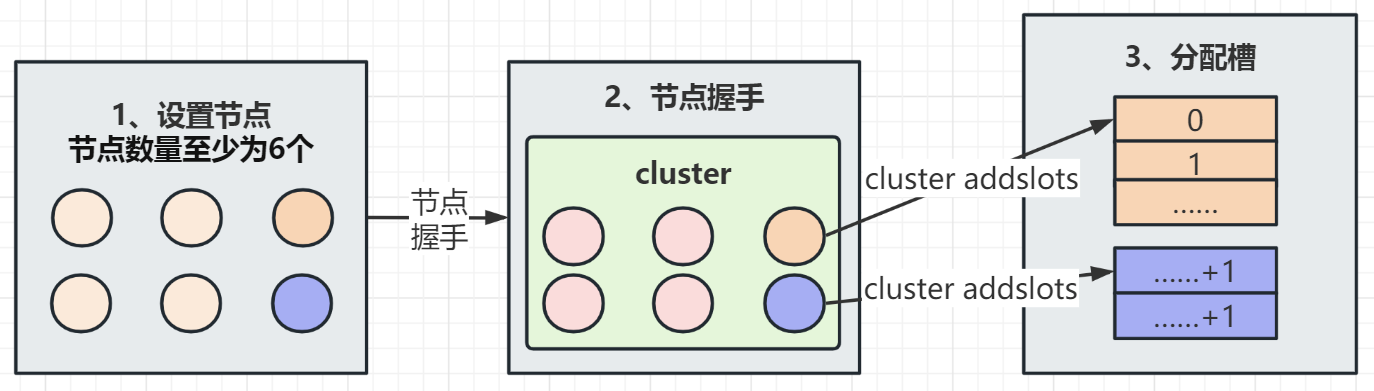
Redis集群通过数据分区实现数据的分布式存储(在创建集群时完成),并通过自动故障切换实现高可用性。
Redis集群通常由多个节点组成,设置节点时,节点数至少为6个以确保集群完整且高度可用,每个节点都需要启用和配置 cluster-enabled yes(启动集群),以在集群模式下运行Redis。
节点握手是指以集群模式运行的一组节点通过 Gossip协议 相互通信,以实现对彼此的感知的过程。节点握手是集群之间通信的第一步。客户端启动命令:cluster meet{ip}{port}。节点握手后,Redis节点形成一个多节点集群。
Redis集群将所有数据映射到16384个插槽,每个节点对应几个插槽(必须全部使用),只有当节点分配了时隙时,它才能响应与这些时隙相关联的密钥命令,通过 cluster addslots命令为节点分配插槽。
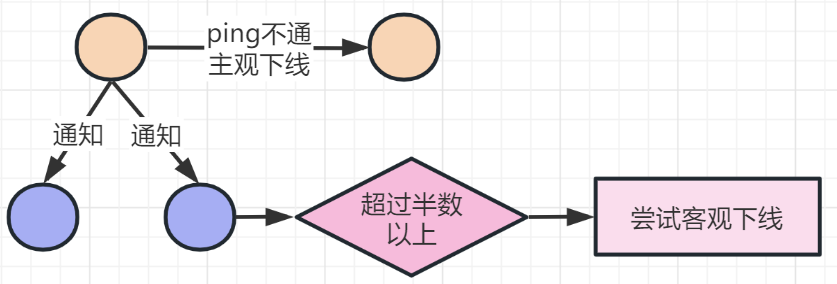
Redis集群中的主节点故障处理模式与哨兵模式类似,但是Redis集群中所有的节点都要承担状态维护的任务。
当一个节点无法成功完成与集群中另一个节点的ping消息通信时,该节点将被标记为主观离线状态,并且信息将被广播到整个集群。
如果节点接收到的节点丢失连接的数量达到集群的大多数,则该节点将被标记为目标脱机状态,并且脱机节点的故障消息将被广播到集群。然后,故障节点将立即从主节点切换到从节点。恢复原始主节点后,它将自动成为新主节点的从节点。如果主节点没有从节点,则集群在发生故障时将不可用。
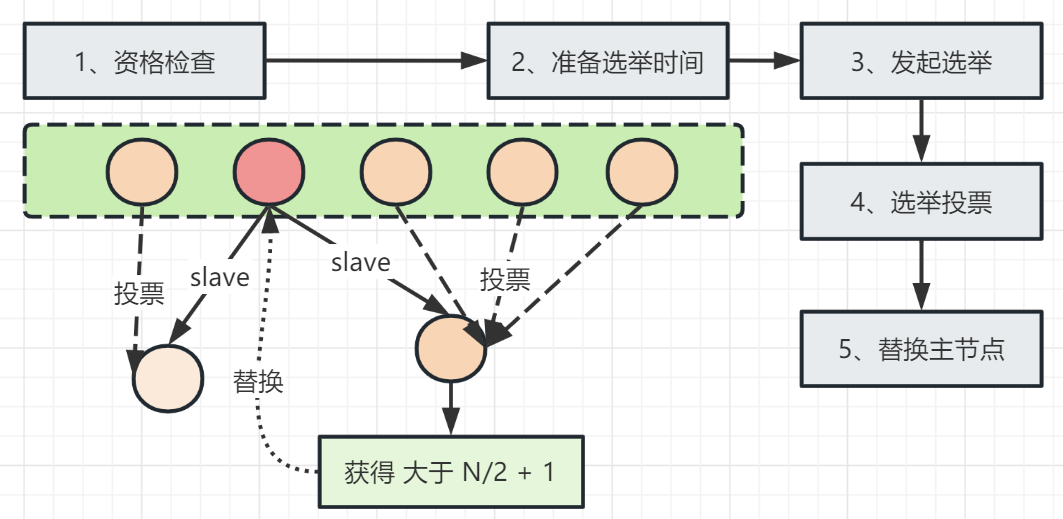
在投票选举阶段,失败的主节点也计入投票数。假设集群中节点的大小为3个主节点和3个从节点,其中2个主节点部署在一台机器上,当此机器停机时,故障切换将失败,因为从节点无法收集3/2+1个主节点的投票(故障查找链路也会发生)。因此,在部署集群时,所有主节点都需要部署在至少三台物理机器上,以避免单点问题。
扩容与缩容类似,都是先把插槽和数据迁移到其他节点,然后把相应的节点下线。
当新节点添加到集群时,它将与集群中的节点握手,该节点将通过gossip协议将集群中其他节点的信息发送到新节点,新节点将在与这些节点握手后加入集群,然后集群中的节点将加入哈希槽并将其分配给新节点。
Gossip protocol(gossip协议),它的特点是,在节点数量有限的网络中,每个节点都会随机(不是真的随机,而是根据规则选择通信节点)与一些节点通信,在混乱的通信之后,每个节点的状态将在一定时间内达到相同。
Gossip 协议包含多种消息,包括ping(在节点故障发现的时候使用),pong(接收节点回复),meet(在节点握手的时候使用),fail(自动故障转移、下线、故障选举)等等。也有一些缺点,例如数据更新的延迟可能导致集群的某些操作滞后,消息延迟、消息冗余等等。
本文是继,Redis高可用之Cluster主从模式详解、Redis高可用之Sentinel哨兵模式详解 ,的Redis高可用与系列第三篇。
本文主要讲解什么是集群模式,集群模式的必要性、基本概念和拓扑结构,集群中数据Hash Solt分区的原理,节点故障处理方式与集群的伸缩。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我经常迷上ruby的一件事是递归模式。例如,假设我有一个数组,它可能包含无限深度的数组作为元素。所以,例如:my_array=[1,[2,3,[4,5,[6,7]]]]我想创建一个方法,可以将数组展平为[1,2,3,4,5,6,7]。我知道.flatten可以完成这项工作,但这个问题是作为我经常遇到的递归问题的一个例子-因此我试图找到一个更可重用的解决方案。简而言之-我猜这种事情有一个标准模式,但我想不出任何特别优雅的东西。任何想法表示赞赏 最佳答案 递归是一种方法,它不依赖于语言。您在编写算法时要考虑两种情况:再次调用函数的情
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven